Esplorando l’AI generativa nelle esperienze conversazionali un’introduzione con Amazon Lex, Langchain e SageMaker Jumpstart.
Exploring Generative AI in Conversational Experiences with Amazon Lex, Langchain, and SageMaker Jumpstart An Introduction.
I clienti si aspettano un servizio rapido ed efficiente dalle aziende nel mondo frenetico di oggi. Tuttavia, fornire un servizio clienti eccellente può essere significativamente difficile quando il volume di richieste supera le risorse umane impiegate per affrontarle. Tuttavia, le aziende possono affrontare questa sfida fornendo un servizio clienti personalizzato ed efficiente con i progressi dell’intelligenza artificiale generativa (generative AI) alimentata da grandi modelli di linguaggio (LLM).
I chatbot di intelligenza artificiale generativa hanno acquisito notorietà per la loro capacità di imitare l’intelligenza umana. Tuttavia, a differenza dei bot orientati al compito, questi bot utilizzano LLM per l’analisi del testo e la generazione di contenuti. I LLM si basano sull’architettura Transformer, una rete neurale di deep learning introdotta nel giugno 2017 che può essere addestrata su un corpus massiccio di testo non etichettato. Questo approccio crea un’esperienza di conversazione più simile a quella umana e si adatta a diversi argomenti.
Al momento della scrittura di questo testo, aziende di tutte le dimensioni vogliono utilizzare questa tecnologia ma hanno bisogno di aiuto per capire da dove cominciare. Se vuoi iniziare con l’intelligenza artificiale generativa e l’uso di LLM nell’intelligenza artificiale conversazionale, questo post è per te. Abbiamo incluso un progetto di esempio per distribuire rapidamente un bot Amazon Lex che consuma un LLM open source pre-addestrato. Il codice include anche il punto di partenza per implementare un gestore di memoria personalizzato. Questo meccanismo consente a un LLM di richiamare interazioni precedenti per mantenere il contesto e il ritmo della conversazione. Infine, è importante sottolineare l’importanza di sperimentare con prompt di raffinamento e parametri di casualità e determinismo di LLM per ottenere risultati coerenti.
Panoramica della soluzione
La soluzione integra un bot Amazon Lex con un popolare LLM open-source di Amazon SageMaker JumpStart, accessibile tramite un endpoint Amazon SageMaker. Utilizziamo anche LangChain, un framework popolare che semplifica le applicazioni alimentate da LLM. Infine, utilizziamo un QnABot per fornire un’interfaccia utente per il nostro chatbot.
- Inizia con la distribuzione open-source di Amazon SageMaker.
- Ospita modelli di Machine Learning su Amazon SageMaker utilizzando Triton Modelli ONNX
- Perfeziona GPT-J utilizzando un estimatore Hugging Face di Amazon SageMaker e la libreria di parallelizzazione del modello.

Innanzitutto, iniziamo descrivendo ogni componente nel diagramma precedente:
- JumpStart offre modelli open-source pre-addestrati per vari tipi di problemi. Questo consente di iniziare rapidamente il machine learning (ML). Include il modello FLAN-T5-XL, un LLM distribuito in un contenitore di deep learning. Si comporta bene in vari compiti di elaborazione del linguaggio naturale (NLP), tra cui la generazione di testo.
- Un endpoint di inferenza in tempo reale di SageMaker consente la distribuzione rapida e scalabile di modelli ML per la previsione di eventi. Con la capacità di integrarsi con le funzioni Lambda, l’endpoint consente la creazione di applicazioni personalizzate.
- La funzione Lambda di AWS gestisce le richieste dal bot Amazon Lex o dal QnABot per preparare il payload per invocare l’endpoint SageMaker utilizzando LangChain. LangChain è un framework che consente ai developer di creare applicazioni alimentate da LLM.
- Il bot Amazon Lex V2 ha il tipo di intento integrato
AMAZON.FallbackIntent. Viene attivato quando l’input dell’utente non corrisponde a nessun intento nel bot. - Il QnABot è una soluzione AWS open-source per fornire un’interfaccia utente ai bot Amazon Lex. Lo abbiamo configurato con una funzione hook Lambda per una voce
CustomNoMatches, e attiva la funzione Lambda quando il QnABot non riesce a trovare una risposta. Presumiamo che tu l’abbia già distribuito e abbiamo incluso i passaggi per configurarlo nelle sezioni seguenti.
La soluzione è descritta a un livello elevato nel seguente diagramma di sequenza. 
Principali compiti eseguiti dalla soluzione
In questa sezione, analizziamo i principali compiti eseguiti nella nostra soluzione. L’intero codice sorgente del progetto di questa soluzione è disponibile per il tuo riferimento in questo repository GitHub.
Gestione dei fallback del chatbot
La funzione Lambda gestisce le risposte “non lo so” tramite AMAZON.FallbackIntent in Amazon Lex V2 e la voce CustomNoMatches in QnABot. Quando attivata, questa funzione guarda la richiesta per una sessione e l’intento di fallback. Se c’è una corrispondenza, passa la richiesta a un dispatcher Lex V2; in caso contrario, il dispatcher QnABot utilizza la richiesta. Vedi il codice seguente:
def dispatch_lexv2(request):
"""Sommario
Args:
request (dict): Event di Lambda che contiene il messaggio di chat di input dell'utente e il contesto (conversazione storica)
Utilizza l'API delle sessioni di LexV2 per gestire gli input precedenti https://docs.aws.amazon.com/lexv2/latest/dg/using-sessions.html
Returns:
dict: Descrizione
"""
lexv2_dispatcher = LexV2SMLangchainDispatcher(request)
return lexv2_dispatcher.dispatch_intent()
def dispatch_QnABot(request):
"""Sommario
Args:
request (dict): Event di Lambda che contiene il messaggio di chat di input dell'utente e il contesto (conversazione storica)
Returns:
dict: Dizionario formattato come documentato per essere un hook lambda per una risposta "non lo so" per QnABot su AWS Solution
vedere https://docs.aws.amazon.com/solutions/latest/QnABot-on-aws/specifying-lambda-hook-functions.html
"""
request['res']['message'] = "Ciao! Questo è il tuo Hook Python personalizzato!"
qna_intent_dispatcher = QnASMLangchainDispatcher(request)
return qna_intent_dispatcher.dispatch_intent()
def lambda_handler(event, context):
print(event)
if 'sessionState' in event:
if 'intent' in event['sessionState']:
if 'name' in event['sessionState']['intent']:
if event['sessionState']['intent']['name'] == 'FallbackIntent':
return dispatch_lexv2(event)
else:
return dispatch_QnABot(event)Fornire memoria al nostro LLM
Per preservare la memoria LLM in una conversazione a più turni, la funzione Lambda include un meccanismo di classe di memoria personalizzata di LangChain che utilizza l’API delle sessioni di Amazon Lex V2 per tenere traccia degli attributi della sessione con i messaggi di conversazione a più turni in corso e per fornire contesto al modello conversazionale tramite interazioni precedenti. Vedere il seguente codice:
class LexConversationalMemory(BaseMemory, BaseModel):
"""Classe di memoria personalizzata LangChain che utilizza la cronologia della conversazione di Lex
Attributes:
history (dict): Dizionario che memorizza la cronologia della conversazione che funge da memoria LangChain
lex_conv_context (str): API delle sessioni di LexV2 che serve come input per la cronologia della conversazione
La memoria viene caricata da qui
memory_key (str): chiave per la variabile di memoria della cronologia della chat LangChain - "history"
"""
history = {}
memory_key = "chat_history" #passare al prompt con chiave
lex_conv_context = ""
def clear(self):
"""Cancella la cronologia della chat
"""
self.history = {}
@property
def memory_variables(self) -> List[str]:
"""Carica le variabili di memoria
Returns:
List[str]: Elenco di chiavi che contengono la memoria LangChain
"""
return [self.memory_key]
def load_memory_variables(self, inputs: Dict[str, Any]) -> Dict[str, str]:
"""Carica la memoria da lex nella memoria della sessione LangChain corrente
Args:
inputs (Dict[str, Any]): Input dell'utente per la sessione LangChain corrente
Returns:
Dict[str, str]: Oggetto di memoria LangChain
"""
input_text = inputs[list(inputs.keys())[0]]
ccontext = json.loads(self.lex_conv_context)
memory = {
self.memory_key: ccontext[self.memory_key] + input_text + "\nAI: ",
}
return memoryIl seguente è il codice di esempio che abbiamo creato per introdurre la classe di memoria personalizzata in una ConversationChain di LangChain:
# Creare una catena di conversazione utilizzando il prompt,
# llm ospitato in Sagemaker e la classe di memoria personalizzata
self.chain = ConversationChain(
llm=sm_flant5_llm,
prompt=prompt,
memory=LexConversationalMemory(lex_conv_context=lex_conv_history),
verbose=True
)Definizione del prompt
Un prompt per un LLM è una domanda o affermazione che imposta il tono per la risposta generata. I prompt funzionano come una forma di contesto che aiuta a indirizzare il modello verso la generazione di risposte pertinenti. Vedere il seguente codice:
# definire il prompt
prompt_template = """La seguente è una conversazione amichevole tra un umano e un AI. L'AI è
loquace e fornisce molti dettagli specifici dal suo contesto. Se l'AI non sa
la risposta a una domanda, dice sinceramente di non saperlo. Viene fornita informazione
sugli enti che l'Umano menziona, se rilevante.
Cronologia della chat:
{chat_history}
Conversazione:
Umano: {input}
AI:"""Usare una sessione Amazon Lex V2 per il supporto alla memoria LLM
Amazon Lex V2 avvia una sessione quando un utente interagisce con un bot. Una sessione persiste nel tempo a meno che non venga interrotta manualmente o scada. Una sessione memorizza metadati e dati specifici dell’applicazione noti come attributi di sessione. Amazon Lex aggiorna le applicazioni client quando la funzione Lambda aggiunge o modifica gli attributi di sessione. QnABot include un’interfaccia per impostare e ottenere gli attributi di sessione in cima ad Amazon Lex V2.
Nel nostro codice, abbiamo utilizzato questo meccanismo per creare una classe di memoria personalizzata in LangChain per tenere traccia della cronologia della conversazione e consentire a LLM di richiamare le interazioni a breve e lungo termine. Vedere il seguente codice:
class LexV2SMLangchainDispatcher():
def __init__(self, intent_request):
# Vedi il formato di input del bot lex per lambda https://docs.aws.amazon.com/lex/latest/dg/lambda-input-response-format.html
self.intent_request = intent_request
self.localeId = self.intent_request['bot']['localeId']
self.input_transcript = self.intent_request['inputTranscript'] # input dell'utente
self.session_attributes = utils.get_session_attributes(
self.intent_request)
self.fulfillment_state = "Fulfilled"
self.text = "" # risposta dal punto finale
self.message = {'contentType': 'PlainText','content': self.text}
class QnABotSMLangchainDispatcher():
def __init__(self, intent_request):
# Attributi di sessione QnABot
self.intent_request = intent_request
self.input_transcript = self.intent_request['req']['question']
self.intent_name = self.intent_request['req']['intentname']
self.session_attributes = self.intent_request['req']['session']Prerequisiti
Per iniziare con la distribuzione, è necessario soddisfare i seguenti prerequisiti:
- Accesso alla console di gestione AWS tramite un utente in grado di avviare stack di AWS CloudFormation
- Familiarità con la navigazione nelle console Lambda e Amazon Lex
Deploy della soluzione
Per distribuire la soluzione, procedere con i seguenti passaggi:
- Scegliere Avvia Stack per avviare la soluzione nella regione
us-east-1:
- Per il nome dello stack, inserire un nome univoco per lo stack.
- Per HFModel, utilizziamo il modello
Hugging Face Flan-T5-XLdisponibile su JumpStart. - Per HFTask, inserire
text2text. - Mantenere S3BucketName com’è.
Tutti questi elementi sono utilizzati per trovare gli asset di Amazon Simple Storage Service (Amazon S3) necessari per distribuire la soluzione e possono cambiare con gli aggiornamenti di questo post.

- Riconoscere le funzionalità.
- Scegliere Crea stack.
Dovrebbero esserci quattro stack creati con successo.

Configurare il bot Amazon Lex V2
Non c’è nulla da fare con il bot Amazon Lex V2. Il nostro modello CloudFormation ha già fatto il grosso del lavoro.
Configurare QnABot
Si presume che si abbia già un QnABot esistente distribuito nel proprio ambiente. Ma se è necessario aiuto, seguire queste istruzioni per distribuirlo.
- Nella console AWS CloudFormation, passare allo stack principale che si è distribuito.
- Nella scheda Output, prendere nota di
LambdaHookFunctionArnperché sarà necessario inserirlo in QnABot in seguito.

- Esegui l’accesso all’interfaccia utente del QnABot Designer come amministratore.
- Nell’interfaccia delle Domande, aggiungi una nuova domanda.

- Inserisci i seguenti valori:
- ID –
CustomNoMatches - Domanda –
no_hits - Risposta – Qualsiasi risposta predefinita per “non so”
- ID –
- Scegli Avanzate e vai alla sezione Hook Lambda.
- Inserisci il nome del Resource Amazon (ARN) della funzione Lambda che hai annotato in precedenza.
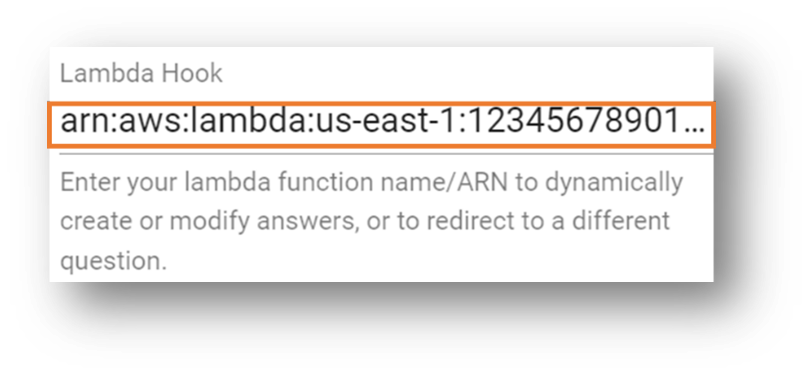
- Scorri fino alla fine della sezione e scegli Crea.
Verrà visualizzata una finestra con un messaggio di successo.

La tua domanda è ora visibile sulla pagina delle Domande.
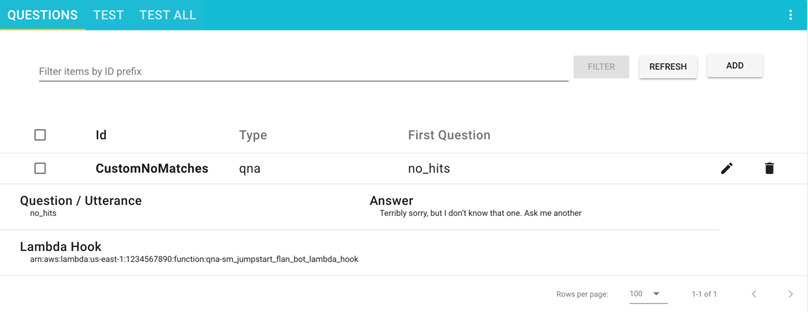
Testare la soluzione
Procediamo con il testing della soluzione. Per prima cosa, vale la pena menzionare che abbiamo deployato il modello FLAN-T5-XL fornito da JumpStart senza alcun fine-tuning. Ciò potrebbe comportare alcune imprevedibilità, con variazioni lievi nelle risposte.
Testare con un bot Amazon Lex V2
Questa sezione ti aiuta a testare l’integrazione del bot Amazon Lex V2 con la funzione Lambda che chiama il LLM deployato nel endpoint SageMaker.
- Nella console di Amazon Lex, naviga nel bot intitolato
Sagemaker-Jumpstart-Flan-LLM-Fallback-Bot. Questo bot è stato configurato per chiamare la funzione Lambda che invoca l’endpoint SageMaker che ospita il LLM come fallback intent quando nessun altro intent viene abbinato. - Scegli Intenti nel riquadro di navigazione.

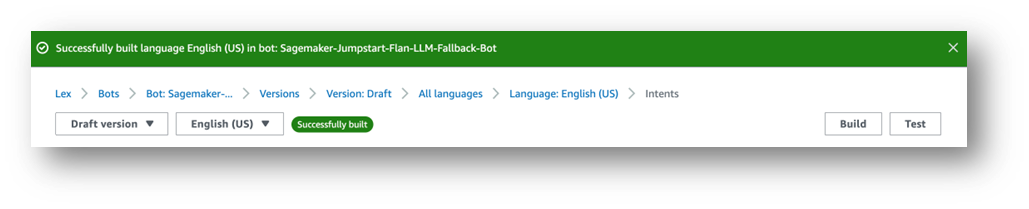
In alto a destra, compare un messaggio che indica “L’inglese (USA) non ha costruito modifiche”.
- Scegli Costruisci.
- Attendi il completamento.
Infine, otterrai un messaggio di successo, come mostrato nella seguente schermata.
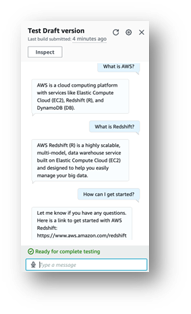
- Scegli Test.
Compare una finestra di chat in cui è possibile interagire con il modello.
Consigliamo di esplorare le integrazioni integrate tra i bot Amazon Lex e Amazon Connect. E anche le piattaforme di messaggistica (Facebook, Slack, Twilio SMS) o i centri di contatto di terze parti utilizzando Amazon Chime SDK e Genesys Cloud, ad esempio.
Testare con un’istanza QnABot
In questa sezione viene testato il QnABot sull’integrazione AWS con la funzione Lambda che chiama LLM distribuito nell’endpoint SageMaker.
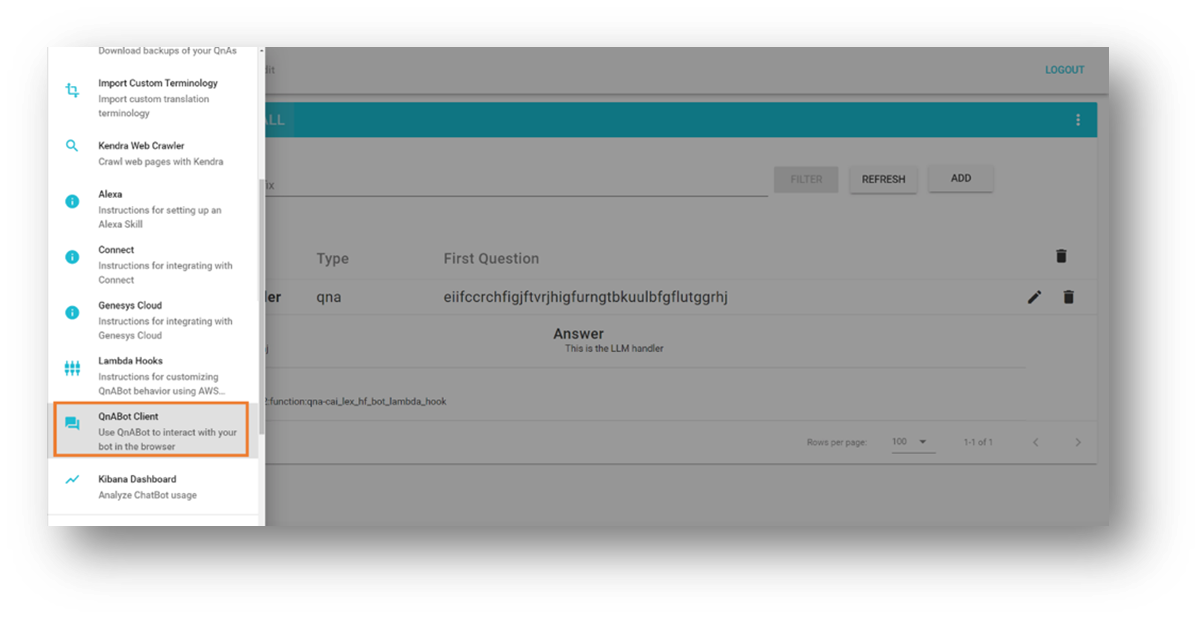
- Aprire il menu degli strumenti nell’angolo in alto a sinistra.
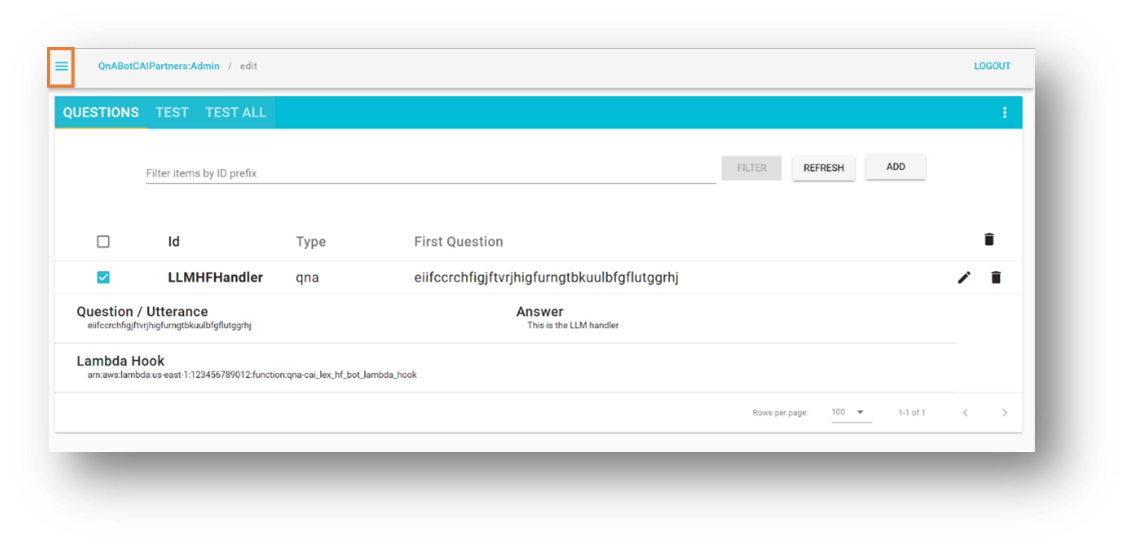
- Scegliere QnABot Client.
- Scegliere Accedi come amministratore.

- Inserisci qualsiasi domanda nell’interfaccia utente.
- Valuta la risposta.

Pulizia
Per evitare di incorrere in future spese, eliminare le risorse create dalla nostra soluzione seguendo questi passaggi:
- Nella console di AWS CloudFormation, selezionare lo stack denominato
SagemakerFlanLLMStack(o il nome personalizzato impostato per lo stack). - Scegliere Elimina.
- Se hai distribuito l’istanza QnABot per i tuoi test, selezionare lo stack QnABot.
- Scegliere Elimina.
Conclusione
In questo post, abbiamo esplorato l’aggiunta di capacità open-domain a un bot orientato al compito che instrada le richieste dell’utente verso un grande modello di lingua open-source.
Ti incoraggiamo a:
- Salvare la cronologia della conversazione in un meccanismo di persistenza esterno. Ad esempio, è possibile salvare la cronologia della conversazione su Amazon DynamoDB o un bucket S3 e recuperarla nell’hook della funzione Lambda. In questo modo, non è necessario fare affidamento sulla gestione interna dei attributi di sessione non persistenti offerti da Amazon Lex.
- Sperimentare con la sintesi – Nelle conversazioni multiturno, è utile generare un riepilogo che è possibile utilizzare nei tuoi prompt per aggiungere contesto e limitare l’utilizzo della cronologia della conversazione. Questo aiuta a ridurre la dimensione della sessione del bot e a mantenere basso il consumo di memoria della funzione Lambda.
- Sperimentare con le variazioni dei prompt – Modifica la descrizione del prompt originale che corrisponde ai tuoi scopi sperimentali.
- Adattare il modello di linguaggio per ottenere risultati ottimali – Puoi farlo affinando i parametri avanzati LLM come casualità (
temperatura) e determinismo (top_p) in base alle tue applicazioni. Abbiamo dimostrato un’integrazione di esempio utilizzando un modello pre-addestrato con valori di esempio, ma divertiti a regolare i valori per i tuoi casi d’uso.
Nel nostro prossimo post, abbiamo intenzione di aiutarti a scoprire come affinare i chatbot alimentati da LLM pre-addestrati con i tuoi dati.
Stai sperimentando con chatbot LLM su AWS? Raccontaci di più nei commenti!
Risorse e riferimenti
- Codice sorgente del post
- Guida per lo sviluppatore di Amazon Lex V2
- Libreria di soluzioni AWS: QnABot su AWS
- Generazione di testo con modelli FLAN T5
- LangChain – Costruzione di applicazioni con LLM
- Esempi di Amazon SageMaker con modelli di base di Jumpstart Foundation
- Amazon BedRock – Il modo più semplice per costruire e scalare applicazioni generative di intelligenza artificiale con modelli di base
- Costruisci rapidamente applicazioni di IA generative ad alta precisione sui dati aziendali utilizzando Amazon Kendra, LangChain e grandi modelli di lingua






