Rivoluzionare l’esperienza dei dati Utilizzare l’AI generativa e una moderna architettura dei dati per sbloccare le intuizioni.
Revolutionize data experience using generative AI and modern data architecture to unlock insights.
Implementare una moderna architettura dei dati fornisce un metodo scalabile per integrare dati provenienti da fonti disparate. Organizzando i dati per domini di business invece che per infrastruttura, ogni dominio può scegliere gli strumenti che meglio si adattano alle proprie esigenze. Le organizzazioni possono massimizzare il valore della loro moderna architettura dei dati con soluzioni di AI generativa, innovando continuamente.
Le capacità di linguaggio naturale consentono agli utenti non tecnici di interrogare i dati attraverso l’inglese conversazionale invece del complesso SQL. Tuttavia, per ottenere tutti i benefici, è necessario superare alcune sfide. I modelli di AI e di linguaggio devono identificare le fonti di dati appropriate, generare efficaci query SQL e produrre risposte coerenti con risultati incorporati su larga scala. Hanno anche bisogno di un’interfaccia utente per le domande in linguaggio naturale.
In generale, l’implementazione di una moderna architettura dei dati e di tecniche di AI generativa con AWS è un approccio promettente per raccogliere e diffondere informazioni chiave da dati diversi ed estesi a livello aziendale. La più recente offerta di AI generativa di AWS è Amazon Bedrock, che è un servizio completamente gestito e il modo più semplice per creare e scalare le applicazioni di AI generativa con modelli di base. AWS offre anche modelli di base attraverso Amazon SageMaker JumpStart come endpoint di Amazon SageMaker. La combinazione di grandi modelli di linguaggio (LLM), inclusa la facilità di integrazione offerta da Amazon Bedrock, e di un’infrastruttura dati scalabile e orientata ai domini, posiziona questa come un metodo intelligente per sfruttare l’abbondante informazione contenuta in vari database di analisi e data lake.
Nel post, mostriamo uno scenario in cui un’azienda ha implementato una moderna architettura dei dati con dati residenti su database multipli e API come dati legali su Amazon Simple Storage Service (Amazon S3), risorse umane su Amazon Relational Database Service (Amazon RDS), vendite e marketing su Amazon Redshift, dati di mercato finanziario su una soluzione di data warehouse di terze parti su Snowflake e dati di prodotto come API. Questa implementazione mira a migliorare la produttività dell’analisi aziendale, dei proprietari di prodotto e degli esperti di business del dominio dell’azienda. Tutto ciò è stato realizzato attraverso l’uso di AI generativa in questa architettura di mesh del dominio, che consente all’azienda di raggiungere i propri obiettivi aziendali in modo più efficiente. Questa soluzione ha l’opzione di includere LLM da JumpStart come endpoint di SageMaker, così come modelli di terze parti. Forniamo agli utenti aziendali un modo di fare domande basate sui fatti senza avere una conoscenza sottostante dei canali dati, astrae quindi le complessità della scrittura di query SQL semplici o complesse.
- Clustering differenzialmente privato per dataset di grandi dimensioni.
- Intelligenza Artificiale Probabilistica che Sa Quanto Bene Sta Funzionando.
- Organizzazione dei dati non strutturati
Panoramica della soluzione
Una moderna architettura dei dati su AWS applica intelligenza artificiale e elaborazione del linguaggio naturale per interrogare più database di analisi. Utilizzando servizi come Amazon Redshift, Amazon RDS, Snowflake, Amazon Athena e AWS Glue, crea una soluzione scalabile per integrare dati provenienti da varie fonti. Utilizzando LangChain, una potente libreria per lavorare con LLM, inclusi i modelli di base di Amazon Bedrock e JumpStart in quaderni di SageMaker Studio, viene creato un sistema in cui gli utenti possono fare domande aziendali in inglese naturale e ricevere risposte con dati estratti dai database pertinenti.
Il seguente diagramma illustra l’architettura.
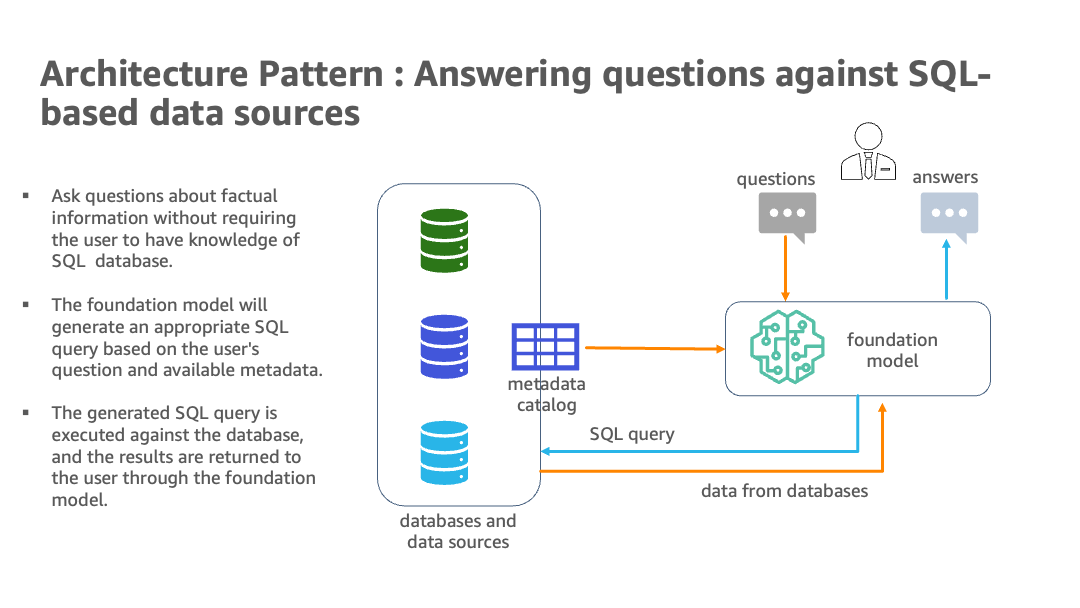
L’architettura ibrida utilizza più database e LLM, con modelli di base di Amazon Bedrock e JumpStart per l’identificazione delle fonti di dati, la generazione di SQL e la generazione di testo con risultati.
Il seguente diagramma illustra i passaggi specifici del flusso di lavoro per la nostra soluzione.
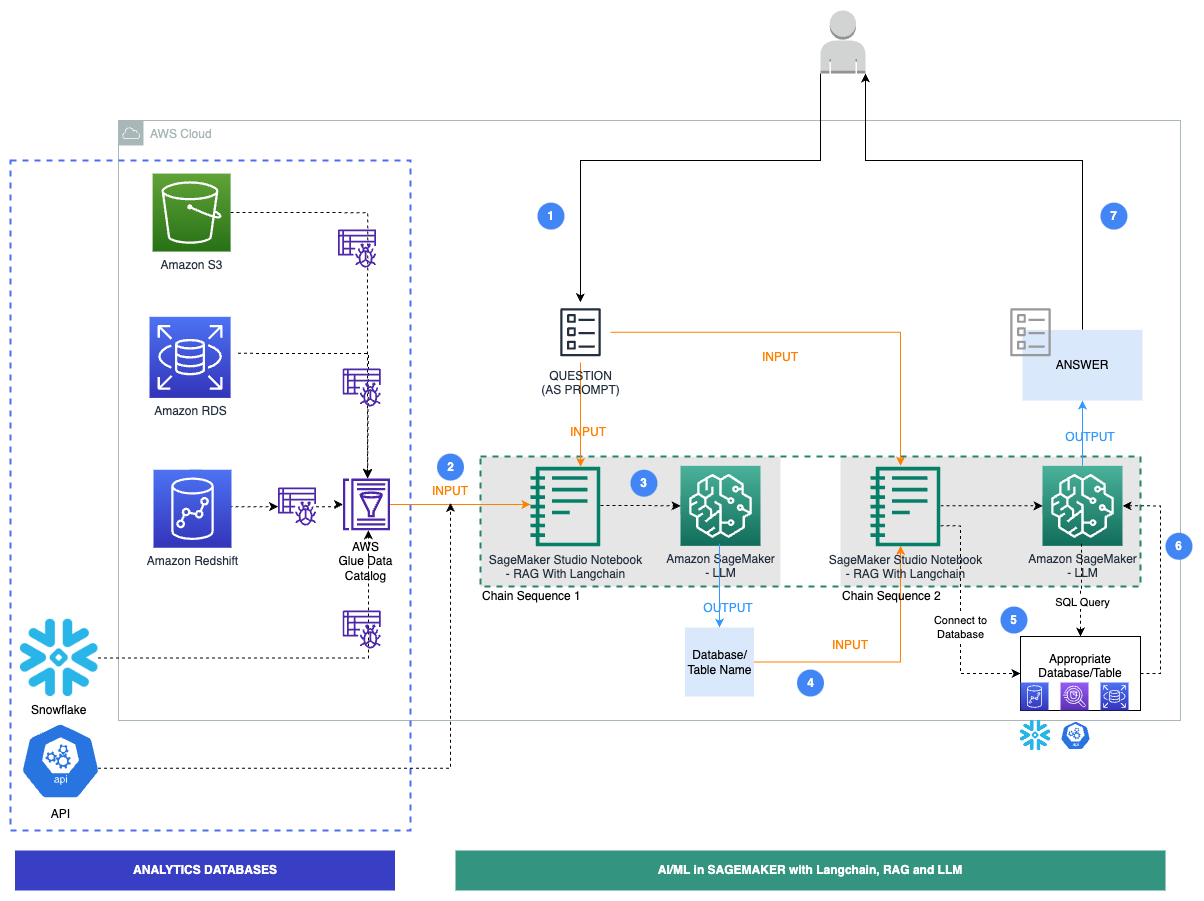
I passaggi sono i seguenti:
- Un utente aziendale fornisce un prompt di domanda in inglese.
- Viene pianificato un crawler AWS Glue per eseguire a intervalli frequenti l’estrazione di metadati dai database e creare definizioni di tabelle nel Catalogo dati AWS Glue. Il Catalogo dati è l’input per la Sequenza di Catena 1 (vedi il diagramma precedente).
- LangChain, uno strumento per lavorare con LLM e prompt, viene utilizzato nei quaderni di Studio. LangChain richiede che un LLM sia definito. Come parte della Sequenza di Catena 1, il prompt e i metadati del Catalogo dati vengono passati a un LLM, ospitato su un endpoint di SageMaker, per identificare il database e la tabella pertinenti utilizzando LangChain.
- Il prompt e il database e la tabella identificati vengono passati alla Sequenza di Catena 2.
- LangChain stabilisce una connessione al database ed esegue la query SQL per ottenere i risultati.
- I risultati vengono passati all’LLM per generare una risposta in inglese con i dati.
- L’utente riceve una risposta in inglese al suo prompt, interrogando i dati provenienti da diversi database.
Le seguenti sezioni spiegano alcuni dei passaggi chiave con il codice associato. Per approfondire la soluzione e il codice per tutti i passaggi mostrati qui, fare riferimento al GitHub repo. Il seguente diagramma mostra la sequenza di passaggi seguita:

Prerequisiti
È possibile utilizzare qualsiasi database compatibile con SQLAlchemy per generare risposte da LLMs e LangChain. Tuttavia, questi database devono avere i loro metadati registrati nel AWS Glue Data Catalog. Inoltre, sarà necessario avere accesso a LLMs tramite JumpStart o chiavi API.
Connetti ai database usando SQLAlchemy
LangChain utilizza SQLAlchemy per connettersi ai database SQL. Inizializziamo la funzione SQLDatabase di LangChain creando un motore e stabilendo una connessione per ogni origine dati. Di seguito è riportato un esempio di come connettersi a un database serverless Amazon Aurora compatibile con MySQL e includere solo la tabella degli impiegati:
#connessione a AWS Aurora MySQL
cluster_arn = <cluster_arn>
secret_arn = <secret_arn>
engine_rds=create_engine('mysql+auroradataapi://:@/employees',echo=True,
connect_args=dict(aurora_cluster_arn=cluster_arn, secret_arn=secret_arn))
dbrds = SQLDatabase(engine_rds, include_tables=['employees'])Successivamente, costruiamo prompt utilizzati dalla sequenza Chain 1 per identificare il database e il nome della tabella in base alla domanda dell’utente.
Genera modelli di prompt dinamici
Utilizziamo il AWS Glue Data Catalog, progettato per archiviare e gestire le informazioni sui metadati, per identificare la fonte dei dati per una query dell’utente e costruire prompt per la sequenza Chain 1, come dettagliato nei seguenti passaggi:
- Costruiamo un Data Catalog esplorando i metadati di più origini dati utilizzando la connessione JDBC utilizzata nella dimostrazione.
- Con la libreria Boto3, costruiamo una vista consolidata del Data Catalog da più origini dati. Di seguito è riportato un esempio su come ottenere i metadati della tabella degli impiegati dal Data Catalog per il database Aurora MySQL:
#recupera i metadati dal catalogo dei dati di colla
glue_tables_rds = glue_client.get_tables(DatabaseName=<database_name>, MaxResults=1000)
for table in glue_tables_rds['TableList']:
for column in table['StorageDescriptor']['Columns']:
columns_str=columns_str+'\n'+('rdsmysql|employees|'+table['Name']+"|"+column['Name'])Un Data Catalog consolidato ha i dettagli sulla fonte dati, come schema, nomi delle tabelle e nomi delle colonne. Di seguito è riportato un esempio dell’output del Data Catalog consolidato:
database|schema|table|column_names
redshift|tickit|tickit_sales|listid
rdsmysql|employees|employees|emp_no
....
s3|none|claims|policy_id- Passiamo il Data Catalog consolidato al modello di prompt e definiamo i prompt utilizzati da LangChain:
prompt_template = """
Dalla tabella sottostante, trovare il database (nella colonna database) che conterrà i dati (nei corrispondenti column_names) per rispondere alla domanda {query} \n
"""+glue_catalog +""" Dare la tua risposta come database == \n Inoltre, dare la tua risposta come database.table == """Chain Sequence 1: Rilevare i metadati di origine per la query dell’utente utilizzando LangChain e un LLM
Passiamo il modello di prompt generato nel passaggio precedente al prompt, insieme alla query dell’utente al modello LangChain, per trovare la migliore origine dati per rispondere alla domanda. LangChain utilizza il modello LLM della nostra scelta per rilevare i metadati di origine.
Utilizzare il seguente codice per utilizzare un LLM da JumpStart o modelli di terze parti:
#definisci il tuo modello LLM qui
llm = <LLM>
#passa il modello di prompt e la query dell'utente al prompt
PROMPT = PromptTemplate(template=prompt_template, input_variables=["query"])
# definire la catena llm
llm_chain = LLMChain(prompt=PROMPT, llm=llm)
#eseguire la query e salvare nei testi generati
generated_texts = llm_chain.run(query)Il testo generato contiene informazioni come i nomi del database e della tabella contro cui viene eseguita la query dell’utente. Ad esempio, per la query dell’utente “Nome tutti i dipendenti con data di nascita questo mese”, generated_text ha le informazioni database == rdsmysql e database.table == rdsmysql.employees.
Successivamente, passiamo i dettagli del dominio delle risorse umane, del database Aurora MySQL e della tabella degli impiegati a Chain Sequence 2.
Catena di sequenza 2: Recupera le risposte dalle fonti di dati per rispondere alla query dell’utente
Successivamente, eseguiamo la catena di database SQL di LangChain per convertire il testo in SQL ed eseguire implicitamente l’SQL generato contro il database per recuperare i risultati del database in un linguaggio semplice e leggibile.
Iniziamo definendo un modello di prompt che istruisce LLM a generare SQL in un dialetto sintatticamente corretto e quindi eseguirlo contro il database:
_DEFAULT_TEMPLATE = """Date una domanda di input, crea prima una query {dialect} sintatticamente corretta da eseguire, quindi guarda i risultati della query e restituisci la risposta.
Usa solo le seguenti tabelle:
{table_info}
Se qualcuno chiede per le vendite, si intende la tabella tickit.sales.
Domanda: {input}"""
#define the prompt
PROMPT = PromptTemplate( input_variables=["input", "table_info", "dialect"], template=_DEFAULT_TEMPLATE)Infine, passiamo LLM, la connessione al database e il prompt alla catena di database SQL ed eseguiamo la query SQL:
db_chain = SQLDatabaseChain.from_llm(llm, db, prompt=PROMPT)
response=db_chain.run(query)Ad esempio, per la query dell’utente “Nome tutti i dipendenti con data di nascita questo mese”, la risposta è la seguente:
Domanda: Nome tutti i dipendenti con data di nascita questo mese
SELECT * FROM employees WHERE MONTH(birth_date) = MONTH(CURRENT_DATE());
Risposta dell'utente:
Gli impiegati con il compleanno questo mese sono:
Christian Koblick
Tzvetan ZielinskiPulizia
Dopo aver eseguito l’architettura dei dati moderna con l’AI generativa, assicurati di pulire tutte le risorse che non verranno utilizzate. Arresta e cancella i database utilizzati (Amazon Redshift, Amazon RDS, Snowflake). Inoltre, elimina i dati in Amazon S3 e interrompi qualsiasi istanza del notebook Studio per non incorrere in ulteriori addebiti. Se hai utilizzato JumpStart per distribuire un LLM come endpoint in tempo reale di SageMaker, elimina l’endpoint tramite la console o Studio di SageMaker.
Conclusioni
In questo post, abbiamo integrato un’architettura moderna dei dati con AI generativa e LLM all’interno di SageMaker. Questa soluzione utilizza vari modelli di base di testo in testo da JumpStart e modelli di terze parti. Questo approccio ibrido identifica le fonti di dati, scrive query SQL e genera risposte con i risultati della query. Utilizza Amazon Redshift, Amazon RDS, Snowflake e LLM. Per migliorare la soluzione, è possibile aggiungere più database, un’interfaccia utente per le query in inglese, ingegneria di prompt e strumenti di dati. Questo potrebbe diventare un modo intelligente e unificato per ottenere informazioni da più store di dati. Per approfondire la soluzione e il codice mostrato in questo post, consulta il repository GitHub. Inoltre, consulta Amazon Bedrock per casi d’uso su AI generativa, modelli di base e grandi modelli di linguaggio.
