Ospita modelli di Machine Learning su Amazon SageMaker utilizzando Triton Modelli ONNX
Host ML models on Amazon SageMaker using Triton ONNX models.
ONNX (Open Neural Network Exchange) è uno standard open-source per la rappresentazione di modelli di deep learning ampiamente supportato da molti provider. ONNX fornisce strumenti per ottimizzare e quantizzare i modelli al fine di ridurre la memoria e il calcolo necessario per eseguire i modelli di machine learning (ML). Uno dei maggiori vantaggi di ONNX è che fornisce un formato standardizzato per rappresentare e scambiare modelli di ML tra diversi framework e strumenti. Ciò consente ai developer di addestrare i propri modelli in un framework e distribuirli in un altro senza la necessità di una conversione o di un nuovo addestramento del modello. Per queste ragioni, ONNX ha acquisito una significativa importanza nella comunità di ML.
In questo post, mostriamo come distribuire modelli basati su ONNX per endpoint multi-modello (MMEs) che utilizzano le GPU. Questo è il proseguimento del post Esegui più modelli di deep learning su GPU con endpoint multi-modello Amazon SageMaker, in cui abbiamo mostrato come distribuire i modelli ResNet50 di PyTorch e TensorRT su Nvidia’s Triton Inference server. In questo post, utilizziamo lo stesso modello ResNet50 in formato ONNX insieme ad un esempio di modello NLP in formato ONNX per mostrare come può essere distribuito su Triton. Inoltre, confrontiamo le prestazioni del modello ResNet50 e vediamo i benefici di prestazione che ONNX fornisce rispetto alle versioni PyTorch e TensorRT dello stesso modello, utilizzando lo stesso input.

ONNX Runtime
ONNX Runtime è un motore di runtime per inferenza di ML progettato per ottimizzare le prestazioni dei modelli su più piattaforme hardware, inclusi CPU e GPU. Consente l’uso di framework di ML come PyTorch e TensorFlow. Agevola la messa a punto delle prestazioni per eseguire modelli in modo efficiente sui hardware di destinazione e supporta funzionalità come la quantizzazione e l’accelerazione hardware, rendendolo una delle scelte ideali per distribuire applicazioni di ML efficienti ad alte prestazioni. Per esempi di come i modelli ONNX possono essere ottimizzati per Nvidia GPU con TensorRT, fare riferimento all’ottimizzazione TensorRT (ORT-TRT) e all’ONNX Runtime con l’ottimizzazione TensorRT.
- Perfeziona GPT-J utilizzando un estimatore Hugging Face di Amazon SageMaker e la libreria di parallelizzazione del modello.
- Costruisci applicazioni di chatbot personalizzate utilizzando i modelli di OpenChatkit su Amazon SageMaker.
- 16 casi d’uso di ChatGPT
Il flusso del contenitore Amazon SageMaker Triton è rappresentato nel seguente diagramma.
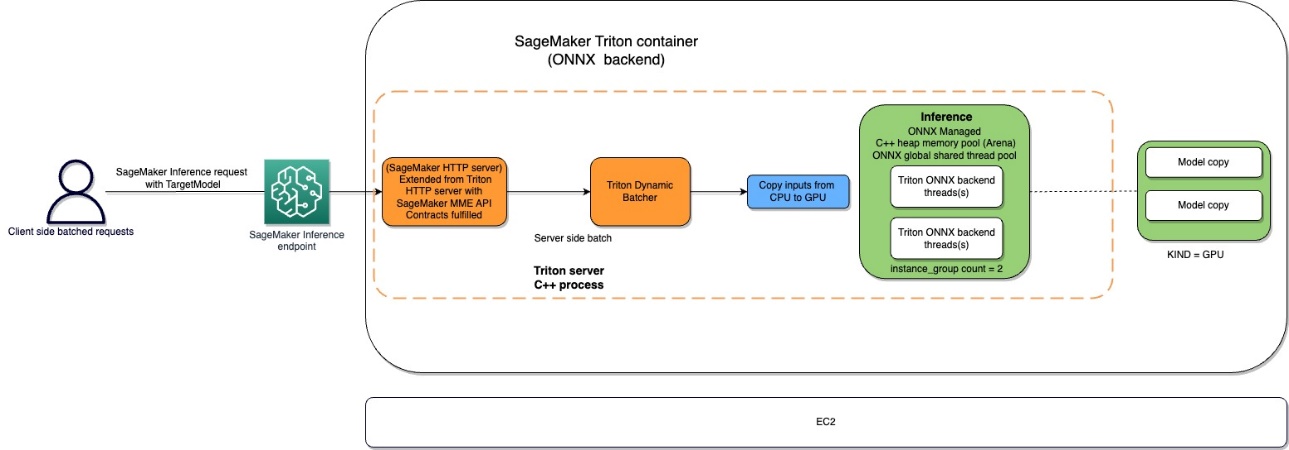
Gli utenti possono inviare una richiesta HTTPS con il payload di input per l’inferenza in tempo reale dietro un endpoint SageMaker. L’utente può specificare un’intestazione TargetModel che contiene il nome del modello a cui la richiesta in questione è destinata ad invocare. Internamente, il contenitore SageMaker Triton implementa un server HTTP con gli stessi contratti menzionati in Come i contenitori servono le richieste. Ha il supporto per il batching dinamico e supporta tutti i back-end che Triton fornisce. In base alla configurazione, viene invocato l’ONNX runtime e la richiesta viene elaborata su CPU o GPU come predefinito nella configurazione del modello fornita dall’utente.
Panoramica della soluzione
Per utilizzare il backend ONNX, eseguire i seguenti passaggi:
- Compilare il modello in formato ONNX.
- Configurare il modello.
- Creare l’endpoint SageMaker.
Prerequisiti
Assicurarsi di avere accesso ad un account AWS con le sufficienti autorizzazioni IAM AWS Identity and Access Management per creare un notebook, accedere ad un bucket Amazon Simple Storage Service (Amazon S3) e distribuire modelli su endpoint SageMaker. Vedere Crea ruolo di esecuzione per ulteriori informazioni.
Compilare il modello in formato ONNX
La libreria transformers fornisce un comodo metodo per compilare il modello PyTorch in formato ONNX. Il seguente codice raggiunge le trasformazioni per il modello NLP:
onnx_inputs, onnx_outputs = transformers.onnx.export(
preprocessor=tokenizer,
model=model,
config=onnx_config,
opset=12,
output=save_path
)L’esportazione dei modelli (sia PyTorch che TensorFlow) è facilmente realizzabile attraverso lo strumento di conversione fornito come parte del repository Hugging Face transformers.
Ecco cosa succede sotto il cofano:
- Allocare il modello da transformers (PyTorch o TensorFlow).
- Inoltrare input dummy attraverso il modello. In questo modo, ONNX può registrare l’insieme di operazioni eseguite.
- I transformers si occupano inherentemente degli assi dinamici durante l’esportazione del modello.
- Salvare il grafico insieme ai parametri di rete.
Un meccanismo simile viene seguito per il caso d’uso di computer vision dal modello zoo di torchvision:
torch.onnx.export(
resnet50,
dummy_input,
args.save,
export_params=True,
opset_version=11,
do_constant_folding=True,
input_names=["input"],
output_names=["output"],
dynamic_axes={"input": {0: "batch_size"}, "output": {0: "batch_size"}},
)Configurare il modello
In questa sezione, configuriamo il modello di computer vision e NLP. Mostriamo come creare un modello ResNet50 e RoBERTA large che è stato pre-addestrato per l’implementazione su SageMaker MME utilizzando le configurazioni del modello Triton Inference Server. Il notebook ResNet50 è disponibile su GitHub. Il notebook RoBERTA è anche disponibile su GitHub. Per ResNet50, utilizziamo l’approccio Docker per creare un ambiente che già ha tutte le dipendenze necessarie per costruire il nostro modello ONNX e generare gli artefatti del modello necessari per questo esercizio. Questo approccio rende molto più facile condividere le dipendenze e creare l’ambiente esatto che è necessario per completare questo compito.
Il primo passo è quello di creare il pacchetto del modello ONNX secondo la struttura della directory specificata in ONNX Models. Il nostro obiettivo è quello di utilizzare il repository del modello minimo per un modello ONNX contenuto in un singolo file come segue:
<model-repository-path> /
Model_name
├── 1
│ └── model.onnx
└── config.pbtxtSuccessivamente, creiamo il file di configurazione del modello che descrive gli input, gli output e le configurazioni del backend per far sì che il Triton Server prenda il controllo e invochi i kernel appropriati per ONNX. Questo file è noto come config.pbtxt ed è mostrato nel seguente codice per il caso d’uso di RoBERTA. Si noti che la dimensione BATCH è omessa dal config.pbtxt. Tuttavia, quando inviamo i dati al modello, includiamo la dimensione del batch. Il codice seguente mostra anche come è possibile aggiungere questa funzionalità con i file di configurazione del modello per impostare il batching dinamico con una dimensione di batch preferita di 5 per l’effettiva inferenza. Con le impostazioni attuali, l’istanza del modello viene invocata istantaneamente quando viene soddisfatta la dimensione del batch preferita di 5 o il tempo di ritardo di 100 microsecondi è trascorso dal momento in cui la prima richiesta raggiunge il batcher dinamico.
name: "nlp-onnx"
platform: "onnxruntime_onnx"
backend: "onnxruntime"
max_batch_size: 32
input {
name: "input_ids"
data_type: TYPE_INT64
dims: [512]
}
input {
name: "attention_mask"
data_type: TYPE_INT64
dims: [512]
}
output {
name: "last_hidden_state"
data_type: TYPE_FP32
dims: [-1, 768]
}
output {
name: "1550"
data_type: TYPE_FP32
dims: [768]
}
instance_group {
count: 1
kind: KIND_GPU
}
dynamic_batching {
max_queue_delay_microseconds: 100
preferred_batch_size:5
}Il seguente è il file di configurazione simile per il caso d’uso di computer vision:
name: "resenet_onnx"
platform: "onnxruntime_onnx"
max_batch_size : 128
input [
{
name: "input"
data_type: TYPE_FP32
format: FORMAT_NCHW
dims: [ 3, 224, 224 ]
}
]
output [
{
name: "output"
data_type: TYPE_FP32
dims: [ 1000 ]
}
]Creare il punto di ingresso di SageMaker
Utilizziamo le API Boto3 per creare il punto di ingresso di SageMaker. Per questo post, mostriamo i passaggi per il notebook RoBERTA, ma questi sono passaggi comuni e saranno gli stessi anche per il modello ResNet50.
Creare un modello SageMaker
Crea ora un modello SageMaker. Utilizziamo l’immagine Amazon Elastic Container Registry (Amazon ECR) e l’artefatto del modello dal passaggio precedente per creare il modello SageMaker.
Creare il container
Per creare il container, estraiamo l’immagine appropriata da Amazon ECR per Triton Server. SageMaker ci consente di personalizzare e iniettare varie variabili d’ambiente. Alcune delle caratteristiche principali sono la capacità di impostare il BATCH_SIZE; possiamo impostarlo per ogni modello nel file config.pbtxt, o possiamo definire un valore predefinito qui. Per i modelli che possono beneficiare di una dimensione di memoria condivisa più grande, possiamo impostare quei valori sotto le variabili SHM. Per abilitare il logging, impostare il livello di log verbose su true. Utilizziamo il seguente codice per creare il modello da utilizzare nel nostro endpoint:
mme_triton_image_uri = (
f"{account_id_map[region]}.dkr.ecr.{region}.{base}" + "/sagemaker-tritonserver:22.12-py3"
)
container = {
"Image": mme_triton_image_uri,
"ModelDataUrl": mme_path,
"Mode": "MultiModel",
"Environment": {
"SAGEMAKER_TRITON_SHM_DEFAULT_BYTE_SIZE": "16777216000", # "16777216", #"16777216000",
"SAGEMAKER_TRITON_SHM_GROWTH_BYTE_SIZE": "10485760",
},
}
from sagemaker.utils import name_from_base
model_name = name_from_base(f"flan-xxl-fastertransformer")
print(model_name)
create_model_response = sm_client.create_model(
ModelName=model_name,
ExecutionRoleArn=role,
PrimaryContainer={
"Image": inference_image_uri,
"ModelDataUrl": s3_code_artifact
},
)
model_arn = create_model_response["ModelArn"]
print(f"Created Model: {model_arn}")Crea un endpoint SageMaker
Puoi utilizzare qualsiasi istanza con più GPU per i test. In questo post, utilizziamo un’istanza g4dn.4xlarge. Non impostiamo i parametri VolumeSizeInGB perché questa istanza è dotata di archiviazione locale dell’istanza. Il parametro VolumeSizeInGB è applicabile alle istanze GPU che supportano l’attacco del volume Amazon Elastic Block Store (Amazon EBS). Possiamo lasciare il timeout di download del modello e il controllo di avvio del contenitore ai valori predefiniti. Per ulteriori dettagli, consultare CreateEndpointConfig .
endpoint_config_response = sm_client.create_endpoint_config(
EndpointConfigName=endpoint_config_name,
ProductionVariants=[{
"VariantName": "AllTraffic",
"ModelName": model_name,
"InstanceType": "ml.g4dn.4xlarge",
"InitialInstanceCount": 1,
#"VolumeSizeInGB" : 200,
#"ModelDataDownloadTimeoutInSeconds": 600,
#"ContainerStartupHealthCheckTimeoutInSeconds": 600,
},
],)'Infine, creiamo un endpoint SageMaker:
create_endpoint_response = sm_client.create_endpoint(
EndpointName=f"{endpoint_name}", EndpointConfigName=endpoint_config_name)Invoca il modello endpoint
Si tratta di un modello generativo, quindi passiamo gli input_ids e attention_mask al modello come parte del payload. Il seguente codice mostra come creare i tensori:
tokenizer("Questa è un'esempio", padding="max_length", max_length=max_seq_len)Ora creiamo il payload appropriato assicurandoci che il tipo di dati corrisponda a quello che abbiamo configurato nel config.pbtxt. Questo ci fornisce anche i tensori con la dimensione del batch inclusa, che è ciò che Triton si aspetta. Utilizziamo il formato JSON per invocare il modello. Triton fornisce anche un metodo di invocazione binario nativo per il modello.
response = runtime_sm_client.invoke_endpoint(
EndpointName=endpoint_name,
ContentType="application/octet-stream",
Body=json.dumps(payload),
TargetModel=f"{tar_file_name}",
# TargetModel=f"roberta-large-v0.tar.gz",
)Nota il parametro TargetModel nel codice precedente. Inviiamo il nome del modello da invocare come header della richiesta perché questo è un endpoint multi-modello, quindi possiamo invocare più modelli in fase di esecuzione su un endpoint di inferenza già distribuito cambiando questo parametro. Ciò dimostra la potenza degli endpoint multi-modello!
Per visualizzare l’output della risposta, possiamo utilizzare il seguente codice:
import numpy as np
resp_bin = response["Body"].read().decode("utf8")
# -- keys are -- "outputs":[{"name":"1550","datatype":"FP32","shape":[1,768],"data": [0.0013,0,3433...]}]
for data in json.loads(resp_bin)["outputs"]:
shape_1 = list(data["shape"])
dat_1 = np.array(data["data"])
dat_1.resize(shape_1)
print(f"Data Outputs recieved back :Shape:{dat_1.shape}")ONNX per ottimizzazione delle prestazioni
Il backend ONNX utilizza l’allocazione della memoria dell’arena C++. L’allocazione dell’arena è una funzionalità disponibile solo in C++ che ti aiuta ad ottimizzare l’utilizzo della memoria e migliorare le prestazioni. L’allocazione e la deallocazione della memoria costituiscono una frazione significativa del tempo CPU impiegato nel codice dei protocol buffers. Per impostazione predefinita, la creazione di un nuovo oggetto esegue l’allocazione dell’heap per ogni oggetto, per ciascuno dei suoi sotto-oggetti e per diversi tipi di campo, come le stringhe. Queste allocazioni si verificano in blocco durante l’analisi di un messaggio e durante la creazione di nuovi messaggi in memoria, e le deallocazioni associate avvengono quando i messaggi e i loro alberi di sotto-oggetti vengono liberati.
La creazione dell’arena è stata progettata per ridurre il costo di prestazione. Con l’allocazione dell’arena, i nuovi oggetti vengono allocati da un’ampia porzione di memoria preallocata chiamata arena. Gli oggetti possono essere liberati tutti insieme scartando l’intera arena, idealmente senza eseguire i distruttori di alcun oggetto contenuto (anche se un’arena può comunque mantenere una lista distruttori quando richiesto). Questo rende l’allocazione di oggetti più veloce riducendola a un semplice incremento del puntatore e rende la deallocazione quasi gratuita. L’allocazione dell’arena fornisce anche una maggiore efficienza della cache: quando i messaggi vengono analizzati, è più probabile che siano allocati in memoria continua, il che rende più probabile che il percorso dei messaggi tocchi linee di cache calde. Lo svantaggio dell’allocazione basata sull’arena è che la memoria heap C++ sarà sovrallocata e rimarrà allocata anche dopo la deallocazione degli oggetti. Ciò potrebbe portare a esaurimento della memoria o ad un uso elevato della memoria della CPU. Per ottenere il meglio di entrambi i mondi, utilizziamo le seguenti configurazioni fornite da Triton e ONNX:
-
arena_extend_strategy – Questo parametro si riferisce alla strategia utilizzata per far crescere l’arena di memoria in relazione alla dimensione del modello. Consigliamo di impostare il valore su 1 (= kSameAsRequested), che non è un valore predefinito. Il ragionamento è il seguente: lo svantaggio della strategia di estensione dell’arena predefinita (kNextPowerOfTwo) è che potrebbe allocare più memoria di quella necessaria, il che potrebbe essere uno spreco. Come suggerisce il nome, kNextPowerOfTwo (predefinito) estende l’arena di una potenza di 2, mentre kSameAsRequested estende la memoria con una dimensione pari alla richiesta di allocazione ogni volta. kSameAsRequested è adatto per configurazioni avanzate in cui si conosce in anticipo l’utilizzo di memoria previsto. Nelle nostre prove, poiché conosciamo la dimensione dei modelli come un valore costante, possiamo scegliere con sicurezza kSameAsRequested.
-
gpu_mem_limit – Impostiamo il valore sul limite di memoria CUDA. Per utilizzare tutta la memoria possibile, passare il massimo size_t. Se non viene specificato nulla, il valore predefinito è SIZE_MAX. Consigliamo di mantenerlo come predefinito.
-
enable_cpu_mem_arena – Questo abilita l’arena di memoria sulla CPU. L’arena può preallocare la memoria per l’utilizzo futuro. Impostare questa opzione su false se non si vuole. Il valore predefinito è True. Se si disabilita l’arena, l’allocazione di memoria heap richiederà tempo, quindi la latenza dell’inferenza aumenterà. Nelle nostre prove, l’abbiamo lasciato come predefinito.
-
enable_mem_pattern – Questo parametro si riferisce alla strategia interna di allocazione della memoria basata sulle forme di input. Se le forme sono costanti, è possibile abilitare questo parametro per generare un modello di memoria per il futuro e risparmiare tempo di allocazione, rendendo più veloce. Utilizzare 1 per abilitare il modello di memoria e 0 per disabilitarlo. È consigliabile impostarlo su 1 quando ci si aspetta che le caratteristiche di input siano le stesse. Il valore predefinito è 1.
-
do_copy_in_default_stream – Nel contesto del provider di esecuzione CUDA in ONNX, uno stream di calcolo è una sequenza di operazioni CUDA che vengono eseguite in modo asincrono sulla GPU. L’ONNX runtime pianifica le operazioni in diversi stream in base alle loro dipendenze, il che aiuta a ridurre il tempo di inattività della GPU e ottenere migliori prestazioni. Consigliamo di utilizzare l’impostazione predefinita di 1 per utilizzare lo stesso stream per la copia e il calcolo; tuttavia, è possibile utilizzare 0 per utilizzare stream separati per la copia e il calcolo, il che potrebbe far sì che il dispositivo esegua in pipeline le due attività. Nelle nostre prove del modello ResNet50, abbiamo utilizzato sia 0 che 1 ma non abbiamo riscontrato alcuna differenza apprezzabile tra i due in termini di prestazioni e consumo di memoria del dispositivo GPU.
-
Graph optimization – Il backend ONNX per Triton supporta diversi parametri che aiutano a ottimizzare le dimensioni del modello e le prestazioni di runtime del modello distribuito. Quando il modello viene convertito in rappresentazione ONNX, l’ONNX runtime fornisce ottimizzazioni del grafico a tre livelli: ottimizzazioni di base, estese e di layout. È possibile attivare tutti i livelli di ottimizzazioni del grafico aggiungendo i seguenti parametri al file di configurazione del modello:
ottimizzazione { grafico: { livello: 1 }} -
cudnn_conv_algo_search – Poiché nelle nostre prove utilizziamo GPU Nvidia basate su CUDA, per il nostro caso d’uso di computer vision con il modello ResNet50, possiamo utilizzare l’ottimizzazione basata sul provider di esecuzione CUDA alla quarta layer del diagramma seguente con il parametro cudnn_conv_algo_search. L’opzione predefinita è esaustiva (0), ma quando abbiamo modificato questa configurazione in 1 – HEURISTIC, abbiamo visto che la latenza del modello in stato stazionario si riduceva a 160 millisecondi. La ragione per cui ciò accade è perché l’ONNX runtime invoca il passaggio in avanti più leggero cudnnGetConvolutionForwardAlgorithm_v7 e quindi riduce la latenza con prestazioni adeguate.
-
Run mode – Il passaggio successivo è selezionare la modalità di esecuzione corretta alla layer 5 nel seguente diagramma. Questo parametro controlla se si desidera eseguire gli operatori nel grafico in modo sequenziale o in parallelo. Di solito, quando il modello ha molte diramazioni, impostare questa opzione su ExecutionMode.ORT_PARALLEL (1) darà migliori prestazioni. Nello scenario in cui il modello ha molte diramazioni nel suo grafico, l’impostazione della modalità di esecuzione in parallelo aiuterà a migliorare le prestazioni. La modalità predefinita è sequenziale, quindi è possibile abilitare questa opzione per soddisfare le proprie esigenze.
parametri { chiave: "execution_mode" valore: { string_value: "1" } }
Per una comprensione più approfondita delle opportunità di ottimizzazione delle prestazioni in ONNX, fare riferimento alla seguente figura.

Fonte: https://static.linaro.org/connect/san19/presentations/san19-211.pdf
Numeri di riferimento e ottimizzazione delle prestazioni
Aprendo le ottimizzazioni del grafico, cudnn_conv_algo_search e i parametri di modalità di esecuzione parallela nei nostri test del modello ResNet50, abbiamo visto che il tempo di avvio a freddo del grafico del modello ONNX è stato ridotto da 4,4 secondi a 1,61 secondi. Un esempio di file di configurazione completo del modello è fornito nella sezione di configurazione ONNX del seguente notebook .
I risultati del benchmark di test sono i seguenti:
- PyTorch – 176 millisecondi, avvio a freddo 6 secondi
- TensorRT – 174 millisecondi, avvio a freddo 4,5 secondi
- ONNX – 168 millisecondi, avvio a freddo 4,4 secondi
Le seguenti grafiche visualizzano queste metriche.



Inoltre, nei nostri test di casi d’uso di computer vision, considerare l’invio del carico di richiesta in formato binario utilizzando il client HTTP fornito da Triton perché migliora significativamente la latenza di invocazione del modello.
Altri parametri che SageMaker espone per ONNX su Triton sono i seguenti:
- Batching dinamico – Il batching dinamico è una funzionalità di Triton che consente di combinare le richieste di inferenza dal server, in modo che venga creata una batch dinamicamente. La creazione di una batch di richieste solitamente comporta un aumento del throughput. Il batcher dinamico dovrebbe essere utilizzato per modelli senza stato. Le batch dinamiche create vengono distribuite a tutte le istanze del modello configurate per il modello.
- Dimensione batch massima – La proprietà
max_batch_sizeindica la dimensione massima della batch che il modello supporta per i tipi di batching che possono essere sfruttati da Triton. Se la dimensione batch del modello è la prima dimensione e tutti gli input e gli output del modello hanno questa dimensione batch, allora Triton può utilizzare il batcher dinamico o il batcher di sequenza per utilizzare automaticamente il batching con il modello. In questo caso,max_batch_sizedovrebbe essere impostato su un valore maggiore o uguale a 1, che indica la dimensione massima della batch che Triton dovrebbe utilizzare con il modello. - Dimensione batch massima predefinita – Il valore di default-max-batch-size viene utilizzato per
max_batch_sizedurante l’autocompletamento quando non viene trovato nessun altro valore. Il backendonnxruntimeimposterà lamax_batch_sizedel modello su questo valore predefinito se l’autocompletamento ha determinato che il modello è in grado di effettuare il batching delle richieste emax_batch_sizeè 0 nella configurazione del modello omax_batch_sizeè omesso dalla configurazione del modello. Se lamax_batch_sizeè maggiore di 1 e non viene fornito alcun scheduler, verrà utilizzato il batch scheduler dinamico. La dimensione massima di batch predefinita è 4.
Pulizia
Assicurarsi di eliminare il modello, la configurazione del modello e il punto di ingresso del modello dopo aver eseguito il notebook. I passaggi per farlo sono forniti alla fine del notebook di esempio nel repository GitHub.
Conclusione
In questo post, ci siamo addentrati nel backend ONNX che Triton Inference Server supporta su SageMaker. Questo backend fornisce l’accelerazione GPU per i modelli ONNX. Ci sono molte opzioni da considerare per ottenere le migliori prestazioni per l’inferenza, come le dimensioni della batch, i formati di input dei dati e altri fattori che possono essere sintonizzati per soddisfare le vostre esigenze. SageMaker consente di utilizzare questa capacità utilizzando punti di ingresso per singoli modelli e multi-modelli. I MME consentono un miglior equilibrio tra prestazioni e risparmi di costi. Per iniziare con il supporto MME per GPU, vedere Host multiple models in one container behind one endpoint .
Vi invitiamo a provare i container Triton Inference Server in SageMaker e condividere i vostri feedback e domande nei commenti.





