Valutazione della sintesi vocale in molte lingue con SQuId
Speech synthesis evaluation in multiple languages with SQuId.
Pubblicato da Thibault Sellam, ricercatore di Google
In precedenza, abbiamo presentato l’iniziativa delle 1.000 lingue e il Modello di Discorso Universale con l’obiettivo di rendere disponibili tecnologie di linguaggio e discorso a miliardi di utenti in tutto il mondo. Parte di questo impegno prevede lo sviluppo di tecnologie di sintesi vocale di alta qualità, che si basano su progetti come VDTTS e AudioLM, per gli utenti che parlano molte lingue diverse.
 |
Dopo aver sviluppato un nuovo modello, è necessario valutare se il discorso che genera sia accurato e naturale: il contenuto deve essere rilevante per il compito, la pronuncia corretta, il tono appropriato e non dovrebbero esserci artefatti acustici come crepe o rumore correlato al segnale. Tale valutazione è un ostacolo importante nello sviluppo di sistemi di discorso multilingue.
Il metodo più popolare per valutare la qualità dei modelli di sintesi vocale è la valutazione umana: un ingegnere di text-to-speech (TTS) produce alcune migliaia di affermazioni dal modello più recente, le invia per la valutazione umana e riceve i risultati qualche giorno dopo. Questa fase di valutazione prevede tipicamente test di ascolto, durante i quali decine di annotatori ascoltano le affermazioni una dopo l’altra per determinare quanto suonano naturali. Sebbene gli esseri umani siano ancora imbattibili nel rilevare se un pezzo di testo suona naturale, questo processo può essere impraticabile – specialmente nelle prime fasi dei progetti di ricerca, quando gli ingegneri hanno bisogno di un feedback rapido per testare e ristrategizzare il loro approccio. La valutazione umana è costosa, richiede molto tempo e può essere limitata dalla disponibilità di valutatori per le lingue di interesse.
Un altro ostacolo al progresso è che diversi progetti e istituzioni utilizzano tipicamente valutazioni, piattaforme e protocolli diversi, il che rende impossibili le comparazioni tra mele e mele. In questo senso, le tecnologie di sintesi vocale sono indietro rispetto alla generazione di testo, dove i ricercatori hanno da tempo integrato la valutazione umana con metriche automatiche come BLEU o, più recentemente, BLEURT.
In “SQuId: Misurazione della Naturalità del Discorso in Molte Lingue”, che sarà presentato a ICASSP 2023, presentiamo SQuId (Speech Quality Identification), un modello di regressione a 600 milioni di parametri che descrive in che misura un pezzo di discorso suona naturale. SQuId si basa su mSLAM (un modello di discorso-testo pre-addestrato sviluppato da Google), sintonizzato su oltre un milione di valutazioni di qualità in 42 lingue e testato in 65. Dimostriamo come SQuId possa essere utilizzato per integrare le valutazioni umane per la valutazione di molte lingue. Questo è lo sforzo pubblicato più grande di questo tipo fino ad oggi.
Valutazione TTS con SQuId
L’ipotesi principale alla base di SQuId è che l’addestramento di un modello di regressione sulle valutazioni raccolte in precedenza possa fornirci un metodo a basso costo per valutare la qualità di un modello TTS. Il modello può quindi essere un’aggiunta preziosa alla cassetta degli attrezzi di valutazione di un ricercatore di TTS, fornendo un’alternativa quasi istantanea, sebbene meno accurata, alla valutazione umana.
SQuId prende un’affermazione come input e un tag di locale opzionale (cioè una variante localizzata di una lingua, come “portoghese brasiliano” o “inglese britannico”). Restituisce un punteggio compreso tra 1 e 5 che indica quanto naturale suona la forma d’onda, con un valore più alto che indica una forma d’onda più naturale.
Internamente, il modello include tre componenti: (1) un encoder, (2) un layer di pooling / regressione e (3) un layer completamente connesso. In primo luogo, l’encoder prende uno spettrogramma in ingresso e lo incorpora in una matrice 2D più piccola che contiene 3.200 vettori di dimensioni 1.024, dove ogni vettore codifica un passaggio temporale. Il layer di pooling / regressione aggrega i vettori, aggiunge il tag di locale e alimenta il risultato in un layer completamente connesso che restituisce un punteggio. Infine, applichiamo una post-elaborazione specifica dell’applicazione che ridimensiona o normalizza il punteggio in modo che sia nell’intervallo [1, 5], che è comune per le valutazioni di naturalità umane. Addestriamo l’intero modello end-to-end con una perdita di regressione.
L’encoder è di gran lunga la parte più grande e importante del modello. Abbiamo utilizzato mSLAM , un preesistente Conformer di 600M di parametri preaddestrato sia su parlato (51 lingue) che su testo (101 lingue).
 |
| Il modello SQuId. |
Per addestrare ed valutare il modello, abbiamo creato il corpus SQuId: una collezione di 1,9 milioni di enunciati valutati in 66 lingue, raccolti per oltre 2.000 progetti di ricerca e prodotto TTS. Il corpus SQuId copre una vasta gamma di sistemi, tra cui modelli concatenativi e neurali, per una vasta gamma di casi d’uso, come le indicazioni stradali e gli assistenti virtuali. L’ispezione manuale rivela che SQuId è esposto a una vasta gamma di errori TTS, come artefatti acustici (ad es. crepe e scoppi), prosodia errata (ad es. domande senza intonazioni crescenti in inglese), errori di normalizzazione del testo (ad es. verbalizzare “7/7” come “sette diviso sette” invece di “sette luglio”), o errori di pronuncia (ad es. verbalizzare “tough” come “toe”).
Un problema comune che si presenta durante l’addestramento di sistemi multilingue è che i dati di addestramento potrebbero non essere uniformemente disponibili per tutte le lingue di interesse. SQuId non è stata un’eccezione. La figura seguente illustra la dimensione del corpus per ciascuna zona geografica. Vediamo che la distribuzione è largamente dominata dall’inglese americano.
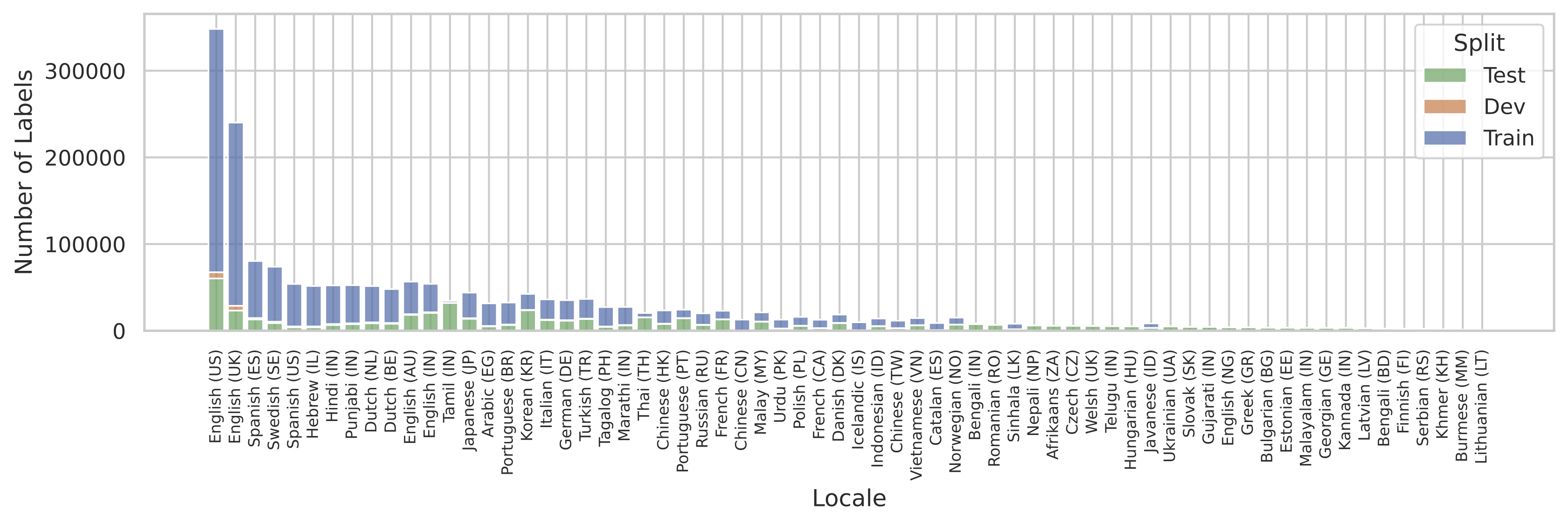 |
| Distribuzione delle zone geografiche nel dataset SQuId. |
Come possiamo fornire una buona performance per tutte le lingue quando ci sono tali variazioni? Ispirati da lavori precedenti sulla traduzione automatica , nonché da lavori precedenti della letteratura sulla parlato , abbiamo deciso di addestrare un modello per tutte le lingue, anziché utilizzare modelli separati per ogni lingua. L’ipotesi è che se il modello è abbastanza grande, allora può avvenire un trasferimento tra le diverse zone geografiche: l’accuratezza del modello su ciascuna zona migliora in seguito all’addestramento congiunto su tutte le altre. Come mostrano i nostri esperimenti, il trasferimento tra le diverse zone geografiche si dimostra un potente driver delle performance.
Risultati sperimentali
Per comprendere le prestazioni complessive di SQuId, lo confrontiamo con un custom Big-SSL-MOS model (descritto nel paper), una baseline competitiva ispirata a MOS-SSL, un sistema di valutazione TTS all’avanguardia. Big-SSL-MOS si basa su w2v-BERT ed è stato addestrato sul dataset VoiceMOS’22 Challenge, il dataset più popolare al momento della valutazione. Abbiamo sperimentato diverse varianti del modello e abbiamo scoperto che SQuId è fino al 50,0% più accurato.
 |
| SQuId versus baselines all’avanguardia. Misuriamo l’accordo con le valutazioni umane utilizzando il Kendall Tau, dove un valore più alto rappresenta una maggiore accuratezza. |
Per capire l’impatto del trasferimento interlingua, abbiamo condotto una serie di studi di ablazione. Abbiamo variato la quantità di lingue introdotte nel set di addestramento e abbiamo misurato l’effetto sull’accuratezza di SQuId. In inglese, che è già sovrarappresentato nel dataset, l’effetto dell’aggiunta di lingue è trascurabile.
 |
| La performance di SQuId in inglese americano, utilizzando 1, 8 e 42 lingue durante la messa a punto. |
Tuttavia, il trasferimento interlingua è molto più efficace per la maggior parte delle altre lingue:
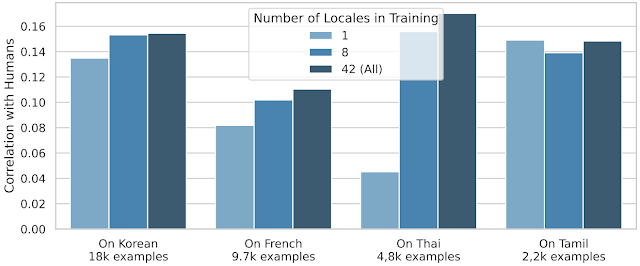 |
| La performance di SQuId in quattro lingue selezionate (coreano, francese, thailandese e tamil), utilizzando 1, 8 e 42 lingue durante la messa a punto. Per ogni lingua, forniamo anche la dimensione del set di addestramento. |
Per spingere il trasferimento al limite, abbiamo tenuto fuori 24 lingue durante l’addestramento e le abbiamo utilizzate esclusivamente per il testing. In questo modo, misuriamo fino a che punto SQuId può gestire lingue che non ha mai visto prima. Il grafico qui sotto mostra che, sebbene l’effetto non sia uniforme, il trasferimento interlingua funziona.
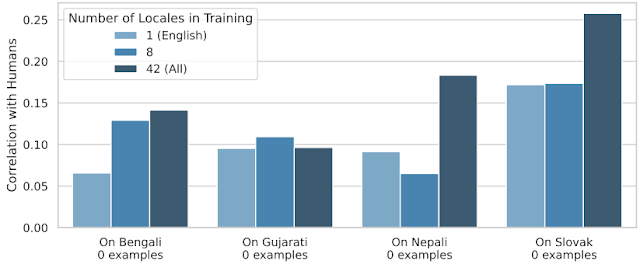 |
| La performance di SQuId in quattro lingue “zero-shot”; utilizzando 1, 8 e 42 lingue durante la messa a punto. |
Quando opera il trasferimento interlingua e come funziona? Presentiamo molte altre ablazioni nel paper e mostriamo che, sebbene la similarità linguistica giochi un ruolo (ad esempio, l’addestramento sul portoghese brasiliano aiuta il portoghese europeo), è sorprendentemente lontana dall’essere l’unico fattore che conta.
Conclusioni e lavoro futuro
Introduciamo SQuId, un modello di regressione con 600 milioni di parametri che sfrutta il dataset di SQuId e l’apprendimento interlingua per valutare la qualità del parlato e descrivere quanto suoni naturale. Dimostriamo che SQuId può integrare i valutatori umani nella valutazione di molte lingue. Il lavoro futuro include il miglioramento dell’accuratezza, l’ampliamento della gamma di lingue coperte e il trattamento di nuovi tipi di errore.
Ringraziamenti
L’autore di questo post fa ora parte di Google DeepMind. Molti ringraziamenti a tutti gli autori del paper: Ankur Bapna, Joshua Camp, Diana Mackinnon, Ankur P. Parikh e Jason Riesa.
