Grandi modelli di sequenza per le attività di sviluppo software
Sequence models for software development activities
Pubblicato da Petros Maniatis e Daniel Tarlow, Scienziati di Ricerca di Google
Il software non viene creato in un unico passo drammatico. Migliora poco alla volta, un piccolo passo alla volta – modificando, eseguendo test unitari, correggendo gli errori di compilazione, affrontando le revisioni del codice, continuando a modificare, accontentando i linters e correggendo ancora più errori – fino a quando non diventa abbastanza buono da poter essere unito in un repository di codice. L’ingegneria del software non è un processo isolato, ma un dialogo tra sviluppatori umani, revisori del codice, segnalatori di bug, architetti del software e strumenti, come compilatori, test unitari, linters e analizzatori statici.
Oggi descriviamo DIDACT (Dynamic Integrated Developer ACTivity), che è una metodologia per addestrare grandi modelli di apprendimento automatico (ML) per lo sviluppo del software. La novità di DIDACT è che utilizza il processo di sviluppo del software come fonte di dati di formazione per il modello, anziché solo lo stato finale lucidato di quel processo, il codice finito. Esponendo il modello ai contesti che i developer vedono mentre lavorano, accoppiati con le azioni che intraprendono in risposta, il modello apprende la dinamica dello sviluppo del software ed è più allineato a come i developer trascorrono il loro tempo. Sfruttiamo l’istrumentazione dello sviluppo del software di Google per scalare la quantità e la diversità dei dati sull’attività degli sviluppatori oltre i lavori precedenti. I risultati sono estremamente promettenti su due dimensioni: utilità per i professionisti dello sviluppo del software e come base potenziale per dotare i modelli ML di abilità generali per lo sviluppo del software.
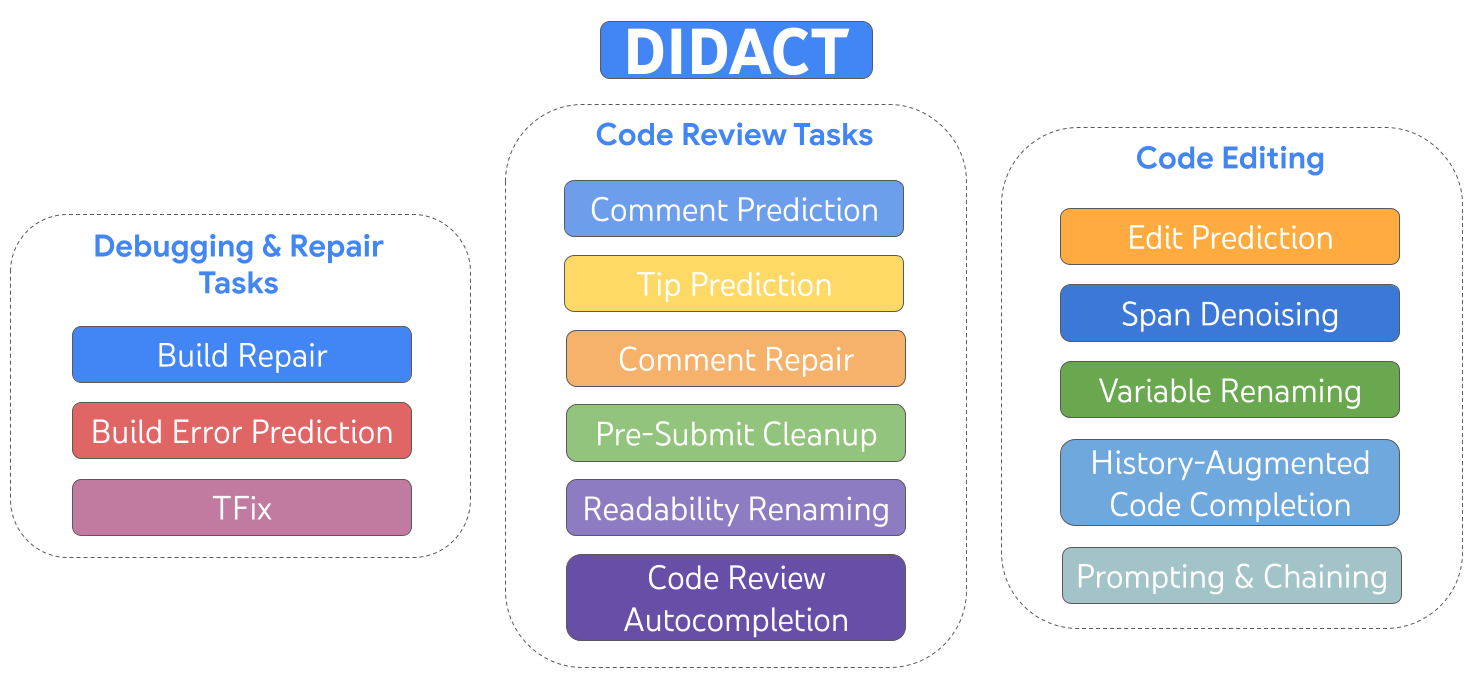 |
| DIDACT è un modello multi-task addestrato su attività di sviluppo che includono modifica, debug, riparazione e revisione del codice. |
Abbiamo costruito e implementato internamente tre strumenti DIDACT, Comment Resolution (che abbiamo annunciato di recente), Build Repair e Tip Prediction, ognuno integrato in diverse fasi del flusso di lavoro di sviluppo. Tutti e tre questi strumenti hanno ricevuto un feedback entusiasta da migliaia di sviluppatori interni. Vediamo questo come il test definitivo di utilità: i professionisti dello sviluppo del software, che sono spesso esperti sulla base del codice e che hanno flussi di lavoro attentamente affinati, utilizzano gli strumenti per migliorare la loro produttività?
Probabilmente il più entusiasmante, dimostriamo come DIDACT sia un primo passo verso un agente di assistenza per sviluppatori a scopo generale. Mostriamo che il modello addestrato può essere utilizzato in una varietà di modi sorprendenti, tramite la suggerimento con prefissi di attività degli sviluppatori e concatenando più previsioni per mettere in atto traiettorie di attività più lunghe. Crediamo che DIDACT apra una promettente strada verso lo sviluppo di agenti in grado di assistere in modo generale in tutto il processo di sviluppo del software.
Un tesoro di dati sul processo di ingegneria del software
Gli strumenti di ingegneria del software di Google archiviano ogni operazione relativa al codice come registro di interazioni tra strumenti e sviluppatori, e lo fanno da decenni. In linea di principio, si potrebbe utilizzare questo record per riprodurre in dettaglio gli episodi chiave nel “video di ingegneria del software” di come è stato creato il codice di Google, passo dopo passo – una modifica del codice, compilazione, commento, rinomina variabile, ecc., alla volta.
Il codice di Google vive in un monorepo, un singolo repository di codice per tutti gli strumenti e i sistemi. Uno sviluppatore di software sperimenta tipicamente con modifiche al codice in un workspace locale gestito da un sistema chiamato Clients in the Cloud (CitC). Quando lo sviluppatore è pronto per imballare un insieme di modifiche al codice insieme per uno scopo specifico (ad esempio, risolvere un bug), crea una lista di cambiamenti (CL) in Critique, il sistema di revisione del codice di Google. Come con altri tipi di sistemi di revisione del codice, lo sviluppatore si impegna in un dialogo con un revisore paritario sulla funzionalità e lo stile. Lo sviluppatore modifica la propria CL per affrontare i commenti del revisore man mano che il dialogo procede. Alla fine, il revisore dichiara “LGTM!” (“sembra buono per me”), e la CL viene unita al repository del codice.
Certo, oltre al dialogo con il revisore del codice, lo sviluppatore mantiene anche un “dialogo” di sorta con una moltitudine di altri strumenti di ingegneria del software, come il compilatore, il framework di testing, i linters, gli analizzatori statici, i fuzzers, ecc.
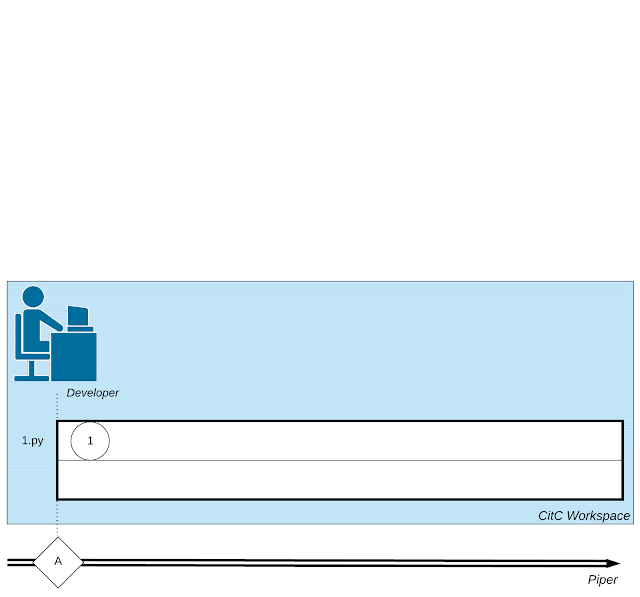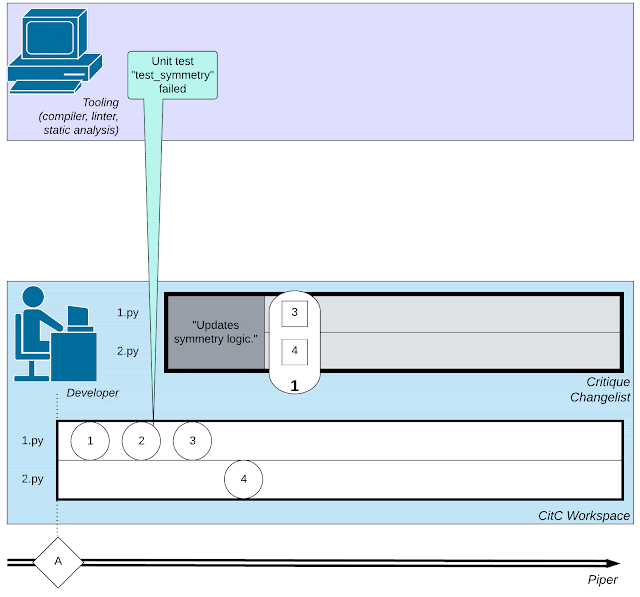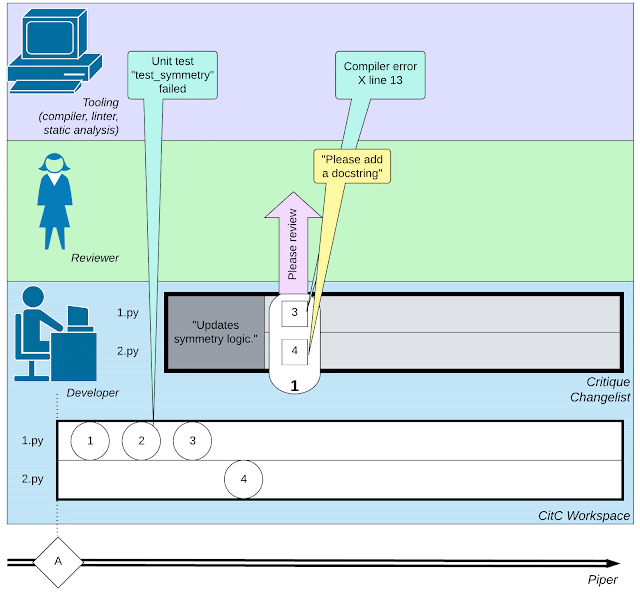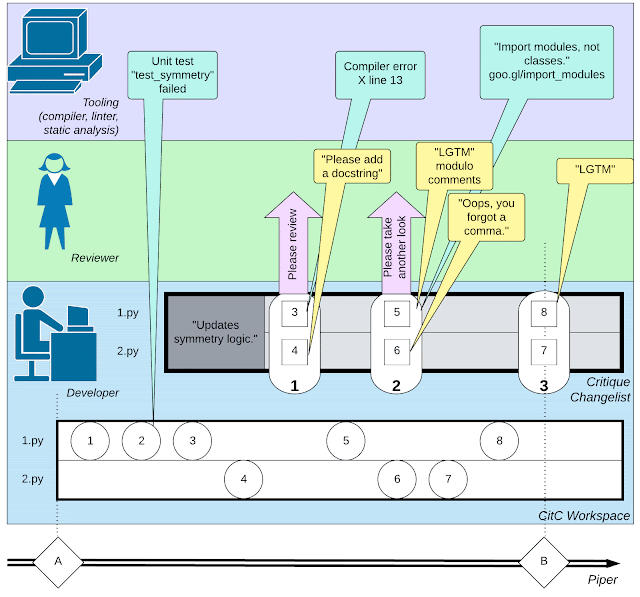 |
| Un’illustrazione della complessa rete di attività coinvolte nello sviluppo del software: piccole azioni da parte dello sviluppatore, interazioni con un revisore del codice e invocazioni di strumenti come i compilatori. |
Un modello multi-task per l’ingegneria del software
DIDACT utilizza le interazioni tra gli ingegneri e gli strumenti per alimentare modelli di ML che assistono gli sviluppatori di Google, suggerendo o migliorando le azioni che gli sviluppatori intraprendono – in contesto – durante le loro attività di ingegneria del software. Per farlo, abbiamo definito una serie di attività relative a singoli sviluppatori: riparazione di un build interrotto, previsione di un commento di revisione del codice, affrontare un commento di revisione del codice, rinominare una variabile, modificare un file, ecc. Utilizziamo un formalismo comune per ogni attività: richiede uno stato (un file di codice), un’intenzione (annotazioni specifiche per l’attività, come commenti di revisione del codice o errori del compilatore) e produce un’azione (l’operazione intrapresa per affrontare il compito). Questa azione è come un mini linguaggio di programmazione e può essere estesa per attività appena aggiunte. Copre cose come l’editing, l’aggiunta di commenti, la rinominazione di variabili, l’evidenziazione del codice con errori, ecc. Chiamiamo questo linguaggio DevScript.
 |
| Il modello DIDACT viene sollecitato con un compito, frammenti di codice e annotazioni relative a tale compito e produce azioni di sviluppo, ad es. modifiche o commenti. |
Questo formalismo stato-intenzione-azione ci consente di catturare molte diverse attività in modo generale. Inoltre, DevScript è un modo conciso per esprimere azioni complesse, senza la necessità di produrre l’intero stato (il codice originale) come sarebbe dopo che l’azione avviene; questo rende il modello più efficiente e più interpretabile. Ad esempio, una rinominazione potrebbe toccare un file in dozzine di posizioni, ma un modello può prevedere un’unica azione di rinominazione.
Un programmatore pari ML
DIDACT fa un buon lavoro su singole attività assistive. Ad esempio, qui di seguito mostriamo DIDACT che effettua la pulizia del codice dopo che la funzionalità è per lo più completata. Esamina il codice insieme ad alcuni commenti finali del revisore del codice (contrassegnati con “umano” nell’animazione) e prevede modifiche per affrontare quei commenti (rendendoli come una diff).
 |
| Dato un frammento di codice iniziale e i commenti che un revisore del codice ha allegato a quel frammento, la pulizia pre-sottomissione di DIDACT produce modifiche (inserimenti e cancellazioni di testo) che affrontano quei commenti. |
La natura multimodale di DIDACT dà origine a alcune capacità sorprendenti, che ricordano i comportamenti emergenti con la scala. Una di queste capacità è l’aumento della storia, che può essere abilitato tramite il prompting. Sapere cosa ha fatto di recente lo sviluppatore consente al modello di fare una migliore congettura su cosa lo sviluppatore dovrebbe fare dopo.
 |
| Un’illustrazione dell’aumento della storia nella completamento del codice in azione. |
Un compito così potente che esemplifica questa capacità è il completamento del codice con aumento della storia. Nella figura sottostante, lo sviluppatore aggiunge un nuovo parametro di funzione (1) e sposta il cursore nella documentazione (2). Condizionato dalla storia delle modifiche dello sviluppatore e dalla posizione del cursore, il modello completa la riga (3) prevedendo correttamente l’ingresso della docstring per il nuovo parametro.
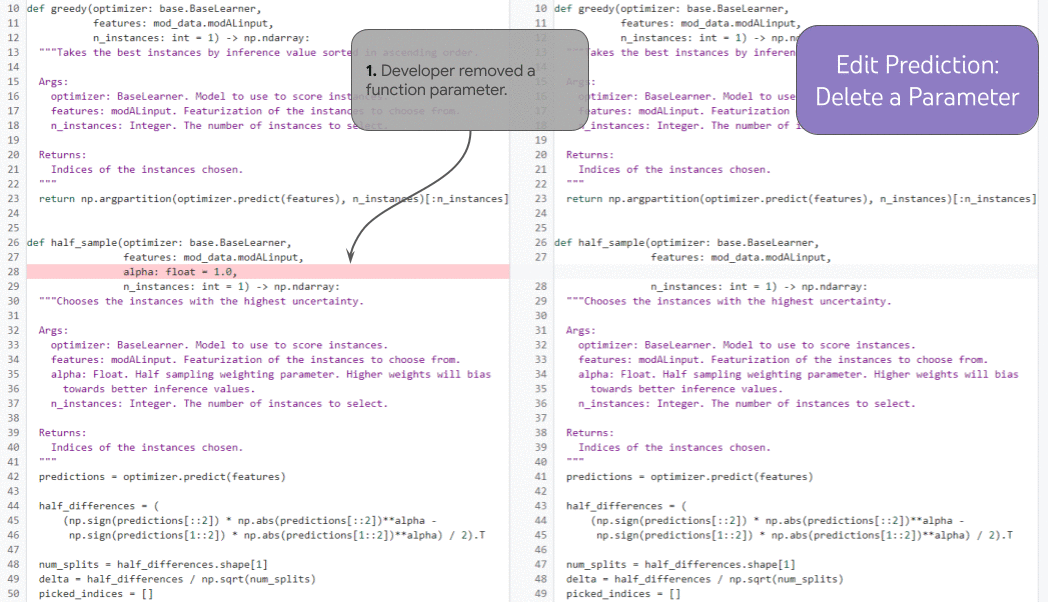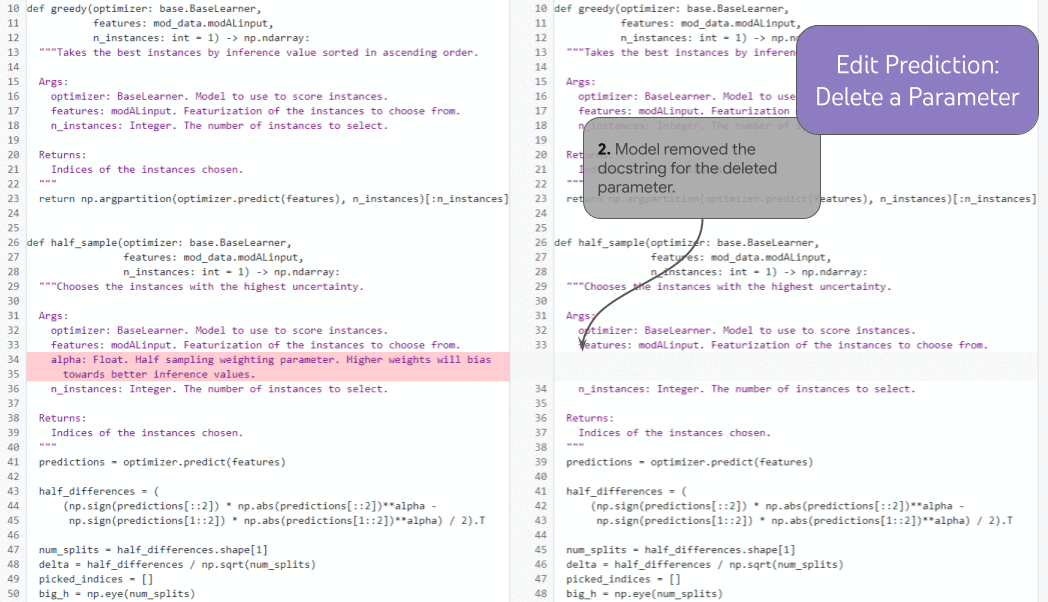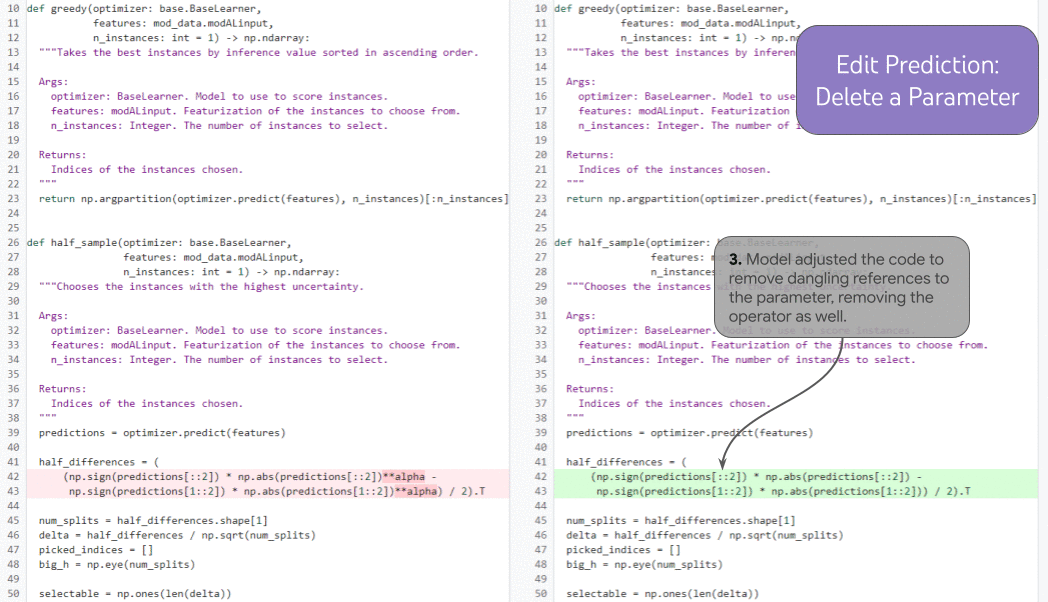 |
| Un’illustrazione della previsione delle modifiche, su più iterazioni concatenate. |
In un compito ancora più potente con l’aumento della storia, la previsione delle modifiche, il modello può scegliere dove modificare successivamente in modo storicamente coerente. Se lo sviluppatore elimina un parametro di funzione (1), il modello può utilizzare la storia per prevedere correttamente un aggiornamento alla docstring (2) che rimuove il parametro eliminato (senza che lo sviluppatore umano posizioni manualmente il cursore lì) e per aggiornare una dichiarazione nella funzione (3) in modo sintatticamente (e – argomentabilmente – semanticamente) corretto. Con la storia, il modello può decidere in modo univoco come continuare correttamente il “video di modifica”. Senza la storia, il modello non saprebbe se il parametro di funzione mancante è intenzionale (perché lo sviluppatore sta lavorando a una modifica più lunga per rimuoverlo) o accidentale (in questo caso, il modello dovrebbe aggiungerlo nuovamente per risolvere il problema).
Il modello può andare ancora oltre. Ad esempio, abbiamo iniziato con un file vuoto e abbiamo chiesto al modello di prevedere successivamente quali modifiche sarebbero arrivate fino a quando non avesse scritto un file di codice completo. La parte sorprendente è che il modello ha sviluppato il codice in modo graduale che sembrerebbe naturale per uno sviluppatore: ha iniziato creando prima uno scheletro completamente funzionante con importazioni, flag e una funzione principale di base. Ha quindi aggiunto incrementalmente nuove funzionalità, come la lettura da un file e la scrittura dei risultati, e ha aggiunto funzionalità per filtrare alcune righe in base a una espressione regolare fornita dall’utente, il che ha richiesto modifiche in tutto il file, come l’aggiunta di nuovi flag.
Conclusioni
DIDACT trasforma il processo di sviluppo del software di Google in dimostrazioni di formazione per gli assistenti sviluppatori di ML e utilizza tali dimostrazioni per formare modelli che costruiscono il codice in modo graduale, interattivo con gli strumenti e i revisori di codice. Queste innovazioni stanno già alimentando gli strumenti utilizzati dai programmatori di Google ogni giorno. L’approccio DIDACT integra i grandi passi compiuti dai grandi modelli di linguaggio di Google e altrove, verso tecnologie che facilitano il lavoro, migliorano la produttività e migliorano la qualità del lavoro degli ingegneri del software.
Ringraziamenti
Questo lavoro è il risultato di una collaborazione pluriennale tra Google Research, Google Core Systems and Experiences e DeepMind. Desideriamo ringraziare i nostri colleghi Jacob Austin, Pascal Lamblin, Pierre-Antoine Manzagol e Daniel Zheng, che si uniscono a noi come principali motori di questo progetto. Questo lavoro non sarebbe stato possibile senza i significativi e costanti contributi dei nostri partner di Alphabet (Peter Choy, Henryk Michalewski, Subhodeep Moitra, Malgorzata Salawa, Vaibhav Tulsyan e Manushree Vijayvergiya), così come molte persone che hanno raccolto dati, identificato compiti, costruito prodotti, strategizzato, evangelizzato e ci hanno aiutato a eseguire i molti aspetti di questo programma (Ankur Agarwal, Paige Bailey, Marc Brockschmidt, Rodrigo Damazio Bovendorp, Satish Chandra, Savinee Dancs, Denis Davydenko, Matt Frazier, Alexander Frömmgen, Nimesh Ghelani, Chris Gorgolewski, Chenjie Gu, Vincent Hellendoorn, Franjo Ivančić, Marko Ivanković, Emily Johnston, Luka Kalinovcic, Lera Kharatyan, Jessica Ko, Markus Kusano, Kathy Nix, Christian Perez, Sara Qu, Marc Rasi, Marcus Revaj, Ballie Sandhu, Michael Sloan, Tom Small, Gabriela Surita, Maxim Tabachnyk, David Tattersall, Sara Toth, Kevin Villela, Sara Wiltberger e Donald Duo Zhao) e il nostro leadership estremamente supportivo (Martín Abadi, Joelle Barral, Jeff Dean, Madhura Dudhgaonkar, Douglas Eck, Zoubin Ghahramani, Hugo Larochelle, Chandu Thekkath e Niranjan Tulpule). Grazie!
