Bilanciamento del carico efficace con Ray su Amazon SageMaker
Bilanciamento del carico efficace con Ray su Amazon SageMaker' can be condensed as 'Efficient load balancing with Ray on Amazon SageMaker
Un metodo per aumentare l’efficienza dell’addestramento delle DNN e ridurre i costi di addestramento
In precedenti articoli (ad esempio, qui) abbiamo approfondito l’importanza del profilare e ottimizzare le prestazioni dei tuoi carichi di lavoro di addestramento delle DNN. Addestrare modelli di deep learning – soprattutto quelli grandi – può essere un’operazione costosa. La tua capacità di massimizzare l’utilizzo delle risorse di addestramento in modo da accelerare la convergenza del tuo modello e ridurre al minimo i costi di addestramento può essere un fattore decisivo per il successo del tuo progetto. L’ottimizzazione delle prestazioni è un processo iterativo in cui identifichiamo e affrontiamo i colli di bottiglia delle prestazioni nella nostra applicazione, ovvero le parti della nostra applicazione che ci impediscono di aumentare l’utilizzo delle risorse e/o accelerare il tempo di esecuzione.
Questo post è il terzo di una serie di post che si concentrano su uno dei colli di bottiglia delle prestazioni più comuni che incontriamo durante l’addestramento dei modelli di deep learning, ovvero il collo di bottiglia del pre-processing dei dati. Un collo di bottiglia del pre-processing dei dati si verifica quando la nostra GPU (o un acceleratore alternativo) – tipicamente la risorsa più costosa nella nostra configurazione di addestramento – si trova inattiva mentre attende l’input dei dati da risorse CPU sovraccaricate.
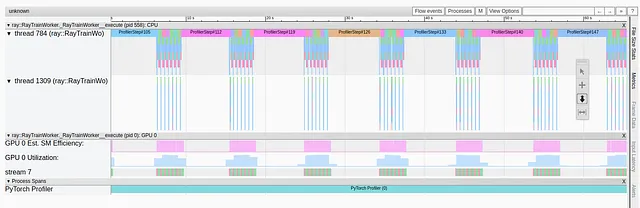
Nel nostro primo post sull’argomento abbiamo discusso e dimostrato diversi modi per affrontare questo tipo di collo di bottiglia, tra cui:
- Scegliere un’istanza di addestramento con un rapporto di calcolo CPU-GPU più adatto al tuo carico di lavoro,
- Migliorare il bilanciamento del carico di lavoro tra CPU e GPU spostando alcune delle operazioni della CPU sulla GPU, e
- Trasferire parte dei calcoli della CPU a dispositivi CPU ausiliari.
Abbiamo dimostrato la terza opzione utilizzando l’API del servizio dati di TensorFlow, una soluzione specifica per TensorFlow, in cui una parte del pre-processing dei dati in input può essere trasferita su altri dispositivi utilizzando gRPC come protocollo di comunicazione sottostante.
- Cosa è Langchain e i modelli di lingua di grandi dimensioni?
- Chiacchierare secondo le tue esigenze Il mio percorso nell’applicazione di Generative AI (LLM) alle specifiche del software
- Creazione di abilità personalizzate per i chatbot con i plugin
Nel nostro secondo post, abbiamo proposto una soluzione basata su gRPC più generica per l’utilizzo di CPU ausiliarie e l’abbiamo dimostrata su un modello giocattolo di PyTorch. Sebbene richiedesse un po’ più di codifica e ottimizzazione manuale rispetto all’API del servizio dati di TensorFlow, la soluzione offriva una maggiore robustezza e consentiva la stessa ottimizzazione delle prestazioni di addestramento.
Bilanciamento del carico con Ray
In questo post mostreremo un altro metodo per utilizzare CPU ausiliarie che mira a combinare la robustezza della soluzione generica con la semplicità e la facilità d’uso dell’API specifica di TensorFlow. Il metodo che mostreremo utilizzerà i Ray Datasets della libreria Ray Data. Sfruttando tutta la potenza dei sistemi di gestione delle risorse e di pianificazione distribuiti di Ray, Ray Data è in grado di eseguire il nostro pipeline di input dei dati di addestramento in modo scalabile e distribuito. In particolare, configureremo il nostro Ray Dataset in modo tale che la libreria rilevi automaticamente e utilizzi tutte le risorse CPU disponibili per il pre-processing dei dati di addestramento. Avvolgeremo inoltre il nostro ciclo di addestramento del modello con un Ray AIR Trainer per consentire una scalabilità senza problemi in un ambiente multi-GPU.
Deployment di un cluster Ray su Amazon SageMaker
Un prerequisito per utilizzare il framework Ray e le sue utilità in un ambiente multi-nodo è il deployment di un cluster Ray. In generale, progettare, distribuire, gestire e mantenere un cluster di calcolo di questo tipo può essere un compito arduo e richiede spesso un ingegnere devops dedicato (o un team di ingegneri). Ciò può rappresentare un ostacolo insormontabile per alcuni team di sviluppo. In questo post mostreremo come superare questo ostacolo utilizzando il servizio di addestramento gestito di AWS, Amazon SageMaker. In particolare, creeremo un cluster eterogeneo di SageMaker con istanze GPU e istanze CPU e lo utilizzeremo per distribuire un cluster Ray all’avvio. Successivamente eseguiremo l’applicazione di addestramento Ray AIR su questo cluster Ray, affidandoci alla backend di Ray per eseguire un efficace bilanciamento del carico su tutte le risorse del cluster. Al termine dell’applicazione di addestramento, il cluster Ray verrà automaticamente smantellato. Utilizzando SageMaker in questo modo, siamo in grado di distribuire e utilizzare un cluster Ray senza gli oneri comunemente associati alla gestione del cluster.
Ray è un framework potente che consente una vasta gamma di carichi di lavoro di machine learning. In questo post mostreremo solo alcune delle sue capacità e API utilizzando Ray versione 2.6.1. Questo post non dovrebbe essere utilizzato come sostituto della documentazione di Ray. Assicurarsi di consultare la documentazione ufficiale per l’utilizzo più appropriato e aggiornato delle utility di Ray.
Prima di iniziare, un ringraziamento speciale a Boruch Chalk per avermi introdotto alla libreria Ray Data e alle sue capacità uniche.
Esempio di gioco
Per facilitare la nostra discussione, definiremo e addestreremo un semplice modello di classificazione basato su PyTorch (2.0) Vision Transformer che addestreremo su un dataset sintetico composto da immagini e etichette casuali. La documentazione di Ray AIR include una vasta varietà di esempi che dimostrano come creare diversi tipi di carichi di lavoro di addestramento utilizzando Ray AIR. Lo script che creiamo qui segue in modo generale i passaggi descritti nell’esempio del classificatore di immagini PyTorch.
Definizione del dataset e del preprocessor di Ray
La API del Trainer di Ray AIR distingue tra il dataset grezzo e la pipeline di preprocessing che viene applicata agli elementi del dataset prima di alimentarli nel ciclo di addestramento. Per il nostro dataset grezzo di Ray creiamo un semplice intervallo di interi di dimensione num_records. Successivamente, definiamo il Preprocessor che desideriamo applicare al nostro dataset. Il nostro Preprocessor di Ray contiene due componenti: il primo è un BatchMapper che mappa gli interi grezzi a coppie immagine-etichetta casuali. Il secondo è un TorchVisionPreprocessor che esegue una trasformazione torchvision sui nostri batch casuali che li converte in tensori PyTorch e applica una serie di operazioni GaussianBlur. Le operazioni GaussianBlur sono destinate a simulare una pipeline di preprocessing dei dati relativamente pesante. I due Preprocessor vengono combinati utilizzando un Preprocessor a catena. La creazione del dataset e del Preprocessor di Ray viene mostrata nel blocco di codice di seguito:
import rayfrom typing import Dict, Tupleimport numpy as npimport torchvision.transforms as transformsfrom ray.data.preprocessors import Chain, BatchMapper, TorchVisionPreprocessordef get_ds(batch_size, num_records): # crea un dataset tabulare Ray grezzo ds = ray.data.range(num_records) # mappa un intero a una coppia immagine-etichetta casuale def synthetic_ds(batch: Tuple[int]) -> Dict[str, np.ndarray]: labels = batch['id'] batch_size = len(labels) images = np.random.randn(batch_size, 224, 224, 3).astype(np.float32) labels = np.array([label % 1000 for label in labels]).astype( dtype=np.int64) return {"image": images, "label": labels} # il primo passo del prepocessor mappa i batch di interi a # coppie immagine-etichetta casuali synthetic_data = BatchMapper(synthetic_ds, batch_size=batch_size, batch_format="numpy") # definiamo una trasformazione torchvision che converte le coppie numpy in # tensori e quindi applica una serie di sfocature gaussiane per simulare # un preprocessing pesante transform = transforms.Compose( [transforms.ToTensor()] + [transforms.GaussianBlur(11)]*10 ) # il secondo passo del prepocessor applica la trasformazione torchvision vision_preprocessor = TorchVisionPreprocessor(columns=["image"], transform=transform) # combina i passaggi di preprocessing preprocessor = Chain(synthetic_data, vision_preprocessor) return ds, preprocessorSi noti che la pipeline dei dati Ray utilizzerà automaticamente tutte le CPU disponibili nel cluster Ray. Ciò include le risorse della CPU che sono presenti nell’istanza GPU oltre alle risorse della CPU di eventuali istanze ausiliarie aggiuntive nel cluster.
Definizione del ciclo di addestramento
Il passo successivo è definire la sequenza di addestramento che verrà eseguita su ciascuno dei worker di addestramento (ad esempio, le GPU). Prima definiamo il modello utilizzando il pacchetto Python timm (0.6.13) e lo incapsuliamo utilizzando l’API train.torch.prepare_model. Successivamente, estraiamo la partizione appropriata dal dataset e definiamo un’iteratore che restituisce batch di dati con la dimensione batch richiesta e li copia sul dispositivo di addestramento. Poi viene il ciclo di addestramento stesso, che è composto da codice standard PyTorch. Quando usciamo dal ciclo, riportiamo la metrica di perdita risultante. La sequenza di addestramento per ogni worker è mostrata nel blocco di codice di seguito:
import timefrom ray import trainfrom ray.air import sessionimport torch.nn as nnimport torch.optim as optimfrom timm.models.vision_transformer import VisionTransformer# crea un modello ViT utilizzando timmdef build_model(): return VisionTransformer()# definisci il ciclo di addestramento per ogni workerdef train_loop_per_worker(config): # incapsula il modello PyTorch con un oggetto Ray model = train.torch.prepare_model(build_model()) criterion = nn.CrossEntropyLoss() optimizer = optim.SGD(model.parameters(), lr=0.001, momentum=0.9) # ottieni la partizione del dataset appropriata train_dataset_shard = session.get_dataset_shard("train") # crea un'iteratore che restituisce batch dal dataset train_dataset_batches = train_dataset_shard.iter_torch_batches( batch_size=config["batch_size"], prefetch_batches=config["prefetch_batches"], device=train.torch.get_device() ) t0 = time.perf_counter() for i, batch in enumerate(train_dataset_batches): # ottieni gli input e le etichette inputs, labels = batch["image"], batch["label"] # azzerare i gradienti dei parametri optimizer.zero_grad() # avanti + indietro + ottimizzazione outputs = model(inputs) loss = criterion(outputs, labels) loss.backward() optimizer.step() # stampa le statistiche if i % 100 == 99: # stampa ogni 100 mini-batch avg_time = (time.perf_counter()-t0)/100 print(f"Iterazione {i+1}: tempo medio per passo {avg_time:.3f}") t0 = time.perf_counter() metrics = dict(running_loss=loss.item()) session.report(metrics)Definizione del Ray Torch Trainer
Una volta definita la nostra pipeline dei dati e il ciclo di addestramento, possiamo passare alla configurazione del Ray TorchTrainer. Configuriamo il Trainer in modo da tenere conto delle risorse disponibili nel cluster. In particolare, impostiamo il numero di worker di addestramento in base al numero di GPU e impostiamo la dimensione del batch in base alla memoria disponibile sulla GPU di destinazione. Costruiamo il nostro dataset con il numero di record necessari per addestrare esattamente 1000 passaggi.
from ray.train.torch import TorchTrainerfrom ray.air.config import ScalingConfigdef train_model(): # configureremo il numero di worker, la dimensione del nostro # dataset e la dimensione dello storage dei dati in base alle # risorse disponibili num_gpus = int(ray.available_resources().get("GPU", 0)) # impostiamo il numero di worker di addestramento in base al numero di GPU num_workers = num_gpus se num_gpus > 0 else 1 # impostiamo la dimensione del batch in base alla capacità di memoria della GPU # della famiglia di istanze Amazon EC2 g5 batch_size = 64 # creiamo un dataset sintetico con abbastanza dati per addestrare per 1000 passaggi num_records = batch_size * 1000 * num_workers ds, preprocessor = get_ds(batch_size, num_records) ds = preprocessor(ds) trainer = TorchTrainer( train_loop_per_worker=train_loop_per_worker, train_loop_config={"batch_size": batch_size}, datasets={"train": ds}, scaling_config=ScalingConfig(num_workers=num_workers, use_gpu=num_gpus > 0), ) trainer.fit()Deploy di un cluster Ray e avvio della sequenza di addestramento
Ora definiamo il punto di ingresso del nostro script di addestramento. È qui che configuriamo il cluster Ray e avviamo la sequenza di addestramento sul nodo principale. Utilizziamo la classe Environment della libreria sagemaker-training per scoprire le istanze nel cluster eterogeneo SageMaker come descritto in questo tutorial. Definiamo il primo nodo del gruppo di istanze GPU come nodo principale del cluster Ray e eseguiamo il comando appropriato su tutti gli altri nodi per connetterli al cluster. (Consultare la documentazione di Ray per ulteriori dettagli sulla creazione di cluster.) Programmiamo il nodo principale per attendere finché tutti i nodi si sono connessi e quindi avviare la sequenza di addestramento. Ciò garantisce che Ray utilizzi tutte le risorse disponibili durante la definizione e la distribuzione delle attività sottostanti di Ray.
import timeimport subprocessfrom sagemaker_training import environmentif __name__ == "__main__": # utilizziamo la classe Environment() per scoprire automaticamente il cluster SageMaker env = environment.Environment() if env.current_instance_group == 'gpu' and \ env.current_instance_group_hosts.index(env.current_host) == 0: # il nodo principale avvia un cluster Ray p = subprocess.Popen('ray start --head --port=6379', shell=True).wait() ray.init() # calcoliamo il numero totale di nodi nel cluster groups = env.instance_groups_dict.values() cluster_size = sum(len(v['hosts']) for v in list(groups)) # attendiamo finché tutti i nodi di SageMaker si sono connessi al cluster Ray connected_nodes = 1 while connected_nodes < cluster_size: time.sleep(1) resources = ray.available_resources().keys() connected_nodes = sum(1 for s in list(resources) if 'node' in s) # chiamiamo la sequenza di addestramento train_model() # smantelliamo il cluster Ray p = subprocess.Popen("ray down", shell=True).wait() else: # i nodi worker si collegano al nodo principale head = env.instance_groups_dict['gpu']['hosts'][0] p = subprocess.Popen( f"ray start --address='{head}:6379'", shell=True).wait() # utilità per verificare se il cluster è ancora attivo def is_alive(): from subprocess import Popen p = Popen('ray status', shell=True) p.communicate()[0] return p.returncode # manteniamo il nodo attivo finché il processo sul nodo principale non viene completato while is_alive() == 0: time.sleep(10)Addestramento su un cluster eterogeneo Amazon SageMaker
Con il nostro script di addestramento completo, ora ci impegniamo a distribuirlo su un cluster eterogeneo Amazon SageMaker. Per farlo, seguiamo i passaggi descritti in questo tutorial. Iniziamo creando una directory source_dir in cui inseriamo lo script train.py e un file requirements.txt contenente le due pacchetti pip su cui si basa il nostro script, timm e ray[air]. Questi vengono installati automaticamente su ciascuno dei nodi nel cluster SageMaker. Definiamo due gruppi di istanze SageMaker, il primo con un’istanza ml.g5.xlarge (contenente 1 GPU e 4 vCPU) e il secondo con un’istanza ml.c5.4xlarge (contenente 16 vCPU). Utilizziamo quindi l’estimatore SageMaker PyTorch per definire e distribuire il nostro lavoro di addestramento nel cloud.
from sagemaker.pytorch import PyTorch
from sagemaker.instance_group import InstanceGroup
cpu_group = InstanceGroup("cpu", "ml.c5.4xlarge", 1)
gpu_group = InstanceGroup("gpu", "ml.g5.xlarge", 1)
estimator = PyTorch(
entry_point='train.py',
source_dir='./source_dir',
framework_version='2.0.0',
role='',
py_version='py310',
job_name='eterogeneo-cluster',
instance_groups=[gpu_group, cpu_group]
)
estimator.fit()Risultati
Nella tabella sottostante confrontiamo i risultati di esecuzione del nostro script di addestramento in due configurazioni diverse: un’istanza GPU ml.g5.xlarge singola e un cluster eterogeneo contenente un’istanza ml.g5.xlarge e un’istanza ml.c5.4xlarge. Valutiamo l’utilizzo delle risorse di sistema utilizzando Amazon CloudWatch e stimiamo il costo di addestramento utilizzando la tariffe di Amazon SageMaker disponibili al momento della stesura di questo documento ($0,816 all’ora per l’istanza ml.c5.4xlarge e $1,408 per l’istanza ml.g5.xlarge).
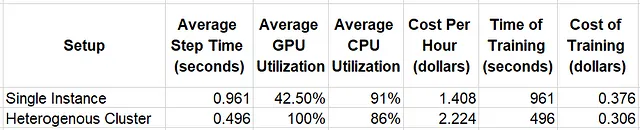
L’utilizzo relativamente elevato della CPU combinato con l’utilizzo basso della GPU nell’esperimento con un’istanza singola indica un collo di bottiglia delle prestazioni nel processo di pre-elaborazione dei dati. Questi problemi sono chiaramente risolti passando al cluster eterogeneo. Non solo l’utilizzo della GPU aumenta, ma anche la velocità di addestramento. Nel complesso, l’efficienza del costo di addestramento aumenta del 23%.
Dobbiamo sottolineare che questi esperimenti di prova sono stati creati esclusivamente per dimostrare le funzionalità di bilanciamento del carico automatizzato abilitate dall’ecosistema Ray. È possibile che un’ottimizzazione dei parametri di controllo possa portare a prestazioni migliorate. È anche probabile che la scelta di una soluzione diversa per affrontare il collo di bottiglia della CPU (ad esempio scegliendo un’istanza della famiglia EC2 g5 con più CPU) possa portare a una migliore performance a livello di costo.
Sommario
In questo post abbiamo dimostrato come i dataset di Ray possono essere utilizzati per bilanciare il carico di un intenso processo di pre-elaborazione dei dati su tutti i worker CPU disponibili nel cluster. Ciò ci consente di affrontare facilmente i colli di bottiglia della CPU semplicemente aggiungendo istanze CPU ausiliarie all’ambiente di addestramento. Il supporto al cluster eterogeneo di Amazon SageMaker è un modo convincente per eseguire un job di addestramento Ray nel cloud in quanto gestisce tutti gli aspetti della gestione del cluster evitando la necessità di supporto devops dedicato.
Tieni presente che la soluzione presentata qui è solo una delle tante diverse modalità per affrontare i colli di bottiglia della CPU. La soluzione migliore per te dipenderà fortemente dai dettagli del tuo progetto.
Come sempre, non esitate a contattarci per commenti, correzioni e domande.






