Ingegneria moderna dei dati con MAGE potenziare l’elaborazione efficiente dei dati
MAGE migliora l'elaborazione dei dati nell'ingegneria moderna.
Introduzione
Nel mondo odierno basato sui dati, le organizzazioni di diverse industrie si confrontano con volumi massicci di dati, pipeline complesse e la necessità di un efficiente elaborazione dei dati. Le tradizionali soluzioni di ingegneria dei dati, come Apache Airflow, hanno svolto un ruolo importante nell’orchestrare e controllare le operazioni sui dati per affrontare queste difficoltà. Tuttavia, con la rapida evoluzione della tecnologia, è emerso un nuovo contendente, Mage, per ridefinire il panorama dell’ingegneria dei dati.
Obiettivi di apprendimento
- Integrare e sincronizzare dati di terze parti in modo fluido
- Costruire pipeline in tempo reale e batch in Python, SQL e R per la trasformazione
- Un codice modulare riutilizzabile e testabile con validazioni dei dati
- Eseguire, monitorare e orchestrare diverse pipeline mentre dormi
- Collaborare sul cloud, il controllo delle versioni con Git e testare pipeline senza dover attendere un ambiente di staging condiviso disponibile
- Deployment veloci su provider Cloud come AWS, GCP e Azure tramite modelli terraform
- Trasformare insiemi di dati molto grandi direttamente nel tuo data warehouse o tramite integrazione nativa con Spark
- Con monitoraggio, allerta e osservabilità integrati attraverso un’interfaccia utente intuitiva
Non sarebbe facile come cadere dal tronco? Allora dovresti assolutamente provare Mage!
In questo articolo, parlerò delle caratteristiche e delle funzionalità di Mage, evidenziando ciò che ho imparato finora e la prima pipeline che ho costruito utilizzandolo.
Questo articolo è stato pubblicato come parte del Data Science Blogathon.
- L’AI aiuta a mostrare come i fluidi del cervello scorrono
- Svelando gli effetti dannosi dell’Intelligenza Artificiale sulla comunità transessuale.
- Analisi a Gruppi Multipli nella Modellizzazione a Equazioni Strutturali
Cos’è Mage?
Mage è uno strumento moderno di orchestrazione dei dati alimentato da AI e costruito su modelli di Machine Learning e mira a semplificare e ottimizzare i processi di ingegneria dei dati come mai prima d’ora. È uno strumento open-source per le pipeline di dati facile ma efficace per la trasformazione e l’integrazione dei dati e può essere una valida alternativa a strumenti consolidati come Airflow. Unendo la potenza dell’automazione e dell’intelligenza, Mage rivoluziona il flusso di lavoro di elaborazione dei dati, trasformando il modo in cui i dati sono gestiti ed elaborati. Mage si sforza di semplificare e ottimizzare il processo di ingegneria dei dati, diversamente da qualsiasi cosa sia stata fatta prima, con le sue ineguagliabili capacità e la sua interfaccia utente amichevole.
Passo 1: Installazione rapida
Mage può essere installato mediante i comandi Docker, pip e conda, o può essere ospitato su servizi cloud come una macchina virtuale.
Utilizzando Docker
#Comando per l'installazione di Mage utilizzando Docker
>docker run -it -p 6789:6789 -v %cd%:/home/src mageai/mageai /app/run_app.sh mage start [project_name]
#Comando per l'installazione di Mage localmente su una porta diversa
>docker run -it -p 6790:6789 -v %cd%:/home/src mageai/mageai /app/run_app.sh mage start [project_name]Utilizzando Pip
#installazione mediante il comando pip
>pip install mage-ai
>mage start [project_name]
#installazione mediante conda
>conda install -c conda-forge mage-aiCi sono anche pacchetti aggiuntivi per l’installazione di Mage utilizzando Spark, Postgres e molti altri. In questo esempio, ho utilizzato Google Cloud Compute Engine per accedere a Mage (come VM) tramite SSH. Ho eseguito i seguenti comandi dopo aver installato i pacchetti Python necessari.
#Comando per l'installazione di Mage
~$ mage sudo pip3 install mage-ai
#Comando per avviare il progetto
~$ mage start nyc_trides_project
Controllo della porta 6789...
Mage è in esecuzione all'indirizzo http://localhost:6789 e serve il progetto /home/srinikitha_sri789/nyc_trides_proj
INFO:mage_ai.server.scheduler_manager:Scheduler status: running.Passo 2: Costruzione
Mage fornisce diversi blocchi con codice integrato che hanno casi di test, che possono essere personalizzati in base alle esigenze del progetto.

Ho utilizzato i blocchi Data Loader, Data Transformer e Data Exporter (ETL) per caricare i dati dall’API, trasformare i dati ed esportarli su Google Big Query per ulteriori analisi.
Vediamo come funziona ogni blocco.
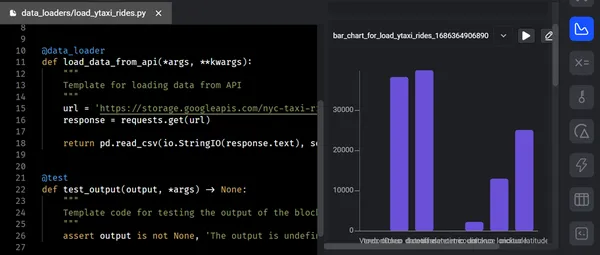
I) Caricatore dati
Il blocco “Caricatore dati” funge da ponte tra la fonte dati e le fasi successive di elaborazione dei dati all’interno del pipeline. Il caricatore dati acquisisce i dati dalle fonti e li trasforma in un formato adatto per renderli disponibili per ulteriori elaborazioni.
Funzionalità chiave
- Connettività fonte dati : Il blocco di caricamento dati consente la connettività a una vasta gamma di database, API, sistemi di archiviazione cloud (Azure Blob Storage, GBQ, GCS, MySQL, S3, Redshift, Snowflake, Delta Lake, ecc.) e altre piattaforme di streaming.
- Controlli qualità dati e gestione errori : Durante il processo di caricamento dei dati, esegue controlli di qualità dei dati per garantire che i dati siano accurati, coerenti e conformi agli standard di convalida stabiliti. La logica della pipeline dei dati fornita può essere utilizzata per registrare, segnalare o affrontare eventuali errori o anomalie scoperti.
- Gestione dei metadati : Il blocco di caricamento dati gestisce e acquisisce i metadati relativi ai dati acquisiti. La fonte dati, il timestamp di estrazione, lo schema dei dati e altri fattori sono tutti inclusi in questi metadati. La gestione efficace dei metadati rende più facile la tracciabilità dei dati, l’audit e il monitoraggio delle trasformazioni dei dati lungo il pipeline.
Lo screenshot qui sotto mostra il caricamento di dati grezzi dall’API in Mage utilizzando il caricatore dati. Dopo aver eseguito il codice del caricatore dati e superato con successo i casi di test, l’output viene presentato in una struttura ad albero all’interno del terminale.


II) Trasformazione dei dati
Il blocco “Trasformazione dei dati” esegue manipolazioni sui dati in ingresso e ne deriva informazioni significative, preparandoli per i processi downstream. Ha un’opzione di codice generico e un file autonomo contenente codice modulare riutilizzabile e testabile con validazioni dei dati in Python per l’esplorazione dei dati, il ridimensionamento e le azioni necessarie sulla colonna, SQl e R.
Funzionalità chiave
- Combinazione di dati : Il blocco trasformatore dei dati rende più facile la combinazione e la fusione di dati provenienti da diverse fonti o diversi set di dati. Gli ingegneri dei dati possono combinare i dati in base a qualità chiave simili perché consente una varietà di join, compresi join interni, join esterni e join incrociati. Questa funzionalità è davvero utile quando si effettua l’arricchimento dei dati o si fondono dati provenienti da diverse fonti.
- Funzioni personalizzate : Permette di definire e applicare funzioni ed espressioni personalizzate per manipolare i dati. È possibile sfruttare le funzioni incorporate o scrivere funzioni definite dall’utente per trasformazioni avanzate dei dati.
Dopo aver caricato i dati, il codice di trasformazione eseguirà tutte le manipolazioni necessarie (in questo esempio – la conversione di un file piatto in tabelle di fatti e dimensioni) e trasforma il codice nell’esportatore di dati. Dopo l’esecuzione del blocco di trasformazione dei dati, viene mostrato il diagramma ad albero qui sotto.


III) Esportatore di dati
Il blocco “Esportatore di dati” esporta e consegna i dati elaborati a varie destinazioni o sistemi per ulteriore consumo, analisi o archiviazione. Garantisce un trasferimento e un’integrazione dei dati senza soluzione di continuità con i sistemi esterni. Possiamo esportare i dati in qualsiasi archiviazione utilizzando i modelli predefiniti forniti per Python (API, Azure Blob Storage, GBQ, GCS, MySQL, S3, Redshift, Snowflake, Delta Lake, ecc.), SQL e R.
Funzionalità chiave
- Adattamento dello schema : Consente agli ingegneri di adattare il formato e lo schema dei dati esportati per soddisfare i requisiti del sistema di destinazione.
- Elaborazione batch e streaming : Il blocco di esportazione dei dati funziona sia in modalità batch che in modalità streaming. Facilita l’elaborazione batch esportando i dati a intervalli predefiniti o in base a trigger specifici. Inoltre, supporta lo streaming in tempo reale dei dati, consentendo il trasferimento continuo e quasi istantaneo dei dati ai sistemi downstream.
- Conformità : Ha funzionalità come la crittografia, il controllo degli accessi e la mascheratura dei dati per proteggere le informazioni riservate durante l’esportazione dei dati.
Dopo la trasformazione dei dati, esportiamo i dati trasformati/elaborati su Google BigQuery utilizzando Data Exporter per l’analisi avanzata. Una volta eseguito il blocco dell’esportatore di dati, il diagramma ad albero qui sotto illustra i passaggi successivi.


Passaggio 3: Anteprima/Analytics
La fase di “Anteprima” consente agli ingegneri dei dati di ispezionare e visualizzare i dati elaborati o intermedi in un determinato punto della pipeline. Offre una preziosa occasione per verificare l’accuratezza delle trasformazioni dei dati, valutare la qualità dei dati e apprendere ulteriori informazioni sui dati.
Durante questa fase, ogni volta che eseguiamo il codice, riceviamo un feedback sotto forma di grafici, tabelle e grafici. Questo feedback ci consente di raccogliere preziose intuizioni e informazioni. Possiamo vedere immediatamente i risultati dall’output del codice con un’interfaccia notebook interattiva. Nella pipeline, ogni blocco di codice genera dati che possiamo versionare, partizionare e catalogare per utilizzi futuri.
Funzionalità chiave
- Visualizzazione dei dati
- Campionamento dei dati
- Valutazione della qualità dei dati
- Validazione dei risultati intermedi
- Sviluppo iterativo
- Debugging e risoluzione dei problemi

Passaggio 4: Lancio
Nella pipeline dei dati, la fase di “Lancio” rappresenta l’ultimo passaggio in cui distribuiamo i dati elaborati in produzione o nei sistemi downstream per ulteriori analisi. Questa fase garantisce che i dati siano diretti alla destinazione appropriata e resi accessibili per gli utilizzi previsti.
Funzionalità chiave
- Implementazione dei dati
- Automazione e pianificazione
- Monitoraggio e segnalazione
- Versionamento e rollback
- Ottimizzazione delle prestazioni
- Gestione degli errori
Puoi distribuire Mage su AWS, GCP o Azure con soli 2 comandi utilizzando i modelli Terraform mantenuti e puoi trasformare set di dati molto grandi direttamente nel tuo data warehouse o tramite integrazione nativa con Spark e operazionalizzare le tue pipeline con monitoraggio, segnalazione ed osservabilità integrati.
Le schermate qui sotto mostrano le esecuzioni totali delle pipeline e il loro stato, come ad esempio “riuscito” o “fallito”, i registri di ogni blocco e il suo livello.



Inoltre, Mage dà priorità alla governance dei dati e alla sicurezza. Fornisce un ambiente sicuro per le operazioni di ingegneria dei dati. Grazie a sofisticati meccanismi di sicurezza integrati come la crittografia end-to-end, i limiti di accesso e le capacità di audit. L’architettura di Mage si basa su rigorose regole di protezione dei dati e sulle migliori pratiche, proteggendo l’integrità e la riservatezza dei dati. Inoltre, puoi applicare casi d’uso del mondo reale e storie di successo che evidenziano il potenziale di Mage in una varietà di settori, tra cui finanza, e-commerce, assistenza sanitaria e altri.
Differenze Varie
| MAGE | ALTRI SOFTWARE |
| Mage è un motore per l’esecuzione di pipeline dati che possono spostare e trasformare i dati. Tali dati possono quindi essere archiviati ovunque (ad es. S3) e utilizzati per addestrare modelli in Sagemaker. | Sagemaker : Sagemaker è un servizio ML completamente gestito utilizzato per addestrare modelli di machine learning. |
| Mage è un tool open source per pipeline dati per l’integrazione e la trasformazione dei dati (ETL). | Fivetran : Fivetran è un’azienda Saas (software-as-a-service) a codice chiuso che fornisce un servizio ETL gestito. |
| Mage è un tool open source per pipeline dati per l’integrazione e la trasformazione dei dati. Il focus di Mage è fornire un’esperienza di sviluppo semplice. | AirByte : AirByte è uno dei principali piattaforme open source ELT che replica i dati da API, applicazioni e database ai data lake, data warehouse e altre destinazioni. |
Conclusioni
In conclusione, gli ingegneri dei dati e gli esperti analitici possono caricare, trasformare, esportare, visualizzare e distribuire in modo efficiente i dati utilizzando le funzionalità di ogni fase del tool Mage e il suo efficiente framework per la gestione e l’elaborazione dei dati. Questa capacità consente di facilitare la presa di decisioni basate sui dati, l’estrazione di informazioni preziose e garantisce la prontezza con i sistemi di produzione o downstream. È ampiamente riconosciuto per le sue capacità all’avanguardia, la scalabilità e una forte attenzione alla governance dei dati, rendendolo un game-changer per l’ingegneria dei dati.
Punti Chiave
- Mage fornisce una pipeline per l’ingegneria dei dati completa, che include l’ingestione, la trasformazione, la visualizzazione e la distribuzione dei dati. Questa piattaforma end-to-end garantisce una rapida elaborazione dei dati, una diffusione efficace dei dati e una connettività senza soluzione di continuità.
- Gli ingegneri dei dati di Mage hanno la capacità di applicare diverse operazioni durante la fase di trasformazione dei dati, garantendo che i dati siano puliti, arricchiti e preparati per l’elaborazione successiva. La fase di visualizzazione consente la convalida e la valutazione della qualità dei dati elaborati, garantendone l’accuratezza e l’affidabilità.
- In tutta la pipeline dell’ingegneria dei dati, Mage dà la priorità all’efficienza e alla scalabilità. Per migliorare le prestazioni, fa uso di tecniche di ottimizzazione come l’elaborazione parallela, la partizione dei dati e la memorizzazione nella cache.
- La fase di lancio di Mage consente il trasferimento senza sforzo dei dati elaborati ai sistemi downstream o di produzione. Dispone di strumenti per l’automazione, la versioning, la risoluzione degli errori e l’ottimizzazione delle prestazioni, fornendo una trasmissione dati affidabile e tempestiva.
Domande Frequenti
I media mostrati in questo articolo non sono di proprietà di Analytics Vidhya e sono utilizzati a discrezione dell’autore.