Diffusione audio minima diffusione della forma d’onda che non richiede il cloud computing
Minimal audio diffusion, waveform diffusion without requiring cloud computing.

Esplorazione di come addestrare modelli e generare suoni con la diffusione di forme d’onda audio su un computer portatile per consumatori e GPU con meno di 2GB di VRAM
Contesto
I modelli di diffusione sono molto popolari al momento, specialmente da quando la Diffusione Stabile ha fatto impazzire il mondo quest’estate. Da allora, innumerevoli variazioni e nuovi modelli di diffusione sono stati pubblicati in una vasta gamma di contesti. E sebbene le straordinarie immagini abbiano rubato la scena, si è sviluppato molto anche nella diffusione legata alla generazione audio.
Alimentata dalla diffusione e da altri metodi, la musica generativa ha visto molti successi recenti, con nuovi modelli pubblicati tutto il tempo. OpenAI ha stupito il mondo con le capacità di Jukebox quando è stato rilasciato nel 2020. Ma Google ha detto “Tieni il mio modello” quando ha prodotto il notevole MusicLM all’inizio di quest’anno. Meta non è stata da meno quando ha rilasciato e reso open source MusicGen il mese scorso. Ma non solo grandi istituzioni si stanno unendo, ci sono state anche contribuzioni molto interessanti da parte di ricercatori indipendenti come Riffusion (Forsgren & Martiros) e Moûsai (Schneider, et al.). Oltre a questi, numerosi altri modelli sono stati rilasciati negli ultimi anni, ognuno con i suoi vantaggi e svantaggi.
I modelli di diffusione hanno affascinato così tante persone per la loro notevole capacità creativa; qualcosa che molti altri generi di apprendimento automatico (ML) non hanno. La maggior parte dei modelli di ML vengono addestrati per svolgere un compito e il loro successo può essere misurato dal fatto che siano corretti o incorretti. Ma quando entriamo nel campo dell’arte e della musica, come può un modello essere ottimizzato per ciò che potrebbe essere considerato il migliore? Potrebbe ovviamente imparare a riprodurre opere d’arte o musica famose, ma senza novità, non ha senso. Quindi come può essere risolto questo problema, come iniettare creatività in una macchina che conosce solo 1 e 0? La diffusione è un metodo che offre una soluzione elegante a questo dilemma.
Diffusione – A 10.000 piedi
Alla base, la diffusione nell’ambito del ML è semplicemente il processo di aggiunta o rimozione di rumore da un segnale (pensa al disturbo di un vecchio televisore). La diffusione in avanti aggiunge rumore a un segnale e la diffusione inversa rimuove il rumore. Il processo con cui siamo più familiari è il processo di diffusione inversa, in cui il modello prende il rumore e poi lo “denoisa” in qualcosa che gli esseri umani riconoscono (arte, musica, discorsi, ecc.). Questo processo può essere manipolato in molteplici modi per scopi diversi.
- ‘Interruttore a levetta’ può aiutare i computer quantistici a tagliare attraverso il rumore
- Algoritmo trova sperma negli uomini infertili più velocemente e accuratamente dei medici
- Sempre più persone stanno diventando cieche. L’AI può aiutare a combattere questo problema.
La “creatività” nella diffusione deriva dal rumore casuale che innesca il processo di denoising. Se fornisci al modello un punto di partenza diverso ogni volta per denoising in una qualche forma di arte o musica, ciò simula la creatività poiché gli output saranno sempre unici.




Il metodo per insegnare a un modello a eseguire questo processo di denoising potrebbe effettivamente essere un po’ controintuitivo a un primo pensiero. Il modello impara effettivamente a denoizzare un segnale facendo esattamente il contrario, ovvero aggiungendo rumore a un segnale pulito più e più volte fino a quando rimane solo rumore. L’idea è che se il modello può imparare come prevedere il rumore aggiunto a un segnale ad ogni passo, allora può anche prevedere il rumore rimosso ad ogni passo per il processo inverso. L’elemento critico per rendere ciò possibile è che il rumore aggiunto/rimosso deve essere di una distribuzione probabilistica definita (tipicamente gaussiana) in modo che i passaggi di rumore/noise siano prevedibili e ripetibili.
Ci sono molti dettagli che vanno in questo processo, ma questo dovrebbe fornire una comprensione concettuale solida di ciò che sta accadendo sotto il cofano. Se sei interessato a saperne di più sui modelli di diffusione (formulazioni matematiche, pianificazione, spazio latente, ecc.), ti consiglio di leggere questo post del blog di AssemblyAI e questi articoli (DDPM, Miglioramento DDPM, DDIM, Diffusione stabile).
Diffusione audio ridotta
Comprensione dell’audio per l’apprendimento automatico
Il mio interesse per la diffusione deriva dal potenziale che ha dimostrato con l’audio generativo. Tradizionalmente, per addestrare gli algoritmi di apprendimento automatico, l’audio veniva convertito in uno spettrogramma, che è essenzialmente una mappa di calore dell’energia sonora nel tempo. Questo perché una rappresentazione spettrogramma era simile a un’immagine, con cui i computer sono eccezionali nel lavorare, ed era una riduzione significativa delle dimensioni dei dati rispetto a una forma d’onda grezza.
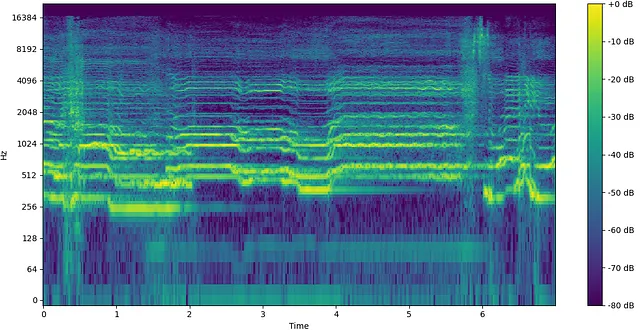
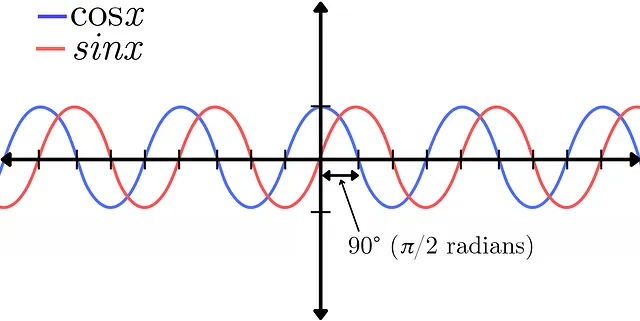
Tuttavia, con questa trasformazione ci sono alcuni compromessi, tra cui una riduzione della risoluzione e una perdita di informazioni di fase. La fase di un segnale audio rappresenta la posizione di più forme d’onda relative l’una all’altra. Ciò può essere dimostrato dalla differenza tra una funzione seno e una funzione coseno. Rappresentano lo stesso segnale esatto in termini di ampiezza, l’unica differenza è uno spostamento di fase di 90° (π/2 radianti) tra le due. Per una spiegazione più approfondita della fase, guarda questo video di Akash Murthy.
La fase è un concetto perpetuamente difficile da comprendere, anche per coloro che lavorano nell’audio, ma svolge un ruolo fondamentale nella creazione delle qualità timbriche del suono. Sia l’informazione di ampiezza che di fase possono essere rappresentate in forma di spettrogramma (la parte complessa della trasformazione), proprio come l’ampiezza. Tuttavia, il risultato è rumoroso e appare visivamente casuale, rendendo difficile per un modello apprendere informazioni utili da esso. A causa di questo svantaggio, recentemente c’è stato un interesse nel non trasformare l’audio in spettrogrammi e invece lasciarlo come una forma d’onda grezza per addestrare i modelli. Sebbene ciò comporti delle sfide, sia l’informazione di ampiezza che di fase sono contenute nel singolo segnale di una forma d’onda, fornendo al modello un quadro più completo del suono da apprendere.
Questo è un elemento chiave del mio interesse nella diffusione delle forme d’onda, ed ha mostrato promesse nel produrre risultati di alta qualità per l’audio generativo. Le forme d’onda, tuttavia, sono segnali molto densi che richiedono una quantità significativa di dati per rappresentare la gamma di frequenze che gli esseri umani possono udire. Ad esempio, il campionamento standard dell’industria musicale è di 44,1 kHz, il che significa che sono necessari 44.100 campioni per rappresentare solo 1 secondo di audio mono. Ora raddoppia tutto ciò per la riproduzione stereo. A causa di ciò, la maggior parte dei modelli di diffusione delle forme d’onda (che non sfruttano la diffusione latente o altri metodi di compressione) richiedono una capacità GPU elevata (di solito almeno 16GB+ di VRAM) per archiviare tutte le informazioni durante l’addestramento.
Motivazione
Molte persone non hanno accesso a GPU potenti o di grande capacità, o non vogliono pagare la tariffa per noleggiare GPU cloud per progetti personali. Trovandomi in questa posizione, ma desiderando comunque esplorare modelli di diffusione delle forme d’onda, ho deciso di sviluppare un sistema di diffusione delle forme d’onda che potesse funzionare sul mio modesto hardware locale.
Configurazione hardware
Ero equipaggiato con un laptop HP Spectre del 2017 con processore Intel Core i7 di ottava generazione e scheda grafica GeForce MX150 con 2GB di VRAM, non esattamente una potenza per addestrare modelli di apprendimento automatico. Il mio obiettivo era quello di essere in grado di creare un modello che potesse addestrare e produrre output stereo ad alta qualità (44,1 kHz) su questo sistema.
Architettura del modello
Ho utilizzato la libreria audio-diffusion-pytorch di Archinet per costruire questo modello, ringrazio Flavio Schneider per il suo aiuto nel lavorare con questa libreria che ha in gran parte costruito.
Attention U-Net
L’architettura di base del modello consiste in una U-Net con blocchi di attenzione, che è lo standard per i moderni modelli di diffusione. Una U-Net è una rete neurale originariamente sviluppata per la segmentazione di immagini (2D), ma è stata adattata all’audio (1D) per le nostre esigenze con la diffusione delle forme d’onda. L’architettura U-Net prende il nome dal suo design a forma di U.
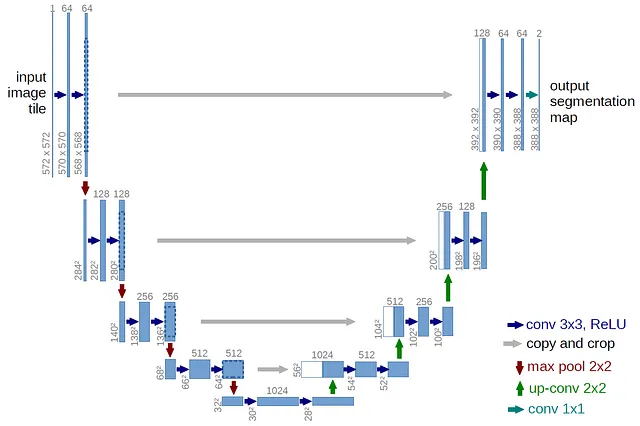
Molto simile a un autoencoder, composto da un encoder e un decoder, una U-Net contiene anche collegamenti di connessione diretta a ciascun livello della rete. Questi collegamenti consentono il trasferimento di dettagli di alta qualità dall’encoder al decoder. L’encoder è responsabile della cattura delle caratteristiche importanti del segnale di input, mentre il decoder è responsabile della generazione del nuovo campione audio. L’encoder riduce gradualmente la risoluzione dell’audio di input, estraendo caratteristiche a diversi livelli di astrazione. Il decoder prende quindi queste caratteristiche e le aumenta gradualmente, aumentando la risoluzione per generare il campione audio finale.

Questa U-Net contiene anche blocchi di auto-attenzione nei livelli inferiori, che aiutano a mantenere la coerenza temporale dell’output. È fondamentale che l’audio venga sottocampionato in modo sufficiente per mantenere l’efficienza del campionamento durante il processo di diffusione e evitare sovraccarichi dei blocchi di attenzione. Il modello sfrutta la tecnica di diffusione V-Diffusion, ispirata al campionamento DDIM.
Per evitare di esaurire la VRAM della GPU, la lunghezza dei dati su cui il modello di base doveva essere addestrato doveva essere breve. Per questo motivo, ho deciso di addestrare campioni di batteria one-shot a causa delle loro lunghezze di contesto intrinsecamente brevi. Dopo molte iterazioni, la lunghezza del modello di base è stata determinata essere di 32.768 campioni @ 44,1kHz in stereo, il che corrisponde a circa 0,75 secondi. Questo potrebbe sembrare particolarmente breve, ma è sufficiente per la maggior parte dei campioni di batteria.
Trasformazioni
Per sottocampionare sufficientemente l’audio per i blocchi di attenzione, sono state testate diverse trasformazioni di pre-elaborazione. L’obiettivo era che, se i dati audio potessero essere sottocampionati senza perdere informazioni significative prima di addestrare il modello, allora il numero di nodi (neuroni) e di livelli potesse essere massimizzato senza aumentare il carico di memoria della GPU.
La prima trasformazione testata è stata una versione di “patching”. Originariamente proposto per le immagini, questo processo è stato adattato all’audio per i nostri scopi. Il campione audio di input è raggruppato per intervalli di tempo sequenziali in pezzi che vengono quindi trasposti in canali. Questo processo può quindi essere invertito all’uscita della U-Net per ripristinare l’audio senza pezzi alla sua lunghezza completa. Tuttavia, il processo di ripristino ha creato problemi di aliasing, causando artefatti indesiderati ad alta frequenza nell’audio generato.
La seconda trasformazione testata, proposta da Schneider, si chiama “trasformazione appresa” e consiste in singoli blocchi convoluzionali con dimensioni di kernel grandi e passi all’inizio e alla fine della U-Net. Sono stati testati diversi kernel e passi (16, 32, 64) insieme a variazioni del modello per sottocampionare adeguatamente l’audio. Anche in questo caso, tuttavia, ciò ha comportato problemi di aliasing nell’audio generato, sebbene non così diffusi come con la trasformazione patching.
A causa di ciò, ho deciso che l’architettura del modello avrebbe dovuto essere adattata per accogliere l’audio grezzo senza trasformazioni di pre-elaborazione per produrre risultati di qualità sufficiente.
Questo ha richiesto di aumentare il numero di livelli all’interno della U-Net per evitare un sottocampionamento troppo rapido e la perdita di importanti caratteristiche lungo il percorso. Dopo molte iterazioni, la migliore architettura ha comportato un sottocampionamento di soli 2 a ogni livello. Sebbene ciò abbia richiesto una riduzione del numero di nodi per livello, ha prodotto i migliori risultati. Informazioni dettagliate sul numero esatto di livelli, livelli, nodi, caratteristiche di attenzione, ecc. possono essere trovate nel file di configurazione nel repository tiny-audio-diffusion su GitHub.
Conclusione
Modelli Pre-Allenati
Ho allenato 4 modelli autonomi separati per produrre calci, tamburi rullanti, hi-hat e percussioni (tutti suoni di batteria). I dataset utilizzati per l’addestramento erano piccoli campioni gratuiti che avevo raccolto per i miei flussi di lavoro di produzione musicale (tutti open-source). Dataset più grandi e più variati migliorerebbero la qualità e la diversità delle uscite generate da ciascun modello. I modelli sono stati allenati per un numero variabile di passi ed epoche a seconda delle dimensioni di ciascun dataset.
I modelli pre-allenati sono disponibili per il download su Hugging Face. Vedi i progressi dell’addestramento e gli esempi di output registrati su Weights & Biases.
Risultati
In generale, la qualità dell’output è piuttosto alta nonostante la ridotta dimensione dei modelli. Tuttavia, rimane ancora un leggero “sibilo” ad alta frequenza, probabilmente dovuto alla dimensione limitata del modello. Questo può essere visto nella piccola quantità di rumore che rimane nelle forme d’onda sottostanti. La maggior parte degli esempi generati sono nitidi, mantenendo trasienti e caratteristiche timbriche a banda larga. A volte i modelli aggiungono rumore extra verso la fine del campione e questo è probabilmente un costo del limite di strati e nodi del modello.
Ascolta alcuni esempi di output dai modelli qui. Di seguito sono mostrati gli output di esempio di ciascun modello.
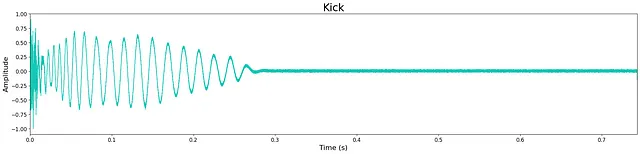
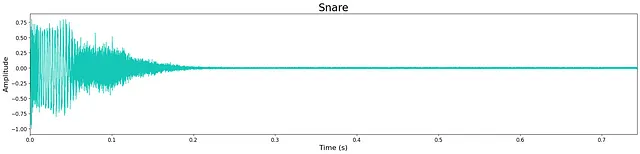
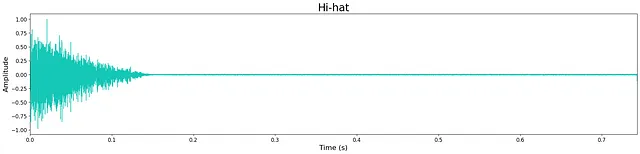
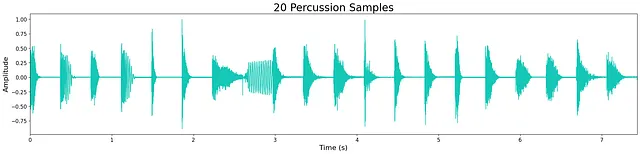
Discussione
Oltre all’esplorazione dei modelli di diffusione delle forme d’onda sul mio hardware locale, un obiettivo importante per questo progetto era quello di poter condividere la stessa opportunità con gli altri. Volevo offrire un punto di ingresso facile per coloro che dispongono di risorse limitate e che desiderano sperimentare la diffusione delle forme d’onda audio. Per questo motivo, ho strutturato il repository del progetto per offrire istruzioni passo-passo su come addestrare o affinare i propri modelli e generare nuovi campioni dal notebook Inference.ipynb.
Inoltre, ho registrato un video tutorial che illustra come configurare un ambiente Anaconda e mostra modi per generare campioni unici con i modelli pre-allenati.
È un momento eccitante per l’audio generativo, specialmente con la diffusione. Ho imparato una quantità enorme attraverso la costruzione di questo progetto e ho ampliato ulteriormente il mio ottimismo su ciò che sta per arrivare nell’audio AI. Spero che questo progetto possa essere utile ad altri che desiderano esplorare il mondo dell’audio AI.
Tutte le immagini, salvo diversa indicazione, sono dell’autore.
Codice tiny-audio-diffusion trovato qui: https://github.com/crlandsc/tiny-audio-diffusion
Video tutorial su come configurare il proprio ambiente per generare campioni con tiny-audio-diffusion: https://youtu.be/m6Eh2srtTro
Sono uno scienziato del suono con un focus su AI/ML e audio spaziale, nonché un musicista da sempre. Se sei interessato ad altre applicazioni di audio AI, consulta il mio recente articolo su Music Demixing.
Trovami su LinkedIn & GitHub e resta aggiornato sul mio lavoro e le mie ricerche attuali qui: www.chrislandschoot.com
Trova la mia musica su Spotify, Apple Music, YouTube, SoundCloud e altre piattaforme di streaming come After August.






