Stendi le tue ali Falcon 180B è qui
Falcon 180B è qui, stendi le tue ali
Introduzione
Oggi siamo entusiasti di dare il benvenuto al Falcon 180B di TII su HuggingFace! Il Falcon 180B rappresenta un nuovo stato dell’arte per i modelli aperti. È il modello di linguaggio più grande disponibile pubblicamente, con 180 miliardi di parametri, ed è stato addestrato su un’enorme quantità di 3,5 trilioni di token utilizzando il dataset RefinedWeb di TII. Questo rappresenta il preaddestramento più lungo per un modello aperto in un singolo epoch.
Puoi trovare il modello su Hugging Face Hub (modello base e modello di chat) e interagire con il modello nello spazio di dimostrazione Falcon Chat.
Per quanto riguarda le capacità, il Falcon 180B ottiene risultati all’avanguardia in diverse attività di linguaggio naturale. Si posiziona al primo posto nella classifica dei modelli di accesso aperto (preaddestrati) e sfida i modelli proprietari come PaLM-2. Sebbene sia ancora difficile classificarlo definitivamente, si considera all’altezza di PaLM-2 Large, rendendo il Falcon 180B uno dei modelli di linguaggio più avanzati pubblicamente conosciuti.
In questo post del blog, esploreremo cosa rende il Falcon 180B così buono analizzando alcuni risultati di valutazione e mostreremo come puoi utilizzare il modello.
- On-Policy vs. Off-Policy Monte Carlo, con visualizzazioni
- Questa newsletter sull’AI è tutto ciò di cui hai bisogno #63
- Esplorazione dei grandi modelli linguistici – Parte 1
- Cosa è il Falcon-180B?
- Quanto è buono il Falcon 180B?
- Come utilizzare il Falcon 180B?
- Demo
- Requisiti hardware
- Formato delle istruzioni
- Transformers
- Risorse aggiuntive
Cosa è il Falcon-180B?
Falcon 180B è un modello rilasciato da TII che fa seguito ai precedenti modelli della famiglia Falcon.
Per quanto riguarda l’architettura, il Falcon 180B è una versione ingrandita del Falcon 40B e si basa sulle sue innovazioni come l’attenzione multiquery per migliorare la scalabilità. Consigliamo di consultare il post iniziale del blog che introduce Falcon per approfondire l’architettura. Il Falcon 180B è stato addestrato su 3,5 trilioni di token su un massimo di 4096 GPU contemporaneamente, utilizzando Amazon SageMaker per un totale di ~7.000.000 ore di GPU. Ciò significa che il Falcon 180B è 2,5 volte più grande di Llama 2 ed è stato addestrato con 4 volte più risorse di calcolo.
Il dataset per il Falcon 180B consiste principalmente di dati web provenienti da RefinedWeb (~85%). Inoltre, è stato addestrato su una miscela di dati selezionati come conversazioni, documenti tecnici e una piccola frazione di codice (~3%). Questo dataset di preaddestramento è abbastanza grande da rendere i 3,5 trilioni di token una quantità inferiore a un epoch.
Il modello di chat rilasciato è stato sottoposto a un fine-tuning su dataset di chat e istruzioni con una miscela di diversi dataset di conversazioni su larga scala.
‼️ Utilizzo commerciale: Falcon 180b può essere utilizzato a scopo commerciale, ma in condizioni molto restrittive, escludendo qualsiasi “uso di hosting”. Consigliamo di verificare la licenza e consultare il proprio team legale se si è interessati a utilizzarlo per scopi commerciali.
Quanto è buono il Falcon 180B?
Il Falcon 180B è attualmente il miglior modello di linguaggio rilasciato pubblicamente, superando Llama 2 70B e GPT-3.5 di OpenAI su MMLU, ed è all’altezza di PaLM 2-Large di Google su HellaSwag, LAMBADA, WebQuestions, Winogrande, PIQA, ARC, BoolQ, CB, COPA, RTE, WiC, WSC, ReCoRD. Il Falcon 180B si posiziona di solito tra GPT 3.5 e GPT4 a seconda del benchmark di valutazione, e sarà molto interessante seguire ulteriori finetuning dalla comunità ora che è stato rilasciato pubblicamente.
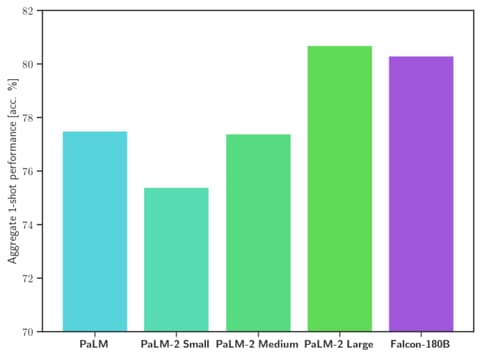
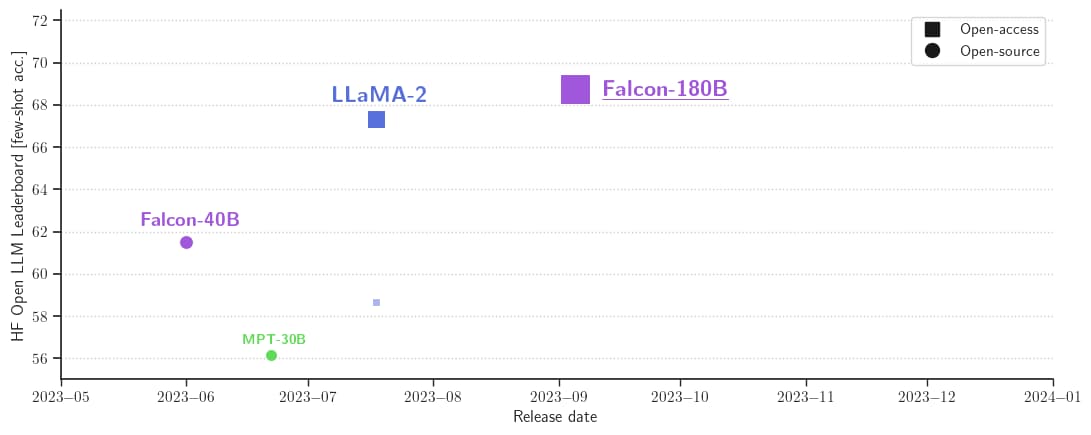
Con 68,74 nel Leaderboard di Hugging Face, il Falcon 180B è il modello preaddestrato LLM rilasciato pubblicamente con il punteggio più alto, superando LLaMA 2 di Meta (67,35).
Come utilizzare il Falcon 180B?
Il Falcon 180B è disponibile nell’ecosistema di Hugging Face a partire dalla versione 4.33 di Transformers.
Demo
Puoi facilmente provare il Big Falcon Model (180 miliardi di parametri!) in questo Spazio o nel playground incorporato di seguito:
Requisiti hardware
Formato prompt
Il modello di base non ha un formato prompt. Ricorda che non si tratta di un modello conversazionale o addestrato con istruzioni, quindi non aspettarti che generi risposte conversazionali: il modello preaddestrato è una piattaforma ideale per il fine-tuning successivo, ma probabilmente non dovresti usarlo direttamente così com’è. Il modello Chat ha una struttura di conversazione molto semplice.
Sistema: Aggiungi qui un prompt di sistema facoltativo
Utente: Questo è l'input dell'utente
Falcon: Questo è ciò che il modello genera
Utente: Questo potrebbe essere un secondo input di turno
Falcon: e così viaTransformers
Con il rilascio di Transformers 4.33, puoi utilizzare Falcon 180B e sfruttare tutti gli strumenti dell’ecosistema HF, come ad esempio:
- script ed esempi di addestramento e inferenza
- formato file sicuro (safetensors)
- integrazioni con strumenti come bitsandbytes (quantizzazione a 4 bit), PEFT (fine-tuning efficiente dei parametri) e GPTQ
- generazione assistita (nota anche come “decodifica speculativa”)
- supporto RoPE per lunghezze di contesto più ampie
- parametri di generazione ricchi e potenti
L’utilizzo del modello richiede l’accettazione della sua licenza e dei termini d’uso. Assicurati di essere loggato nel tuo account Hugging Face e di avere l’ultima versione di transformers:
pip install --upgrade transformers
huggingface-cli loginbfloat16
Ecco come si utilizza il modello di base in bfloat16. Falcon 180B è un modello complesso, quindi prendi in considerazione i requisiti hardware riassunti nella tabella sopra.
from transformers import AutoTokenizer, AutoModelForCausalLM
import transformers
import torch
model_id = "tiiuae/falcon-180B"
tokenizer = AutoTokenizer.from_pretrained(model_id)
model = AutoModelForCausalLM.from_pretrained(
model_id,
torch_dtype=torch.bfloat16,
device_map="auto",
)
prompt = "Mi chiamo Pedro, vivo in"
inputs = tokenizer(prompt, return_tensors="pt").to("cuda")
output = model.generate(
input_ids=inputs["input_ids"],
attention_mask=inputs["attention_mask"],
do_sample=True,
temperature=0.6,
top_p=0.9,
max_new_tokens=50,
)
output = output[0].to("cpu")
print(tokenizer.decode(output)Ciò potrebbe produrre un output del genere:
Mi chiamo Pedro, vivo in Portogallo e ho 25 anni. Sono un grafico, ma sono anche appassionato di fotografia e video.
Amo viaggiare e sono sempre alla ricerca di nuove avventure. Amo conoscere nuove persone ed esplorare nuovi posti.8-bit e 4-bit con bitsandbytes
Le versioni quantizzate a 8-bit e 4-bit di Falcon 180B mostrano una differenza quasi nulla in termini di valutazione rispetto al riferimento bfloat16! Questa è una buona notizia per l’inferenza, poiché puoi utilizzare con fiducia una versione quantizzata per ridurre i requisiti hardware. Tieni presente, però, che l’inferenza a 8-bit è molto più veloce rispetto all’esecuzione del modello a 4-bit.
Per utilizzare la quantizzazione, è necessario installare la libreria bitsandbytes e abilitare semplicemente il flag corrispondente durante il caricamento del modello:
model = AutoModelForCausalLM.from_pretrained(
model_id,
torch_dtype=torch.bfloat16,
load_in_8bit=True,
device_map="auto",
)Modello Chat
Come accennato in precedenza, la versione del modello addestrato per seguire le conversazioni utilizza un template di addestramento molto semplice. Dobbiamo seguire lo stesso schema per eseguire l’inferenza in stile chat. A titolo di riferimento, puoi dare un’occhiata alla funzione format_prompt nella demo Chat, che si presenta così:
def format_prompt(message, history, system_prompt):
prompt = ""
if system_prompt:
prompt += f"Sistema: {system_prompt}\n"
for user_prompt, bot_response in history:
prompt += f"Utente: {user_prompt}\n"
prompt += f"Falcon: {bot_response}\n"
prompt += f"Utente: {message}\nFalcon:"
return promptCome puoi vedere, le interazioni dell’utente e le risposte del modello sono precedute dai separatori User: e Falcon:. Li concateniamo insieme per formare un prompt che contiene l’intera storia della conversazione. Possiamo fornire un prompt di sistema per regolare lo stile della generazione.
Risorse aggiuntive
- Modelli
- Demo
- Il Falcon è atterrato nell’ecosistema di Hugging Face
- Annuncio ufficiale
Ringraziamenti
Rilasciare un modello del genere, con supporto ed valutazioni nell’ecosistema, non sarebbe stato possibile senza il contributo di molti membri della comunità, tra cui Clémentine ed Eleuther Evaluation Harness per le valutazioni LLM; Loubna e BigCode per le valutazioni del codice; Nicolas per il supporto all’inferenza; Lysandre, Matt, Daniel, Amy, Joao e Arthur per l’integrazione del Falcon in transformers. Grazie a Baptiste e Patrick per la demo open-source. Grazie a Thom, Lewis, TheBloke, Nouamane, Tim Dettmers per i molteplici contributi che hanno reso possibile tutto ciò. Infine, grazie al HF Cluster per consentire l’esecuzione delle valutazioni LLM e per fornire l’inferenza per una demo gratuita e open-source del modello.