Incontra BLIVA un grande modello di linguaggio multimodale per una migliore gestione delle domande visive ricche di testo
Incontra BLIVA, un modello di linguaggio multimodale per gestire domande visive con testo


Recentemente, i Large Language Models (LLMs) hanno svolto un ruolo cruciale nel campo della comprensione del linguaggio naturale, mostrando notevoli capacità di generalizzazione in una vasta gamma di compiti, inclusi scenari di zero-shot e few-shot. I Vision Language Models (VLMs), esemplificati dal GPT-4 di OpenAI nel 2023, hanno dimostrato progressi significativi nell’affrontare compiti di domande e risposte visuali senza limiti, che richiedono a un modello di rispondere a una domanda su un’immagine o un insieme di immagini. Questi avanzamenti sono stati ottenuti integrando LLMs con capacità di comprensione visiva.
Sono state proposte varie metodologie per sfruttare i LLMs per compiti legati alla visione, inclusi l’allineamento diretto con le caratteristiche di una codificatore visivo a patch e l’estrazione di informazioni sull’immagine attraverso un numero fisso di embedding di query.
Tuttavia, nonostante le loro significative capacità nelle interazioni uomo-agente basate sull’immagine, questi modelli incontrano sfide quando si tratta di interpretare il testo all’interno delle immagini. Le immagini contenenti testo sono diffuse nella vita quotidiana e la capacità di comprendere tali contenuti è cruciale per la percezione visiva umana. Ricerche precedenti hanno impiegato un modulo di astrazione con embedding di query, ma questo approccio ha limitato la loro capacità di catturare dettagli testuali all’interno delle immagini.
- Come sta rivoluzionando l’IA la produzione di audiolibri? Creazione di migliaia di audiolibri di alta qualità da e-book con la tecnologia di sintesi vocale neurale.
- Snowflake vs. Data Bricks Competere per creare la migliore piattaforma di dati cloud
- Ricercatori del MIT introducono una nuova attenzione multi-scala leggera per la segmentazione semantica su dispositivo
Nello studio descritto in questo articolo, i ricercatori presentano BLIVA (InstructBLIP con Visual Assistant), un LLM multimodale strategicamente progettato per integrare due componenti chiave: embedding di query appresi strettamente allineati con il LLM stesso ed embedding di patch codificati dell’immagine, che contengono dati relativi all’immagine più estesi. Una panoramica dell’approccio proposto è presentata nella figura seguente.
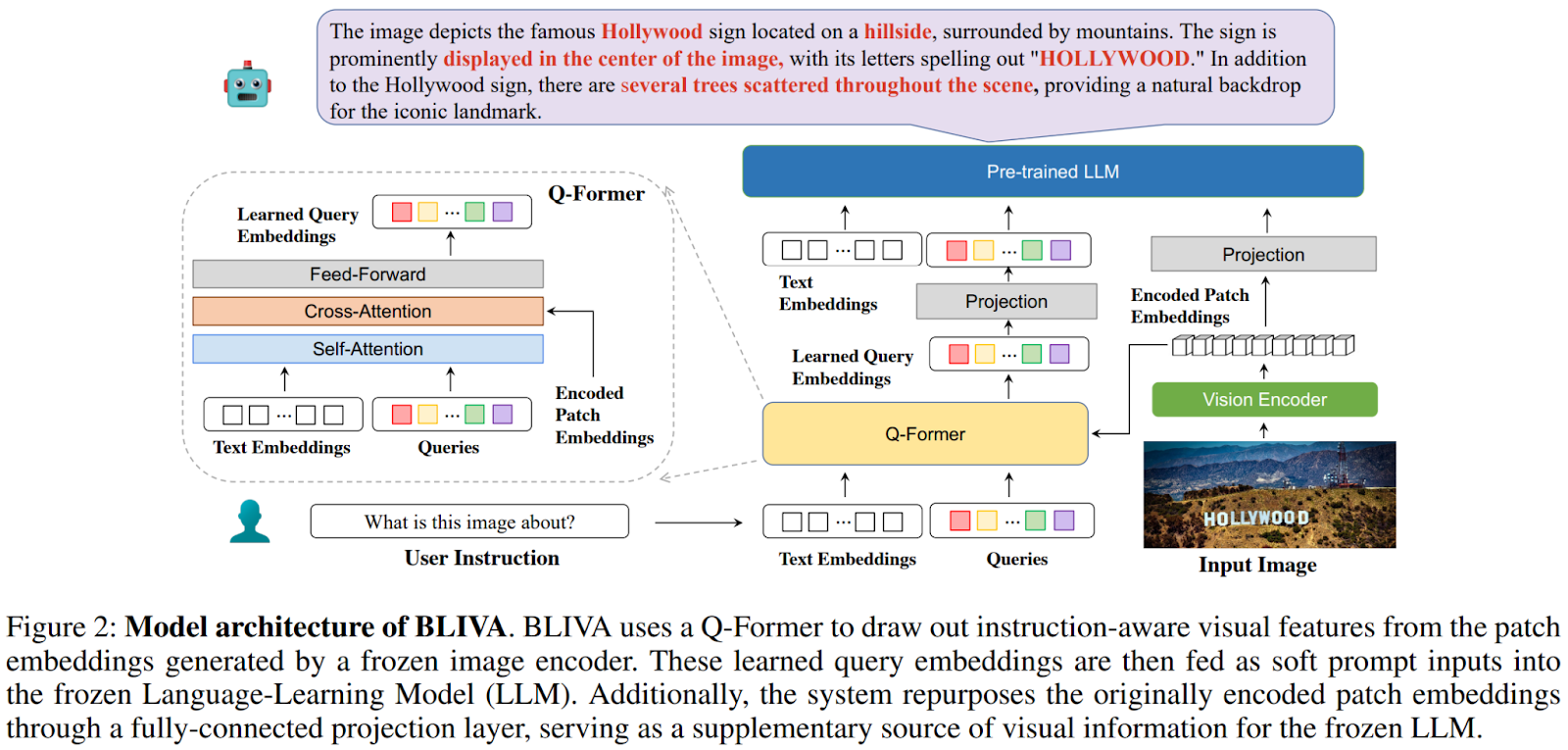
Questa tecnica supera i vincoli tipicamente associati alla fornitura di informazioni sull’immagine ai modelli di linguaggio, portando infine a una percezione e comprensione visiva testo-immagine migliorata. Il modello viene inizializzato utilizzando un InstructBLIP pre-addestrato e un livello di proiezione di patch codificate addestrato da zero. Viene seguito un paradigma di addestramento a due fasi. La fase iniziale prevede il pre-addestramento del livello di proiezione delle embedding di patch e il fine-tuning sia del Q-former che del livello di proiezione delle embedding di patch utilizzando dati di sintonizzazione delle istruzioni. Durante questa fase, sia l’encoder dell’immagine che il LLM rimangono in uno stato congelato, basato su due conclusioni chiave dagli esperimenti: in primo luogo, lo scongelamento dell’encoder della visione porta a un oblio catastrofico delle conoscenze precedenti e, in secondo luogo, l’addestramento simultaneo del LLM non ha portato a miglioramenti ma ha introdotto una significativa complessità di addestramento.
Qui vengono riportati due scenari di esempio presentati dagli autori, che mostrano l’impatto di BLIVA nell’affrontare compiti VQA legati a “Didascalia dettagliata” e “piccola didascalia + VQA”.

Questo è stato il riassunto di BLIVA, un nuovo framework multimodale AI LLM che combina embedding di patch codificati testuali e visivi per affrontare compiti VQA. Se sei interessato e vuoi saperne di più, ti invitiamo a fare riferimento ai link citati di seguito.






