Gestione della memoria in Apache Spark Disk Spill
Gestione memoria Spark Disk Spill
Cos’è e come gestirlo
Nel mondo del big data, Apache Spark è amato per la sua capacità di elaborare volumi massicci di dati in modo estremamente rapido. Essendo il motore di elaborazione di big data numero uno al mondo, imparare ad utilizzare questo strumento è un fondamento delle competenze di ogni professionista del settore. E un passo importante in questo percorso è comprendere il sistema di gestione della memoria di Spark e le sfide dello “spillamento su disco”.
Lo spillamento su disco avviene quando Spark non riesce più a memorizzare i suoi dati in memoria e ha bisogno di archiviarli su disco. Uno dei principali vantaggi di Spark è la capacità di elaborare in memoria, che è molto più veloce rispetto all’utilizzo di unità a disco. Quindi, creare applicazioni che fanno spillare i dati su disco va in qualche modo contro lo scopo di Spark.
Lo spillamento su disco ha una serie di conseguenze indesiderate, quindi imparare come affrontarlo è una competenza importante per uno sviluppatore Spark. E questo è ciò che questo articolo si propone di aiutare a fare. Approfondiremo cosa è lo spillamento su disco, perché avviene, quali sono le sue conseguenze e come risolverlo. Utilizzando l’interfaccia utente integrata di Spark, impareremo come individuare segni di spillamento su disco e comprenderne le metriche. Infine, esploreremo alcune strategie operative per mitigare lo spillamento su disco, come una partizione dei dati efficace, una memorizzazione nella cache appropriata e una ridimensionamento dinamico del cluster.
Gestione della memoria in Spark
Prima di addentrarci nello spillamento su disco, è utile comprendere come funziona la gestione della memoria in Spark, poiché questo gioca un ruolo cruciale nel modo in cui avviene lo spillamento su disco e come viene gestito.
- Competenze culturali per la gestione del rischio nell’apprendimento automatico
- Una guida completa agli LLM open-source
- Apprendimento automatico, illustrato Apprendimento incrementale
Spark è progettato come un motore di elaborazione di dati in memoria, il che significa che utilizza principalmente la RAM per memorizzare e manipolare i dati anziché fare affidamento sulla memoria di archiviazione del disco. Questa capacità di elaborazione in memoria è una delle caratteristiche chiave che rende Spark veloce ed efficiente.
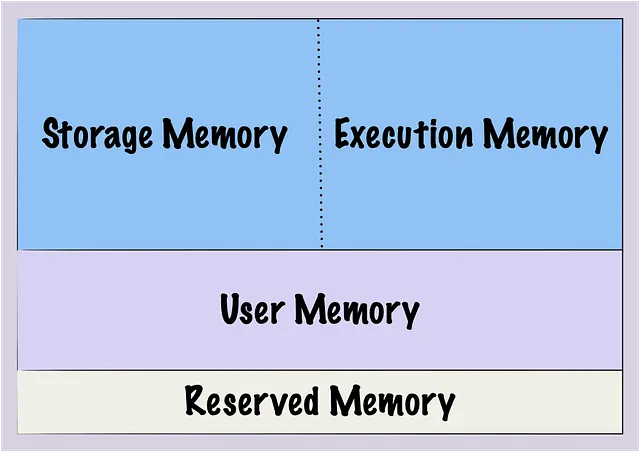
Spark ha una quantità limitata di memoria allocata per le sue operazioni e questa memoria è divisa in diverse sezioni, che compongono ciò che è conosciuto come Memoria Unificata: