Incontra PANOGEN Un Metodo di Generazione che Potenzialmente Può Creare un Numero Infinito di Ambienti Panoramici Diversi Condizionati dal Testo.
PANOGEN un metodo di generazione di ambienti panoramici condizionati dal testo, in grado di produrre un numero infinito di varianti.


Quando qualcuno parla di intelligenza artificiale, la prima cosa che viene in mente è un robot, un androide o un umanoide che può fare cose che gli esseri umani fanno con lo stesso effetto, se non addirittura meglio. Abbiamo tutti visto questi mini robot specifici impiegati in vari campi, ad esempio negli aeroporti per guidare le persone verso determinati punti vendita, nelle forze armate per navigare e affrontare situazioni difficili e persino come tracker.
Tutti questi sono alcuni esempi sorprendenti di AI in senso vero e proprio. Come per ogni altro modello di AI, ci sono alcuni requisiti di base che devono essere soddisfatti, ad esempio la scelta dell’algoritmo, il grande corpus di dati su cui esercitarsi, il raffinamento e quindi la distribuzione.
Ora, questo tipo di problema è spesso definito il problema della navigazione visuale e linguistica. La navigazione visiva e linguistica nell’intelligenza artificiale (AI) si riferisce alla capacità di un sistema di AI di comprendere e navigare nel mondo utilizzando informazioni visive e linguistiche. Combina tecniche di visione artificiale, elaborazione del linguaggio naturale e apprendimento automatico per costruire sistemi intelligenti in grado di percepire scene grafiche, comprendere istruzioni testuali e navigare in ambienti fisici.
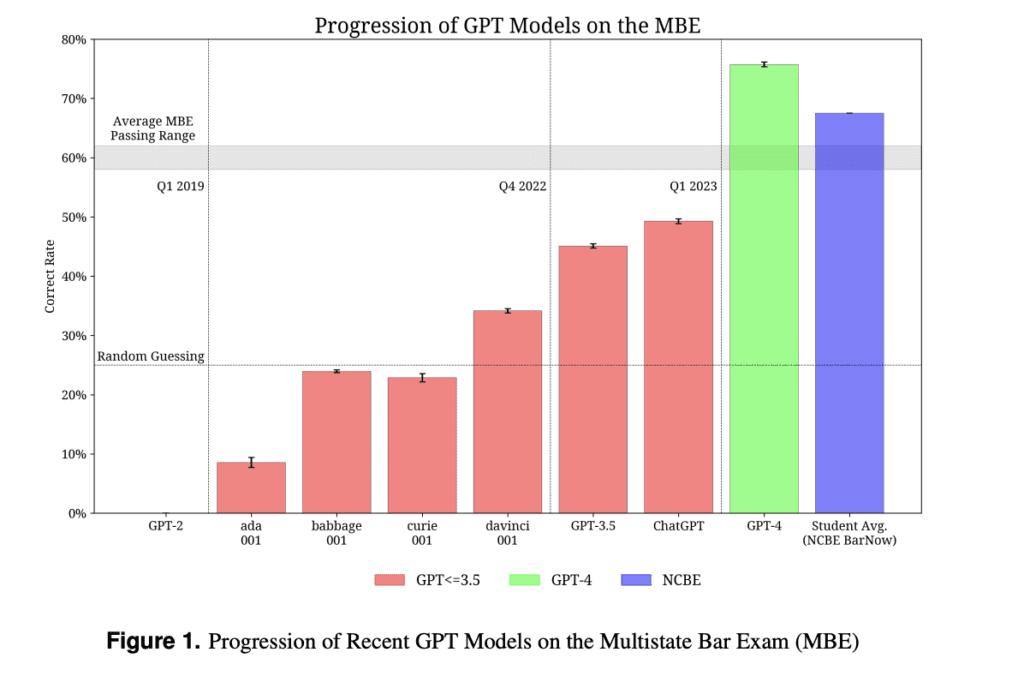
- Microsoft AI presenta Orca un modello di 13 miliardi di parametri che impara a imitare il processo di ragionamento dei LFM (Large Foundation Models).
- Come ho eseguito l’etichettatura automatica delle immagini utilizzando il grounding DINO.
- Corso gratuito di ChatGPT utilizza l’API di OpenAI per creare 5 progetti.
Molti modelli, come CLIP, RecBERT e PREVALENT, lavorano su questi problemi, ma tutti questi modelli soffrono di due problemi principali.
Dati limitati e bias dei dati: l’addestramento dei sistemi visivi e di apprendimento richiede grandi quantità di dati etichettati. Tuttavia, ottenere tali dati può essere costoso, richiedere molto tempo o addirittura impraticabile in alcuni domini. Inoltre, la disponibilità di dati diversi e rappresentativi è cruciale per evitare il bias nella comprensione e nelle decisioni del sistema. Se i dati di addestramento sono sbilanciati, possono portare a previsioni e comportamenti ingiusti o imprecisi.
Generalizzazione: i sistemi di AI devono generalizzare bene per dati non visti o nuovi. Dovrebbero memorizzare i dati di addestramento e apprendere concetti e modelli sottostanti che possono essere applicati a nuovi esempi. L’overfitting si verifica quando un modello funziona bene sui dati di addestramento ma non è in grado di generalizzare per nuovi dati. Raggiungere una generalizzazione robusta è una sfida significativa, soprattutto in compiti visivi complessi che comportano variazioni nelle condizioni di illuminazione, nei punti di vista e nelle apparenze degli oggetti.
Anche se sono stati proposti molti sforzi per aiutare l’agente a imparare ingressi di istruzioni diversi, tutti questi dataset sono costruiti sugli stessi ambienti di camera 3D di Matterport3D, che contiene solo 60 ambienti di camera diversi per l’addestramento degli agenti.
PanoGen, la svolta nel dominio dell’AI, ha fornito una solida soluzione a questo problema. Ora con PanoGen, la scarsità di dati è risolta e la creazione del corpus e la diversificazione dei dati sono state anche semplificate.
PanoGen è un metodo generativo che può creare infinite immagini panoramiche diverse (ambienti) in base al testo. Hanno raccolto descrizioni di stanze descrivendo le immagini delle stanze disponibili con il set di dati Matterport3D e hanno utilizzato un modello di testo-su-immagine SoTA per generare visioni panoramiche (ambienti). Utilizzano quindi la pittura ricorsiva sull’immagine generata per creare una vista panoramica consistente a 360 gradi. Le immagini panoramiche sviluppate condividono informazioni semantiche simili in funzione delle descrizioni testuali, il che garantisce la co-occorrenza degli oggetti nel panorama segue l’intuizione umana e crea abbastanza diversità nell’aspetto e nella disposizione della stanza con la pittura dell’immagine fuori.
Hanno affermato che sono stati fatti tentativi di aumentare la varietà dei dati di addestramento e migliorare il corpus. Tutti quei tentativi si basavano sulla miscelazione di scene da HM3D (Habitat Matterport 3D), che riporta nuovamente allo stesso problema che tutte le impostazioni, più o meno, sono state fatte con Matterport3D.
PanoGen risolve questo problema in quanto può creare un numero infinito di dati di addestramento con quante variazioni sono necessarie.
Nel documento si afferma inoltre che utilizzando l’approccio PanoGen, hanno battuto il SoTA attuale e raggiunto il nuovo SoTA sui dataset Room-to-Room, Room-for-Room e CVDN.
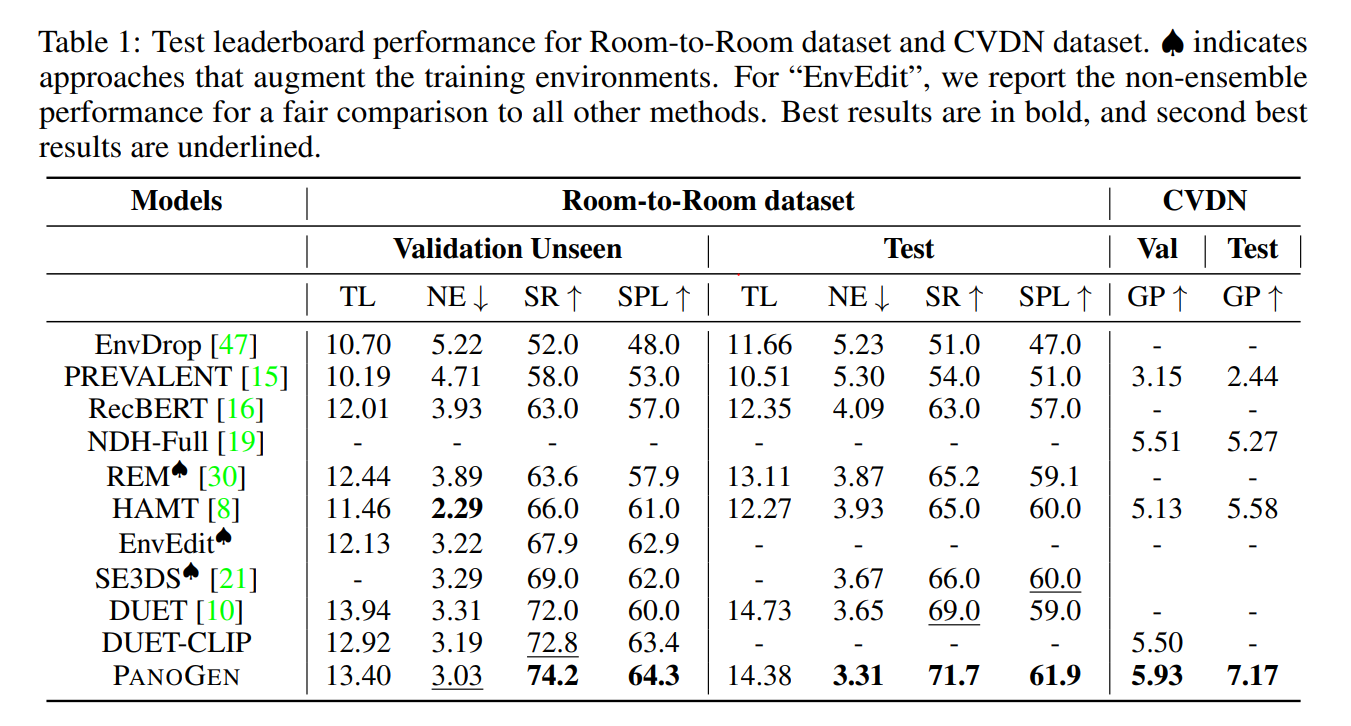
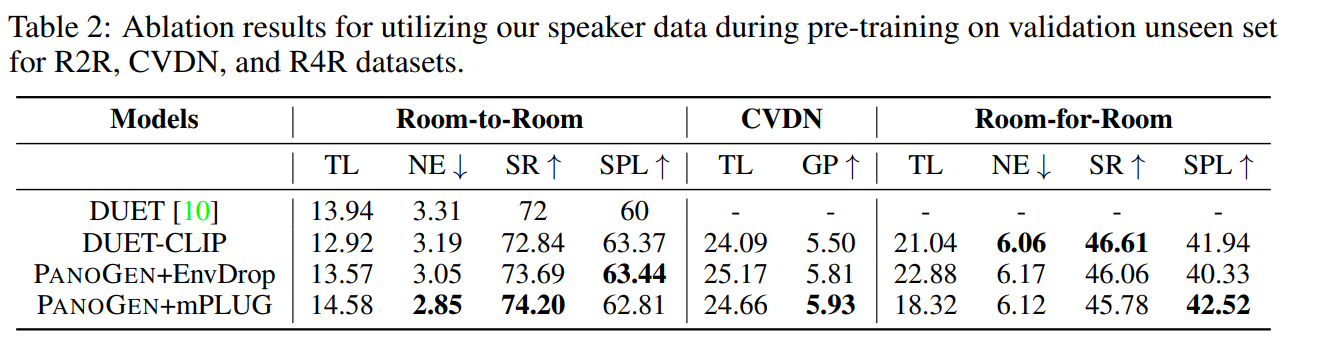
In conclusione, PanoGen è una sviluppo innovativo che affronta le principali sfide nei problemi di navigazione visuale e linguistica. Con la capacità di generare campioni di allenamento illimitati con molte variazioni, PanoGen apre nuove possibilità per i sistemi di intelligenza artificiale per comprendere e navigare nel mondo reale come fanno gli esseri umani. La notevole capacità dell’approccio di superare il SoTA evidenzia il suo potenziale per rivoluzionare i compiti di VLN guidati dall’AI.