Sviluppo di cruscotti interattivi e informativi con Spark e Plotly Dash
Development of interactive and informative dashboards with Spark and Plotly Dash.
Visualizzazione Interattiva di Grandi Volumi di Dati per Applicazioni Web in Python

1. Introduzione
Il data lake cloud è ampiamente adottato dalle organizzazioni aziendali come un repository scalabile e a basso costo di tutti i tipi di dati (strutturati e non strutturati). Ci sono molte sfide nell’analisi di un dataset di grandi dimensioni dal data lake in modo efficiente per ottenere informazioni significative per la presa di decisioni basata sui dati. Una sfida è che la dimensione del dataset tende ad essere troppo grande per essere contenuta in una singola macchina. Un cluster di server è tipicamente richiesto per gestire un grande dataset. Un’altra sfida è come condividere i risultati dell’analisi dei dati sui server con i clienti/azionisti correlati ovunque facilmente ed economicamente.
Questo articolo utilizza lo stesso dataset open source utilizzato in [1] per presentare un framework di applicazione Web basato su open source per lo sviluppo di dashboard interattive e intuitive utilizzando Spark [2][3] e Plotly Dash[4]. Questo framework ci consente di analizzare e visualizzare dataset di grandi dimensioni sui server e condividere i risultati dell’analisi dei dati e della visualizzazione come dashboard ovunque.
Come mostrato nella Figura 1, il nuovo framework di applicazione Web è composto da tre componenti principali:
- Servizio Spark SQL (ad esempio, DataFrame) per l’elaborazione distribuita dei dati (vedi Sezione 2)
- Servizio di grafici Plotly per la creazione di grafici di visualizzazione dei dati come dashboard (vedi Sezione 3)
- Servizio Web di Dash per l’interazione tra il servizio di grafici Plotly lato server e i client dashboard (vedi Sezione 4)

2. Servizio Spark SQL per l’Elaborazione Distribuita dei Dati
Come descritto in [2], PySpark (API Python per Spark) può essere facilmente utilizzato per leggere file csv dal data lake cloud come AWS S3. Per semplicità, si assume in questo articolo che un file csv del dataset train_data.csv [1] sia disponibile sulla macchina locale senza perdita di generalità.
- È un Buon Percorso di Carriera Essere un Analista dei Dati?
- Ingegneria moderna dei dati con MAGE potenziare l’elaborazione efficiente dei dati
- L’AI aiuta a mostrare come i fluidi del cervello scorrono
Il seguente codice serve per caricare il file csv in memoria come Spark SQL DataFrame:
import pysparkfrom pyspark.sql import SparkSessionspark = SparkSession.builder.appName('hospital-stay').getOrCreate()spk_df = spark.read.csv('./data/train_data.csv', header = True, inferSchema = True)Dopo il caricamento dei dati, può essere creato una vista temporanea globale come segue per la comodità della query dinamica dei dati.
spk_df.createOrReplaceTempView("dataset_view")Una volta creata la vista del dataset, possiamo utilizzare Spark SQL per interrogare i dati come una comune query di dati da un database. Come esempio, il seguente codice interroga tutte le righe da dataset_view in cui l’età delle persone rientra nell’intervallo di [21, 30].
age = "21-30"sdf = spark.sql(f"SELECT * FROM dataset_view WHERE Age=='{age}'")Per utilizzare Plotly per creare grafici di visualizzazione dei dati da un DataFrame Spark sdf, dobbiamo convertirlo in un DataFrame Pandas pdf perché Plotly non supporta direttamente DataFrame Spark.
pdf = sdf.toPandas()3. Plotly per la Creazione di Grafici di Visualizzazione dei Dati
Plotly supporta la generazione di molti tipi diversi di grafici. Alcuni di essi sono adatti per creare grafici da caratteristiche numeriche continue, mentre altri sono adatti per creare grafici da caratteristiche categoriche discrete.
Questo articolo utilizza la libreria Plotly Express per creare i seguenti diagrammi comuni a scopo dimostrativo.
- Grafici per caratteristiche numeriche: scatter plot, istogramma e grafico a linee
- Grafici per caratteristiche categoriche: grafico a barre, istogramma, grafico a linee e grafico a torta
3.1 Grafici per Caratteristiche Numeriche
Come descritto in precedenza, tre dei grafici comuni per le feature numeriche sono:
- scatter plot
- istogramma
- grafico a linee
Dati una coppia di feature numeriche, lo scatter plot utilizza ogni coppia di valori delle feature come coordinate per disegnare un punto su un piano 2D. Ad esempio, la seguente figura mostra uno scatter plot di due feature numeriche ID Paziente e Deposito di Ammissione per persone dai 21 ai 30 anni. La feature Tipo di Ammissione viene utilizzata per la codifica dei colori.
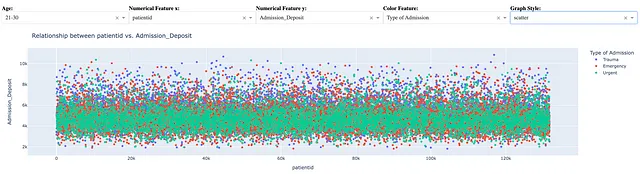
Assumendo che un utente del cruscotto abbia selezionato l’intervallo di età [21, 30], una coppia di feature numeriche x = idpaziente e y = Deposito_Ammissione , e una feature di codifica dei colori = Tipo di Ammissione , la seguente istruzione crea lo scatter plot sopra.
fig = px.scatter(dff, x = x, y = y, color = color_feature)Allo stesso modo, la seguente istruzione viene utilizzata per creare un istogramma dei medesimi dati:
fig = px.histogram(dff, x = x, y = y, color = color_feature)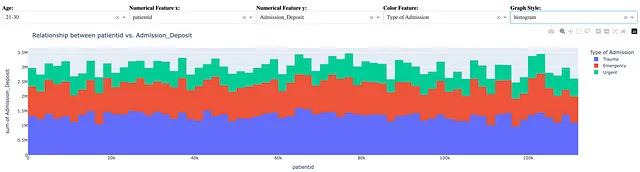
Per essere completi, la seguente istruzione viene utilizzata per creare un grafico a linee.
fig = px.ine(dff, x = x, y = y, color = color_feature)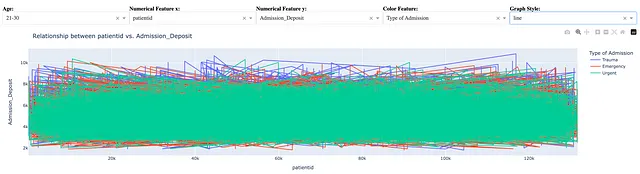
Anche se possiamo facilmente creare un grafico a linee, un grafico a linee come quello sopra non rivela informazioni utili. Un buon utilizzo del grafico a linee è applicarlo a un dataset ordinato in modo significativo, come una sequenza di dati ordinati temporalmente o un elenco di valori di feature ordinati per conteggio come mostrato nella Sezione 3.2.
3.2 Grafici per le Feature Categoriche
Questa sottosezione mostra quattro dei grafici comuni per le feature categoriche:
- grafico a barre
- istogramma
- grafico a linee
- grafico a torta
Assumendo che un utente del cruscotto abbia selezionato età = [21-30], feature categorica = Permanenza , colore = viola , stile del grafico = barre , il seguente codice può essere utilizzato per generare il grafico a barre seguente.
dff = spark.sql(f"SELECT * FROM dataset_view WHERE Age=='{age}'").toPandas()vc = dff[feature].value_counts()fig = px.bar(vc, x = vc.index, y = vc.values)Ho notato che un istogramma ha lo stesso risultato di un grafico a barre per il conteggio dei valori delle feature categoriche.
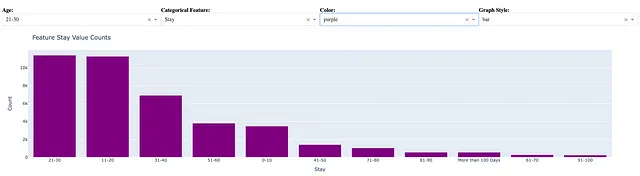
Possiamo creare un grafico a linee come segue selezionando lo stile del grafico = linee :
fig = px.line(vc, x = vc.index, y = vc.values)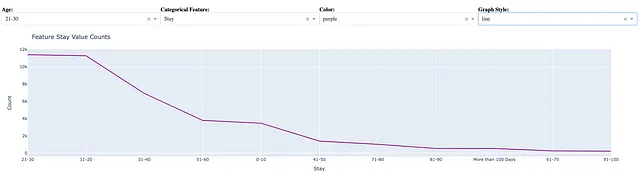
Come già menzionato, il grafico a linee è adatto per visualizzare il conteggio dei valori di una caratteristica categorica.
Il codice qui sotto è per creare un grafico a torta per il conteggio dei valori della stessa caratteristica categorica di Stay.
fig = px.pie(vc, x=vc.index, y=vc.values)Questo grafico a torta utilizza la codifica automatica del colore invece del colore selezionato viola.
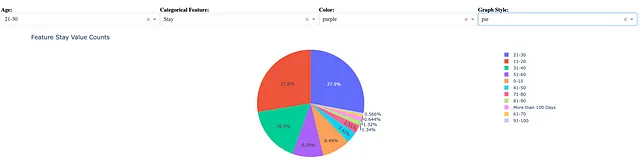
4. Dash per la visualizzazione interattiva dei dati
La sezione precedente descrive come creare cruscotti con diversi tipi di grafici utilizzando la libreria Plotly Express su un cluster di server Spark. Questa sezione mostra come utilizzare Dash per condividere cruscotti con i clienti delle applicazioni Web e consentire loro di utilizzare i cruscotti per visualizzare i dati in vari modi in modo interattivo.
La seguente procedura può essere seguita per sviluppare un cruscotto a pagina singola di un’applicazione Web:
- Passo 1: importare i moduli della libreria Dash
- Passo 2: creare un oggetto applicazione Dash
- Passo 3: definire un layout del cruscotto della pagina HTML
- Passo 4: definire le funzioni di callback (punti finali del servizio Web)
- Passo 5: avviare il server
4.1 Importare i moduli della libreria Dash
Come primo passo, i moduli della libreria Plotly Dash vengono importati come segue per lo scopo di dimostrazione in questo articolo.
import plotly.express as pxfrom dash import Dash, dcc, html, callback, Input, Output4.2 Creare un oggetto applicazione Dash
Dopo aver importato i moduli della libreria, il passo successivo consiste nel creare un oggetto applicazione Dash:
app = Dash(__name__)4.3 Definire il layout del cruscotto
Dopo aver creato un oggetto applicazione Dash, è necessario definire un layout del cruscotto come pagina HTML.
In questo articolo, la pagina HTML del cruscotto è divisa in due parti:
- Parte 1: visualizzazione delle caratteristiche numeriche
- Parte 2: visualizzazione delle caratteristiche categoriche
La parte 1 del layout del cruscotto è definita come segue:
app.layout = html.Div([ # layout del cruscotto html.Div([ # Parte 1 html.Div([ html.Label(['Età:'], style={'font-weight': 'bold', "text-align": "center"}), dcc.Dropdown( ['0-10', '11-20', '21-30', '31-40', '41-50', '51-60', '61-70', '71-80', '81-90', '91-100', 'Più di 100 giorni'], value='21-30', id='numerical_age' ), ], style={'width': '20%', 'display': 'inline-block'}), html.Div([ html.Label(['Caratteristica numerica x:'], style={'font-weight': 'bold', "text-align": "center"}), dcc.Dropdown( ['patientid', 'Hospital_code', 'City_Code_Hospital'], value='patientid', id='axis_x', ) ], style={'width': '20%', 'display': 'inline-block'}), html.Div([ html.Label(['Caratteristica numerica y:'], style={'font-weight': 'bold', "text-align": "center"}), dcc.Dropdown( ['Hospital_code', 'Admission_Deposit', 'Bed Grade', 'Available Extra Rooms in Hospital', 'Visitatori con il paziente', 'Bed Grade', 'City_Code_Patient'], value='Admission_Deposit', id='axis_y' ), ], style={'width': '20%', 'display': 'inline-block'}), html.Div([ html.Label(['Caratteristica colore:'], style={'font-weight': 'bold', "text-align": "center"}), dcc.Dropdown( ['Severity of Illness', 'Stay', 'Department', 'Ward_Type', 'Ward_Facility_Code', 'Type of Admission', 'Hospital_region_code'], value='Type of Admission', id='color_feature' ), ], style={'width': '20%', 'display': 'inline-block'}), html.Div([ html.Label(['Stile del grafico:'], style={'font-weight': 'bold', "text-align": "center"}), dcc.Dropdown( ['scatter', 'histogram', 'line'], value='histogram', id='numerical_graph_style' ), ], style={'width': '20%', 'float': 'right', 'display': 'inline-block'}) ], style={ 'padding': '10px 5px' }), html.Div([ dcc.Graph(id='numerical-graph-content') ]),......Le Figure 2, 3 e 4 sono create utilizzando la Parte 1 della disposizione del dashboard.
La Parte 2 della disposizione del dashboard è definita come segue:
......html.Div([ # Parte 2 html.Div([ html.Label(['Età:'], style={'font-weight': 'bold', "text-align": "center"}), dcc.Dropdown( ['0-10', '11-20', '21-30', '31-40', '41-50', '51-60', '61-70', '71-80', '81-90', '91-100', 'Oltre 100 giorni'], value='21-30', id='categorical_age' ), ], style={'width': '25%', 'display': 'inline-block'}), html.Div([ html.Label(['Funzione Categorica:'], style={'font-weight': 'bold', "text-align": "center"}), dcc.Dropdown( ['Gravità della malattia', 'Permanenza', 'Reparto', 'Tipo di reparto', 'Codice struttura del reparto', 'Tipo di ammissione', 'Codice regione ospedale'], value='Permanenza', id='categorical_feature' ), ], style={'width': '25%', 'display': 'inline-block'}), html.Div([ html.Label(['Colore:'], style={'font-weight': 'bold', "text-align": "center"}), dcc.Dropdown( ['rosso', 'verde', 'blu', 'arancione', 'viola', 'nero', 'giallo'], value='blu', id='categorical_color' ), ], style={'width': '25%', 'display': 'inline-block'}), html.Div([ html.Label(['Stile del grafico:'], style={'font-weight': 'bold', "text-align": "center"}), dcc.Dropdown([ 'istogramma', 'barra', 'linea', 'torta'], value='barra', id='categorical_graph_style' ), ], style={'width': '25%', 'float': 'right', 'display': 'inline-block'}) ], style={ 'padding': '10px 5px' }), html.Div([ dcc.Graph(id='categorical-graph-content') ])]) # fine della disposizione del dashboardLe Figure 5, 6 e 7 sono create utilizzando la Parte 2 della disposizione del dashboard.
4.4 Definire le funzioni di callback
La disposizione del dashboard crea solo una pagina HTML statica di un dashboard. Le funzioni di callback (cioè, i punti finali del servizio Web) devono essere definite in modo che l’azione dell’utente del dashboard possa essere inviata a una funzione di callback lato server come richiesta di servizio Web. In altre parole, le funzioni di callback consentono l’interazione tra gli utenti del dashboard e i servizi Web del dashboard lato server, come la creazione di un nuovo grafico su richiesta dell’utente (ad esempio, selezionare una scelta a discesa).
Ci sono due funzioni di callback definite in questo documento per le due parti della disposizione del dashboard.
La funzione di callback per la Parte 1 della disposizione del dashboard è definita come segue:
@callback( Output('numerical-graph-content', 'figure'), Input('axis_x', 'value'), Input('axis_y', 'value'), Input('numerical_age', 'value'), Input('numerical_graph_style', 'value'), Input('color_feature', 'value'))def update_numerical_graph(x, y, age, graph_style, color_feature): dff = spark.sql(f"SELECT * FROM dataset_view WHERE Age=='{age}'").toPandas() if graph_style == 'line': fig = px.line(dff, x = x, y = y, color = color_feature ) elif graph_style == 'istogramma': fig = px.histogram(dff, x = x, y = y, color = color_feature ) else: fig = px.scatter(dff, x = x, y = y, color = color_feature ) fig.update_layout( title=f"Relazione tra {x} e {y}", ) return figLa funzione di callback per la Parte 2 della disposizione del dashboard è definita come segue:
@callback( Output('categorical-graph-content', 'figure'), Input('categorical_feature', 'value'), Input('categorical_age', 'value'), Input('categorical_graph_style', 'value'), Input('categorical_color', 'value'))def update_categorical_graph(feature, age, graph_style, color): dff = spark.sql(f"SELECT * FROM dataset_view WHERE Age=='{age}'").toPandas() vc = dff[feature].value_counts() if graph_style == 'barra': fig = px.bar(vc, x = vc.index, y = vc.values ) elif graph_style == 'istogramma': fig = px.histogram(vc, x = vc.index, y = vc.values ) elif graph_style == 'linea': fig = px.line(vc, x = vc.index, y = vc.values ) else: fig = px.pie(vc, names = vc.index, values = vc.values ) if graph_style == 'linea': fig.update_traces(line_color=color) elif graph_style != 'torta': fig.update_traces(marker_color=color) fig.update_layout( title=f"Conteggio dei valori della funzione {feature}", xaxis_title=feature, yaxis_title="Conteggio" ) return figOgni funzione di callback è associata a un’annotazione @ callback. L’annotazione associata a una funzione di callback controlla quali componenti HTML (ad esempio, un menu a discesa) forniscono input alla funzione di callback su richiesta degli utenti e quale componente HTML (ad esempio, un grafico all’interno di un tag div) riceve l’output della funzione di callback.
4.5 Avvio del server
Il passaggio finale di un’applicazione Web Dash è avviare un server di servizio Web come indicato di seguito:
if __name__ == "__main__": app.run_server()Il diagramma seguente mostra uno scenario del cruscotto quando un utente del cruscotto ha selezionato le seguenti scelte nel cruscotto:
- età da 21 a 30
- coppia di caratteristiche numeriche patientid e Admission_Deposit
- caratteristica categorica Tipo di ammissione per la codifica a colori della visualizzazione delle caratteristiche numeriche
- grafico a dispersione per la visualizzazione delle caratteristiche numeriche
- caratteristica categorica Stay per il calcolo dei conteggi delle caratteristiche
- colore blu per grafico a barre, istogramma e grafico a linee
- grafico a torta con codifica automatica del colore per la visualizzazione dei conteggi dei valori delle caratteristiche categoriche
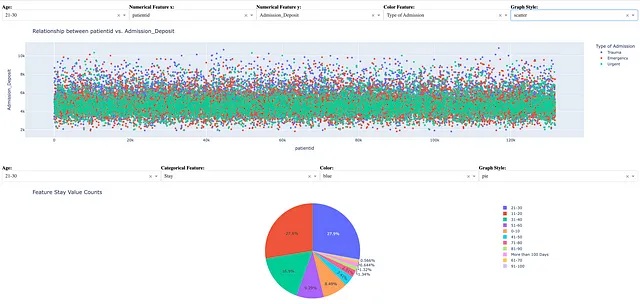
Come esempio di acquisizione di possibili informazioni utili, lo scenario del cruscotto sopra riportato rivela le seguenti informazioni:
- la maggioranza dei pazienti tra i 21 e i 30 anni aveva un deposito tra $3.000 e $6.000, indipendentemente da quanto tempo sono rimasti in ospedale
- la maggioranza dei pazienti tra i 21 e i 30 anni è rimasta in ospedale per 11-30 giorni (27,6%) o 21-30 giorni (27,9%)
La figura seguente mostra un altro scenario del cruscotto quando un utente del cruscotto ha selezionato le seguenti scelte nel cruscotto:
- età da 21 a 30
- coppia di caratteristiche numeriche patientid e Admission_Deposit
- caratteristica categorica Tipo di ammissione per la codifica a colori della visualizzazione delle caratteristiche numeriche
- istogramma per la visualizzazione delle caratteristiche numeriche
- Caratteristica categorica Tipo di ammissione
- colore verde per grafico a barre, istogramma e grafico a linee
- grafico a barre per la visualizzazione dei conteggi dei valori delle caratteristiche categoriche
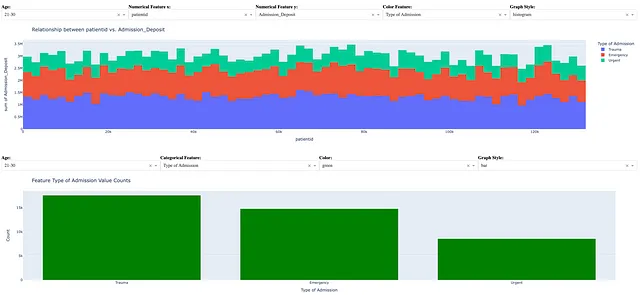
Come altro esempio di acquisizione di possibili informazioni utili, lo scenario del cruscotto sopra riportato rivela le seguenti informazioni:
- i pazienti in cura urgente avevano un deposito totale più alto rispetto ai pazienti in altri tipi di ammissione
- la maggioranza dei pazienti è stata ammessa come trauma
In sintesi, il cruscotto consente all’utente di visualizzare i dati in modi flessibili per acquisire varie informazioni utili in modo interattivo, tra cui:
- visualizzare caratteristiche numeriche e categoriche in un determinato intervallo di età come 0-10, 11-20, …, ecc.
- visualizzare qualsiasi coppia di caratteristiche numeriche in grafici a dispersione, istogrammi e/o grafici a linee
- usare qualsiasi valore di caratteristica categorica per la codifica a colori per la visualizzazione delle caratteristiche numeriche
- visualizzare i conteggi dei valori di qualsiasi caratteristica categorica come grafico a barre/istogramma, grafico a linee e/o grafico a torta con diverse codifiche a colori
5. Conclusioni
Questo articolo ha presentato un framework di applicazione Web open source in Python per lo sviluppo di cruscotti interattivi e informativi utilizzando Spark [3] e Plotly Dash[4]. Questo framework ci consente di analizzare dataset su larga scala dal data lake Cloud, creare cruscotti interattivi sui server Spark e consentire agli utenti di interagire con i cruscotti ovunque per visualizzare i dati in modi flessibili per acquisire varie informazioni utili.
Riferimenti
[1] Yu Huang, Predicting Hospitalized Time of Covid-19 Patients
[2] PySpark AWS S3 Read Write Operations
[3] Esempi di Apache Spark
[4] Guida utente di Dash Python