Accelerare PyTorch con DeepSpeed per allenare grandi modelli di linguaggio con istanze DL1 basate su Intel Habana Gaudi su EC2.
Accelerate PyTorch with DeepSpeed for training large language models using DL1 instances based on Intel Habana Gaudi on EC2.
Formare modelli di lingua di grandi dimensioni (LLM) con miliardi di parametri può essere impegnativo. Oltre a progettare l’architettura del modello, i ricercatori devono impostare tecniche di formazione all’avanguardia per la formazione distribuita come il supporto alla precisione mista, l’accumulo del gradiente e il checkpointing. Con modelli di grandi dimensioni, l’allestimento della formazione è ancora più impegnativo perché la memoria disponibile in un singolo dispositivo acceleratore limita la dimensione dei modelli addestrati utilizzando solo la parallelizzazione dei dati e utilizzare la formazione parallela del modello richiede un ulteriore livello di modifiche al codice di formazione. Librerie come DeepSpeed (una libreria di ottimizzazione di deep learning open source per PyTorch) affrontano alcune di queste sfide e possono aiutare ad accelerare lo sviluppo e la formazione del modello.
In questo post, impostiamo la formazione sulle istanze Amazon Elastic Compute Cloud (Amazon EC2) DL1 basate su Intel Habana Gaudi e quantifichiamo i vantaggi dell’utilizzo di un framework di scalabilità come DeepSpeed. Presentiamo risultati di scalabilità per un modello di transformer di tipo codificatore (BERT con 340 milioni a 1,5 miliardi di parametri). Per il modello di 1,5 miliardi di parametri, abbiamo ottenuto un’efficienza di scalabilità dell’82,7% su 128 acceleratori (16 istanze dl1.24xlarge) utilizzando le ottimizzazioni ZeRO stage 1 di DeepSpeed. Gli stati dell’ottimizzatore sono stati suddivisi da DeepSpeed per addestrare grandi modelli utilizzando il paradigma di parallelismo dei dati. Questo approccio è stato esteso per addestrare un modello di 5 miliardi di parametri utilizzando il parallelismo dei dati. Abbiamo anche utilizzato il supporto nativo di Gaudi del tipo di dati BF16 per ridurre le dimensioni della memoria e aumentare le prestazioni di formazione rispetto all’utilizzo del tipo di dati FP32. Di conseguenza, abbiamo raggiunto la convergenza del modello di preformazione (fase 1) entro 16 ore (il nostro obiettivo era di addestrare un grande modello entro un giorno) per il modello di 1,5 miliardi di parametri BERT utilizzando il dataset wikicorpus-en.
Impostazione della formazione
Abbiamo messo a disposizione un cluster di calcolo gestito composto da 16 istanze dl1.24xlarge utilizzando AWS Batch. Abbiamo sviluppato un workshop di AWS Batch che illustra i passaggi per impostare il cluster di formazione distribuita con AWS Batch. Ogni istanza dl1.24xlarge ha otto acceleratori Habana Gaudi, ognuno con 32 GB di memoria e una rete RoCE mesh completa tra le schede con una larghezza di banda di interconnessione bidirezionale totale di 700 Gbps ciascuno (vedere Amazon EC2 DL1 instances Deep Dive per ulteriori informazioni). Il cluster dl1.24xlarge ha anche utilizzato quattro adattatori Elastic Fabric di AWS (EFA), con un’interconnessione totale di 400 Gbps tra i nodi.
Il workshop di formazione distribuita illustra i passaggi per impostare il cluster di formazione distribuita. Il workshop mostra l’allestimento della formazione distribuita utilizzando AWS Batch e in particolare, la funzione di lavoro parallelo multiprocessore per lanciare lavori di formazione containerizzati su larga scala su cluster completamente gestiti. Più specificamente, viene creato un ambiente di calcolo AWS Batch completamente gestito con istanze DL1. I contenitori vengono estratti dal Registro dei contenitori elastici di Amazon (Amazon ECR) e lanciati automaticamente nelle istanze del cluster in base alla definizione di lavoro parallelo multiprocessore. Il workshop si conclude con l’esecuzione di una formazione parallela dei dati su più nodi e più HPU di un modello BERT (da 340 milioni a 1,5 miliardi di parametri) utilizzando PyTorch e DeepSpeed.
- 10 Corsi Brevi Gratuiti per Padroneggiare l’AI Generativa
- NT-Xent (Normalized Temperature-Scaled Cross-Entropy) Loss spiegato ed implementato in PyTorch
- Comprendere la Policy Gradient costruendo Cross Entropy da zero
Preformazione di BERT 1.5B con DeepSpeed
Habana SynapseAI v1.5 e v1.6 supportano le ottimizzazioni ZeRO1 di DeepSpeed. La versione di DeepSpeed del repository GitHub di Habana include le modifiche necessarie per supportare gli acceleratori Gaudi. Vi è il pieno supporto del parallelismo dei dati distribuito (multi-card, multi-istanza), delle ottimizzazioni ZeRO1 e dei tipi di dati BF16.
Tutte queste funzionalità sono abilitate nel repository di riferimento del modello BERT 1.5B, che introduce un modello di codificatore bidirezionale a 48 strati, 1600 dimensioni nascoste e 25 testa, derivato da un’implementazione BERT. Il repository contiene anche l’implementazione del modello BERT Large di base: un’architettura di rete neurale a 24 strati, 1024 nascosta, 16 testa e 340 milioni di parametri. Gli script di modellizzazione della preformazione sono derivati dal repository degli esempi di apprendimento profondo di NVIDIA per scaricare i dati wikicorpus_en, preprocessare i dati grezzi in token e suddividere i dati in dataset h5 più piccoli per la formazione parallela dei dati distribuiti. È possibile adottare questo approccio generico per addestrare le proprie architetture di modelli PyTorch personalizzati utilizzando i propri dataset utilizzando le istanze DL1.
Risultati di scalatura della preformazione (fase 1)
Per la preformazione di grandi modelli su larga scala, ci siamo concentrati principalmente su due aspetti della soluzione: le prestazioni di formazione, misurate dal tempo di formazione, e la convenienza economica di arrivare a una soluzione completamente convergente. Successivamente, approfondiamo questi due metodi con la preformazione di BERT 1.5B come esempio.
Scalabilità delle prestazioni e tempo di addestramento
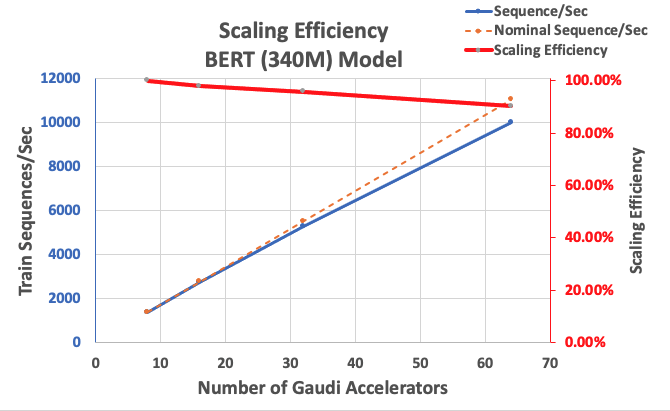
Cominciamo misurando le prestazioni dell’implementazione di BERT Large come base per la scalabilità. La seguente tabella elenca la produttività misurata delle sequenze al secondo da 1-8 istanze dl1.24xlarge (con otto dispositivi di accelerazione per istanza). Utilizzando la produttività di singola istanza come base, abbiamo misurato l’efficienza di scalabilità su più istanze, che è una leva importante per comprendere la metrica di addestramento prezzo-prestazioni.
| Numero di istanze | Numero di acceleratori | Sequenze al secondo | Sequenze al secondo per acceleratore | Efficienza di scalabilità |
| 1 | 8 | 1.379,76 | 172,47 | 100,0% |
| 2 | 16 | 2.705,57 | 169,10 | 98,04% |
| 4 | 32 | 5.291,58 | 165,36 | 95,88% |
| 8 | 64 | 9.977,54 | 155,90 | 90,39% |
La seguente figura illustra l’efficienza di scalabilità.
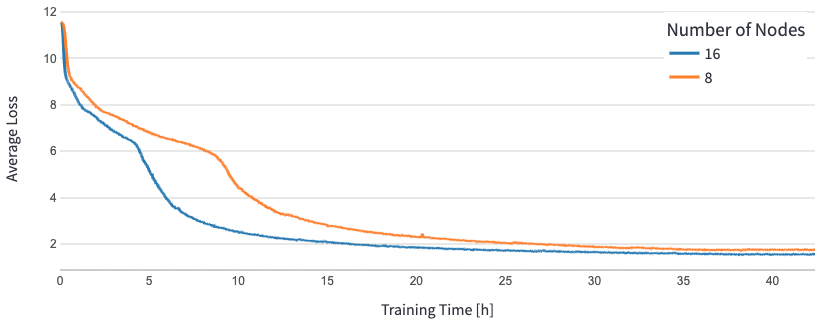
Per BERT 1.5B, abbiamo modificato gli iperparametri per il modello nel repository di riferimento per garantire la convergenza. La dimensione del batch effettiva per acceleratore è stata impostata a 384 (per la massima utilizzazione della memoria), con micro-batch di 16 per passo e 24 passaggi di accumulo del gradiente. Sono state utilizzate le tassi di apprendimento di 0,0015 e 0,003 per 8 e 16 nodi, rispettivamente. Con queste configurazioni, abbiamo raggiunto la convergenza della fase 1 di pre-addestramento di BERT 1.5B su 8 istanze dl1.24xlarge (64 acceleratori) in circa 25 ore e 15 ore su 16 istanze dl1.24xlarge (128 acceleratori). La seguente figura mostra la perdita media in funzione del numero di epoche di addestramento, mentre aumentiamo il numero di acceleratori.
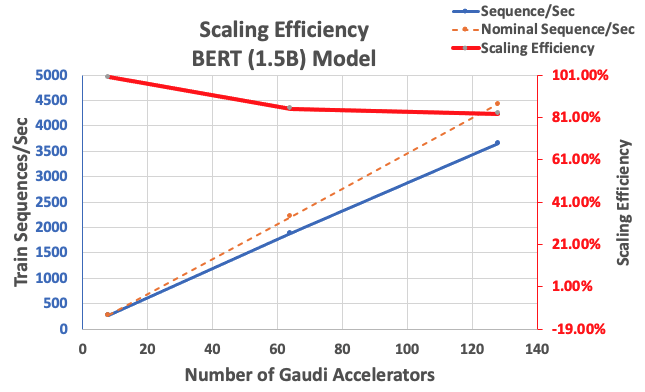
Con la configurazione descritta in precedenza, abbiamo ottenuto un’efficienza di scalabilità forte del 85% con 64 acceleratori e del 83% con 128 acceleratori, rispetto a una base di 8 acceleratori in una singola istanza. La seguente tabella riassume i parametri.
| Numero di istanze | Numero di acceleratori | Sequenze al secondo | Sequenze al secondo per acceleratore | Efficienza di scalabilità |
| 1 | 8 | 276,66 | 34,58 | 100,0% |
| 8 | 64 | 1.883,63 | 29,43 | 85,1% |
| 16 | 128 | 3.659,15 | 28,59 | 82,7% |
La seguente figura illustra l’efficienza di scalabilità.
Conclusione
In questo post, abbiamo valutato il supporto di DeepSpeed da parte di Habana SynapseAI v1.5/v1.6 e come aiuta ad aumentare la scala dell’addestramento LLM su acceleratori Habana Gaudi. La pre-elaborazione di un modello BERT di 1,5 miliardi di parametri richiedeva 16 ore per convergere su un cluster di 128 acceleratori Gaudi, con una scalabilità forte dell’85%. Vi invitiamo a dare un’occhiata all’architettura dimostrata nel workshop AWS e a considerare l’adozione di questa tecnologia per addestrare architetture di modelli PyTorch personalizzati utilizzando istanze DL1.