Ricerca di Google a I/O 2023
Google I/O 2023 search.
Pubblicato da James Manyika, SVP Google Research and Technology & Society, e Jeff Dean, Chief Scientist, Google DeepMind e Google Research
Mercoledì 10 maggio è stata una giornata entusiasmante per la comunità di ricerca di Google, mentre abbiamo visto i risultati di mesi e anni del nostro lavoro fondamentale e applicato essere annunciati sul palco di Google I/O. Con il rapido ritmo degli annunci sul palco, può essere difficile trasmettere lo sforzo sostanziale e le innovazioni uniche che sottostanno alle tecnologie che abbiamo presentato. Quindi oggi siamo entusiasti di rivelare di più sugli sforzi di ricerca che si celano dietro alcune delle numerose e interessanti novità di quest’anno alla I/O.
PaLM 2
Il nostro modello di lingua (LLM) di nuova generazione, PaLM 2, si basa sui progressi nella scalabilità ottimale del calcolo, nell’ottimizzazione delle istruzioni su larga scala e nella miscelazione di set di dati migliorata. Sintonizzando e ottimizzando il modello per scopi diversi, siamo stati in grado di integrare capacità all’avanguardia in oltre 25 prodotti e funzionalità di Google, dove sta già aiutando ad informare, assistere e deliziare gli utenti. Per esempio:
- Bard è un primo esperimento che consente di collaborare con l’AI generativa e aiuta ad aumentare la produttività, accelerare le idee e alimentare la curiosità. Si basa sui progressi nell’efficienza del deep learning e sfrutta l’apprendimento per rinforzo dal feedback umano per fornire risposte più pertinenti e aumentare la capacità del modello di seguire le istruzioni. Bard è ora disponibile in 180 paesi, dove gli utenti possono interagire con esso in inglese, giapponese e coreano, e grazie alle capacità multilingue offerte da PaLM 2, il supporto per 40 lingue arriverà presto.
- Con Search Generative Experience stiamo togliendo più lavoro dalla ricerca, così potrai capire un argomento più velocemente, scoprire nuovi punti di vista e intuizioni e fare le cose più facilmente. Come parte di questo esperimento, vedrai uno snapshot alimentato dall’AI di informazioni chiave da considerare, con link per approfondire.
- MakerSuite è un ambiente di prototipazione facile da usare per l’API di PaLM, alimentato da PaLM 2. Infatti, l’interazione degli utenti interni con i prototipi iniziali di MakerSuite ha accelerato lo sviluppo del nostro modello PaLM 2 stesso. MakerSuite è nato da una ricerca incentrata sugli strumenti di prompting, ovvero strumenti esplicitamente progettati per personalizzare e controllare LLM. Questa linea di ricerca include PromptMaker (precursore di MakerSuite), e AI Chains e PromptChainer (uno dei primi sforzi di ricerca che dimostrano l’utilità del chaining LLM).
- Il progetto Tailwind ha anche utilizzato prototipi di ricerca iniziali di MakerSuite per sviluppare funzionalità per aiutare gli scrittori e i ricercatori ad esplorare idee e migliorare la loro prosa; il suo prototipo di notebook AI-first ha utilizzato PaLM 2 per consentire agli utenti di porre domande del modello basate su documenti che definiscono.
- Med-PaLM 2 è il nostro modello medico LLM di ultima generazione, costruito su PaLM 2. Med-PaLM 2 ha raggiunto il 86,5% di prestazioni sulle domande in stile esame di licenza medica degli Stati Uniti, illustrando il suo entusiasmante potenziale per la salute. Stiamo ora esplorando le capacità multimodali per sintetizzare input come le radiografie.
- Codey è una versione di PaLM 2 ottimizzata per il codice sorgente per funzionare come assistente per sviluppatori. Supporta una vasta gamma di funzionalità di Code AI, tra cui completamento del codice, spiegazione del codice, correzione degli errori, migrazione del codice sorgente, spiegazioni degli errori e altro ancora. Codey è disponibile attraverso il nostro programma di tester affidabili tramite IDE (Colab, Android Studio, Duet AI for Cloud, Firebase) e tramite un’API rivolta a terze parti.
Forse ancora più eccitante per gli sviluppatori, abbiamo aperto le API di PaLM & MakerSuite per offrire alla comunità opportunità di innovare utilizzando questa tecnologia innovativa.
- Grandi modelli di sequenza per le attività di sviluppo software
- Ricercatori Dividono i Fononi in un Passo Verso un Nuovo Tipo di Computer Quantistico
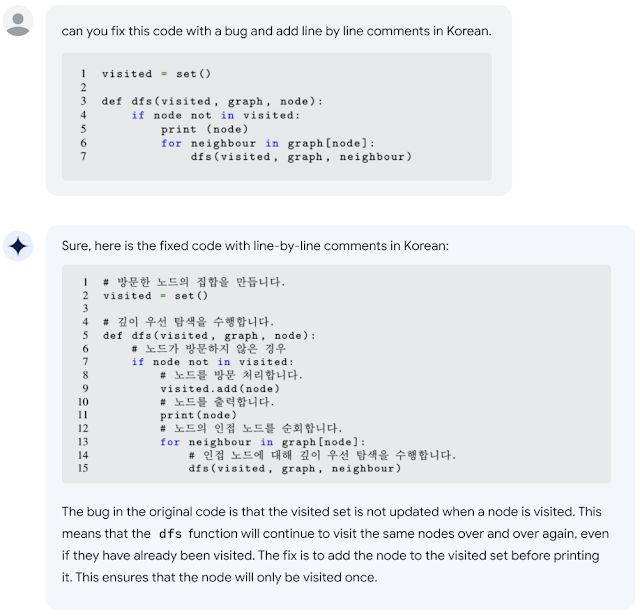 |
| PaLM 2 ha capacità avanzate di codifica che gli consentono di trovare errori di codice e fare suggerimenti in diverse lingue. |
Immagine
La nostra famiglia di modelli di generazione e modifica di immagini Imagen si basa sui progressi dei modelli di linguaggio basati su grandi Transformer e dei modelli di diffusione. Questa famiglia di modelli è stata incorporata in diversi prodotti Google, tra cui:
- La generazione di immagini in Google Slides e la wallpaper Generative AI di Android sono alimentati dalle nostre funzionalità di generazione di testo per immagini.
- Vertex AI di Google Cloud consente la generazione di immagini, la modifica delle immagini, l’upscaling delle immagini e il fine-tuning per aiutare i clienti enterprise a soddisfare le loro esigenze commerciali.
- I/O Flip, una versione digitale di un classico gioco di carte, presenta mascotte sviluppate da Google su carte completamente generate dall’IA. Questo gioco ha mostrato una tecnica di fine-tuning chiamata DreamBooth per adattare i modelli di generazione di immagini pre-addestrati. Utilizzando solo una manciata di immagini come input per il fine-tuning, consente agli utenti di generare immagini personalizzate in pochi minuti. Con DreamBooth, gli utenti possono sintetizzare un soggetto in diverse scene, pose, visualizzazioni e condizioni di illuminazione che non appaiono nelle immagini di riferimento. ——————————————————————————————————————————————————————————————————————————————————————————–
 I/O Flip presenta mazzi di carte personalizzati progettati con DreamBooth. ——————————————————————————————————————————————————————————————————————————————————————————–
I/O Flip presenta mazzi di carte personalizzati progettati con DreamBooth. ——————————————————————————————————————————————————————————————————————————————————————————–
Phenaki
Phenaki, il modello di generazione di video basato su Transformer di Google, è stato presentato nel pre-show di I/O. Phenaki è un modello che può sintetizzare video realistici da sequenze di prompt testuali mediante il sfruttamento di due componenti principali: un modello encoder-decoder che comprime i video in embedding discreti e un modello di Transformer che traduce gli embedding di testo in token video.
 |
 |
ARCore e la Scene Semantic API
Tra le nuove funzionalità di ARCore annunciate dal team AR a I/O, la Scene Semantic API può riconoscere la semantica pixel-wise in una scena all’aperto. Ciò aiuta gli utenti a creare esperienze AR personalizzate basate sulle caratteristiche dell’area circostante. Questa API è potenziata dal modello di segmentazione semantica all’aperto, sfruttando i nostri recenti lavori sull’architettura DeepLab e su un dataset di comprensione delle scene all’aperto egocentriche. L’ultima versione di ARCore include anche un modello di profondità monoculare migliorato che fornisce una maggiore precisione nelle scene all’aperto.
 |
| L’API della Semantica della Scena utilizza un modello di segmentazione semantica basato su DeepLab per fornire etichette accurate pixel-per-pixel in una scena all’aperto. |
Chirp
Chirp è la famiglia di modelli di riconoscimento vocale universale di ultima generazione di Google, addestrati su 12 milioni di ore di parlato per consentire il riconoscimento vocale automatico (ASR) per oltre 100 lingue. I modelli possono eseguire ASR su lingue sottorappresentate, come l’amharico, il cebuano e l’assamese, oltre a lingue ampiamente parlate come l’inglese e il mandarino. Chirp è in grado di coprire una così ampia varietà di lingue utilizzando l’apprendimento auto-supervisionato su un dataset multilingue non etichettato con il fine-tuning su un insieme più piccolo di dati etichettati. Chirp è ora disponibile nell’API di Google Cloud Speech-to-Text, consentendo agli utenti di eseguire inferenze sul modello attraverso un’interfaccia semplice. Puoi iniziare con Chirp qui.

MusicLM
All’I/O, abbiamo lanciato MusicLM, un modello di testo-musica che genera 20 secondi di musica da un prompt di testo. Puoi provarlo tu stesso su AI Test Kitchen, o vederlo in primo piano durante lo spettacolo I/O, dove il musicista e compositore elettronico Dan Deacon ha utilizzato MusicLM nella sua performance.
MusicLM, che consiste di modelli alimentati da AudioLM e MuLAN, può fare musica (da testo, canto, immagini o video) e accompagnamenti musicali al canto. AudioLM genera audio di alta qualità con consistenza a lungo termine. Mappa l’audio in una sequenza di token discreti e lancia la generazione audio come un compito di modellizzazione del linguaggio. Per sintetizzare output più lunghi in modo efficiente, ha utilizzato un nuovo approccio che abbiamo sviluppato chiamato SoundStorm.

Universal Translator dubbing
I nostri sforzi di doppiaggio sfruttano decine di tecnologie di apprendimento automatico per tradurre l’intera gamma espressiva dei contenuti video, rendendo i video accessibili a pubblici di tutto il mondo. Queste tecnologie sono state utilizzate per doppiare video in una varietà di prodotti e tipologie di contenuti, inclusi contenuti educativi, campagne pubblicitarie e contenuti creativi, con in più da venire. Utilizziamo la tecnologia di apprendimento profondo per raggiungere la conservazione della voce e la corrispondenza delle labbra e per consentire la traduzione video di alta qualità. Abbiamo costruito questo prodotto per includere la revisione umana per la qualità, controlli di sicurezza per prevenire abusi e renderlo accessibile solo ai partner autorizzati.
AI per il bene sociale globale
Stiamo applicando le nostre tecnologie di AI per risolvere alcune delle sfide globali più grandi, come mitigare il cambiamento climatico, adattarsi a un pianeta in fase di riscaldamento e migliorare la salute e il benessere umani. Ad esempio:
- Gli ingegneri del traffico utilizzano le nostre raccomandazioni Green Light per ridurre il traffico a colpi di freno e accelerazione nelle intersezioni e migliorare il flusso del traffico nelle città da Bangalore a Rio de Janeiro e Amburgo. Green Light modella ogni intersezione, analizzando i modelli di traffico per sviluppare raccomandazioni che rendano i semafori più efficienti – ad esempio, sincronizzando meglio i tempi tra semafori adiacenti o regolando il tempo verde per una determinata strada e direzione.
- Abbiamo anche ampliato la copertura globale su Flood Hub a 80 paesi, come parte dei nostri sforzi per prevedere le inondazioni fluviali e avvisare le persone che stanno per essere colpite prima che si verifichino i disastri. I nostri sforzi di previsione delle inondazioni si basano su modelli idrologici informati da osservazioni satellitari, previsioni meteorologiche e misurazioni in situ.

Tecnologie per applicazioni di ML inclusivo e equo
Con il nostro continuo investimento nelle tecnologie di AI, stiamo enfatizzando lo sviluppo responsabile di AI con l’obiettivo di rendere i nostri modelli e strumenti utili e impattanti, garantendo allo stesso tempo equità, sicurezza e allineamento con i nostri principi di AI. Alcuni di questi sforzi sono stati evidenziati a I/O, tra cui:
- Il rilascio del dataset Monk Skin Tone Examples (MST-E) per aiutare i professionisti a comprendere meglio la scala MST e addestrare gli annotatori umani per ottenere annotazioni di tonalità della pelle più coerenti, inclusive e significative. Puoi leggere di più su questo e altri sviluppi sul nostro sito web. Questo è un avanzamento rispetto al rilascio open source della Monk Skin Tone (MST) Scale che abbiamo lanciato l’anno scorso per consentire ai developer di costruire prodotti più inclusivi e che rappresentino meglio i loro utenti diversi.
- Una nuova competizione Kaggle (aperta fino al 10 agosto) in cui la comunità di ML è incaricata di creare un modello che possa identificare rapidamente e con precisione il fingerspelling della lingua dei segni americana (ASL) – in cui ogni lettera di una parola viene composta in ASL rapidamente utilizzando una sola mano, invece di usare i segni specifici per intere parole – e tradurlo in testo scritto. Scopri di più sulla competizione Kaggle per il fingerspelling, che presenta una canzone di Sean Forbes, un musicista e rapper sordo. Abbiamo anche presentato a I/O l’algoritmo vincente della competizione dell’anno precedente che alimenta PopSign, un’app di apprendimento ASL per i genitori di bambini sordi o ipoudenti creata da Georgia Tech e Rochester Institute of Technology (RIT).
Costruire insieme il futuro di AI
È stimolante far parte di una comunità di così tanti individui talentuosi che stanno guidando lo sviluppo di tecnologie all’avanguardia, approcci di AI responsabili ed esperienze utente entusiasmanti. Siamo nel bel mezzo di un periodo di cambiamento incredibile e trasformativo per l’AI. Restate sintonizzati per altri aggiornamenti sulle modalità in cui la comunità di ricerca di Google sta esplorando audacemente le frontiere di queste tecnologie e le sta utilizzando in modo responsabile per beneficiare delle vite delle persone in tutto il mondo. Speriamo che siate tanto entusiasmanti quanto noi per il futuro delle tecnologie di AI e vi invitiamo a interagire con le nostre squadre attraverso i riferimenti, i siti e gli strumenti che abbiamo evidenziato qui.
