Apprendimento automatico, illustrato Apprendimento incrementale
Apprendimento automatico incrementale
Come i modelli apprendono nuove informazioni nel tempo, mantenendo e ampliando la conoscenza precedente
Benvenuti alla serie Illustrated Machine Learning. Se avete letto gli altri articoli della serie, sapete come funziona. Prendiamo un concetto di machine learning (che può sembrare noioso) e lo rendiamo divertente illustrandolo! Questo articolo tratterà un concetto chiamato Incremental Learning, in cui i modelli di machine learning imparano nuove informazioni nel tempo, mantenendo e ampliando la conoscenza precedente. Ma prima di approfondire questo argomento, parliamo del processo di costruzione del modello come lo conosciamo oggi.
Solitamente seguiamo un processo chiamato apprendimento statico nella costruzione dei modelli. In questo processo, addestriamo un modello utilizzando i dati più recenti disponibili. Modifichiamo e ottimizziamo il modello durante il processo di addestramento. E una volta soddisfatti delle sue prestazioni, lo mettiamo in produzione. Questo modello rimane in produzione per un po’ di tempo. Poi ci accorgiamo che le prestazioni del modello peggiorano nel tempo. È a quel punto che scartiamo il modello esistente e ne costruiamo uno nuovo utilizzando i dati più recenti disponibili. E ripetiamo questo stesso processo.
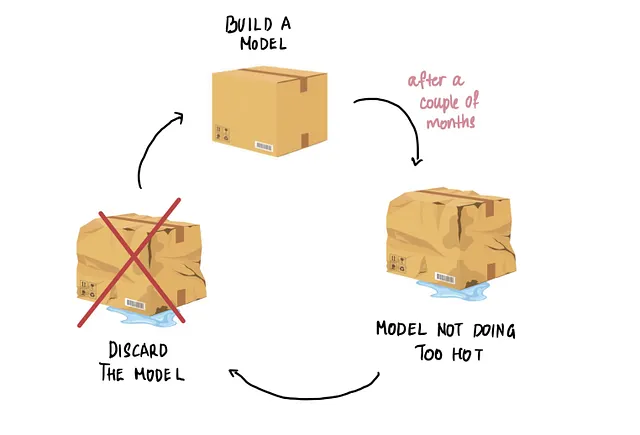
Illustreremo questo concetto con un esempio concreto. Consideriamo questa situazione ipotetica. Abbiamo iniziato a costruire un modello di rilevazione delle frodi alla fine di gennaio 2023. Questo modello individua se una transazione con carta di credito è fraudolenta o meno. Addestriamo il nostro modello utilizzando tutti i dati delle transazioni con carta di credito che abbiamo raccolto nel periodo di un anno precedente (gennaio 2022 – dicembre 2022) e utilizziamo i dati delle transazioni di questo mese (gennaio 2023) per testare il modello.
- 3 Metodi Semplici Per Migliorare Il Tuo Grande Modello Linguistico
- Tecniche di caccia alle minacce di nuova generazione con integrazione SIEM-SOAR
- Come ottenere un lavoro in Data Science come studente
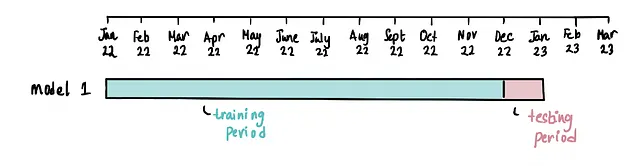
Alla fine del mese successivo, ci accorgiamo che il modello non si comporta bene con i nuovi dati. Quindi costruiamo un altro modello, ma questa volta utilizziamo i dati del periodo di un anno precedente (febbraio 2022 – gennaio 2023) per addestrarlo e poi utilizziamo i dati del mese corrente (febbraio 2023) per testarlo. Tutti i dati al di fuori di questi periodi di addestramento e test vengono scartati.






