Apprendimento Profondo con R
Deep Learning with R.
In questo tutorial, impara come eseguire un’attività di deep learning in R.
Introduzione
Chi non è stato divertito dai progressi tecnologici, in particolare nell’intelligenza artificiale, da Alexa alle auto a guida autonoma di Tesla e miriadi di altre innovazioni? Mi meraviglio dei progressi ogni altro giorno, ma ciò che è ancora più interessante è quando si ha un’idea di ciò che sottostà a quelle innovazioni. Benvenuti nell’Intelligenza Artificiale e nelle infinite possibilità del deep learning. Se vi state chiedendo cos’è, allora siete nel posto giusto.
In questo tutorial, decostruirò la terminologia e vi guiderò attraverso come eseguire un’attività di deep learning in R. Da notare, questo articolo presupporrà che abbiate una comprensione di base dei concetti di machine learning come la regressione, la classificazione e il clustering.
- I migliori framework di AutoML da considerare nel 2023
- Progetto RedPajama un’iniziativa open-source per democratizzare gli LLM
- Tecniche avanzate di selezione delle caratteristiche per i modelli di apprendimento automatico.
Cominciamo con le definizioni di alcune terminologie che circondano il concetto di deep learning:
Il deep learning è un ramo del machine learning che insegna ai computer a imitare le funzioni cognitive del cervello umano. Ciò viene raggiunto attraverso l’uso di reti neurali artificiali che aiutano a scomporre modelli complessi in set di dati. Con il deep learning, un computer può classificare suoni, immagini o persino testi.
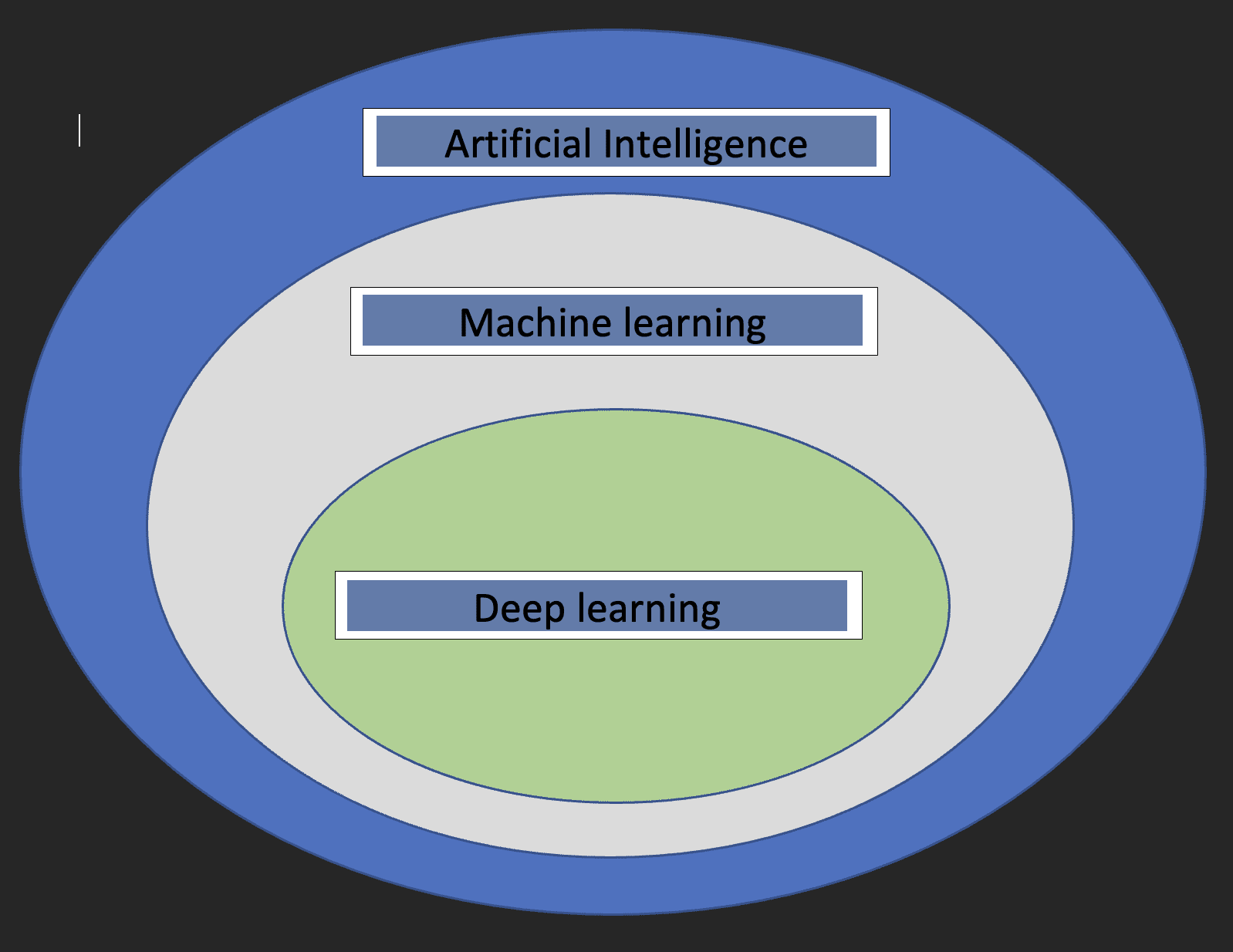
Prima di addentrarci nei dettagli del deep learning, sarebbe bello capire cosa sia il machine learning e l’intelligenza artificiale e come i tre concetti siano correlati tra di loro.
L’intelligenza artificiale: Questo è un ramo dell’informatica che si occupa dello sviluppo di macchine il cui funzionamento imita il cervello umano.
Machine learning: Questo è un sottoinsieme dell’Intelligenza Artificiale che consente ai computer di apprendere dai dati.
Con le definizioni sopra riportate, ora abbiamo un’idea di come il deep learning sia correlato all’intelligenza artificiale e al machine learning.
Il diagramma sottostante aiuterà a mostrare la relazione.
Due cose cruciali da notare sul deep learning sono:
- Richiede enormi volumi di dati
- Richiede una grande potenza di elaborazione
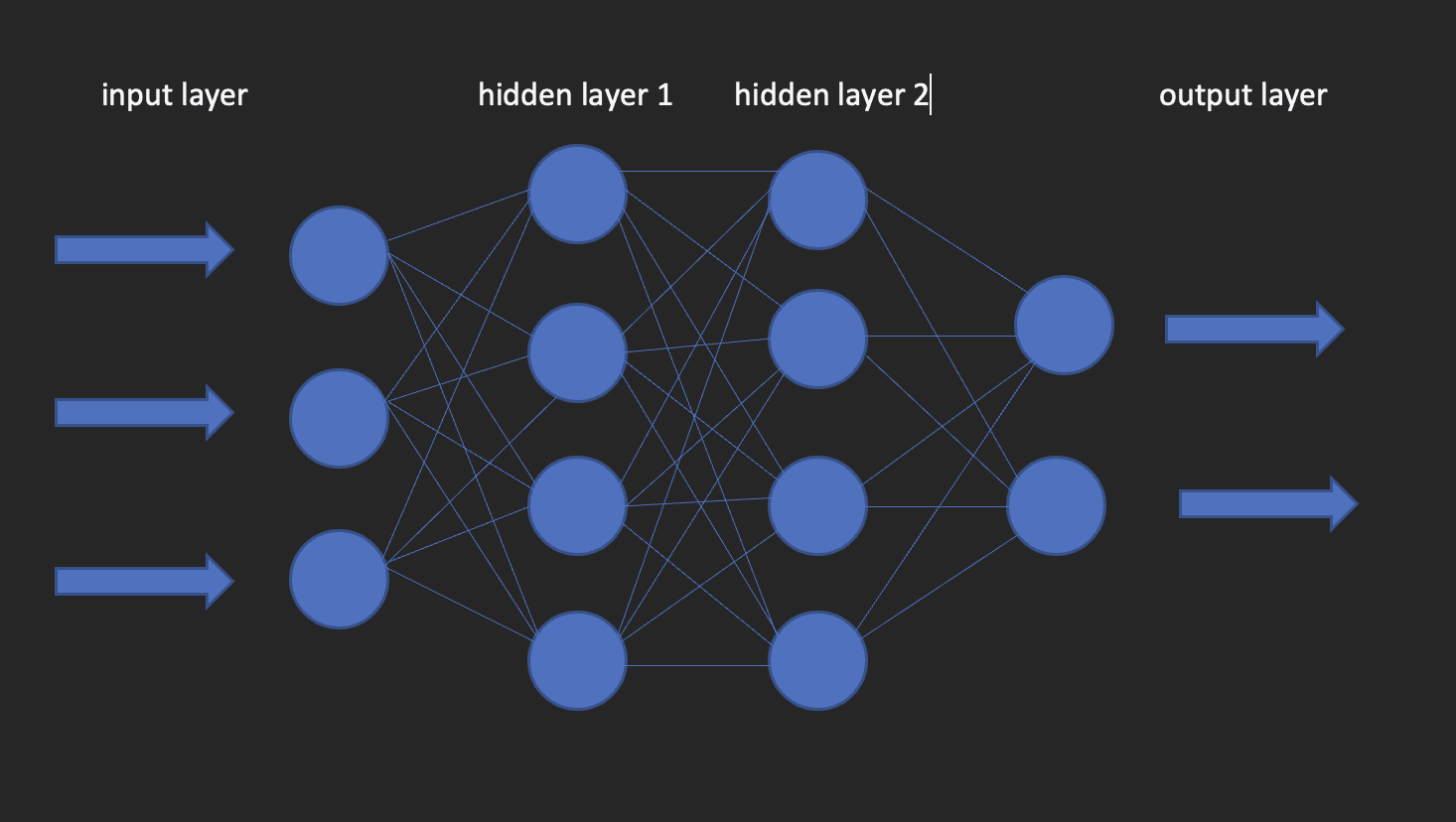
Reti Neurali
Questi sono i mattoni fondamentali dei modelli di deep learning. Come suggerisce il nome, la parola neurale deriva dai neuroni, proprio come i neuroni del cervello umano. In realtà, l’architettura delle reti neurali profonde trae ispirazione dalla struttura del cervello umano.
Una rete neurale ha uno strato di input, uno strato nascosto e uno strato di output. Questa rete viene chiamata rete neurale superficiale. Quando abbiamo più di uno strato nascosto, diventa una rete neurale profonda, dove gli strati potrebbero essere fino a centinaia.
L’immagine sottostante mostra l’aspetto di una rete neurale.
Questo ci porta alla domanda su come costruire modelli di deep learning in R? Entra in gioco kera!
Keras è una libreria di deep learning open-source che facilita l’uso di reti neurali nel machine learning. Questa libreria è un wrapper che utilizza TensorFlow come motore di backend. Tuttavia, ci sono altre opzioni per il backend come Theano o CNTK.
Installiamo ora sia TensorFlow che Keras.
Inizia creando un ambiente virtuale usando reticulate
library(reticulate)
virtualenv_create("virtualenv", python = "/percorso/al/tuo/python3")
install.packages(“tensorflow”) #Fai questo solo una volta!
library(tensorflow)
install_tensorflow(envname = "/percorso/al/tuo/virtualenv", version = "cpu")
install.packages(“keras”) #Fai questo solo una volta!
library(keras)
install_keras(envname = "/percorso/al/tuo/virtualenv")
# confermare che l'installazione sia stata eseguita con successo
tf$constant("Hello TensorFlow!")Ora che le nostre configurazioni sono impostate, possiamo passare a come possiamo utilizzare il deep learning per risolvere un problema di classificazione.
Breve descrizione dei dati
I dati che userò per questo tutorial provengono da un’indagine retributiva in corso effettuata da https://www.askamanager.org.
La domanda principale posta nel modulo è quanto guadagni, oltre ad alcuni dettagli come l’industria, l’età, gli anni di esperienza, ecc. I dettagli vengono raccolti in un foglio Google da cui ho ottenuto i dati.
Il problema che vogliamo risolvere con i dati è quello di essere in grado di creare un modello di deep learning che preveda quanto potrebbe guadagnare una persona dati come età, genere, anni di esperienza e il livello più alto di istruzione.
Carica le librerie che ci serviranno.
library(dplyr)
library(keras)
library(caTools)Importa i dati
url <- “https://raw.githubusercontent.com/oyogo/salary_dashboard/master/data/salary_data_cleaned.csv”
salary_data <- read.csv(url)Seleziona le colonne di cui abbiamo bisogno
salary_data <- salary_data %>% select(age,professional_experience_years,gender,highest_edu_level,annual_salary)Pulizia dei dati
Ricorda il concetto informatico GIGO? (Garbage in Garbage Out). Beh, questo concetto è perfettamente applicabile qui come in altri campi. I risultati del nostro addestramento dipenderanno in gran parte dalla qualità dei dati che utilizziamo. Ecco perché la pulizia e la trasformazione dei dati sono un passaggio critico in qualsiasi progetto di Data Science.
Alcune delle principali questioni affrontate dalla pulizia dei dati sono: la coerenza, i valori mancanti, i problemi di ortografia, gli outlier e i tipi di dati. Non entrerò nei dettagli su come affrontare queste questioni e questo è per il semplice motivo di non voler deviare dal tema di questo articolo. Pertanto, userò la versione pulita dei dati, ma se sei interessato a sapere come è stata gestita la pulizia, dai un’occhiata a questo articolo.
Trasformazioni dei dati
Le reti neurali artificiali accettano solo variabili numeriche e visto che alcune delle nostre variabili sono di natura categorica, dovremo codificare tali variabili in numeri. Questo fa parte del passaggio di pre-elaborazione dei dati, che è necessario perché spesso non si ottengono dati pronti per la modellizzazione.
# crea una funzione di codifica
encode_ordinal <- function(x, order = unique(x)) {
x <- as.numeric(factor(x, levels = order, exclude = NULL))
}
salary_data <- salary_data %>% mutate(
highest_edu_level = encode_ordinal(highest_edu_level, order = c("Diploma di scuola superiore","Laurea triennale","Laurea magistrale","Diploma professionale (MD, JD, ecc.)","PhD")),
professional_experience_years = encode_ordinal(professional_experience_years,
order = c("1 anno o meno", "2 - 4 anni","5-7 anni", "8 - 10 anni", "11 - 20 anni", "21 - 30 anni", "31 - 40 anni", "41 anni o più")),
age = encode_ordinal(age, order = c( "sotto i 18 anni", "18-24 anni","25-34 anni", "35-44 anni", "45-54 anni", "55-64 anni","65 anni o più")),
gender = case_when(gender== "Donna" ~ 0,
gender == "Uomo" ~ 1))Visto che vogliamo risolvere una classificazione, dobbiamo categorizzare il salario annuale in due classi in modo da utilizzarlo come variabile di risposta.
salary_data <- salary_data %>%
mutate(categories = case_when(
annual_salary <= 100000 ~ 0,
annual_salary > 100000 ~ 1))
salary_data <- salary_data %>% select(-annual_salary)Dividi i dati
Come negli approcci di machine learning di base; regressione, classificazione e clustering, dovremo dividere i nostri dati in set di addestramento e di test. Lo facciamo utilizzando la regola 80-20, che prevede l’80% del dataset per l’addestramento e il 20% per il test. Questo non è inciso nella pietra, poiché puoi decidere di utilizzare qualsiasi rapporto di suddivisione come preferisci, ma tieni presente che il set di addestramento dovrebbe avere una buona percentuale.
set.seed(123)
sample_split <- sample.split(Y = salary_data$categories, SplitRatio = 0.7)
train_set <- subset(x=salary_data, sample_split == TRUE)
test_set <- subset(x = salary_data, sample_split == FALSE)
y_train <- train_set$categories
y_test <- test_set$categories
x_train <- train_set %>% select(-categories)
x_test <- test_set %>% select(-categories)Keras accetta input sotto forma di matrici o array. Utilizziamo la funzione as.matrix per la conversione. Inoltre, dobbiamo scalare le variabili predittive e quindi convertire la variabile di risposta in tipo di dato categorico.
x <- come.matrice(apply(x_train, 2, fonction(x) (x-min(x))/(max(x) - min(x))))
y <- to_categorical(y_train, num_classes = 2)Istanziate il modello
Crea un modello sequenziale al quale aggiungeremo i layer usando l’operatore pipe.
model = keras_model_sequential()Configurare i layer
L’input_shape specifica la forma dei dati di input. Nel nostro caso, abbiamo ottenuto questo utilizzando la funzione ncol. activation: Qui specifichiamo la funzione di attivazione; una funzione matematica che trasforma l’output in un formato non lineare desiderato prima di passarlo al layer successivo.
units: il numero di neuroni in ogni layer della rete neurale.
model %>%
layer_dense(input_shape = ncol(x), units = 10, activation = "relu") %>%
layer_dense(units = 10, activation = "relu") %>%
layer_dense(units = 2, activation = "sigmoid")Configurare il processo di apprendimento del modello
Usiamo il metodo compile per farlo. La funzione prende tre argomenti;
optimizer: Questo oggetto specifica la procedura di addestramento. loss: Questa è la funzione da minimizzare durante l’ottimizzazione. Le opzioni disponibili sono mse (errore quadratico medio), binary_crossentropy e categorical_crossentropy.
metrics: Ciò che usiamo per monitorare l’addestramento. Precisione per i problemi di classificazione.
model %>%
compile(
loss = "binary_crossentropy",
optimizer = "adagrad",
metrics = "accuracy"
)Addestramento del modello
Possiamo ora addestrare il modello utilizzando il metodo fit di Keras. Alcuni degli argomenti che fit prende sono:
epochs: Un’epoca è un’iterazione sul dataset di addestramento.
batch_size: Il modello suddivide la matrice/array passata in input in batch più piccoli su cui itera durante l’addestramento.
validation_split: Keras dovrà suddividere una porzione dei dati di addestramento per ottenere un set di validazione che verrà utilizzato per valutare le prestazioni del modello per ogni epoca.
shuffle: Indica se si vuole mischiare i dati di addestramento prima di ogni epoca.
fit = model %>%
fit(
x = x,
y = y,
shuffle = T,
validation_split = 0.2,
epochs = 100,
batch_size = 5
)Valutazione del modello
Per ottenere il valore di accuratezza del modello utilizza la funzione evaluate come segue.
y_test <- to_categorical(y_test, num_classes = 2)
model %>% evaluate(as.matrix(x_test),y_test)Previsione
Per effettuare una previsione su nuovi dati utilizza la funzione predict_classes dalla libreria keras come segue.
model %>% predict(as.matrix(x_test))Conclusione
Questo articolo ti ha guidato attraverso le basi del deep learning con Keras in R. Se vuoi approfondire, giocare con i parametri, sporcarti le mani con la preparazione dei dati e magari scalare i calcoli sfruttando la potenza del cloud computing. Clinton Oyogo, scrittore presso Saturn Cloud, crede che analizzare i dati per ottenere informazioni utili sia una parte fondamentale del suo lavoro quotidiano. Con le sue competenze nella visualizzazione dei dati, nella manipolazione dei dati e nell’apprendimento automatico, si prende cura del suo lavoro come scienziato dei dati.
Originale. Ripubblicato con il permesso.