AVFormer Iniettare la visione in modelli di discorso congelati per l’AV-ASR senza sforzo
Inject vision into frozen speech models for effortless AV-ASR.
Pubblicato da Arsha Nagrani e Paul Hongsuck Seo, Scienziati della Ricerca, Google Research
Il riconoscimento automatico della voce (ASR) è una tecnologia consolidata e ampiamente adottata per diverse applicazioni, come le videoconferenze, la trascrizione video in tempo reale e i comandi vocali. Sebbene le sfide per questa tecnologia siano incentrate su input audio rumorosi, lo stream visivo nei video multimodali (ad esempio, TV, video online editati) può fornire forti indizi per migliorare la robustezza dei sistemi ASR – questo è chiamato audiovisual ASR (AV-ASR).
Anche se il movimento delle labbra può fornire segnali forti per il riconoscimento della voce ed è l’area più comune di focus per AV-ASR, la bocca spesso non è direttamente visibile nei video in natura (ad esempio, a causa di punti di vista egocentrici, maschere per il viso e bassa risoluzione) e quindi, un’area emergente di ricerca è quella dell’AV-ASR non vincolato (ad esempio, AVATAR), che investiga il contributo di interi frame visivi, e non solo della regione della bocca.
Tuttavia, la creazione di dataset audiovisivi per l’allenamento dei modelli AV-ASR è impegnativa. Sono stati creati dataset come How2 e VisSpeech a partire da video didattici online, ma sono di piccole dimensioni. Al contrario, i modelli stessi sono tipicamente grandi e consistono sia di encoder visivi che audio, e quindi tendono a sovradattarsi a questi piccoli dataset. Tuttavia, sono stati rilasciati di recente modelli audio-only su larga scala che sono fortemente ottimizzati tramite l’allenamento su larga scala su dati audio-only massivi ottenuti da audiolibri, come LibriLight e LibriSpeech. Questi modelli contengono miliardi di parametri, sono facilmente disponibili e mostrano una forte generalizzazione tra i domini.
- Sottotitoli visivi Utilizzo di grandi modelli linguistici per arricchire le videoconferenze con immagini dinamiche.
- Valutazione della sintesi vocale in molte lingue con SQuId
- Il Machine Learning rivela una sorpresa sul COVID
Con le sfide sopra menzionate in mente, in “AVFormer: Injecting Vision into Frozen Speech Models for Zero-Shot AV-ASR”, presentiamo un metodo semplice per aumentare i modelli esistenti audio-only su larga scala con informazioni visive, contemporaneamente eseguendo l’adattamento di dominio leggero. AVFormer inietta embedding visivi in un modello ASR congelato (simile a come Flamingo inietta informazioni visive in grandi modelli linguistici per compiti di testo-visione) utilizzando adattatori addestrabili leggeri che possono essere addestrati su una piccola quantità di dati video debolmente etichettati con un minimo di tempo e parametri di addestramento aggiuntivi. Introduciamo anche uno schema di curriculum semplice durante l’allenamento, che dimostriamo essere cruciale per consentire al modello di elaborare congiuntamente informazioni audio e visive in modo efficace. Il modello AVFormer risultante raggiunge le prestazioni zero-shot state-of-the-art su tre diversi benchmark AV-ASR (How2, VisSpeech ed Ego4D), mantenendo anche una decente prestazione su benchmark di riconoscimento vocale tradizionali solo audio (ovvero, LibriSpeech).
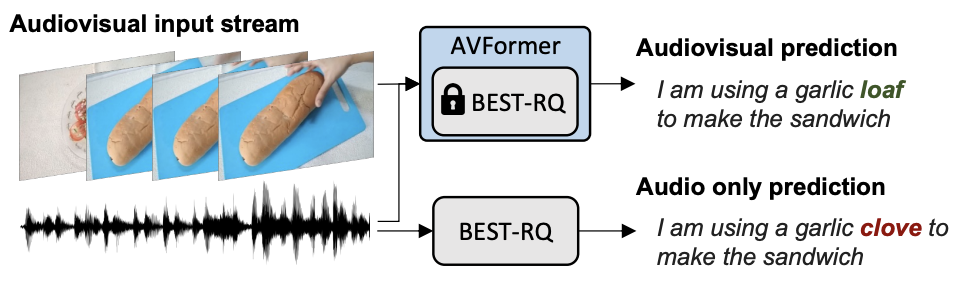 |
| Riconoscimento vocale audiovisivo non vincolato. Iniettiamo la visione in un modello di riconoscimento vocale congelato (BEST-RQ, in grigio) per AV-ASR zero-shot tramite moduli leggeri per creare un modello efficiente in termini di parametri e dati chiamato AVFormer (blu). Il contesto visivo può fornire indizi utili per il riconoscimento robusto della voce, specialmente quando il segnale audio è rumoroso (il visual loaf of bread aiuta a correggere l’errore solo audio “clove” in “loaf” nella trascrizione generata). |
Iniettare la visione utilizzando moduli leggeri
Il nostro obiettivo è quello di aggiungere capacità di comprensione visiva a un modello ASR solo audio esistente mantenendo la sua performance di generalizzazione per vari domini (sia AV che solo audio).
Per raggiungere questo obiettivo, integriamo un modello ASR state-of-the-art esistente (Best-RQ) con i seguenti due componenti: (i) proiettore visivo lineare e (ii) adattatori leggeri. Il primo proietta le caratteristiche visive nello spazio di embedding dei token audio. Questo processo consente al modello di collegare correttamente rappresentazioni di caratteristiche visive pre-addestrate e di input audio del token. Il secondo modifica quindi minimamente il modello per aggiungere la comprensione di input multimodali dai video. Quindi addestriamo questi moduli aggiuntivi su video web non etichettati del dataset HowTo100M, insieme agli output di un modello ASR come pseudo ground truth, mantenendo il resto del modello Best-RQ congelato. Tali moduli leggeri consentono un’efficienza nei dati e una forte generalizzazione delle prestazioni.
Avevamo valutato il nostro modello esteso su benchmark AV-ASR in un ambiente zero-shot, in cui il modello non è mai stato addestrato su un dataset AV-ASR annotato manualmente.
Apprendimento del curriculum per l’iniezione visiva
Dopo la valutazione iniziale, abbiamo scoperto empiricamente che con un singolo round di addestramento congiunto ingenuo, il modello fatica a imparare sia gli adattatori che i proiettori visivi in una sola volta. Per mitigare questo problema, abbiamo introdotto una strategia di apprendimento del curriculum a due fasi che decoppia questi due fattori – adattamento del dominio e integrazione delle caratteristiche visive – e addestra la rete in modo sequenziale. Nella prima fase, i parametri dell’adattatore vengono ottimizzati senza alimentare affatto i token visivi. Una volta addestrati gli adattatori, aggiungiamo i token visivi e addestriamo gli strati di proiezione visivi da soli nella seconda fase, mentre gli adattatori addestrati vengono mantenuti congelati.
La prima fase si concentra sull’adattamento del dominio audio. Nella seconda fase, gli adattatori sono completamente congelati e il proiettore visivo deve semplicemente imparare a generare prompt visivi che proiettano i token visivi nello spazio audio. In questo modo, la nostra strategia di apprendimento del curriculum consente al modello di incorporare input visivi e di adattarsi a nuovi domini audio nei benchmark AV-ASR. Applichiamo ciascuna fase solo una volta, poiché l’applicazione iterativa di fasi alternative porta a una degradazione delle prestazioni.
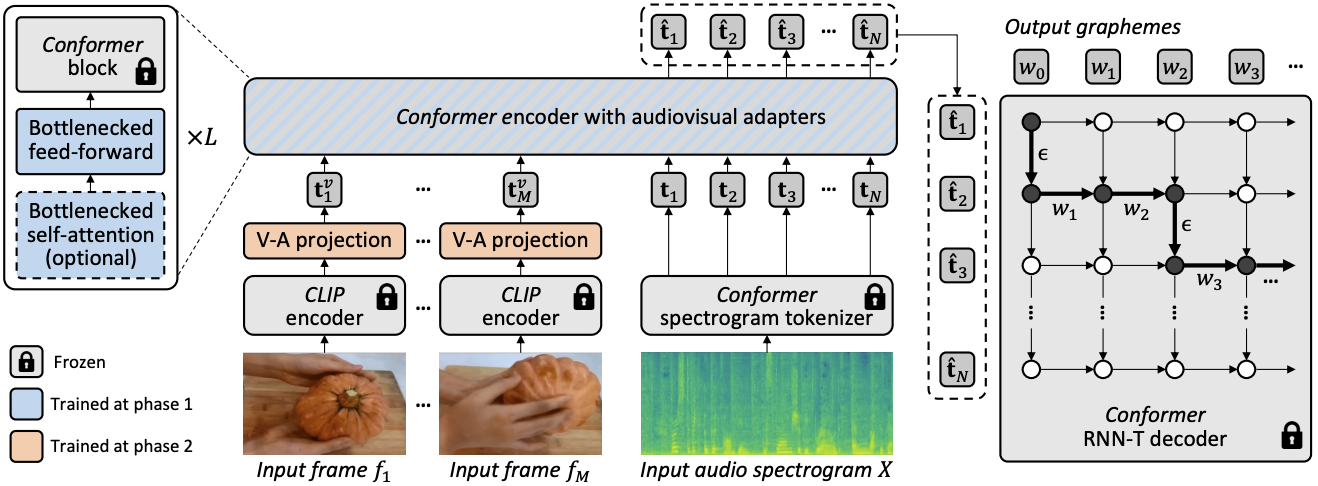 |
| Architettura complessiva e procedura di addestramento per AVFormer. L’architettura consiste in un modello codificatore-decodificatore Conformer congelato e un codificatore CLIP congelato (strati congelati mostrati in grigio con un simbolo di blocco), insieme a due moduli leggeri addestrabili – (i) strato di proiezione visiva (arancione) e adattatori di bottiglia (blu) per consentire l’adattamento del dominio multimodale. Proponiamo una strategia di apprendimento del curriculum a due fasi: gli adattatori (blu) vengono prima addestrati senza alcun token visivo, dopodiché lo strato di proiezione visiva (arancione) viene sintonizzato mentre tutte le altre parti vengono mantenute congelate. |
I grafici qui sotto mostrano che senza apprendimento del curriculum, il nostro modello AV-ASR è peggiore del baseline solo audio in tutti i dataset, con il divario che aumenta all’aumentare dei token visivi. In contrasto, quando viene applicato il curriculum a due fasi proposto, il nostro modello AV-ASR si comporta significativamente meglio del modello solo audio di base.
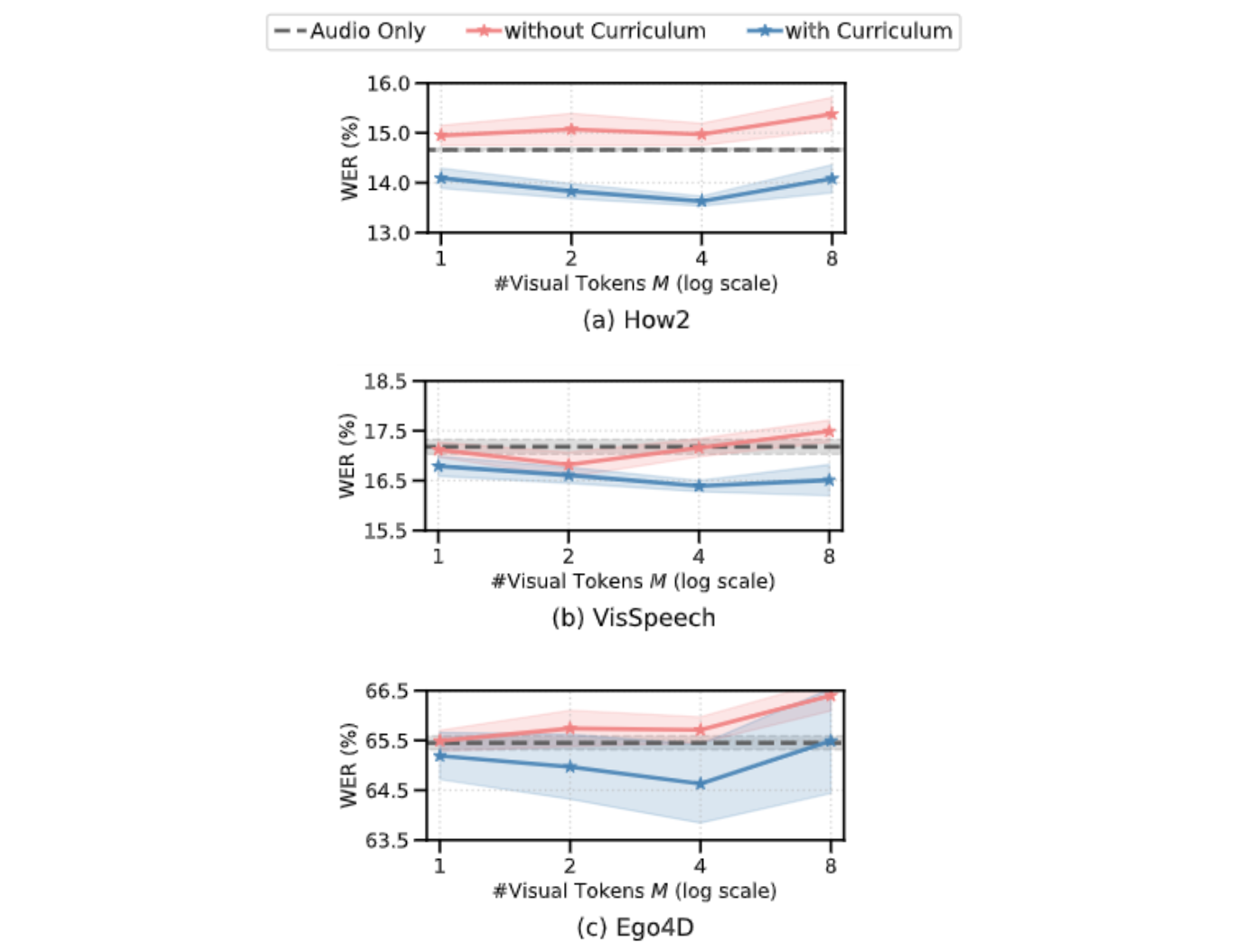 |
| Effetti dell’apprendimento del curriculum. Le linee rosse e blu sono per i modelli audiovisivi e sono mostrate su 3 dataset in un ambiente zero-shot (il WER più basso è migliore). L’uso del curriculum aiuta su tutti e 3 i dataset (per How2 (a) e Ego4D (c) è essenziale per superare le prestazioni solo audio). Le prestazioni migliorano fino a 4 token visivi, momento in cui si saturano. |
Risultati in zero-shot AV-ASR
Confrontiamo AVFormer con BEST-RQ, la versione audio del nostro modello, e AVATAR, lo stato dell’arte in AV-ASR, per le prestazioni zero-shot sui tre benchmark AV-ASR: How2, VisSpeech ed Ego4D. AVFormer supera AVATAR e BEST-RQ su tutti, superando anche sia AVATAR che BEST-RQ quando vengono addestrati su LibriSpeech e l’intero set di HowTo100M. Questo è notevole perché per BEST-RQ, questo comporta l’addestramento di 600M di parametri, mentre AVFormer addestra solo 4M di parametri e richiede quindi solo una piccola frazione del dataset di addestramento (il 5% di HowTo100M). Inoltre, valutiamo anche le prestazioni su LibriSpeech, che è solo audio, e AVFormer supera entrambi i baselines.
.png) |
| Confronto con i metodi all’avanguardia per le prestazioni zero-shot su diversi database AV-ASR. Mostriamo anche le prestazioni su LibriSpeech, che è solo audio. I risultati sono riportati come WER % (più basso è meglio). AVATAR e BEST-RQ sono raffinati end-to-end (tutti i parametri) su HowTo100M, mentre AVFormer funziona efficacemente anche con il 5% del set di dati grazie al piccolo set di parametri raffinati. |
Conclusione
Presentiamo AVFormer, un metodo leggero per adattare i modelli ASR all’avanguardia esistenti e congelati per AV-ASR. Il nostro approccio è pratico ed efficiente, e raggiunge impressionanti prestazioni zero-shot. Man mano che i modelli ASR diventano sempre più grandi, diventa impraticabile sintonizzare l’intero set di parametri dei modelli pre-addestrati (ancora di più per domini diversi). Il nostro metodo consente in modo fluido sia il trasferimento di dominio che la miscelazione dell’input visivo nello stesso modello a basso consumo di parametri.
Riconoscimenti
Questa ricerca è stata condotta da Paul Hongsuck Seo, Arsha Nagrani e Cordelia Schmid.
