Esplorazione dei grandi modelli linguistici – Parte 1
Esplorazione modelli linguistici - Parte 1
Il Santo Graal del Machine Learning – Apprendimento non Supervisionato, Emergenza della Comprensione, Comprensione dell’Addestramento LLM
Questo articolo è scritto principalmente per l’autoapprendimento. Quindi, copre ampiamente e anche in profondità. Sentitevi liberi di saltare alcune sezioni in base ai vostri interessi o di cercare l’area che vi interessa.
Ecco alcune delle domande che mi hanno incuriosito o che sono emerse durante il tentativo di ottimizzare LLM. L’articolo è un tentativo di rispondere a queste domande e condividere queste informazioni con altri curiosi.
Dal momento che LLM si basa su NeuralNet con funzione di perdita, tutto l’addestramento di LLM è addestramento supervisionato? Perché viene solitamente definito addestramento non supervisionato?Puoi addestrare un LLM in una frase molto breve per illustrare come funziona l’addestramento di LLM in pratica?Cos’è un Masked e un Causal LM?Puoi spiegare l’intuizione dietro l’Architettura Transformer in un’unica immagine?Cosa si intende esattamente per addestramento non supervisionato in LLM?Perché l’architetto principale di ChatGPT – Ilya Suverskar – considera l’addestramento non supervisionato come il Santo Graal del machine learning?Cosa si intende per Emergenza/Comprensione di LLM?
Quali sono i casi d’uso di LLM?Perché LLM sono più adatti come assistenti di produttività?Qual è il pattern di recupero delle informazioni del Vector DB/Embedding?LLM può essere utilizzato per scopi diversi dalle attività testuali? Cos’è il ragionamento causale?Qual è il problema con LLM?Perché menti come Yan LeCun pensano che i LLM attuali siano disperati?I LLM sono spiegabili, come possono essere utilizzati in modo efficace se non lo sono?
- Esplorazione di modelli di linguaggio di grandi dimensioni – Parte 2
- Esplorazione di grandi modelli di linguaggio – Parte 3
- Apprendimento per rinforzo SARSA e Q-Learning – Parte 3
Qual è la necessità di ottimizzare/ri-addestrare i LLM?Perché è difficile addestrare i LLM?In che modo Quanitsation e LoRA aiutano nell’addestramento di LLM di grandi dimensioni?Come funzionano Quantisation e LoRA?Qual è un modo efficace per ottimizzare i LLM pre-addestrati?Cos’è l’Instruct Tuning?Cos’è il Self Instruct? Come possiamo generare un dataset di addestramento di alta qualità per l’Instruct Tuning?
Ancora da risponderePuoi mostrare come i LLM di diverse capacità possono essere strutturati in modo gerarchico per creare un’automazione complessa con ragionamento causale?Perché stiamo cercando di creare un’intelligenza simile a quella umana da LLM o reti neurali? Perché questo sembra inquietantemente simile alla creazione del volo simile a quello degli uccelli nel tempo prima dell’invenzione dell’aereo a ali fisse?
Dato che l’articolo è piuttosto lungo, l’ho strutturato in tre parti per una migliore leggibilità.
Parte 1 discuterà l’evoluzione dell’addestramento di LLM. L’intenzione è quella di creare il contesto per capire la magia, o più tecnicamente – l’emergenza, che inizia a verificarsi quando la dimensione del modello aumenta oltre una soglia e quando viene addestrato con un’enorme quantità di dati. Le sezioni approfondite illustrano questi concetti in modo più dettagliato e approfondito, anche se sono facili da seguire per la maggior parte dei programmatori.
Parte 2 discuterà brevemente i casi d’uso popolari di LLM, assistenti personali e chatbot con dati personalizzati tramite modelli di recupero delle informazioni (ricerca nello spazio vettoriale con l’ausilio di LLM). Esploreremo anche spunti su come il modello mentale e la NLU dei modelli potrebbero diventare infine i loro casi d’uso più potenti. In questo contesto, esploreremo una limitazione principale del modello LLM mettendo a confronto i punti di forza dell’addestramento supervisionato con un punto debole dei modelli LLM – la mancanza di spiegabilità o la difficoltà nel determinare fatti rispetto alle allucinazioni. Esploreremo come tali sistemi siano stati utilizzati in modo molto efficace nei sistemi informatici attraverso una gerarchia di controlli, sistemi non affidabili resi affidabili da un controllo di livello superiore, ad esempio il nostro uso quotidiano di ChatGPT, e come tutto ciò possa essere esteso ad altri casi d’uso.
Parte 3 discuterà alcuni concetti legati all’addestramento dei LLM nei domini personalizzati. In questo caso, ci concentriamo sulla comprensione del dominio e su come ciò sia molto più potente rispetto ai semplici modelli di recupero delle informazioni nello spazio vettoriale. Questo è facile negli esempi di giocattolo, ma praticamente non molto facile con dati reali. Esploreremo come le tecniche di quantizzazione abbiano aperto i LLM molto grandi al mondo e come ciò, unito ai concetti di riduzione dei parametri di addestramento, abbia democratizzato l’ottimizzazione dei LLM. Esploreremo la principale tecnica di ottimizzazione efficace, l’Instruct Tuning, e come risolvere il più grande problema pratico dell’Instruct Tuning: l’indisponibilità di un dataset di addestramento di qualità con tutti i concetti che abbiamo affrontato finora.
Le sezioni future discuteranno il concetto di sfruttare la parte di comprensione dei LLM e l’utilizzo della gerarchia dei controlli per sfruttare questi potenti sistemi per il potenziamento dei sistemi AI/ML.
Introduzione
I modelli di linguaggio di grandi dimensioni (LLM) ci offrono due capacità evidenti: un’interfaccia di linguaggio naturale per comunicare con il modello e una vasta quantità di conoscenza memorizzata in modo molto efficiente nei modelli, l’intera quantità di dati testuali presenti su Internet. Più grandi sono i modelli, migliori diventano in entrambe queste capacità.
C’è un’altra capacità che non è così evidente, ma potrebbe essere la più potente. È implicita nella prima capacità e tecnicamente definita come NLU, Natural Language Understanding (Comprensione del linguaggio naturale). Per capire qualcosa, hai bisogno di un modello di quella cosa. Per gli esseri umani, un modello mentale. Per capire il linguaggio, hai bisogno di un modello di sintassi e semantica del linguaggio. Per capire una domanda dell’utente e essere in grado di rispondere in modo efficace, il modello ha bisogno di un modello del mondo interno. C’è un dibattito tra i leader di pensiero in questo campo su se questi LLM apprendano qualche modello del mondo interno o se sembri a noi come se fosse presente.
Tuttavia, la loro comprensione del linguaggio naturale è così buona e il loro modello del mondo interno ha abbastanza informazioni da superare il Test di Turing come è stato concepito (https://www.nature.com/articles/d41586-023-02361-7) e anche il Mini Test di Turing basato sul Reasoning causale proposto dal critico più famoso dell’IA, Judea Pearl. Torneremo su questo argomento più avanti.
Visto da un certo punto di vista, tutti sanno cosa sia l’intelligenza; visto da un altro punto di vista, nessuno lo sa. Robert J. Sternberg, fonte
Tuttavia, questo non significa che siano intelligenti nel vero senso del termine, ma potremmo dire con maggiore sicurezza che sono intelligenti nella comprensione del linguaggio naturale. Questa è la proprietà chiave che distingue questi modelli.
I LLM iniziano come automi stupidi, ma da qualche parte durante il loro addestramento diventano abbastanza intelligenti da generalizzare il loro addestramento per compiti per i quali non sono esplicitamente addestrati. Questo è ciò che possiamo definire più liberamente come “comprensione”. Come ho già detto, questo è un argomento molto dibattuto e il nostro obiettivo non è approfondire il dibattito ma cercare di imparare.
Addestramento di LLM e l’Emergenza della Comprensione
Possiamo capire questo argomento in modo più divertente seguendo la storia di alcuni famosi sistemi di intelligenza artificiale/apprendimento automatico (AI/ML).
Motore di Regole/Ricerca nell’Albero
Possiamo iniziare con IBM DeepBlue, il supercomputer che gioca a scacchi. Utilizzando la potenza di un Super Computer e chip personalizzati, ha sconfitto Gary Kasparov, il grande maestro degli scacchi, nel 1997. Tuttavia, allora non c’era intelligenza artificiale o reti neurali coinvolte, era una Ricerca nell’Albero. Si potrebbe astrarre un po’ e dire che era un motore basato su regole. I dati di addestramento erano competenze di dominio codificate a mano, distillate in un insieme di regole. L’algoritmo ottimizzava la scelta della prossima mossa da un vasto ma calcolabile insieme di risultati in base allo stato attuale del suo mondo. Era chiaro, tuttavia, che era impossibile fare programmazione basata su regole per domini più ampi.
Addestramento Supervisionato
Un decennio dopo, nel 2011, IBM Watson, progettato per il Question Answering e addestrato specificamente per Trivia QA, ha giocato a Jeopardy e ha vinto contro un campione. C’era un’enorme hype intorno a questo come il prossimo sistema di conoscenza che avrebbe rivoluzionato tutto. Il modo principale in cui il sistema è stato addestrato sembra essere l’Addestramento Supervisionato. Cioè, dati con etichette su cui il sistema è stato addestrato per scegliere la risposta corretta o, in questo caso, la domanda corretta.
L’Apprendimento Supervisionato funziona bene. Questo è il fondamento di quasi tutto l’apprendimento automatico utilizzato in produzione oggi. Con abbastanza dati etichettati, i sistemi di intelligenza artificiale/apprendimento automatico impareranno ad approssimare qualsiasi funzione complessa multivariata. Sono eccellenti approssimatori di funzioni universali.
“Tutti i successi impressionanti dell’apprendimento profondo si riducono a semplice adattamento di curve…”. Judea Pearl, vincitore del Premio Turing, famoso critico dei sistemi di intelligenza artificiale/apprendimento automatico
Il problema con l’Apprendimento Supervisionato è che etichettare una enorme quantità di dati per addestrare modelli enormi richiede molto sforzo umano costoso e lento.
L’esempio migliore di uno dei più grandi insiemi di dati etichettati e le sue implicazioni è ImageNet. È stata l’enorme quantità di dati di immagini etichettate raccolte come parte del progetto ImageNet che ha aiutato AlexNet, introdotto nel 2012 (Ilya Sutskever, Alex Krizhevsky e Geoffrey Hinton), a rivoluzionare la visione artificiale, anche se già nel 1998 Yann LeCun e altri avevano introdotto una rete neurale convoluzionale basata su LeNet per il riconoscimento della scrittura a mano.
Nota che Ilya Sutskever è anche uno dei fondatori di OpenAI ed è stato fondamentale nella formazione dei modelli GPT successivi.
Tornando alla storia. L’entusiasmo intorno a IBM Watson è diminuito nel corso degli anni, poiché sono emerse le limitazioni del sistema. Un articolo del NY Times offre una panoramica di alcune delle sfide che hanno impedito all’IBM Watson di generalizzare bene in altri campi come sperava IBM, la mancanza di dati adeguatamente etichettati è stata la principale.
Apprendimento per rinforzo
Nel 2016, Google DeepMind AlphaGo è diventato molto popolare sconfiggendo il campione di Go. Questo gioco è un dominio/strategia molto più ampio rispetto agli scacchi (impossibile per algoritmi di tipo motore di regole/ricerca ad albero). La chiave qui è stata l’apprendimento per rinforzo (RL).
Qui l’addestramento può essere astratto come il compiere una mossa casuale, e se la mossa ti avvicina alla vittoria (attraverso un calcolo di perdita), effettua più mosse del genere, e viceversa. E poi hanno creato agenti e li hanno messi l’uno contro l’altro, giocando probabilmente migliaia di anni di partite e migliorando nel gioco.
Un gioco più complicato del Go è Dota, e nel 2019, una piccola azienda (in quel momento) chiamata OpenAI ha sconfitto i campioni in carica di Dota 2
Ecco un interessante frammento legato a questo evento. L’ultima parola “scala” è una parte interessante che potrebbe suggerire come hanno utilizzato questo concetto per il loro lavoro futuro nei modelli GPT
Abbiamo avviato OpenAI Five per lavorare su un problema che sembrava al di là della portata dell’apprendimento per rinforzo profondo esistente. .. Ci aspettavamo di avere bisogno di idee algoritmiche sofisticate, come l’apprendimento per rinforzo gerarchico, ma siamo rimasti sorpresi da ciò che abbiamo scoperto: il miglioramento fondamentale di cui avevamo bisogno per questo problema era la scala.
DeepDive – L’apprendimento per rinforzo difficile sembra essere utilizzabile per tutto (ad esempio, è così che un bambino impara a camminare o la maggior parte degli organismi impara), al di fuori di domini come i giochi che hanno uno spazio di stato molto limitato o controllato, è molto difficile da implementare. Ad esempio, in un’auto a guida autonoma, anche una piccola modifica dello stato in un passaggio precedente può avere un impatto positivo o negativo in seguito. Si riduce all’implementazione di una funzione di perdita in grado di archiviare e lavorare temporaneamente. (https://stanford.edu/~ashlearn/RLForFinanceBook/book.pdf, Perché è necessaria l’approssimazione della retropropagazione per RL https://stats.stackexchange.com/a/340657/191675)
Abbiamo quindi affrontato l’apprendimento supervisionato (il pane e burro degli algoritmi di AI/ML finora) e l’apprendimento per rinforzo – principalmente nei videogiochi e simili.
Apprendimento non supervisionato – Il Santo Graal di tutto l’apprendimento?
Presso OpenAI .. la speranza era che se si ha una rete neurale in grado di prevedere la parola successiva, risolverà l’apprendimento non supervisionato. Quindi, prima dei GPT, l’apprendimento non supervisionato era considerato il Santo Graal dell’apprendimento automatico …
Ma le nostre reti neurali non erano all’altezza del compito. Stavamo usando reti neurali ricorrenti. Quando è uscito il trasformatore, letteralmente appena è uscito il paper, letteralmente il giorno successivo, era chiaro a me, a noi, che i trasformatori affrontavano le limitazioni delle reti neurali ricorrenti, delle dipendenze a lungo termine …
E questo è ciò che ha portato a GPT-3 e fondamentalmente a dove siamo oggi. -Intervista a Ilya Sutskever
Prima di approfondire cosa intende per “Santo Graal”, facciamo un passo indietro per chiarire il contesto ed esplorare cosa intendono di solito gli ingegneri quando parlano di apprendimento non supervisionato e cosa si intende qui. Quello che intende qui, in breve, è una forma di apprendimento di livello superiore e non l’implementazione effettiva. È ancora un mistero come una rete addestrata a prevedere i token successivi possa generalizzare così tanto come le LLM; cioè, imparano a generalizzare in modo non supervisionato, anche se l’addestramento è la previsione supervisionata del token successivo.
L’approccio usuale all’apprendimento non supervisionato
Quando di solito parliamo di apprendimento non supervisionato in ML, ci riferiamo a pochi algoritmi correlati al clustering, ad esempio, il clustering k-means, la riduzione della dimensionalità, l’analisi delle componenti principali o l’adattamento delle serie temporali. Questi si basano su proprietà matematiche o matrici. Sono tutti piuttosto complessi, ma se si è bravi in matematica o si mette abbastanza sforzo, possono essere chiaramente compresi.
Nel caso dell’apprendimento profondo, l’esempio di livello inferiore è quello degli autoencoder. Gli autoencoder sono più interessanti nel contesto delle LLM per come apprendono le strutture per una rappresentazione compressa interna. Negli autoencoder, l’obiettivo è lo stesso dell’input. Cioè, dato un dato complesso (ad esempio, un’immagine altamente dettagliata), addestra una rete superficiale a produrre un’uscita simile. Per fare ciò, la rete deve apprendere alcuni modelli nei dati per comprimerli in modo sufficiente. Per saperne di più: http://ufldl.stanford.edu/tutorial/unsupervised/Autoencoders/
In questo articolo, ci stiamo concentrando non sui classici casi d’uso di ML o DL, ma sull’apprendimento non supervisionato per LLM.
DeepDive: Tutti gli attuali algoritmi di machine learning basati su reti neurali profonde richiedono una funzione di perdita da ottimizzare e una retropropagazione; e per avere una perdita, è necessario avere un obiettivo da calcolare. Nel contesto di LLM, l’obiettivo è il prossimo token in un insieme di token (i token approssimano le parole). In questo modo, possiamo utilizzare l’intero testo di Internet (pulito) come un enorme set di dati di addestramento etichettato.
Vediamo come possiamo adattare o riaddestrare un modello pre-addestrato per prevedere qualcosa di diverso, ad esempio ‘Zoo’ invece di ‘City’ che precede la frase ‘Amo New York’. In questo modo possiamo avere un’intuizione dell’addestramento e della perdita di un LLM.
La frase di addestramento di esempio sarà ‘Amo New York Zoo’. Il modello riceve la prima parola ‘Amo’ e produrrà un’uscita. Ma l’obiettivo è dato come
amoree la perdita di entropia incrociata viene calcolata con quell’obiettivo e minimizzata tramite addestramento. Infine, dopoYork, l’obiettivo èZoo. L’etichetta o l’obiettivo è fondamentalmente il prossimo token.Questo è un semplice addestramento supervisionato. Poiché il modello è piccolo e il set di dati è piccolo, qui non avviene l’apprendimento non supervisionato.
Sia che si tratti del piccolo modello giocattolo NanoGPT o del modello LLAMA2, la perdita utilizzata è essenzialmente la perdita di entropia incrociata.
La funzione softmax viene utilizzata come ultimo strato di una rete neurale per produrre una distribuzione di probabilità tra le classi. Nel nostro caso, le classi sono tutte le parole nel vocabolario.
Quindi è necessaria una funzione di perdita per calcolare la differenza tra le distribuzioni di probabilità generate e quelle attese. La perdita di entropia incrociata viene quindi applicata a questa distribuzione di probabilità per misurare l’errore tra le probabilità previste e le etichette di classe vere.
Per capire meglio, dobbiamo approfondire leggermente l’architettura del Transformer. I modelli LLM sono generalmente progettati come modelli linguistici causali o modelli di linguaggio mascherato (MLM) in cui viene introdotto un certo rumore tramite la mascheratura di alcune parole in una frase (ma il modello è in grado di vedere tutti i token nella frase). Questi sono anche noti come modelli unidirezionali e bidirezionali rispettivamente.
La terza opzione è una combinazione chiamata modellazione del linguaggio causale o mascherato prefissato, in cui è presente una stringa di prefisso di attività nei dati di addestramento (ad esempio “Traduci in francese:”). L’ultima opzione è resa famosa dal tipo di modello T5 (FlanT5 – Finetune Langage Model per Text-to-Text Transformer). (Ci sono anche altre variazioni)
Ci sono differenze nell’addestramento di questi modelli. Per Caual LM, l’obiettivo è lo stesso dell’input spostato di una posizione a destra. Per Masked LM, è necessario creare un addestramento privo di rumore in cui l’obiettivo è il valore reale delle maschere.
I modelli di linguaggio causali sono chiamati così perché operano in modo causale, prevedendo in base ai token precedenti e presumibilmente in base alla relazione causale di quei token. Come viene trovata questa relazione è tutta la storia del Modello Transformer e del ruolo dell'”Attention” – il famoso documento “Attention is all you need” che ha introdotto le Reti Transformer.
Non è facile spiegare questo concetto in modo semplice. Ti consiglio vivamente di guardare questo video di spiegazione, possibilmente più volte: Intuition Behind Self-Attention Mechanism in Transformer Networks – YouTube.
Possiamo dire che nel processo di apprendimento del token ‘successivo’ corretto da prevedere, vengono apprese tre serie di pesi per token mediante retropropagazione della perdita: i pesi della Chiave, della Query e del Valore. Questi formano la base del meccanismo “Attention”. Il video sopra spiega in modo eccellente questo concetto in questa posizione.
Il concetto di prodotto scalare tra vettori viene utilizzato per calcolare i vettori Valore, che è la somma del contributo del prodotto scalare dei vettori Query e Chiave.
L’intuizione è che i vettori “simili” nello spazio di incorporamento dei vettori avranno un valore di prodotto scalare maggiore e un contributo maggiore. Questo è il trucco per catturare l’associazione causale di token/parole in una frase.
I pesi vengono quindi regolati tramite retropropagazione, il che significa che i pesi appresi rappresentano uno spazio di incorporamento vettoriale contestuale nuovo e migliore per la frase. (I pesi delle Chiavi e delle Query sono multidimensionali e ci sono più “attention heads”, quindi non si tratta di uno spazio vettoriale ma di molti)
Nelle Reti Transformer, ci sono più “attention heads”, quindi quale attention head pesare di più può anche essere regolato tramite pesi. La rete Transformer è questa architettura, in cui l’intuizione della relazione causale tra i token è codificata come pesi apprendibili in strati lineari di reti neurali.
Ho cercato di spiegare questo concetto in un’immagine semplificata qui sotto
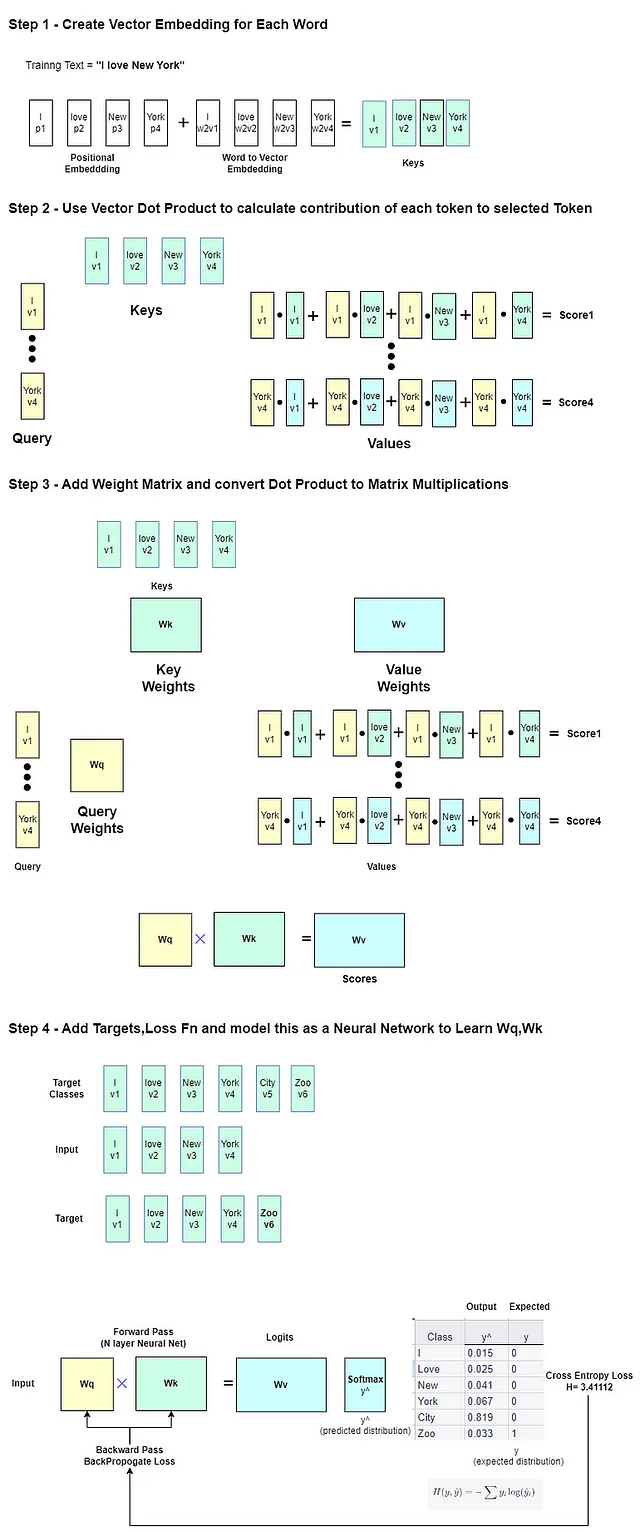
Puoi vedere qui in maggior dettaglio come un piccolo modello pre-addestrato, che ha la probabilità più alta di generare
CiydopoI love New York, può essere ottimizzato per ridurre la perdita nella generazione diZoohttps://github.com/alexcpn/tranformer_learn/blob/main/LLM_Loss_Understanding.ipynb
Quindi, non c’è nulla di straordinario qui. Abbiamo visto il solito apprendimento non supervisionato (nel contesto di LLM) attraverso l’addestramento supervisionato, la funzione di perdita, l’addestramento (basato sull’usuale discesa del gradiente e retropropagazione)
Tuttavia, quando la rete diventa grande e i dati di addestramento diventano enormi (da miliardi a trilioni di token), si verifica un altro fenomeno in cui, oltre al semplice “fittare la curva”, può generalizzare l’addestramento per “comprendere” la struttura intrinseca (lingua umana, linguaggio di programmazione, ecc.) dei dati di addestramento senza essere esplicitamente addestrato per questo. Questo è il santo graal dell’apprendimento non supervisionato.
Ilya Sutskever lo descrive qui https://youtu.be/AKMuA_TVz3A?t=490
Quindi, dall’umile addestramento supervisionato, si sviluppa il misterioso apprendimento non supervisionato
L’emergenza della comprensione
Il paper Language Models are Unsupervised Multitask Learners ha introdotto GPT-2 nel mondo sulla base dell’architettura Transformer. Ha fatto qualcosa di straordinario.
Ha dimostrato empiricamente che un LLM sufficientemente grande, quando addestrato con un dataset sufficientemente grande (CommomCrawl / WebText – dati di internet ripuliti), inizia a “comprendere” la struttura del linguaggio. Intenzionalmente non uso il termine meno controverso “generalizzare” invece di “comprendere” qui per comunicare meglio il significato a tutti.
Ecco un paper di ricerca di Google/DeepMind facile da leggere su questo argomento https://arxiv.org/pdf/2206.07682.pdf.
Mostrano otto modelli in cui il comportamento emergente, misurato dalla precisione rispetto alla selezione casuale per alcune attività prompt a pochi passi, aumenta notevolmente con la scala del modello..
Gli stessi autori hanno discusso questo con migliori visualizzazioni (sotto)
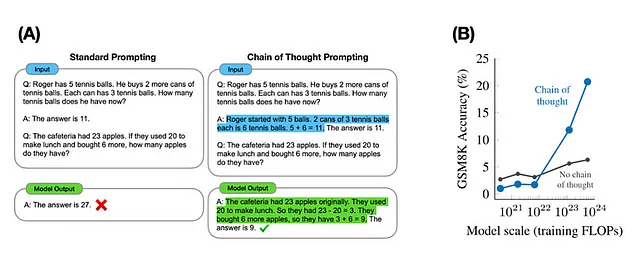
Ci sono altri studi che contestano questo e questo dibattito è appena iniziato. Il paper fa riferimento all’incapacità del LLM in matematica, che ovviamente non è il suo punto di forza.
Per comprendere veramente qualcosa e non essere solo un generatore di distribuzioni probabilistiche, è necessario essenzialmente un modello di mondo interno appreso, secondo Ilya Sutskever. Questo lo rende completamente diverso da altre forme di ML e AI.
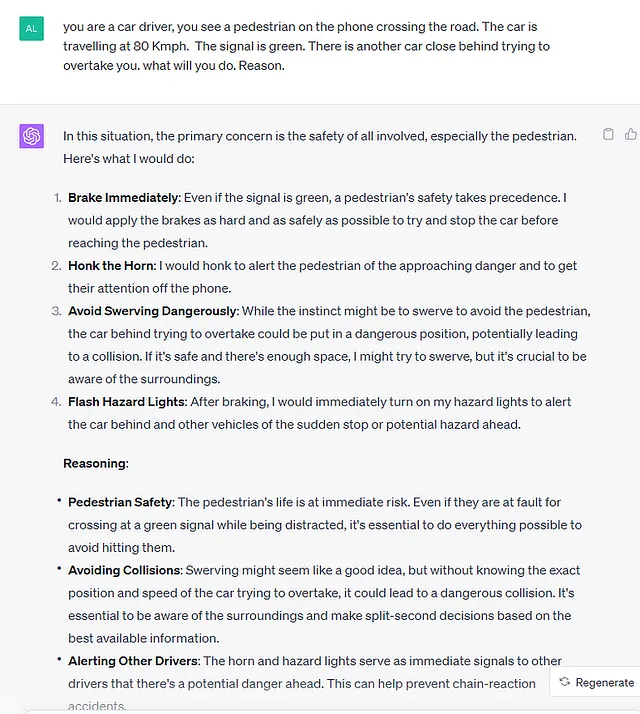
Per rendere questo chiaro, ecco un esempio di input e output dal modello ChatGpt4. Il modello non è stato esplicitamente addestrato per la guida automobilistica. Ma puoi vedere che ha formato una visione del mondo o un modello del mondo dai suoi dati di addestramento e può rispondere in modo completo.
Non è chiaro come avvenga l’emergenza della comprensione quando scala il parametro di addestramento e del modello, poiché ciò che semplifichiamo come un generatore di funzioni di distribuzione di probabilità o rigettiamo come pappagalli stocastici potrebbe avere ulteriori rivelazioni nella ricerca futura. Il ruolo della casualità, o del suo studio/misurazione – la probabilità, nei sistemi di interfaccia complessi, ad esempio, come presentato in “L’orologiaio cieco”, correlato all’evoluzione e alla fisica a livello quantistico, a volte fa riflettere se ci sia un altro modo oltre alle funzioni di distribuzione di probabilità per descriverli. È necessaria più ricerca e più struttura per spiegare questo in modo più chiaro.
Ad esempio, ho cercato entropia e LLM e sono arrivato a questo articolo Studio della possibilità di transizioni di fase in LLM e anche una presentazione correlata del fondatore di Wolfarm e scienziato Stephen Wolfarm. Quindi non è così azzardato pensare in queste direzioni.
Si noti che altri segnali che seguono questa proprietà del linguaggio potrebbero essere candidati efficaci per l’addestramento di LLM, dove invece delle parole, il segnale potrebbe essere tokenizzato. Un esempio potrebbe essere la musica https://ai.googleblog.com/2022/10/audiolm-language-modeling-approach-to.html. Allo stesso modo, le strutture che non seguono questo modello, come ad esempio il DNA, potrebbero essere un accoppiamento difficile per questi tipi di modelli.
Tornando al punto — c’è una gara su come sfruttare questo potenziale di LLM in vari settori. Inizieremo con quelli più semplici e successivamente con forme più estese in cui la capacità di ragionamento del modello potrebbe essere utilizzata nelle applicazioni. Tratteremo questo argomento nella Parte 2 della serie.