Perfeziona GPT-J utilizzando un estimatore Hugging Face di Amazon SageMaker e la libreria di parallelizzazione del modello.
Improve GPT-J using an Amazon SageMaker Hugging Face estimator and model parallelization library.
GPT-J è un modello open-source da 6 miliardi di parametri rilasciato da Eleuther AI. Il modello è addestrato su Pile ed è in grado di svolgere varie attività di elaborazione del linguaggio. Può supportare una vasta gamma di casi d’uso, tra cui classificazione del testo, classificazione dei token, generazione di testo, domanda e risposta, estrazione di entità, riassunto, analisi del sentiment e molti altri. GPT-J è un modello di trasformatori addestrato utilizzando il Mesh Transformer JAX di Ben Wang.
In questo post, presentiamo una guida e le migliori pratiche per addestrare grandi modelli di linguaggio (LLM) utilizzando la libreria di parallelismo di modelli distribuiti di Amazon SageMaker per ridurre il tempo e il costo di addestramento. Imparerai come addestrare facilmente un modello GPT-J da 6 miliardi di parametri su SageMaker. Infine, condivideremo le principali caratteristiche del parallelismo di modelli distribuiti di SageMaker che aiutano ad accelerare il tempo di addestramento.
Reti neurali di trasformatori
Una rete neurale di trasformatori è un’architettura di deep learning popolare per risolvere compiti sequenza-su-sequenza. Utilizza l’attenzione come meccanismo di apprendimento per ottenere prestazioni vicine al livello umano. Alcune delle altre proprietà utili dell’architettura rispetto alle precedenti generazioni di modelli di elaborazione del linguaggio naturale (NLP) includono la capacità di distribuzione, scalabilità e pre- addestramento. I modelli basati su trasformatori possono essere applicati in diversi casi d’uso quando si tratta di dati testuali, come la ricerca, i chatbot e molti altri. I trasformatori utilizzano il concetto di pre-addestramento per acquisire intelligenza da grandi dataset. I trasformatori pre-addestrati possono essere utilizzati così come sono o essere adattati ai tuoi dataset, che possono essere molto più piccoli e specifici per la tua attività.
Hugging Face su SageMaker
Hugging Face è un’azienda che sviluppa alcune delle librerie open-source più popolari che forniscono tecnologie NLP all’avanguardia basate su architetture di trasformatori. Le librerie Hugging Face transformers, tokenizers e datasets forniscono API e strumenti per scaricare e prevedere utilizzando modelli pre-addestrati in più lingue. SageMaker consente di addestrare, adattare e eseguire l’elaborazione utilizzando i modelli Hugging Face direttamente dal suo Hugging Face Model Hub utilizzando l’estimatore Hugging Face nel SDK SageMaker. L’integrazione rende più facile personalizzare i modelli Hugging Face per casi d’uso specifici del dominio. Dietro le quinte, il SDK SageMaker utilizza i container di deep learning AWS (DLC), che sono un insieme di immagini Docker pre-costruite per addestrare e servire modelli offerti da SageMaker. I DLC sono sviluppati attraverso una collaborazione tra AWS e Hugging Face. L’integrazione offre anche l’integrazione tra l’SDK di Hugging Face transformers e le librerie di addestramento distribuito di SageMaker, consentendo di scalare i lavori di addestramento su un cluster di GPU.
- Costruisci applicazioni di chatbot personalizzate utilizzando i modelli di OpenChatkit su Amazon SageMaker.
- 16 casi d’uso di ChatGPT
- Dopo Amazon, l’ambizione di accelerare la produzione americana
Panoramica della libreria di parallelismo di modelli distribuiti di SageMaker
Il parallelismo di modelli è una strategia di addestramento distribuito che suddivide il modello di deep learning su numerosi dispositivi, all’interno o tra le istanze. I modelli di deep learning (DL) con più strati e parametri svolgono meglio compiti complessi come la visione artificiale e l’NLP. Tuttavia, la dimensione massima del modello che può essere archiviato nella memoria di una singola GPU è limitata. I vincoli di memoria della GPU possono essere collo di bottiglia durante l’addestramento dei modelli DL nei seguenti modi:
- Limitano la dimensione del modello che può essere addestrato perché l’impronta di memoria del modello varia proporzionalmente al numero di parametri
- Riducono l’utilizzo della GPU e l’efficienza di addestramento limitando la dimensione del batch per GPU durante l’addestramento
SageMaker include la libreria di parallelismo di modelli distribuiti per aiutare a distribuire ed addestrare efficacemente i modelli DL su molte unità di elaborazione, superando le restrizioni associate all’addestramento di un modello su una singola GPU. Inoltre, la libreria consente di ottenere l’addestramento distribuito più ottimale utilizzando dispositivi supportati da EFA, che migliorano le prestazioni di comunicazione inter-nodo con bassa latenza, elevata velocità di trasmissione dati ed elusione del sistema operativo.
Perché i grandi modelli come GPT-J, con miliardi di parametri, hanno un’impronta di memoria GPU che supera una singola scheda, diventa essenziale suddividerli su più GPU. La libreria di parallelismo di modelli SageMaker (SMP) consente la suddivisione automatica dei modelli su più GPU. Con il parallelismo di modelli SageMaker, SageMaker esegue un lavoro di profilazione iniziale per analizzare i requisiti di elaborazione e memoria del modello. Queste informazioni vengono quindi utilizzate per decidere come suddividere il modello su più GPU, al fine di massimizzare un obiettivo, come massimizzare la velocità o minimizzare l’impronta di memoria.
Supporta anche la pianificazione facoltativa delle esecuzioni in pipeline per massimizzare l’utilizzo complessivo delle GPU disponibili. La propagazione delle attivazioni durante il passaggio in avanti e dei gradienti durante il passaggio all’indietro richiede la computazione sequenziale, che limita la quantità di utilizzo della GPU. SageMaker supera il vincolo di computazione sequenziale utilizzando la pianificazione delle esecuzioni in pipeline suddividendo i mini-batch in micro-batch da elaborare in parallelo su diverse GPU. Il parallelismo di modelli SageMaker supporta due modalità di esecuzione in pipeline:
- Pipeline semplice – In questa modalità viene completata la passata in avanti per ogni micro-batch prima di iniziare la passata all’indietro.
- Pipeline intercalata – In questa modalità, la fase di esecuzione all’indietro dei micro-batch viene priorizzata quando possibile. Ciò consente un rilascio più rapido della memoria utilizzata per le attivazioni, utilizzando quindi la memoria in modo più efficiente.
Parallelismo del tensore
Le singole layer o nn.Modules sono divise tra i dispositivi utilizzando il parallelismo del tensore in modo da poter essere eseguite contemporaneamente. L’esempio più semplice di come la libreria divide un modello con quattro layer per ottenere un parallelismo del tensore bidirezionale ("tensor_parallel_degree": 2) è mostrato nella figura seguente. Le layer di ogni replica del modello sono divise in due parti e distribuite tra due GPU. Il grado di parallelismo dei dati è otto in questo esempio perché la configurazione parallela del modello include inoltre "pipeline_parallel_degree": 1 e "ddp": True. La libreria gestisce la comunicazione tra le repliche del modello tensor-distribuito.
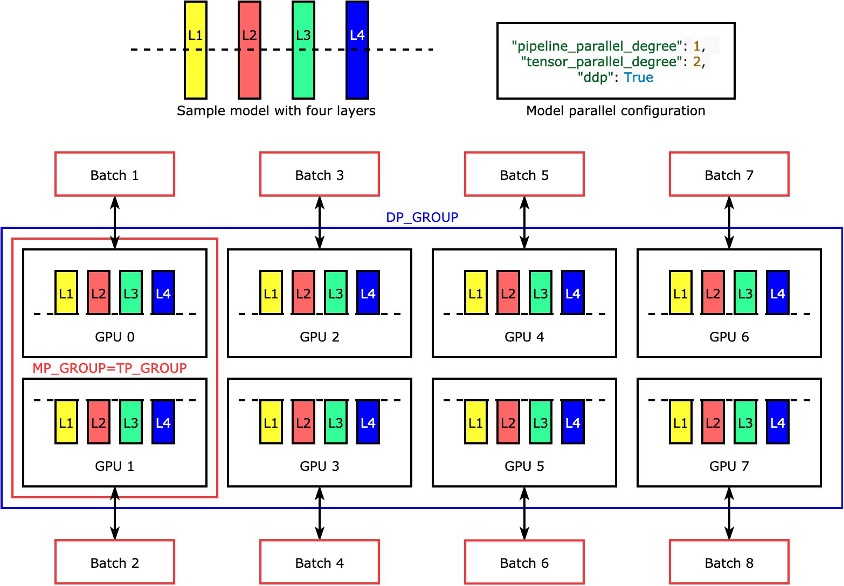
Il vantaggio di questa caratteristica è che è possibile scegliere a quali layer o quali sottoinsieme di layer applicare il parallelismo del tensore. Per approfondire il parallelismo del tensore e altre funzionalità di risparmio di memoria per PyTorch, e per imparare come configurare una combinazione di parallelismo del pipeline e del tensore, vedere le funzionalità estese della libreria di parallelismo del modello SageMaker per PyTorch.
Parallelismo di dati sharded di SageMaker
Il parallelismo di dati sharded è una tecnica di formazione distribuita che consente di risparmiare memoria suddividendo lo stato di formazione di un modello (parametri del modello, gradienti e stati dell’ottimizzatore) attraverso le GPU di un gruppo parallelo.
Quando si scala il job di formazione su un grande cluster di GPU, è possibile ridurre l’impronta di memoria per GPU del modello suddividendo lo stato di formazione su più GPU. Ciò restituisce due vantaggi: è possibile adattare modelli più grandi, che altrimenti esaurirebbero la memoria con il parallelismo standard dei dati, o è possibile aumentare la dimensione del batch utilizzando la memoria GPU liberata.
La tecnica standard del parallelismo dei dati replica lo stato di formazione su tutte le GPU del gruppo parallelo e esegue l’aggregazione dei gradienti sulla base dell’operazione AllReduce. In effetti, il parallelismo di dati sharded introduce un compromesso tra il costo di comunicazione e l’efficienza della memoria GPU. Utilizzando il parallelismo di dati sharded si aumenta il costo di comunicazione, ma l’impronta di memoria per GPU (escludendo l’utilizzo della memoria dovuto alle attivazioni) è divisa per il grado di parallelismo di dati sharded, quindi modelli più grandi possono adattarsi a un cluster di GPU.
SageMaker implementa il parallelismo di dati sharded attraverso l’implementazione MiCS. Per maggiori informazioni, vedere la scalabilità quasi lineare della formazione di modelli giganteschi su AWS.
Per ulteriori dettagli su come applicare il parallelismo di dati sharded ai job di formazione, consultare il parallelismo di dati sharded.
Usa la libreria di parallelismo del modello SageMaker
La libreria di parallelismo del modello SageMaker viene fornita con il SDK Python di SageMaker. È necessario installare il SDK Python di SageMaker per utilizzare la libreria, ed è già installato sui kernel dei notebook SageMaker. Per fare in modo che lo script di formazione PyTorch utilizzi le funzionalità della libreria SMP, è necessario apportare le seguenti modifiche:
- Iniziare importando e inizializzando la libreria
smpcon la chiamatasmp.init(). - Una volta inizializzata, è possibile avvolgere il modello con il wrapper
smp.DistributedModele utilizzare l’oggettoDistributedModelrestituito invece del modello utente. - Per lo stato dell’ottimizzatore, utilizzare il wrapper
smp.DistributedOptimizerattorno all’ottimizzatore del modello, abilitandosmpa salvare e caricare lo stato dell’ottimizzatore. La logica di passaggio in avanti e all’indietro può essere astratta come una funzione separata e aggiungere un decoratoresmp.stepalla funzione. Fondamentalmente, il passaggio in avanti e la retropropagazione devono essere eseguiti all’interno della funzione con il decoratoresmp.stepposizionato sopra di esso. Ciò consente asmpdi suddividere l’input del tensore per la funzione in un determinato numero di micro-batch specificati durante l’avvio del job di formazione. - Successivamente, è possibile spostare i tensori di input sulla GPU utilizzata dal processo corrente utilizzando l’API
torch.cuda.set_deviceseguita dalla chiamata.to(). - Infine, per la retropropagazione, sostituire
torch.Tensor.backwardetorch.autograd.backward.
Vedi il seguente codice:
@smp.step
def train_step(model, data, target):
output = model(data)
loss = F.nll_loss(output, target, reduction="mean")
model.backward(Loss)
return output, loss
with smp.tensor_parallelism():
model = AutoModelForCausalLM.from_config(model_config)
model = smp.DistributedModel (model)
optimizer = smp. DistributedOptimizer(optimizer)La parallelizzazione tensore della libreria SageMaker per la parallelizzazione dei modelli offre il supporto out-of-the-box per i seguenti modelli Hugging Face Transformer:
- GPT-2, BERT e RoBERTa (disponibili nella libreria SMP v1.7.0 e successivi)
- GPT-J (disponibile nella libreria SMP v1.8.0 e successivi)
- GPT-Neo (disponibile nella libreria SMP v1.10.0 e successivi)
Best practices per l’ottimizzazione delle prestazioni con la libreria SMP
Quando si addestrano modelli di grandi dimensioni, considerare i seguenti passaggi in modo che il modello si adatti alla memoria GPU con una dimensione batch ragionevole:
- Si consiglia di utilizzare istanze con memoria GPU superiore e interconnessione ad alta larghezza di banda per le prestazioni, come le istanze p4d e p4de.
- Lo sharding dello stato dell’ottimizzatore può essere abilitato nella maggior parte dei casi e sarà utile quando hai più di una copia del modello (parallelismo dei dati abilitato). Puoi attivare lo sharding dello stato dell’ottimizzatore impostando
"shard_optimizer_state": Truenella configurazionemodelparallel. - Usa il checkpointing di attivazione, una tecnica per ridurre l’uso della memoria cancellando le attivazioni di determinati strati e ricomputandole durante un passaggio all’indietro di moduli selezionati nel modello.
- Usa lo scarico dell’attivazione, una funzionalità aggiuntiva che può ridurre ulteriormente l’uso della memoria. Per utilizzare lo scarico dell’attivazione, impostare
"offload_activations": Truenella configurazionemodelparallel. Usa quando il checkpointing dell’attivazione e la parallelizzazione della pipeline sono attivati e il numero di microbatch è maggiore di uno. - Abilita la parallelizzazione del tensore e aumenta i gradi di parallelismo in cui il grado è una potenza di 2. Tipicamente per motivi di prestazioni, la parallelizzazione del tensore è limitata all’interno di un nodo.
Ancora molti esperimenti sono stati eseguiti per ottimizzare l’addestramento e la messa a punto di GPT-J su SageMaker con la libreria SMP. Siamo riusciti a ridurre il tempo di addestramento di GPT-J per un’epoca su SageMaker da 58 minuti a meno di 10 minuti, ovvero sei volte più veloce il tempo di addestramento per epoca. Ci sono voluti meno di un minuto per l’inizializzazione, il download del modello e del dataset da Amazon Simple Storage Service (Amazon S3), la tracciatura e la suddivisione automatica con GPU come dispositivo di tracciamento meno di 1 minuto e addestrare un’epoca 8 minuti utilizzando la parallelizzazione del tensore su una istanza ml.p4d.24xlarge, la precisione FP16 e un estimatore Hugging Face SageMaker.
Per ridurre il tempo di addestramento come pratica consigliata, quando si addestra GPT-J su SageMaker, si consiglia quanto segue:
- Memorizza il modello pre-addestrato su Amazon S3
- Usa la precisione FP16
- Usa la GPU come dispositivo di tracciamento
- Usa la suddivisione automatica, il checkpointing dell’attivazione e lo sharding dello stato dell’ottimizzatore:
auto_partition: Trueshard_optimizer_state: True
- Usa la parallelizzazione del tensore
- Usa un’istanza di addestramento SageMaker con più GPU come ml.p3.16xlarge, ml.p3dn.24xlarge, ml.g5.48xlarge, ml.p4d.24xlarge o ml.p4de.24xlarge.
Addestramento e messa a punto del modello GPT-J su SageMaker con la libreria SMP
Un esempio di codice passo-passo funzionante è disponibile nel repository pubblico degli esempi Amazon SageMaker. Navigare nella cartella training/distributed_training/pytorch/model_parallel/gpt-j. Selezionare la cartella gpt-j e aprire il notebook Jupyter train_gptj_smp_tensor_parallel_notebook.jpynb per l’esempio di parallelismo del tensore e train_gptj_smp_notebook.ipynb per l’esempio di parallelismo della pipeline. È possibile trovare una spiegazione del codice nel nostro workshop Generative AI su Amazon SageMaker.
Questa guida ti illustra come utilizzare le funzionalità di parallelismo tensoriale fornite dalla libreria di parallelismo dei modelli SageMaker. Imparerai come eseguire l’addestramento FP16 del modello GPT-J con parallelismo tensoriale e parallelismo di pipeline sul dataset GLUE sst2.
Sommario
La libreria di parallelismo dei modelli SageMaker offre diverse funzionalità. Puoi ridurre i costi e accelerare l’addestramento di LLM su SageMaker. Puoi anche apprendere ed eseguire codici di esempio per BERT, GPT-2 e GPT-J nel repository pubblico Amazon SageMaker Examples. Per saperne di più sulle migliori pratiche AWS per l’addestramento di LLMS utilizzando la libreria SMP, consulta le seguenti risorse:
- Migliori pratiche di parallelismo distribuito dei modelli SageMaker
- Addestramento di modelli di lingua di grandi dimensioni su Amazon SageMaker: Migliori pratiche
Per scoprire come uno dei nostri clienti ha ottenuto inferenza GPT-J a bassa latenza su SageMaker, consulta come Mantium ottiene inferenza GPT-J a bassa latenza con DeepSpeed su Amazon SageMaker.
Se stai cercando di accelerare il time-to-market dei tuoi LLM e ridurre i costi, SageMaker può aiutarti. Facci sapere cosa costruisci!





