Esplorazione di modelli di linguaggio di grandi dimensioni – Parte 2
Esplorazione modelli linguaggio dimensioni - Parte 2
Usare LLM in modo efficace: Ricerca di informazioni, Assistenti personali, Agenti di ragionamento causale, Spiegabilità e deploy basato su controllo gerarchico.
Questo articolo è scritto principalmente per l’autoapprendimento. Quindi è ampio ma anche approfondito. Sentiti libero di saltare alcune sezioni in base ai tuoi interessi o di cercare l’area che ti interessa.
Ecco alcune delle domande che mi hanno intrigato o che sono emerse durante il tentativo di affinare LLM. L’articolo è un tentativo di rispondere a queste domande e condividere queste informazioni con altri curiosi.
Dato che LLM si basa su NeuralNet con funzione di perdita, non è tutto l’addestramento di LLM addestramento supervisionato? Perché viene generalmente definito addestramento non supervisionato? Puoi addestrare un LLM con una frase molto breve per illustrare come funziona l’addestramento di LLM in pratica? Cosa significa Masked e Causal LM? Puoi spiegare l’intuizione dietro l’architettura del Transformer in un’unica immagine? Cosa si intende esattamente per addestramento non supervisionato in LLM? Perché l’architetto principale di ChatGPT – Ilya Suverskar considera l’addestramento non supervisionato come il Santo Graal dell’apprendimento automatico? Cosa si intende per Emergenza/Comprensione di LLM?
Quali sono i casi d’uso di LLM? Perché LLM è più adatto come assistente di produttività? Qual è il modello Vector DB/Embedding per il recupero di informazioni? LLM può essere utilizzato per scopi diversi dai compiti testuali? Cosa è il ragionamento causale? Qual è il problema con LLM? Perché menti come Yan LeCun pensano che gli attuali LLM siano senza speranza? LLM sono spiegabili, come possono essere utilizzati in modo efficace se non lo sono?
- Esplorazione di grandi modelli di linguaggio – Parte 3
- Apprendimento per rinforzo SARSA e Q-Learning – Parte 3
- Una coppia perfetta adidas e Covision Media utilizzano l’IA, NVIDIA RTX per creare contenuti 3D fotorealistici
Qual è la necessità di affinare/rieducare LLM? Perché è difficile addestrare LLM? Come aiutano le tecniche di Quantizzazione e LoRA nell’addestramento di grandi LLM? Come funzionano Quantizzazione e LoRA? Qual è un modo efficace per affinare LLM pre-addestrati? Cos’è l’Instruct Tuning? Cos’è l’Autoinsegnamento? Come possiamo generare un dataset di addestramento di alta qualità per l’Instruct Tuning?
Da rispondere ancora: Puoi mostrare come LLM di capacità variabile possono essere strutturati gerarchicamente per creare un’automazione complessa con ragionamento causale? Perché stiamo cercando di creare un’intelligenza simile a quella umana da LLM o reti neurali? Perché sembra inquietantemente simile alla creazione del volo simile a quello degli uccelli nel tempo antico prima dell’invenzione dell’aereo ad ala fissa?
Dato che l’articolo è piuttosto lungo, l’ho strutturato in tre parti per una migliore leggibilità.
Parte 1 discuterà l’evoluzione dell’addestramento di LLM. L’intenzione è stabilire il contesto per comprendere la magia, o più tecnicamente l’emergenza, che inizia a verificarsi quando la dimensione del modello aumenta oltre una soglia e quando viene addestrato con un’enorme quantità di dati. Le sezioni approfondite illustrano questi concetti in maggiore dettaglio e profondità, anche se sono anche facili da seguire per la maggior parte dei programmatori.
Parte 2 discuterà brevemente i casi d’uso popolari di LLM, assistenti personali e chatbot con dati personalizzati tramite modelli di recupero delle informazioni (ricerca nello spazio vettoriale con l’ausilio di LLM). Esploreremo anche spunti su come il modello mentale e il NLU dei modelli potrebbero diventare casi d’uso più potenti. In questo contesto, esploreremo una delle principali limitazioni del modello LLM mettendo a confronto i punti di forza dell’addestramento supervisionato con un punto debole dei modelli LLM – la mancanza di spiegabilità o la difficoltà nel determinare fatti vs. allucinazioni. Esploreremo come tali sistemi siano stati utilizzati in modo molto efficace nei sistemi informatici attraverso una gerarchia di controlli, sistemi non affidabili resi affidabili da un controllo di livello superiore – come ad esempio il nostro utilizzo quotidiano di ChatGPT e come possa essere esteso ad altri casi d’uso.
Parte 3 discuterà alcuni concetti relativi all’addestramento dei modelli LLM su domini personalizzati. In questa parte ci concentreremo sulla comprensione del dominio e su come questa sia molto più potente rispetto a semplici modelli di recupero delle informazioni nello spazio vettoriale. Questo è facile in esempi di prova ma non molto facile in pratica con dati reali. Esploreremo come le tecniche di quantizzazione abbiano aperto i grandi modelli LLM al mondo e come ciò, unito ai concetti di riduzione dei parametri di addestramento, abbia democratizzato l’affinamento di LLM. Esploreremo la tecnica principale dell’affinamento efficace – l’Instruct Tuning, e come risolvere il più grande problema pratico dell’Instruct Tuning – la mancanza di un dataset di addestramento di istruzioni di qualità con tutti i concetti che abbiamo affrontato finora.
Le sezioni future discuteranno il concetto di sfruttare la parte di comprensione di LLM e utilizzare la gerarchia di controlli per potenziare questi potenti sistemi nell’augmenting di sistemi AI/ML.
Un caso d’uso primario è l’aumento della produttività – Smart Assistant.
Questo è un modello importante e ampiamente utilizzabile per LLM. Questo documento, The Economic Potential of Generative AI – The Next Productivity Frontier (Giugno 2023), di McKinsey & Company, contiene proiezioni su come questo aspetto di LLM, applicato in vari formati, possa modificare il lavoro attuale in diversi settori e aggiungere trilioni all’economia mondiale.
Prima di approfondire i dettagli, c’è stato un recente discorso in cui l’autore parla di come costruire sistemi più affidabili a partire da sistemi meno affidabili, citando il famoso design dello stack TCP/IP. Esiste un design stratificato in cui i livelli IP non affidabili o soggetti a perdita vengono resi affidabili dalla logica di controllo della trasmissione e della ritrasmissione (nel caso in cui venga rilevata la perdita di pacchetti) del livello TCP.
Anche il tipo di assistente è stratificato, dove i difetti dei LLM come le allucinazioni vengono superati da un controllo superiore e migliore (di solito umano)
Potrebbe anche essere un modello più cognitivo rispetto ai modelli inferiori. Questo è ciò che rende così diffuso e robusto questo caso d’uso. Gli ingegneri del software che utilizzano Github Co-pilot sono un esempio classico. L’inferenza del modello è abbinata a un controllo migliore che può utilizzare efficacemente l’output, cogliere gli aspetti positivi e affinare o eliminare gli aspetti negativi (errori, allucinazioni). Più abile è l’essere umano, più efficientemente può utilizzare questi modelli. I notevoli guadagni di efficienza di questo approccio come assistente di programmazione o di dominio sono ben noti nel brevissimo periodo di tempo trascorso dalla sua introduzione. Lo stesso vale quando questi assistenti vengono sviluppati per altri settori, un esempio recente è Med-Palm2 di Google e la sua straordinaria capacità di aiutare i medici nel campo medico.
Questa necessità di un controllo migliore è implicitamente legata al concetto di spiegabilità.
Spiegabilità e il suo impatto.
Abbiamo menzionato qui il caso d’uso dell’assistente, l’approccio stratificato e Med_Palm2. Ciò che è implicito in questo è il concetto di spiegabilità.
La spiegabilità è attualmente un punto debole nei LLM.
Ecco cosa ne pensa Yann LeCun. Lo dice piuttosto candidamente:
I LLM autoregressivi sono terribili! Sono buoni come assistenti. Non sono in grado di fornire risposte accurate e consistenti (a causa delle allucinazioni), tenendo conto delle informazioni recenti (addestramento obsoleto sempre)
I LLM autoregressivi sono condannati. Non possono essere resi accurati e non è risolvibile (senza una riprogettazione totale)…
La mancanza di spiegabilità comporta un livello superiore di controllo e una minore automazione. Abbiamo già esplorato in precedenza il popolare caso d’uso dell’assistente di dominio, o tramite ChatGPT, sperimentiamo quotidianamente il caso d’uso in cui noi esseri umani siamo il controllo di livello superiore.
Ma quando si parla di AI/ML, si mira all’automazione basata su computer. Per dare un esempio in uno scenario non LLM e per fornire alcune idee, esploriamo come le reti neurali convoluzionali hanno rivoluzionato la visione artificiale e come superano efficacemente questo problema di spiegabilità.
Neppure i migliori modelli di visione artificiale hanno una comprensione delle immagini. Di conseguenza, è molto facile ingannare questi modelli con immagini avversarie per prevedere qualcos’altro. Un modello addestrato per rilevare – ad esempio – alcune malattie dalle immagini mediche non può essere considerato affidabile, che sia stato manipolato o che abbia rilevato qualcosa nell’immagine che si presenta come simile a un’immagine avversaria. (Le auto a guida autonoma che si basano su telecamere a volte interpretano erroneamente – talvolta con risultati fatali – i casi ai confini)
Un controllo migliore – qui un medico deve riesaminare questo. Tuttavia, se un medico dovesse riesaminare tutti i dettagli delle immagini, non ci sarebbe molto vantaggio nell’automazione in primo luogo. Qui entra in gioco la spiegabilità visiva utilizzata nella visione artificiale per tali casi d’uso. Il medico avrà bisogno di una spiegazione su perché il modello ha previsto come ha fatto – Spiegabilità della previsione. Per la visione artificiale, ciò può essere rappresentato visivamente utilizzando gli algoritmi di Grad-CAM. Di seguito, possiamo vedere che il modello sta effettivamente rilevando le caratteristiche rilevanti per prevedere che l’immagine contenga un corno francese. Nel campo medico, dove gli oggetti non sono così evidenti, ciò aiuta ad accelerare la diagnosi con un controllo efficace.

Per altri modelli di DL basati sui dati, la spiegabilità si riferisce alle combinazioni di caratteristiche selezionate dal modello per la sua previsione. La spiegabilità è un problema difficile ovunque nell’ambito dell’ML, soprattutto quando si utilizza DL quando ci sono troppe caratteristiche inizialmente per un motore basato su regole o per un essere umano per correlare. Tuttavia, è ancora possibile in certa misura in sistemi di ML addestrati supervisionati mediante la rimozione delle caratteristiche e verificando come ciò influisce sull’output del modello e su altri metodi simili.
Fino a quando tali tecniche non verranno inventate nei LLM, sarà necessario un controllo rigoroso poiché non esiste un modo per identificare le allucinazioni. L’altra alternativa è utilizzare queste tecniche in scenari in cui alcuni errori non sono così importanti. Vedremo un caso d’uso del genere in cui utilizziamo i LLM per creare dati di addestramento per addestrare i LLM nella Sezione 3. Ci sono molti altri casi d’uso, come motori di raccomandazione prodotti migliori e simili, in cui pochi errori non sono importanti.
LLM come motori di ricerca (LLM potenziato per il recupero delle informazioni)
Questo è un caso d’uso estremamente popolare e in crescita, con nuovi attori che spuntano frequentemente. Ci si chiederà perché questo sia molto migliore rispetto alla ricerca aziendale tradizionale basata su tecniche di indicizzazione delle parole chiave.
La principale intuizione tecnica qui è l’embedding vettoriale e la ricerca di similarità; e la principale intuizione non tecnica rispetto ad altre ricerche aziendali (ad esempio ElasticSearch) è che ciò sfrutta il concetto di embedding contestuale delle parole/embedding delle frasi.
Mentre i motori di ricerca convenzionali indicizzano ogni parola (o il concetto di indice invertito di ES), in questo caso ogni frase viene raggruppata in base a quanto è simile alle altre frasi. Questo rende, in teoria, agenti di recupero delle informazioni molto migliori. Dobbiamo tornare alla Parte 1 e vedere come i Transformers aiutano a fare ciò tramite il loro meccanismo di attenzione per capire questo più a fondo. Inoltre, la prima parte di questo articolo spiega questo molto approfonditamente per GPT2.
Nella pratica, ciò viene fatto calcolando l’embedding di alto ordine o l’embedding semantico dei dati tramite modelli preaddestrati (popolari SentenceTransformers) e alcune librerie come FAISS (Facebook AI Similarity Search) per il recupero veloce basato sulla ricerca di similarità di questi embedding rispetto al vettore di query dell’utente calcolato in modo simile. Oltre all’embedding, invece o anche, FAISS o tecnologie simili sono database vettoriali in continua crescita – Pinecone, Weviate, Milvus ecc. Vedi questo articolo di Forbes.
DeepDive: tutti i documenti vengono prima suddivisi in componenti (frasi, paragrafi o anche documenti con URL e alcune informazioni come metadati) e convertiti in embedding vettoriali utilizzando un modello come Sentence Transformers. (Pensate a loro come fluttuanti in uno spazio N-dimensionale (N è un numero molto grande), e vettori simili sono raggruppati insieme in questo spazio vettoriale).
Ecco un Quaderno di Colab in cui viene utilizzato SentenceTransformer e FAISS con solo archiviazione locale per questo pattern: https://colab.research.google.com/drive/1PU-KEHq-vUpUUhjbMbrJip6MP7zGBFk2?usp=sharing. Nota che Langchain ha wrapper più semplici su molte librerie ed è quello che stiamo utilizzando sopra. La modalità diretta è un po’ più criptica, guarda questo quaderno di Colab.
L’embedding semantico dei chunk viene utilizzato come embedding vettoriale. Ad esempio, nel caso in cui si utilizzi LamaCPPEmbedding, è possibile vedere i logit prelevati dall’eval del modello in cui sembra essere prelevato l’embedding dell’ultima parola per rappresentare la frase. langchain -> lmacpp (python) -> lamacpp (c++)
Il vantaggio di questo approccio è che è più facile calcolare gli embedding vettoriali memorizzarli e poi utilizzare questi dati rispetto al fine-tuning del modello. Lo svantaggio è che la selezione dei dati si basa sulla comprensione della query dell’utente, ma su una suddivisione basata sulle parole nella query con la complessità dell’attenzione/embedding semantico. Il modello non ha una “comprensione” del dominio come abbiamo spiegato in precedenza. Poiché viene utilizzato un modello preaddestrato, comprende la query e può utilizzare i contesti dalla ricerca di similarità per creare una risposta significativa.
In genere, questo sarà sufficiente per molti utilizzi. Ma se si sente che lo stesso livello di raffinatezza dell’output ottenuto, ad esempio, con ChatGPT o Bard, manca con questo, l’opzione è quella di effettuare il fine-tuning di un modello nel proprio dominio personalizzato.
LLM come agenti di ragionamento causale
Relativamente alla spiegabilità che abbiamo scoperto in precedenza, c’è il concetto di causalità nell’ML (SHAP, LIME, Il Libro del Perché – Judea Pearl spiega questo concetto in modo più approfondito ed è fuori dallo scope qui).
In termini semplici, si tratta di un ragionamento causa-effetto. Immaginate come gli esseri umani primitivi associavano causa ed effetto. Una sera stavano facendo una danza ritualistica e il giorno successivo c’era la pioggia.

Questo si ripeteva una o due volte e loro associavano questi due fatti. L’associazione è il primo passo nella scala del pensiero causale, ma non l’unico.
Come afferma Judea P., tutti i nostri sistemi di intelligenza artificiale sono a questo stadio. (Suppongo che molti di noi esseri umani siano ancora pesantemente qui). Gli esseri umani semplici ballerebbero ancora la prossima volta per la pioggia. Ora, per i nostri antenati di esempio, presumendo che ballassero ogni volta che pioveva, sarebbe quasi impossibile convincerli del contrario.
A meno che loro non abbiano “non” ballato e sia comunque piovuto, o abbiano ballato e non sia piovuto. Il primo passo, “Associazione”, può anche essere rappresentato come “Vedere”, il successivo come “Fare” e il terzo come “Immaginare” (come nel libro).
Si spera che questo ci renda consapevoli del fatto che il ragionamento causale richiede una certa comprensione e non solo l’associazione tra i token.
C’è un interessante articolo di ricerca di Microsoft che utilizza LLM per la scoperta causale
Abbiamo scoperto che i metodi basati su LLM stabiliscono nuovi record di precisione su diversi benchmark causali.
Ho verificato le stesse indicazioni nell’articolo con ChatGPT 4, e ha ottenuto risultati migliori rispetto a quelli ottenuti in precedenza con lo stesso modello; il che non significa molto, ma è comunque illustrativo della loro capacità di ragionamento causale “out of the box”.
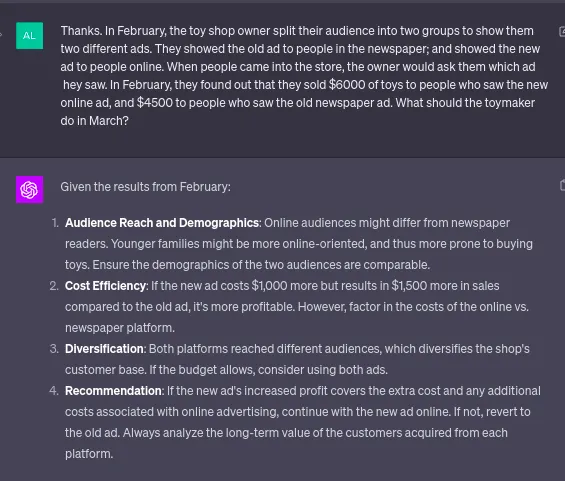
Notare qui che non c’era alcun riferimento a demografie online e offline, ecc. Il modello GPT4 ha individuato i confounders e ha ragionato non solo sui dati ma anche in base alla sua visione del mondo. Come descritto dagli autori, gli LLM non sono perfetti in questo e commettono errori.
Anche qui non è facile illustrare con un semplice caso d’uso, ma si tratta di un campo di ricerca interessante. Mi piace particolarmente questa citazione dell’articolo, che evita efficacemente di dimostrare o confutare argomenti su se siano o meno dei mimici e di utilizzare le capacità in modo pratico.
Indipendentemente dal fatto che gli LLM siano veramente in grado di eseguire un ragionamento causale o meno, la loro capacità empiricamente osservata di svolgere determinati compiti causali è abbastanza forte da fornire un utile aiuto per gli aspetti del ragionamento causale in cui attualmente ci affidiamo solo agli esseri umani.
Cioè, sebbene questi sistemi siano difficili da spiegare, possono essere utilizzati come strumenti per scoprire relazioni causali tra variabili in un dataset. Ciò illustra il loro possibile potenziale in compiti di ragionamento di livello superiore.
Nella parte 3, esploreremo come raffinare i modelli utilizzando anche i modelli stessi per aiutare nella generazione di dati e come ciò possa essere sfruttato nelle applicazioni di dominio personalizzato.