Ricerca di similarità, Parte 1 kNN e Indice a File Invertito
Similarity search, Part 1 kNN and Inverted File Index.
Introduzione alla ricerca di similarità con kNN e la sua accelerazione con inverted file.

La ricerca di similarità è un problema in cui, dato un query, lo scopo è trovare i documenti più simili ad esso tra tutti i documenti del database.
Introduzione
Nella scienza dei dati, la ricerca di similarità appare spesso nel dominio del NLP, nei motori di ricerca o nei sistemi di raccomandazione in cui i documenti o gli elementi più rilevanti devono essere recuperati per una query. Normalmente, i documenti o gli elementi sono rappresentati sotto forma di testi o immagini. Tuttavia, gli algoritmi di apprendimento automatico non possono lavorare direttamente con testi o immagini grezzi, motivo per cui i documenti e gli elementi sono solitamente preprocessati e memorizzati come vettori di numeri.
A volte ogni componente di un vettore può contenere un significato semantico. In questo caso, tali rappresentazioni vengono anche chiamate embedding. Tali embedding possono avere centinaia di dimensioni e la loro quantità può arrivare fino a milioni! A causa di queste enormi quantità, qualsiasi sistema di recupero delle informazioni deve essere in grado di individuare rapidamente i documenti rilevanti.
- Svelare il Pattern di Progettazione delle Reti Neurali Informate dalla Fisica Parte 06
- Accelerare l’Acceleratore uno scienziato velocizza l’HPC del CERN con le GPU e l’AI
- Microsoft Bing accelera la consegna degli annunci pubblicitari con NVIDIA Triton.
Nell’apprendimento automatico, un vettore è anche chiamato oggetto o punto.
Indice
Per accelerare le prestazioni di ricerca, viene costruita una struttura dati speciale sulla base degli embedding del dataset. Tale struttura dati viene chiamata indice. Ci sono state molte ricerche in questo campo e molti tipi di indici sono stati sviluppati. Prima di scegliere un indice da applicare per un determinato compito, è necessario capire come funziona sotto il cofano poiché ogni indice serve a uno scopo diverso e ha i suoi pro e contro.
In questo articolo, daremo un’occhiata all’approccio più ingenuo – kNN. Sulla base di kNN, passeremo a inverted file – un indice utilizzato per una ricerca più scalabile che può accelerare la procedura di ricerca diverse volte.
kNN
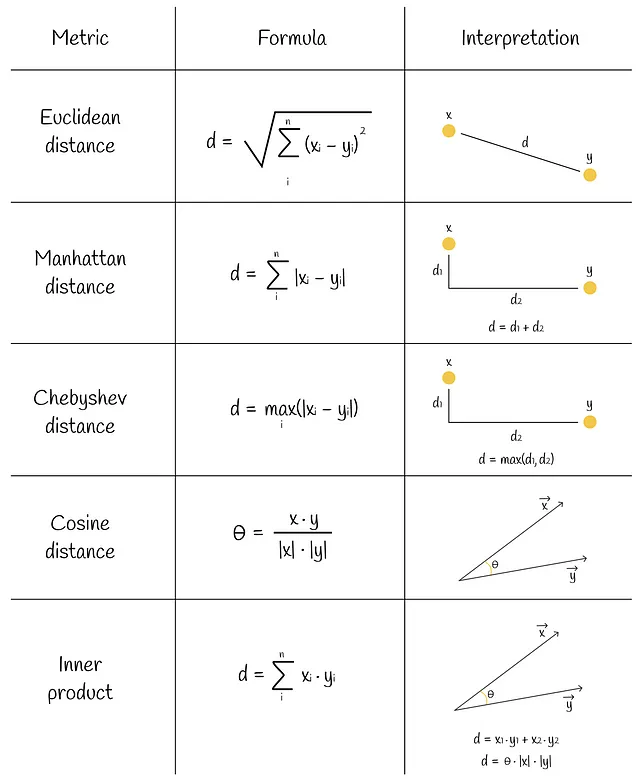
kNN è l’algoritmo più semplice e ingenuo per la ricerca di similarità. Consideriamo un dataset di vettori e un nuovo vettore di query Q. Vorremmo trovare i primi k vettori del dataset che sono più simili a Q. Il primo aspetto da considerare è come misurare la similarità (distanza) tra due vettori. In effetti, ci sono diverse metriche di similarità per farlo. Alcune di esse sono illustrate nella figura qui sotto.
Formazione
kNN è uno degli algoritmi di apprendimento automatico che non richiede una fase di formazione. Dopo aver scelto una metrica appropriata, possiamo fare previsioni direttamente.
Inferenza
Per un nuovo oggetto, l’algoritmo calcola esaustivamente le distanze con tutti gli altri oggetti. Dopodiché, trova i k oggetti con le distanze più piccole e li restituisce come risposta.

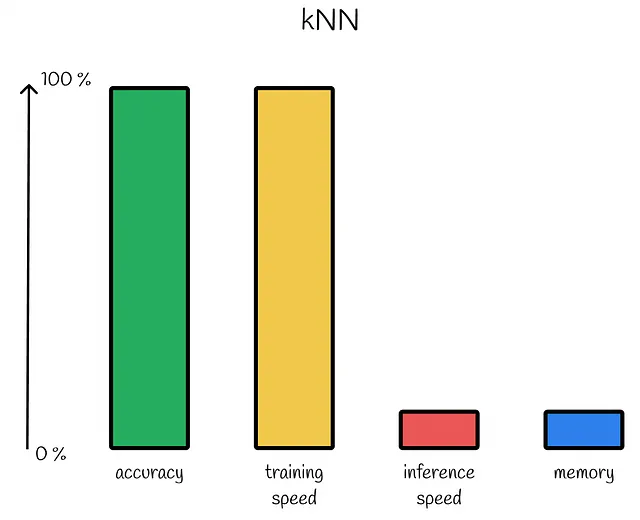
Ovviamente, controllando le distanze con tutti i vettori del dataset, kNN garantisce risultati accurati al 100%. Tuttavia, tale approccio a forza bruta è molto inefficiente in termini di prestazioni temporali. Se un dataset consiste di n vettori con m dimensioni, allora per ciascuno dei n vettori è necessario un tempo di O(m) per calcolare la distanza da esso da una query Q che comporta una complessità totale di O(mn). Come vedremo in seguito, esistono metodi più efficienti.
Inoltre, non esiste un meccanismo di compressione per i vettori originali. Immaginiamo un dataset con miliardi di oggetti. Sarebbe probabilmente impossibile memorizzarli tutti in RAM!
Applicazione
kNN ha un campo di applicazione limitato e dovrebbe essere utilizzato solo in uno dei seguenti scenari:
- La dimensione del dataset o dell’incorporazione è relativamente piccola. Questo aspetto assicura che l’algoritmo funzioni ancora velocemente.
- L’accuratezza richiesta dell’algoritmo deve essere del 100%. In termini di accuratezza, non c’è altro algoritmo di vicini più vicini che possa superare kNN.
La rilevazione di una persona in base alle sue impronte digitali è un esempio di un problema in cui è richiesta un’accuratezza del 100%. Se la persona ha commesso un reato e ha lasciato le sue impronte digitali, è vitale recuperare solo i risultati corretti. In caso contrario, se il sistema non è affidabile al 100%, un’altra persona può essere ritenuta colpevole di un reato, il che è un errore molto critico.
Fondamentalmente, ci sono due modi principali per migliorare kNN (che discuteremo in seguito):
- Ridurre l’ambito di ricerca.
- Ridurre la dimensionalità dei vettori.
Utilizzando uno di questi due approcci, non eseguiremo nuovamente una ricerca esaustiva. Tali algoritmi sono chiamati vicini approssimativi più vicini (ANN) perché non garantiscono risultati accurati al 100%.
Indice di file invertito
**“Indice invertito** (anche indicato come elenco di posting, file di posting o file invertito) è un indice di database che memorizza una mappatura dal contenuto, come parole o numeri, alle sue posizioni in una tabella, o in un documento o in un insieme di documenti” — Wikipedia
Quando si esegue una query, viene calcolata la funzione hash della query e vengono presi i valori mappati dalla tabella hash. Ciascuno di questi valori mappati contiene il proprio insieme di candidati potenziali che vengono quindi completamente controllati in base a una condizione per essere il vicino più vicino della query. In questo modo, l’ambito di ricerca di tutti i vettori del database viene ridotto.
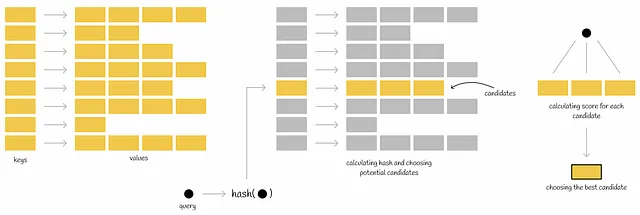
Ci sono diverse implementazioni di questo indice a seconda di come vengono calcolate le funzioni hash. L’implementazione che stiamo per esaminare è quella che utilizza diagrammi di Voronoi (o tessellazione di Dirichlet).
Formazione
L’idea dell’algoritmo è quella di creare diverse regioni non intersecanti a cui ogni punto del dataset apparterrà. Ogni regione ha il suo centroide che punta al centro di quella regione.
A volte le regioni di Voronoi sono indicate come cellule o partizioni.

La proprietà principale dei diagrammi di Voronoi è che la distanza da un centroide a qualsiasi punto della sua regione è inferiore alla distanza da quel punto a un altro centroide.
Inferenza
Quando viene fornito un nuovo oggetto, vengono calcolate le distanze a tutti i centroidi delle partizioni di Voronoi. Quindi viene scelto il centroide con la distanza più bassa e i vettori contenuti in questa partizione vengono presi come candidati.
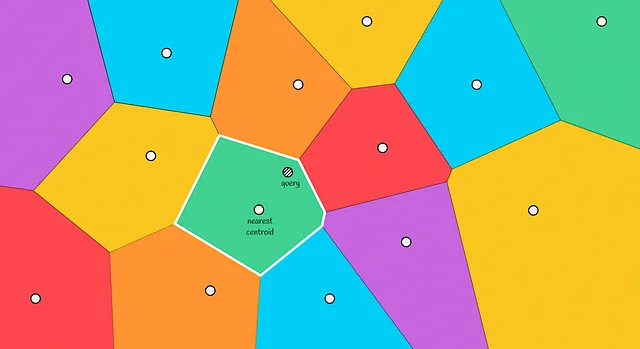
In definitiva, calcolando le distanze ai candidati e scegliendo i primi k più vicini di essi, viene restituita la risposta finale.
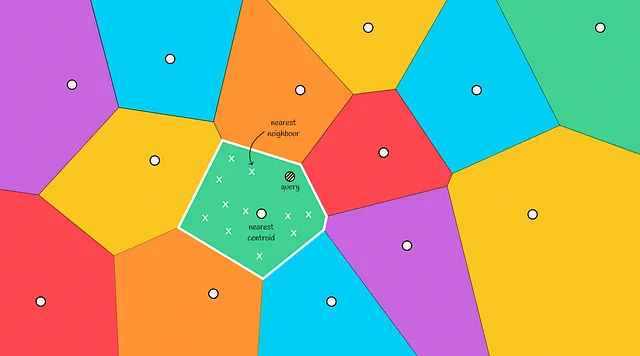
Come puoi vedere, questo approccio è molto più veloce rispetto al precedente poiché non dobbiamo cercare attraverso tutti i vettori del dataset.
Problema dell’orlo
Con l’aumento della velocità di ricerca, l’indice a file invertito presenta un lato negativo: non garantisce che l’oggetto trovato sia sempre il più vicino.
Nella figura qui sotto possiamo vedere un tale scenario: il vicino effettivo più vicino si trova nella regione rossa, ma stiamo selezionando i candidati solo dalla zona verde. Una situazione del genere è chiamata problema dell’orlo.

Questo caso si verifica tipicamente quando l’oggetto interrogato si trova vicino al confine con un’altra regione. Per ridurre il numero di errori in tali casi, possiamo aumentare la portata di ricerca e scegliere diverse regioni in cui cercare i candidati in base ai m centroidi più vicini all’oggetto.
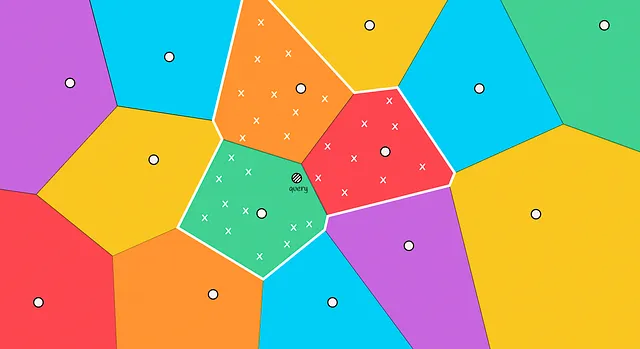
Più regioni vengono esplorate, risultati più accurati e più tempo ci vuole per calcolarli.
Applicazione
Nonostante il problema dell’orlo, l’indice a file invertito mostra risultati decenti in pratica. È perfetto da utilizzare nei casi in cui vogliamo fare un trade-off tra una leggera diminuzione dell’accuratezza e il raggiungimento della crescita della velocità diverse volte.
Uno degli esempi di utilizzo è un sistema di raccomandazione basato sul contenuto. Immaginiamo che raccomandi un film a un utente in base ad altri film che ha visto in passato. Il database contiene un milione di film tra cui scegliere.
- Utilizzando kNN, il sistema sceglie effettivamente il film più rilevante per un utente e lo raccomanda. Tuttavia, il tempo richiesto per eseguire la query è molto lungo.
- Assumiamo che con l’indice a file invertito, il sistema raccomandi il quinto film più rilevante che è probabilmente il caso nella vita reale. Il tempo di ricerca è 20 volte più veloce di kNN.
Dall’esperienza dell’utente, sarà molto difficile distinguere tra il risultato di qualità di queste due raccomandazioni: il primo e il quinto risultato più rilevante sono entrambe buone raccomandazioni tra un milione di possibili film. L’utente sarà probabilmente soddisfatto di entrambe queste raccomandazioni. Dal punto di vista del tempo, l’indice a file invertito è, ovviamente, il vincitore. Ecco perché in questa situazione è meglio utilizzare l’approccio successivo.
Implementazione Faiss
Faiss (Facebook AI Search Similarity) è una libreria Python scritta in C++ utilizzata per la ricerca di similarità ottimizzata. Questa libreria presenta diversi tipi di indici che sono strutture dati utilizzate per archiviare efficacemente i dati e eseguire query.
In base alle informazioni dalla documentazione di Faiss, vedremo come sono creati e parametrizzati gli indici.
kNN
Gli indici che implementano l’approccio kNN sono definiti come flat in Faiss perché non comprimono alcuna informazione. Sono gli unici indici che garantiscono il risultato di ricerca corretto. In realtà, esistono due tipi di indici piatti in Faiss:
- IndexFlatL2. La similarità viene calcolata come distanza euclidea.
- IndexFlatIP. La similarità viene calcolata come prodotto interno.
Entrambi questi indici richiedono un singolo parametro d nei loro costruttori: la dimensione dei dati. Questi indici non hanno alcun parametro regolabile.
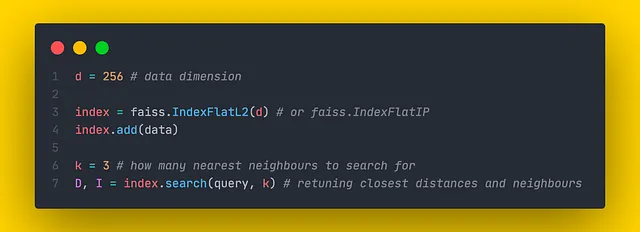
Sono richiesti 4 byte per memorizzare un singolo componente di un vettore. Pertanto, per memorizzare un singolo vettore di dimensionalità d, sono necessari 4 * d byte.

Indice del file invertito
Per il file invertito descritto, Faiss implementa la classe IndexIVFFlat . Come nel caso di kNN, la parola ” Flat ” indica che non c’è alcuna decompressione dei vettori originali e che essi sono completamente memorizzati.
Per creare questo indice, abbiamo prima bisogno di passare un quantizzatore, un oggetto che determinerà come i vettori del database saranno memorizzati e confrontati.
IndexIVFFlat ha 2 parametri importanti:
- nlist definisce il numero di regioni (celle di Voronoi) da creare durante la formazione.
- nprobe determina quanti regioni prendere per la ricerca dei candidati. La modifica del parametro nprobe non richiede la rifomazione.

Come nel caso precedente, abbiamo bisogno di 4 * d byte per memorizzare un singolo vettore. Ma ora dobbiamo anche memorizzare le informazioni sulle regioni di Voronoi a cui appartengono i vettori del dataset. Nell’implementazione di Faiss, queste informazioni richiedono 8 byte per vettore. Pertanto, la memoria richiesta per memorizzare un singolo vettore è:

Conclusione
Siamo passati attraverso due algoritmi base nella ricerca di similarità. Il kNN effettivamente ingenuo dovrebbe essere quasi mai usato per le applicazioni di machine learning a causa della sua scarsa scalabilità, tranne per casi specifici. D’altra parte, il file invertito fornisce buone euristiche per la ricerca accelerata la cui qualità può essere migliorata regolando i suoi iperparametri. Le prestazioni di ricerca possono ancora essere migliorate da diverse prospettive. Nella prossima parte di questa serie di articoli, daremo un’occhiata a uno dei metodi progettati per comprimere i vettori del dataset.
Ricerca di similarità, parte 2: Quantizzazione del prodotto
Nella prima parte di questa serie di articoli, abbiamo esaminato la struttura dell’indice kNN e del file invertito per eseguire la similarità…
Nisoo.com
Risorse
- Indice invertito | Wikipedia
- Documentazione di Faiss
- Repository di Faiss
- Riassunto degli indici di Faiss
- Linee guida per la scelta di un indice
Tutte le immagini, salvo diversa indicazione, sono dell’autore.