Clustering differenzialmente privato per dataset di grandi dimensioni.
Differentially private clustering for large datasets.
Pubblicato da Vincent Cohen-Addad e Alessandro Epasto, ricercatori di Google Research, Graph Mining team
Il clustering è un problema centrale nell’apprendimento automatico (ML) non supervisionato con molte applicazioni in diversi domini sia nell’industria che nella ricerca accademica in generale. Alla base, il clustering consiste nel seguente problema: dato un insieme di elementi di dati, l’obiettivo è di partizionare gli elementi di dati in gruppi in modo che gli oggetti simili siano nello stesso gruppo, mentre gli oggetti dissimili siano in gruppi diversi. Questo problema è stato studiato in matematica, informatica, ricerca operativa e statistica per più di 60 anni nelle sue innumerevoli varianti. Due forme comuni di clustering sono il clustering metrico, in cui gli elementi sono punti in uno spazio metrico, come nel problema k-means, e il clustering di grafi, in cui gli elementi sono nodi di un grafo i cui archi rappresentano la loro somiglianza.
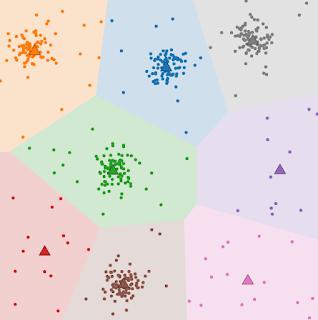 |
| Nel problema di clustering k-means, ci viene fornito un insieme di punti in uno spazio metrico con l’obiettivo di identificare k punti rappresentativi, chiamati centri (qui rappresentati come triangoli), in modo da minimizzare la somma delle distanze quadrate da ciascun punto al centro più vicino. Fonte, diritti: CC-BY-SA-4.0 |
Nonostante l’ampia letteratura sulla progettazione di algoritmi per il clustering, pochi lavori pratici si sono concentrati sulla protezione rigorosa della privacy dell’utente durante il clustering. Quando il clustering viene applicato ai dati personali (ad esempio, le query che un utente ha effettuato), è necessario considerare le implicazioni sulla privacy dell’utilizzo di una soluzione di clustering in un sistema reale e quanto le informazioni sulla soluzione in output rivelino sui dati in ingresso.
Per garantire la privacy in senso rigoroso, una soluzione è quella di sviluppare algoritmi di clustering con privacy differenziale (DP). Questi algoritmi garantiscono che l’output del clustering non rivelere informazioni private su un elemento di dati specifico (ad esempio, se un utente ha effettuato una determinata query) o dati sensibili sul grafo di input (ad esempio, una relazione in una rete sociale). Data l’importanza delle protezioni della privacy nell’apprendimento automatico non supervisionato, negli ultimi anni Google ha investito nella ricerca sulla teoria e sulla pratica del clustering metrico o grafico con privacy differenziale, e sulla privacy differenziale in una varietà di contesti, ad esempio heatmap o strumenti per progettare algoritmi DP.
- Intelligenza Artificiale Probabilistica che Sa Quanto Bene Sta Funzionando.
- Organizzazione dei dati non strutturati
Oggi siamo entusiasti di annunciare due importanti aggiornamenti: 1) un nuovo algoritmo con privacy differenziale per il clustering gerarchico di grafi, che presenteremo all’ICML 2023, e 2) la pubblicazione open-source del codice di un algoritmo k-means con privacy differenziale scalabile. Questo codice porta il clustering k-means con privacy differenziale a dataset su larga scala utilizzando il calcolo distribuito. Qui, discuteremo anche il nostro lavoro sulla tecnologia di clustering per un recente lancio nel settore della salute per informare le autorità sanitarie pubbliche.
Clustering gerarchico con privacy differenziale
Il clustering gerarchico è un approccio di clustering popolare che consiste nella partizione ricorsiva di un dataset in cluster sempre più fini. Un esempio ben noto di clustering gerarchico è l’albero filogenetico in biologia in cui tutta la vita sulla Terra è suddivisa in gruppi sempre più fini (ad esempio, regno, phylum, classe, ordine, ecc.). Un algoritmo di clustering gerarchico riceve in input un grafo che rappresenta la somiglianza tra le entità e apprende tali partizioni ricorsive in modo non supervisionato. Tuttavia, al momento della nostra ricerca, non era noto alcun algoritmo per calcolare il clustering gerarchico di un grafo con privacy degli archi, cioè preservando la privacy delle interazioni tra i vertici.
In “Clustering gerarchico con privacy differenziale e garanzie di approssimazione dimostrabili”, consideriamo quanto bene il problema possa essere approssimato in un contesto DP e stabiliamo limiti superiori e inferiori fermi sulla garanzia di privacy. Progettiamo un algoritmo di approssimazione (il primo del suo genere) con un tempo di esecuzione polinomiale che raggiunge sia un errore additivo che scala con il numero di nodi n (dell’ordine di n^2,5) che un’approssimazione moltiplicativa di O (log ½ n), con l’errore moltiplicativo identico alla modalità non privata. Inoltre, forniamo un nuovo limite inferiore sull’errore additivo (dell’ordine di n^2) per qualsiasi algoritmo privato (indipendentemente dal suo tempo di esecuzione) e forniamo un algoritmo di tempo esponenziale che corrisponde a questo limite inferiore. Inoltre, il nostro documento include un’analisi oltre il caso peggiore che si concentra sul modello di blocco stocastico gerarchico, un modello di grafo casuale standard che presenta una struttura di clustering gerarchica naturale, e introduce un algoritmo privato che restituisce una soluzione con un costo additivo rispetto all’ottimo che è trascurabile per grafi sempre più grandi, corrispondendo ancora una volta ai migliori approcci non privati. Crediamo che questo lavoro ampli la comprensione degli algoritmi per la privacy preservante sui dati di grafi e consentirà nuove applicazioni in tali impostazioni.
Clustering differenziale privato su larga scala
Cambiamo ora argomento e parliamo del nostro lavoro per il clustering in uno spazio metrico. La maggior parte dei lavori precedenti sul clustering metrico DP si è concentrata sul miglioramento delle garanzie di approssimazione degli algoritmi sull’obiettivo k-means, lasciando fuori le questioni di scalabilità. Infatti, non è chiaro come gli algoritmi non privati come k-means ++ o k-means// possano essere resi differenzialmente privati senza sacrificare drasticamente le garanzie di approssimazione o di scalabilità. D’altra parte, sia la scalabilità che la privacy sono di primaria importanza per Google. Per questo motivo, abbiamo pubblicato di recente diversi articoli che affrontano il problema di progettare algoritmi differenziali privati efficienti per il clustering che possono scalare a set di dati massivi. Il nostro obiettivo è, inoltre, di offrire scalabilità a grandi set di dati di input, anche quando il numero di centri target, k, è grande.
Lavoriamo nel modello di calcolo massivamente parallelo (MPC), che è un modello di calcolo rappresentativo delle moderne architetture di calcolo distribuito. Il modello è composto da diverse macchine, ognuna delle quali detiene solo una parte dei dati di input, che lavorano insieme con l’obiettivo di risolvere un problema globale minimizzando la quantità di comunicazione tra le macchine. Presentiamo un algoritmo di approssimazione a fattore costante differenzialmente privato per k-means che richiede solo un numero costante di round di sincronizzazione. Il nostro algoritmo si basa sul nostro lavoro precedente sul problema (con codice disponibile qui), che era il primo algoritmo di clustering differenziale privato con garanzie di approssimazione provabili che può funzionare nel modello MPC.
L’algoritmo di approssimazione a fattore costante DP migliora drasticamente il lavoro precedente utilizzando un approccio a due fasi. In una fase iniziale calcola una grossolana approssimazione per “seminare” la seconda fase, che consiste in un algoritmo distribuito più sofisticato. Dotata dell’approssimazione del primo passaggio, la seconda fase si basa sui risultati della letteratura di Coreset per sottocampionare un insieme rilevante di punti di input e trovare una buona soluzione di clustering differenziale privata per i punti di input. Dimostriamo poi che questa soluzione generalizza con circa la stessa garanzia sull’intero input.
Vaccination search insights tramite clustering DP
Applichiamo poi questi progressi nel clustering differenziale privato alle applicazioni del mondo reale. Un esempio è la nostra applicazione della soluzione di clustering differenziale privata per la pubblicazione di query relative al vaccino COVID, fornendo al contempo forti protezioni della privacy per gli utenti.
Lo scopo di Vaccination Search Insights (VSI) è aiutare i decisori della sanità pubblica (autorità sanitarie, agenzie governative e organizzazioni non profit) a identificare e rispondere alle esigenze informative delle comunità riguardo ai vaccini COVID. Per raggiungere questo obiettivo, lo strumento consente agli utenti di esplorare a diverse granularità geolocalizzate (codice postale, contea e stato negli Stati Uniti) i temi principali cercati dagli utenti riguardo alle query COVID. In particolare, lo strumento visualizza le statistiche sulle query di tendenza in aumento di interesse in un dato luogo e momento.
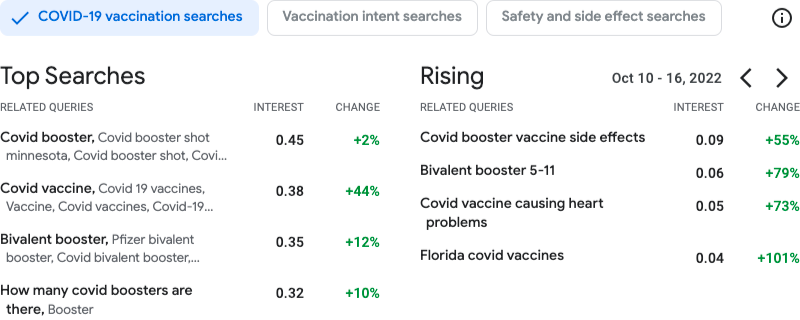 |
| Screenshot dell’output dello strumento. Visualizzate a sinistra, le ricerche principali relative ai vaccini Covid nel periodo dal 10 al 16 ottobre 2022. A destra, le query che hanno avuto una crescente importanza durante lo stesso periodo e confrontate con la settimana precedente. |
Per aiutare a identificare i temi delle ricerche di tendenza, lo strumento raggruppa le query di ricerca in base alla loro somiglianza semantica. Ciò viene fatto applicando un algoritmo basato su k-means personalizzato eseguito su dati di ricerca che sono stati anonimizzati utilizzando il meccanismo gaussiano DP per aggiungere rumore e rimuovere le query a bassa frequenza (risultando così in un clustering differenziale). Il metodo garantisce forti garanzie di privacy differenziale per la protezione dei dati degli utenti.
Questo strumento ha fornito dati dettagliati sulla percezione del vaccino COVID nella popolazione con una scala di granularità senza precedenti, qualcosa che è particolarmente rilevante per capire le esigenze delle comunità marginalizzate colpite in modo sproporzionato da COVID. Questo progetto sottolinea l’impatto del nostro investimento nella ricerca in privacy differenziale e metodi di ML non supervisionati. Stiamo cercando altre aree importanti in cui possiamo applicare queste tecniche di clustering per aiutare a guidare la presa di decisioni in materia di sfide di salute globale, come le ricerche sul cambiamento climatico, come la qualità dell’aria o il calore estremo.
Ringraziamenti
Ringraziamo i nostri co-autori Jacob Imola, Silvio Lattanzi, Jason Lee, Mohammad Mahdian, Vahab Mirrokni, Andres Munoz Medina, Shyam Narayanan, Mark Phillips, David Saulpic, Chris Schwiegelshohn, Sergei Vassilvitskii, Peilin Zhong e i membri del team Health AI che hanno reso possibile il lancio di VSI: Shailesh Bavadekar, Adam Boulanger, Tague Griffith, Mansi Kansal, Chaitanya Kamath, Akim Kumok, Yael Mayer, Tomer Shekel, Megan Shum, Charlotte Stanton, Mimi Sun, Swapnil Vispute e Mark Young.
Per ulteriori informazioni sul team di Graph Mining (parte di Algorithm and Optimization) visitare le nostre pagine.
