Come sta rivoluzionando l’IA la produzione di audiolibri? Creazione di migliaia di audiolibri di alta qualità da e-book con la tecnologia di sintesi vocale neurale.
L'IA rivoluziona la produzione di audiolibri con la sintesi vocale neurale.


Oggi, molte persone leggono audiolibri invece di libri o altri media. Gli audiolibri non solo permettono ai lettori di godere delle informazioni mentre sono in viaggio, ma possono anche aiutare a rendere il contenuto accessibile a gruppi, tra cui bambini, persone con problemi di vista e chiunque stia imparando una nuova lingua. Le tecniche tradizionali di produzione di audiolibri richiedono tempo e denaro e possono comportare una qualità di registrazione variabile, come la narrazione umana professionale o iniziative basate su volontari come LibriVox. A causa di questi problemi, tenere il passo con il numero crescente di libri pubblicati richiede tempo ed impegno.
Tuttavia, la creazione automatica di audiolibri ha sofferto storicamente a causa della natura robotica dei sistemi di sintesi vocale e della difficoltà nel decidere quali testi non devono essere letti ad alta voce (come tabelle dei contenuti, numeri di pagina, figure e note a piè di pagina). Essi forniscono un metodo per superare le difficoltà sopra menzionate creando audiolibri di alta qualità da varie collezioni di libri online. Il loro approccio incorpora specificamente gli sviluppi recenti nella sintesi vocale neurale, nella lettura espressiva, nel calcolo scalabile e nel riconoscimento automatico di contenuti pertinenti per produrre migliaia di audiolibri dal suono naturale.
Contribuiscono con oltre 5.000 audiolibri del valore di oltre 35.000 ore al software open source. Forniscono inoltre un software dimostrativo che consente ai partecipanti alle conferenze di creare i propri audiolibri leggendo ad alta voce qualsiasi libro della biblioteca utilizzando solo un breve campione audio. Questo lavoro introduce un metodo scalabile per convertire gli e-book basati su HTML in eccellenti audiolibri. SynapseML, una piattaforma di machine learning scalabile che consente l’orchestrazione distribuita dell’intero processo di generazione di audiolibri, è alla base del loro flusso di lavoro. La catena di distribuzione inizia con migliaia di e-book gratuiti forniti da Project Gutenberg. Si occupano principalmente del formato HTML di questi e-book poiché si presta a un parsing automatizzato, il migliore tra tutti i formati disponibili per queste pubblicazioni.
- Snowflake vs. Data Bricks Competere per creare la migliore piattaforma di dati cloud
- Ricercatori del MIT introducono una nuova attenzione multi-scala leggera per la segmentazione semantica su dispositivo
- La ricerca di Google DeepMind esplora il fenomeno misterioso del Grokking nelle reti neurali svelando l’interazione tra memorizzazione e generalizzazione
Come risultato, siamo stati in grado di organizzare e visualizzare l’intera collezione di pagine HTML di Project Gutenberg e individuare molti gruppi consistenti di file con una struttura simile. Le principali classi di e-book sono state trasformate in un formato standard che può essere elaborato automaticamente utilizzando un normalizzatore HTML basato su regole creato utilizzando queste collezioni di file HTML. Grazie a questo approccio, abbiamo sviluppato un sistema in grado di analizzare rapidamente e in modo deterministico un enorme numero di libri. In modo significativo, ci ha permesso di concentrarci sui file che avrebbero prodotto registrazioni di alta qualità quando letti.
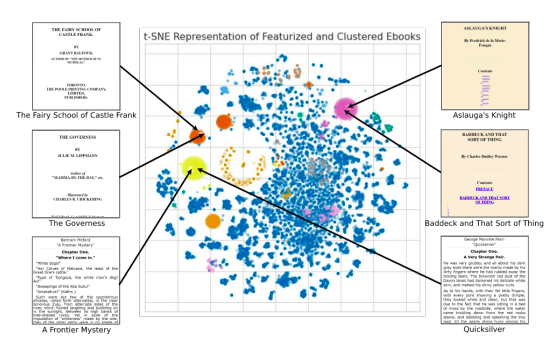
I risultati di questo approccio per il clustering sono mostrati nella Figura 1, che illustra come vari gruppi di libri elettronici organizzati in modo simile si sviluppino spontaneamente nella collezione di Project Gutenberg. Dopo il processo di elaborazione, è possibile estrarre uno stream di testo semplice e alimentarlo agli algoritmi di sintesi vocale. Ci sono molte tecniche di lettura richieste per vari audiolibri. Una voce chiara e oggettiva è la migliore per i libri di saggistica, mentre una lettura espressiva e un po’ di “recitazione” sono migliori per la narrativa con dialoghi. Tuttavia, nella loro dimostrazione dal vivo, offriranno ai clienti l’opzione di modificare la voce, il ritmo, il tono e l’intonazione del testo. Per la maggior parte dei libri, utilizzano una voce chiara e neutrale di sintesi vocale neurale.
Utilizzano tecniche di sintesi vocale “zero-shot” per trasferire in modo efficace le caratteristiche vocali da un piccolo numero di registrazioni registrate per duplicare la voce di un utente. In questo modo, un utente può rapidamente produrre un audiolibro nella propria voce, utilizzando solo un piccolo frammento di audio che è stato registrato. Utilizzano un sistema di inferenza automatica di voce ed emozione per modificare dinamicamente la voce e il tono di lettura in base al contesto al fine di produrre una lettura di testo emotiva. Questo migliora la realismo e l’interesse delle sequenze con più persone e interazioni dinamiche.
Per fare ciò, dividono prima il testo in narrazione e conversazione, assegnando un diverso speaker per ogni riga di dialogo. Quindi, in modo auto-supervisionato, prevedono il tono emotivo di ciascun dialogo. Infine, utilizzano il modello di sintesi vocale neurale basato su multi-stile e contesto per assegnare voci ed emozioni diverse alla narrazione e alle conversazioni dei personaggi. Ritengono che questo approccio possa aumentare significativamente la disponibilità e l’accessibilità degli audiolibri.






