Come Forethought risparmia oltre il 66% dei costi per i modelli di intelligenza artificiale generativi utilizzando Amazon SageMaker.
Forethought saves over 66% on generative AI model costs using Amazon SageMaker.
Questo post è stato scritto in collaborazione con Jad Chamoun, Direttore dell’Ingegneria presso Forethought Technologies, Inc. e Salina Wu, Ingegnere Senior di ML presso Forethought Technologies, Inc.
Forethought è una suite di intelligenza artificiale generativa leader nel servizio clienti. Al centro della sua suite si trova l’innovativa tecnologia SupportGPT™ che utilizza il machine learning per trasformare il ciclo di supporto al cliente, aumentando la deflessione, migliorando il CSAT e aumentando la produttività degli agenti. SupportGPT™ sfrutta i sistemi di recupero delle informazioni di ultima generazione (IR) e i grandi modelli linguistici (LLM) per alimentare oltre 30 milioni di interazioni con i clienti ogni anno.

Il caso d’uso principale di SupportGPT è quello di migliorare la qualità e l’efficienza delle interazioni e delle operazioni di supporto al cliente. Utilizzando i sistemi IR all’avanguardia alimentati da modelli di embedding e di ranking, SupportGPT può cercare rapidamente informazioni pertinenti, fornendo risposte accurate e concise alle richieste dei clienti. Forethought utilizza modelli per cliente sintonizzati perfettamente per rilevare le intenzioni dei clienti al fine di risolvere le interazioni con i clienti. L’integrazione di grandi modelli linguistici aiuta ad umanizzare l’interazione con gli agenti automatizzati, creando un’esperienza di supporto più coinvolgente e soddisfacente.
- AI Time Journal presenta un innovativo eBook sulle tendenze dell’AI nel 2023.
- Linee guida per l’era della guerra dell’AI.
- Robot di consegna di cibo Uber Eats pronti per l’uso in molte città degli Stati Uniti.
SupportGPT assiste anche gli agenti di supporto al cliente offrendo suggerimenti di completamento automatico e creando risposte adeguate ai ticket dei clienti che si allineano con l’azienda in base alle risposte precedenti. Utilizzando i modelli di linguaggio avanzati, gli agenti possono affrontare le preoccupazioni dei clienti in modo più rapido e preciso, ottenendo un maggiore grado di soddisfazione dei clienti.
Inoltre, l’architettura di SupportGPT consente di individuare lacune nelle basi di conoscenza del supporto, il che aiuta gli agenti a fornire informazioni più accurate ai clienti. Una volta identificate queste lacune, SupportGPT può generare automaticamente articoli e altri contenuti per colmare questi vuoti di conoscenza, garantendo che la base di conoscenza di supporto rimanga centrata sui clienti e aggiornata.
In questo post, condivideremo come Forethought utilizza i punti finali multi-modello di Amazon SageMaker nei casi d’uso di intelligenza artificiale generativa per risparmiare oltre il 66% dei costi.
Sfide infrastrutturali
Per aiutare a portare queste capacità sul mercato, Forethought scala efficientemente i suoi carichi di lavoro di ML e fornisce soluzioni iper-personalizzate su misura per ciascun caso d’uso specifico del cliente. Questa iper-personalizzazione è ottenuta attraverso il sintonizzazione fine dei modelli di embedding e dei classificatori sui dati dei clienti, garantendo risultati precisi di recupero delle informazioni e conoscenze di dominio che soddisfano le esigenze uniche di ciascun cliente. Anche i modelli di completamento automatico personalizzati sono sintonizzati sui dati dei clienti per migliorare ulteriormente l’accuratezza e la pertinenza delle risposte generate.
Una delle sfide significative nel processamento dell’IA è l’utilizzo efficiente delle risorse hardware come le GPU. Per affrontare questa sfida, Forethought utilizza i punti finali multi-modello (MME) di SageMaker per eseguire più modelli di IA su un singolo punto finale di inferenza e scalare. Poiché l’iper-personalizzazione dei modelli richiede modelli unici da addestrare e distribuire, il numero di modelli scala linearmente con il numero di clienti, il che può diventare costoso.
Per ottenere il giusto equilibrio di prestazioni per l’inferenza in tempo reale e il costo, Forethought ha scelto di utilizzare i punti finali MME di SageMaker, che supportano l’accelerazione GPU. I punti finali MME di SageMaker consentono a Forethought di fornire soluzioni ad alte prestazioni, scalabili ed economiche con latenza inferiore al secondo, affrontando numerosi scenari di supporto ai clienti su larga scala.
SageMaker e Forethought
SageMaker è un servizio completamente gestito che fornisce ai developer e ai data scientist la possibilità di creare, formare e distribuire modelli di ML rapidamente. I punti finali multi-modello di SageMaker forniscono una soluzione scalabile ed economica per la distribuzione di un gran numero di modelli per l’inferenza in tempo reale. I punti finali MME utilizzano un contenitore di servizio condiviso e una flotta di risorse che possono utilizzare istanze accelerate come le GPU per ospitare tutti i tuoi modelli. Ciò riduce i costi di hosting massimizzando l’utilizzo del punto finale rispetto all’utilizzo dei punti finali a singolo modello. Inoltre, riduce gli oneri di distribuzione perché SageMaker gestisce il caricamento e lo scaricamento dei modelli in memoria e la loro scalabilità in base ai modelli di traffico del punto finale. Inoltre, tutti i punti finali in tempo reale di SageMaker beneficiano delle capacità integrate per gestire e monitorare i modelli, come la gestione delle varianti ombra, la scalabilità automatica e l’integrazione nativa con Amazon CloudWatch (per ulteriori informazioni, fare riferimento alle metriche di CloudWatch per le distribuzioni di punti finali multi-modello).
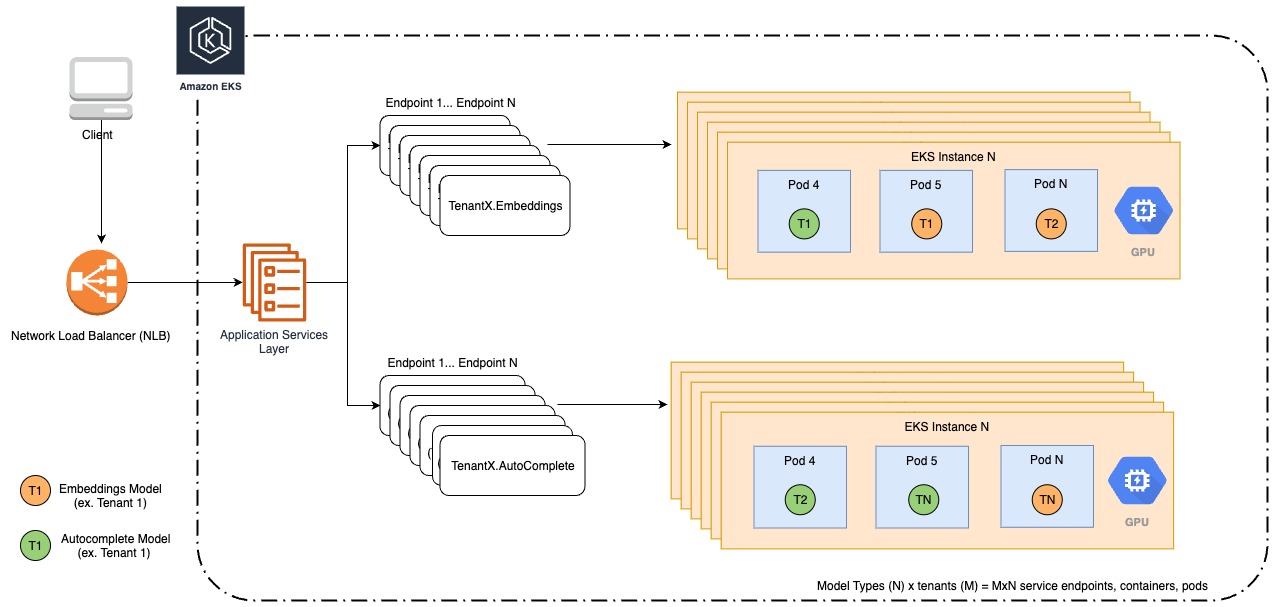
Quando Forethought è cresciuta ospitando centinaia di modelli che richiedevano anche risorse GPU, abbiamo visto l’opportunità di creare un’architettura più economica, affidabile e gestibile tramite i punti finali MME di SageMaker. Prima di migrare ai punti finali MME di SageMaker, i nostri modelli erano distribuiti su Kubernetes su Amazon Elastic Kubernetes Service (Amazon EKS). Anche se Amazon EKS forniva capacità di gestione, è stato immediatamente evidente che stavamo gestendo un’infrastruttura che non era specificamente progettata per l’inferenza. Forethought doveva gestire l’inferenza del modello su Amazon EKS da sola, il che rappresentava un onere per l’efficienza dell’ingegneria. Ad esempio, per condividere le costose risorse GPU tra più modelli, eravamo responsabili dell’allocazione di frazioni di memoria rigide ai modelli specificati durante la distribuzione. Volevamo affrontare i seguenti problemi chiave della nostra infrastruttura esistente:
- Costi elevati – Per garantire che ogni modello avesse abbastanza risorse, eravamo molto conservativi nel numero di modelli da adattare per ogni istanza. Ciò ha comportato costi di hosting del modello molto più elevati del necessario.
- Bassa affidabilità – Nonostante fossimo conservativi nell’allocazione della memoria, non tutti i modelli hanno gli stessi requisiti e occasionalmente alcuni modelli generavano errori di memoria esaurita (OOM).
- Gestione inefficiente – Dovevamo gestire diversi manifesti di distribuzione per ogni tipo di modello (come classificatori, embedding e completamento automatico), il che richiedeva tempo ed era soggetto a errori. Dovevamo anche mantenere la logica per determinare l’allocazione della memoria per diversi tipi di modello.
In definitiva, avevamo bisogno di una piattaforma di inferenza per gestire il lavoro pesante dei nostri modelli in tempo reale per migliorare il costo, l’affidabilità e la gestione del servizio dei nostri modelli. SageMaker MME ci ha permesso di soddisfare queste esigenze.
Grazie al suo caricamento e scaricamento intelligente e dinamico dei modelli e alle sue capacità di scalabilità, SageMaker MME ha fornito una soluzione significativamente meno costosa e più affidabile per l’hosting dei nostri modelli. Ora siamo in grado di adattare molti più modelli per ogni istanza e non dobbiamo preoccuparci degli errori OOM poiché SageMaker MME gestisce il caricamento e lo scaricamento dei modelli in modo dinamico. Inoltre, le distribuzioni sono ora semplici come chiamare le API SageMaker di Boto3 e allegare le politiche di autoscaling appropriate.
Il seguente diagramma illustra la nostra architettura legacy.
Per iniziare la nostra migrazione a SageMaker MME, abbiamo identificato i migliori casi d’uso per MME e quali dei nostri modelli avrebbero beneficiato maggiormente di questo cambiamento. MME sono meglio utilizzati per i seguenti casi:
- Modelli che si prevede abbiano una bassa latenza ma possono resistere a un tempo di avvio a freddo (quando viene caricato per la prima volta)
- Modelli che vengono chiamati spesso e in modo consistente
- Modelli che richiedono risorse parziali della GPU
- Modelli che condividono requisiti comuni e logica di inferenza
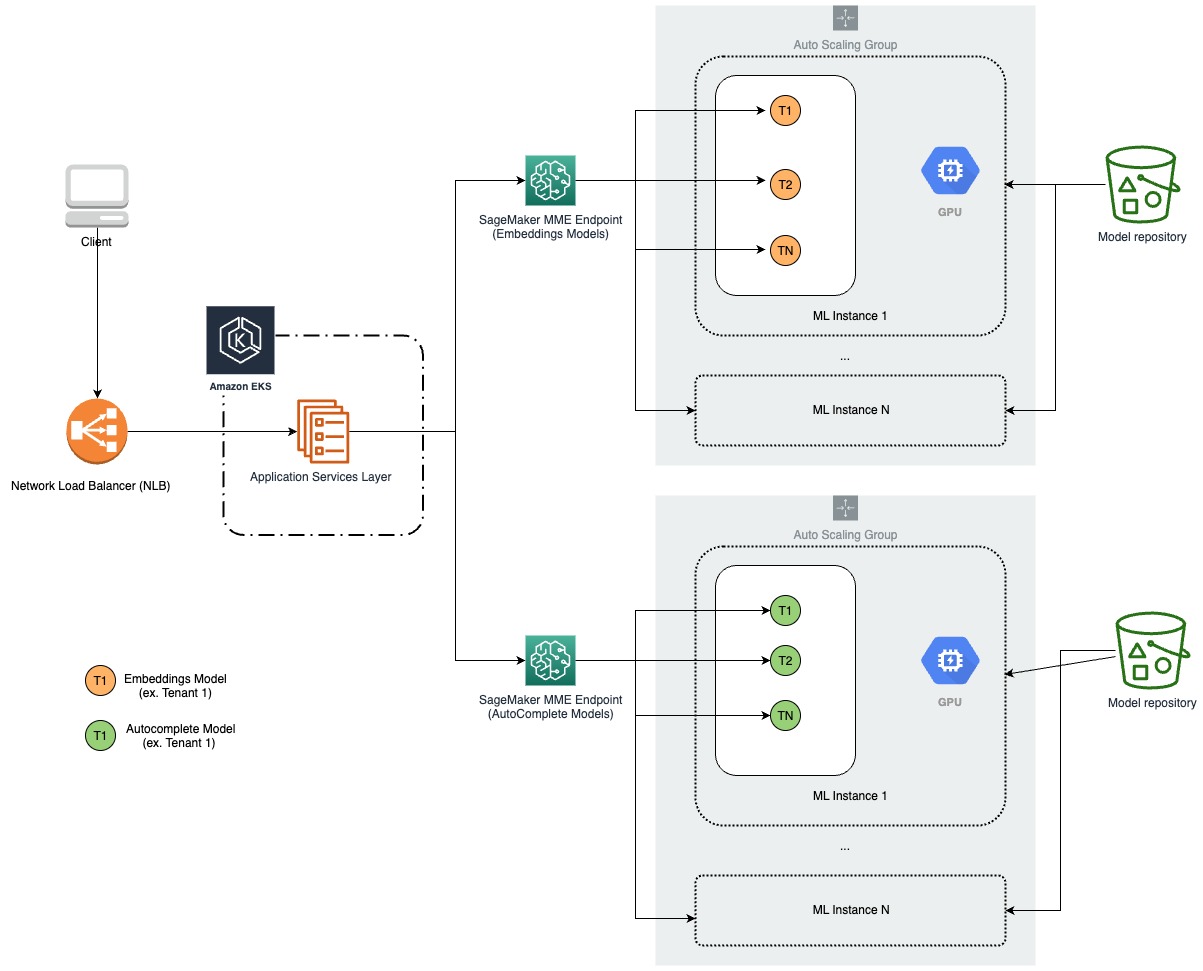
Abbiamo identificato i nostri modelli di embedding e i modelli di lingua di completamento automatico come i migliori candidati per la nostra migrazione. Per organizzare questi modelli sotto MME, creeremmo un MME per tipo di modello o attività, uno per i nostri modelli di embedding e un altro per i modelli di lingua di completamento automatico.
Già avevamo uno strato API sopra i nostri modelli per la gestione e l’inferenza dei modelli. Il nostro compito era di ripensare come questo API stava distribuendo e gestendo l’inferenza sui modelli sotto il cofano con SageMaker, con modifiche minime a come i clienti e i team di prodotto interagivano con l’API. Dovevamo anche imballare i nostri modelli e la logica di inferenza personalizzata per essere compatibili con NVIDIA Triton Inference Server utilizzando SageMaker MME.
Il seguente diagramma illustra la nostra nuova architettura.
Logica di inferenza personalizzata
Prima di migrare a SageMaker, il codice di inferenza personalizzato di Forethought (preelaborazione e post-elaborazione) veniva eseguito nello strato API quando veniva invocato un modello. L’obiettivo era trasferire questa funzionalità al modello stesso per chiarire la separazione delle responsabilità, modularizzare e semplificare il loro codice e ridurre il carico sull’API.
Embedding
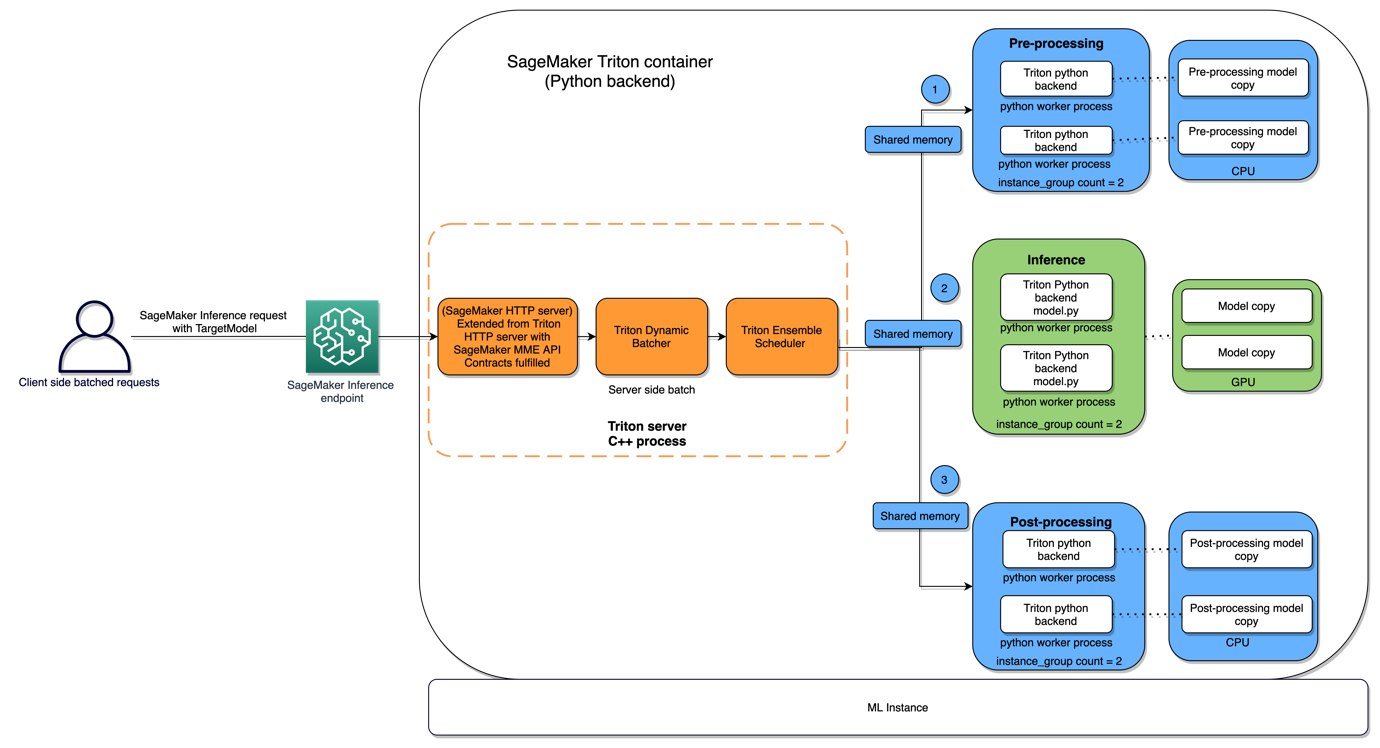
I modelli di embedding di Forethought consistono in due artefatti di modello PyTorch, e la richiesta di inferenza determina quale modello chiamare. Ogni modello richiede testo preelaborato come input. Le principali sfide consistevano nell’integrare una fase di preelaborazione e nell’accomodare due artefatti di modello per definizione di modello. Per affrontare la necessità di più fasi nella logica di inferenza, Forethought ha sviluppato un modello di ensemble Triton con due fasi: un processo di preelaborazione di backend Python e una chiamata di modello di backend PyTorch. I modelli di ensemble consentono di definire e ordinare le fasi nella logica di inferenza, con ogni fase rappresentata da un modello Triton di qualsiasi tipo di backend. Per garantire la compatibilità con il backend PyTorch di Triton, gli artefatti di modello esistenti sono stati convertiti nel formato TorchScript. Sono stati creati modelli Triton separati per ciascuna definizione di modello, e lo strato API di Forethought era responsabile della determinazione del TargetModel appropriato da invocare in base alla richiesta in arrivo.
Completamento automatico
I modelli di completamento automatico (sequenza a sequenza) presentavano un insieme distinto di requisiti. In particolare, dovevamo abilitare la capacità di scorrere attraverso più chiamate di modello e memorizzare nella cache input sostanziali per ogni chiamata, il tutto mantenendo una bassa latenza. Inoltre, questi modelli richiedevano sia fasi di preelaborazione che di post-elaborazione. Per affrontare queste esigenze e raggiungere la flessibilità desiderata, Forethought ha sviluppato modelli MME di completamento automatico utilizzando il backend Python di Triton, che offre il vantaggio di scrivere il modello come codice Python.
Benchmarking
Dopo aver determinato le forme dei modelli Triton, abbiamo distribuito i modelli su endpoint di staging e condotto benchmarking delle risorse e delle prestazioni. Il nostro obiettivo principale era determinare la latenza per i modelli iniziali rispetto a quelli in memoria e come la latenza era influenzata dalla dimensione della richiesta e dalla concorrenza. Volevamo anche sapere quanti modelli potevamo ospitare su ciascuna istanza, quanti modelli avrebbero causato l’espansione delle istanze con la nostra politica di auto scaling e quanto rapidamente sarebbe avvenuta l’espansione. In linea con i tipi di istanze che stavamo già usando, abbiamo fatto il benchmarking con le istanze ml.g4dn.xlarge e ml.g4dn.2xlarge.
Risultati
La seguente tabella riassume i nostri risultati.
| Dimensione della richiesta | Latenza iniziale | Latenza di inferenza memorizzata nella cache | Latenza concorrente (5 richieste) |
| Piccola (30 token) | 12,7 secondi | 0,03 secondi | 0,12 secondi |
| Nisoo (250 token) | 12,7 secondi | 0,05 secondi | 0,12 secondi |
| Grande (550 token) | 12,7 secondi | 0,13 secondi | 0,12 secondi |
Notevolmente, la latenza per le richieste iniziali è significativamente più alta della latenza per le richieste di inferenza memorizzate nella cache. Ciò è dovuto al fatto che il modello deve essere caricato da disco o da Amazon Simple Storage Service (Amazon S3) quando viene effettuata una richiesta iniziale. La latenza per le richieste concorrenti è anche più alta della latenza per le richieste singole. Ciò è dovuto al fatto che il modello deve essere condiviso tra le richieste concorrenti, il che può portare a conflitti.
La seguente tabella confronta la latenza dei modelli legacy e dei modelli SageMaker.
| Dimensione della richiesta | Modelli legacy | Modelli SageMaker |
| Piccola (30 token) | 0,74 secondi | 0,24 secondi |
| Nisoo (250 token) | 0,74 secondi | 0,24 secondi |
| Grande (550 token) | 0,80 secondi | 0,32 secondi |
In generale, i modelli SageMaker sono una scelta migliore per l’hosting di modelli di completamento automatico rispetto ai modelli legacy. Offrono una latenza inferiore, scalabilità, affidabilità e sicurezza.
Utilizzo delle risorse
Nella nostra ricerca per determinare il numero ottimale di modelli che potevano essere ospitati su ciascuna istanza, abbiamo condotto una serie di test. Il nostro esperimento consisteva nel caricare i modelli nei nostri endpoint utilizzando un tipo di istanza ml.g4dn.xlarge, senza alcuna politica di auto scaling.
Queste particolari istanze offrono 15,5 GB di memoria, e miravamo ad ottenere circa l’80% di utilizzo della memoria GPU per istanza. Considerando le dimensioni di ciascun artefatto del modello di encoder, siamo riusciti a trovare il numero ottimale di encoder Triton da caricare su un’istanza per raggiungere il nostro obiettivo di utilizzo della memoria GPU. Inoltre, dato che ciascuno dei nostri modelli di embedding corrisponde a due modelli di encoder Triton, siamo stati in grado di ospitare un numero definito di modelli di embedding per istanza. Di conseguenza, abbiamo calcolato il numero totale di istanze necessarie per servire tutti i nostri modelli di embedding. Questa sperimentazione è stata cruciale nell’ottimizzazione del nostro utilizzo delle risorse e nell’aumento dell’efficienza dei nostri modelli.
Abbiamo effettuato benchmarking simili per i nostri modelli di autocompletamento. Questi modelli erano di circa 292,0 MB ciascuno. Mentre testavamo quanti modelli sarebbero stati in grado di adattarsi su un singolo istanza ml.g4dn.xlarge, abbiamo notato che eravamo in grado di adattare solo quattro modelli prima che la nostra istanza iniziasse a scaricare i modelli, nonostante le dimensioni ridotte dei modelli. Le nostre principali preoccupazioni erano:
- Causa dell’aumento dell’utilizzo della memoria della CPU
- Causa della rimozione dei modelli quando abbiamo provato a caricare un modello in più invece del solo modello utilizzato meno recentemente (LRU)
Siamo stati in grado di individuare la causa principale dell’aumento dell’utilizzo della memoria dalla CPU derivante dall’inizializzazione del nostro ambiente di runtime CUDA nel nostro modello Python, il che era necessario per spostare i nostri modelli e dati sul e dal dispositivo GPU. CUDA carica molte dipendenze esterne nella memoria della CPU quando il runtime è inizializzato. Poiché l’interfaccia posteriore di Triton PyTorch gestisce e astrae lo spostamento dei dati sul e dal dispositivo GPU, non abbiamo avuto problemi per i nostri modelli di embedding. Per affrontare questo problema, abbiamo provato a utilizzare istanze ml.g4dn.2xlarge, che avevano la stessa quantità di memoria GPU ma il doppio della memoria CPU. Inoltre, abbiamo aggiunto diverse ottimizzazioni minori nel nostro codice di backend Python, tra cui l’eliminazione dei tensori dopo l’uso, lo svuotamento della cache, la disabilitazione dei gradienti e la pulizia dei rifiuti. Con il tipo di istanza più grande, siamo riusciti a adattare 10 modelli per istanza e l’utilizzo della memoria della CPU e della GPU è diventato molto più allineato.
Il seguente diagramma illustra questa architettura.
Auto scaling
Abbiamo collegato le politiche di autoscaling sia alle nostre embedding che alle nostre MME di autocompletamento. La nostra politica per il nostro endpoint di embedding ha mirato all’80% di utilizzo medio della memoria GPU utilizzando metriche personalizzate. I nostri modelli di autocompletamento hanno visto un modello di traffico elevato durante le ore di lavoro e un traffico minimo durante la notte. Per questo motivo, abbiamo creato una politica di autoscaling basata su InvocationsPerInstance in modo da poter scalare in base ai modelli di traffico, risparmiando sui costi senza sacrificare la affidabilità. Sulla base del nostro benchmarking dell’utilizzo delle risorse, abbiamo configurato le nostre politiche di scaling con un target di 225 InvocationsPerInstance.
Deploy logic e pipeline
Creare un MME su SageMaker è semplice e simile alla creazione di qualsiasi altro endpoint su SageMaker. Dopo la creazione dell’endpoint, l’aggiunta di modelli aggiuntivi all’endpoint è semplice come spostare l’artefatto del modello nel percorso S3 al quale l’endpoint punta; a questo punto, possiamo fare richieste di inferenza al nostro nuovo modello.
Abbiamo definito la logica che avrebbe preso i metadati del modello, formattato l’endpoint in modo deterministico in base ai metadati e verificato se l’endpoint esisteva. Se non esisteva, creavamo l’endpoint e aggiungevamo l’artefatto del modello Triton al percorso S3 per l’endpoint (formattato in modo deterministico). Ad esempio, se i metadati del modello indicavano che si tratta di un modello di autocompletamento, sarebbe stato creato un endpoint per i modelli di autocompletamento e un percorso S3 associato per gli artefatti del modello di autocompletamento. Se l’endpoint esisteva, avremmo copiato l’artefatto del modello nel percorso S3.
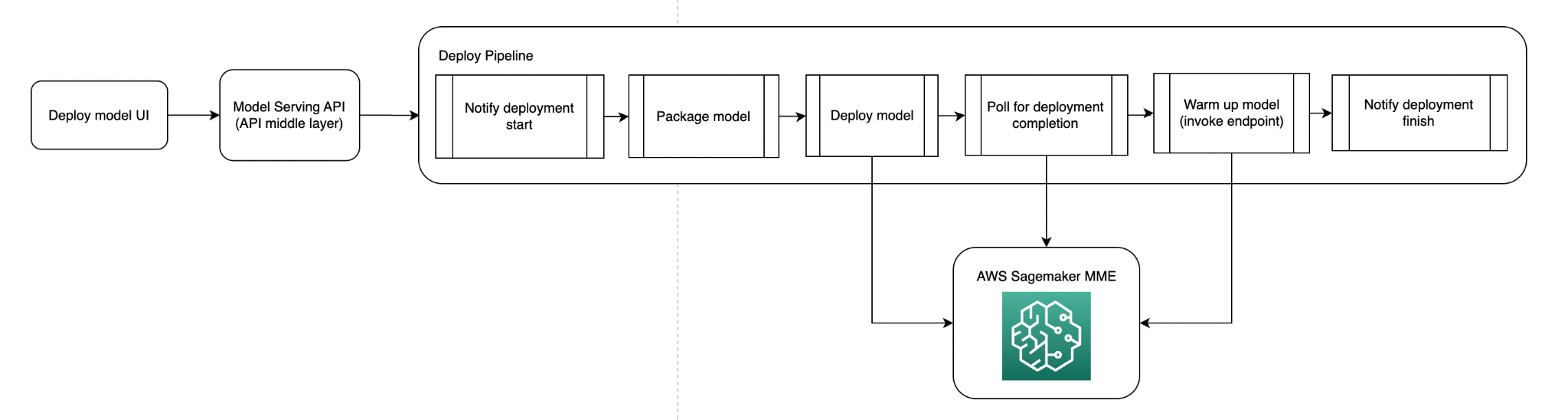
Ora che avevamo le forme dei nostri modelli MME e la funzionalità per distribuire i nostri modelli su MME, avevamo bisogno di un modo per automatizzare il deployment. I nostri utenti devono specificare quale modello vogliono distribuire; noi ci occupiamo del packaging e del deployment del modello. Il codice di inferenza personalizzato confezionato con il modello è versionato e spinto su Amazon S3; nella fase di confezionamento, tiriamo fuori il codice di inferenza in base alla versione specificata (o l’ultima versione) e utilizziamo i file YAML che indicano le strutture dei modelli Triton.
Un requisito per noi era che tutti i nostri modelli MME sarebbero stati caricati in memoria per evitare eventuali latenze di avvio a freddo durante le richieste di inferenza di produzione per caricare i modelli. Per ottenere questo, abbiamo allocato abbastanza risorse per adattare tutti i nostri modelli (in base al benchmarking precedente) e abbiamo chiamato ogni modello nel nostro MME a un cadenza oraria.
Il seguente diagramma illustra la pipeline di deployment del modello.
Il seguente diagramma illustra la pipeline di warm-up del modello.

Invocazione del modello
La nostra attuale API fornisce un’astrazione per i chiamanti per effettuare inferenze su tutti i nostri modelli di ML. Ciò significava che dovevamo solo aggiungere la funzionalità all’API per chiamare SageMaker MME con il modello di destinazione corretto a seconda della richiesta di inferenza, senza alcuna modifica al codice di chiamata. Il codice di inferenza SageMaker prende la richiesta di inferenza, formatta gli input di Triton definiti nei nostri modelli di Triton e invoca gli MME utilizzando Boto3.
Benefici di costo
Forethought ha compiuto progressi significativi nella riduzione dei costi di hosting del modello e nella mitigazione degli errori OOM del modello, grazie alla migrazione verso SageMaker MME. Prima di questo cambiamento, venivano utilizzate istanze ml.g4dn.xlarge in esecuzione in Amazon EKS. Con la transizione verso MME, abbiamo scoperto che potevamo ospitare 12 modelli di embedding per istanza, raggiungendo l’utilizzo dell’80% della memoria GPU. Ciò ha portato a una significativa diminuzione delle nostre spese mensili. Per metterlo in prospettiva, abbiamo realizzato un risparmio di costi fino all’80%. Inoltre, per gestire un traffico più elevato, abbiamo considerato di aumentare le repliche. Supponendo uno scenario in cui impieghiamo tre repliche, abbiamo scoperto che il nostro risparmio di costi sarebbe comunque sostanziale, attestandosi intorno al 43%.
Il percorso con SageMaker MME si è dimostrato finanziariamente vantaggioso, riducendo le nostre spese garantendo al contempo un’ottimale prestazione del modello. In precedenza, i nostri modelli di lingua di completamento automatico erano distribuiti in Amazon EKS, richiedendo un numero variabile di istanze ml.g4dn.xlarge in base all’allocazione di memoria per modello. Ciò ha comportato un considerevole costo mensile. Tuttavia, con la nostra recente migrazione a SageMaker MME, siamo stati in grado di ridurre sostanzialmente questi costi. Ora ospitiamo tutti i nostri modelli su istanze ml.g4dn.2xlarge, dando la possibilità di impacchettare i modelli in modo più efficiente. Ciò ha ridotto significativamente le nostre spese mensili e abbiamo ora realizzato un risparmio di costi nel range del 66-74%. Questa mossa ha dimostrato come l’utilizzo efficiente delle risorse possa portare a significativi risparmi finanziari utilizzando SageMaker MME.
Conclusione
In questo post, abbiamo esaminato come Forethought utilizza i punti finali multi-modello di SageMaker per ridurre i costi per l’inferenza in tempo reale. SageMaker si occupa del sollevamento pesante indifferenziato, in modo che Forethought possa aumentare l’efficienza dell’ingegneria. Consente inoltre a Forethought di abbassare drasticamente il costo per l’inferenza in tempo reale mantenendo le prestazioni necessarie per le operazioni critiche per l’attività. In questo modo, Forethought è in grado di fornire un’offerta differenziata per i propri clienti utilizzando modelli iper-personalizzati. Utilizza SageMaker MME per ospitare i tuoi modelli su larga scala e ridurre i costi di hosting migliorando l’utilizzo del punto finale. Riduce anche l’overhead di distribuzione perché Amazon SageMaker gestisce il caricamento dei modelli in memoria e ne scala le dimensioni in base ai modelli di traffico del tuo punto finale. Puoi trovare esempi di codice per l’hosting di più modelli utilizzando SageMaker MME su GitHub.






