Data Morph Andare oltre i Dodici Datasaurus
Andare oltre i Dodici Datasaurus

Nota dell’editore: Stefanie Molin è una relatrice per ODSC West 2023 quest’autunno. Assicurati di dare un’occhiata al suo intervento, “Data Morph: Un racconto di avvertimento sulle statistiche riassuntive,” lì!
Questo articolo introduce Data Morph, un nuovo pacchetto open-source Python che può essere utilizzato per trasformare un insieme di punti 2D in forme selezionate, preservando le statistiche riassuntive ad un dato numero di cifre decimali attraverso il surriscaldamento simulato. Data Morph estende la ricerca di Autodesk per creare il Datasaurus Dozen ed è destinato ad essere utilizzato come strumento didattico per illustrare perché non si può fare affidamento solo sulle statistiche riassuntive.
Gioca con noi. Sto pensando ad una distribuzione con le seguenti statistiche riassuntive. Riesci ad immaginare come apparirebbe un grafico a dispersione dei dati?
- Apprendimento di rappresentazioni su grafi e reti
- Semplificazione dell’analisi delle serie temporali per i data scientist
- Saturn Un nuovo approccio per l’addestramento di grandi modelli di linguaggio e altre reti neurali
- Media di X = 30.37
- Media di Y = 53.01
- Deviazione standard di X = 13.44
- Deviazione standard di Y = 15.53
- Coefficiente di correlazione di Pearson = 0.04
La media è una misura di centralità, la deviazione standard è una misura di dispersione dal centro e la correlazione quantifica come le variabili x e y si muovono insieme, quindi è tentante pensare che questo sia sufficiente per descrivere i dati. Tuttavia, queste statistiche riassuntive sono insufficienti: ci sono molti dataset possibili per un dato insieme di statistiche riassuntive. Ecco un grafico a dispersione dei dati che stavo riassumendo – hai indovinato?

Il dataset musicale fornito da Data Morph.
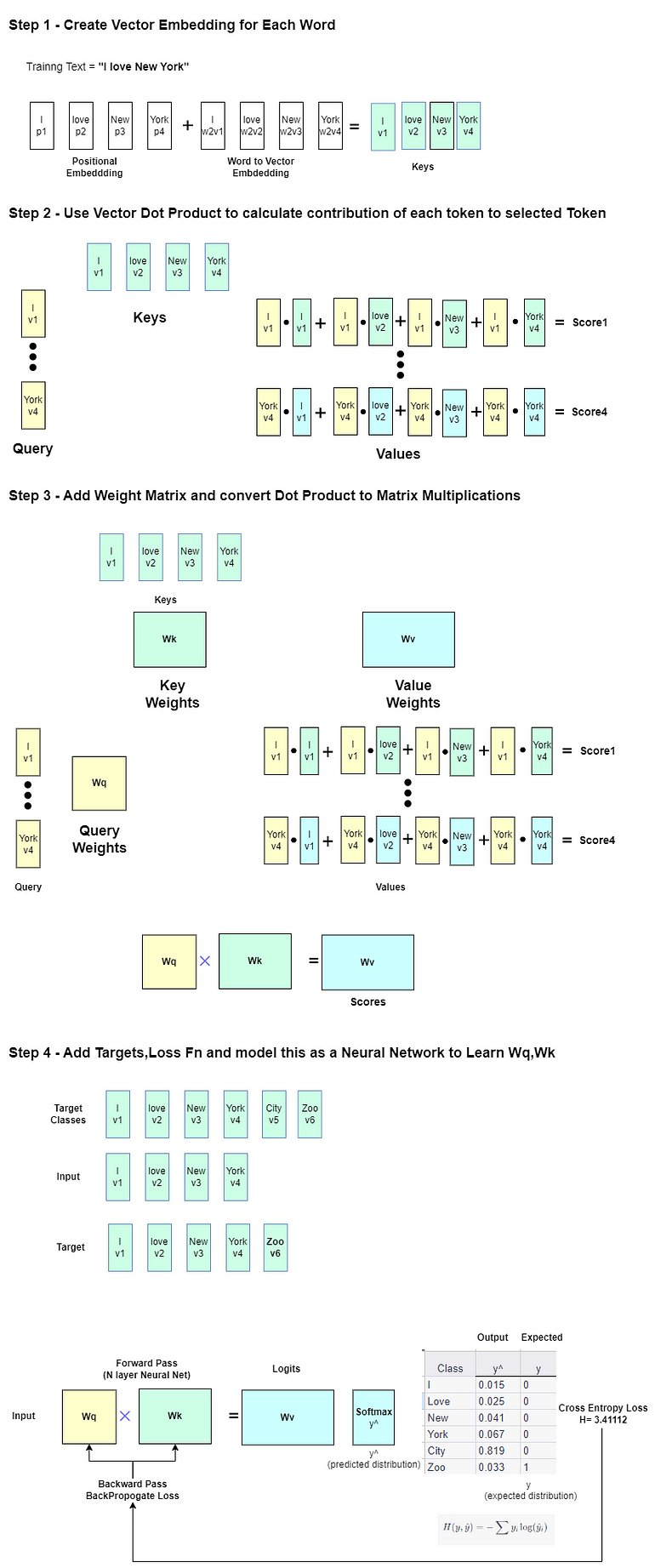
La nozione che non possiamo fare affidamento solo sulle statistiche riassuntive non è nuova. I ricercatori hanno illustrato ciò generando molti dataset molto diversi visualmente, ma condividono le stesse statistiche riassuntive. Nel 1973, Francis Anscombe ha introdotto un insieme di quattro tali dataset noto come il “Quartetto di Anscombe”:
Ognuno di questi dataset è molto diverso visualmente, tuttavia condividono tutti le stesse statistiche riassuntive. (Questa visualizzazione è stata creata da Stefanie Molin utilizzando il dataset del Quartetto di Anscombe fornito da seaborn.)
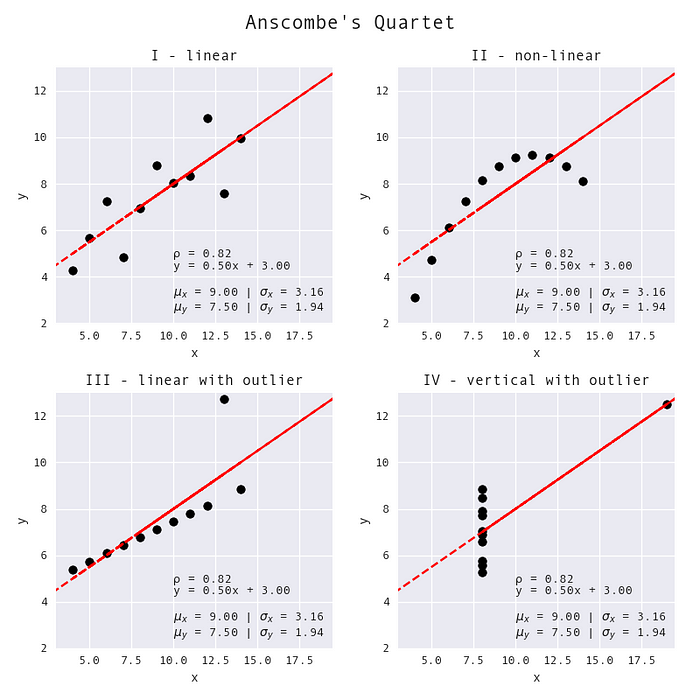
Nel 2017, i ricercatori di Autodesk hanno sviluppato il “Datasaurus Dozen” a partire dall’idea del Quartetto di Anscombe: hanno trasformato un insieme di punti a forma di dinosauro (il Datasaurus di Alberto Cairo) in 12 forme distinte utilizzando il “surrogato annealing simulato”, che è una tecnica per trovare ottimi globali, nel progetto “Statistiche Simili, Grafici Diversi”:
I dataset del Datasaurus Dozen. (Questa visualizzazione è stata creata da Stefanie Molin utilizzando il dataset del Datasaurus Dozen fornito da jmatejka/same-stats-different-graphs.)
Per generare il Datasaurus Dozen, l’algoritmo seleziona ripetutamente un punto dal dataset in modo casuale e cerca di spostarlo in una nuova posizione perturbandolo di una piccola quantità casuale. Affinché la nuova posizione venga considerata, deve cambiare solo le statistiche riassuntive di una quantità sufficientemente piccola tale che i valori vecchi e nuovi siano ancora equivalenti a due cifre decimali. Se il cambio di posizione riduce la distanza dalla forma target, l’algoritmo sposta quel punto nella nuova posizione. Tuttavia, se aumenta la distanza dalla forma target, l’algoritmo sposterà il punto nella nuova posizione solo con una certa probabilità, p, che diminuisce nel tempo. Durante le prime iterazioni, l’algoritmo è più propenso ad accettare nuove posizioni che lo allontanano dalla forma target; man mano che le iterazioni passano, questa probabilità diminuisce. Questo processo aiuta ad evitare di rimanere bloccati in ottimi locali e consente una maggiore varianza nelle forme che possono essere create, dal momento che più dello spazio può essere esplorato.
Rispetto al Quartetto di Anscombe, c’è un maggiore effetto sorpresa nel vedere il Datasaurus trasformarsi in un insieme di linee inclinate, preservando le statistiche riassuntive. Credo che questo effetto sorpresa sia più efficace quando si tratta di spiegare perché la visualizzazione dei dati è essenziale – basta dare un’occhiata alle reazioni a questo post su LinkedIn.
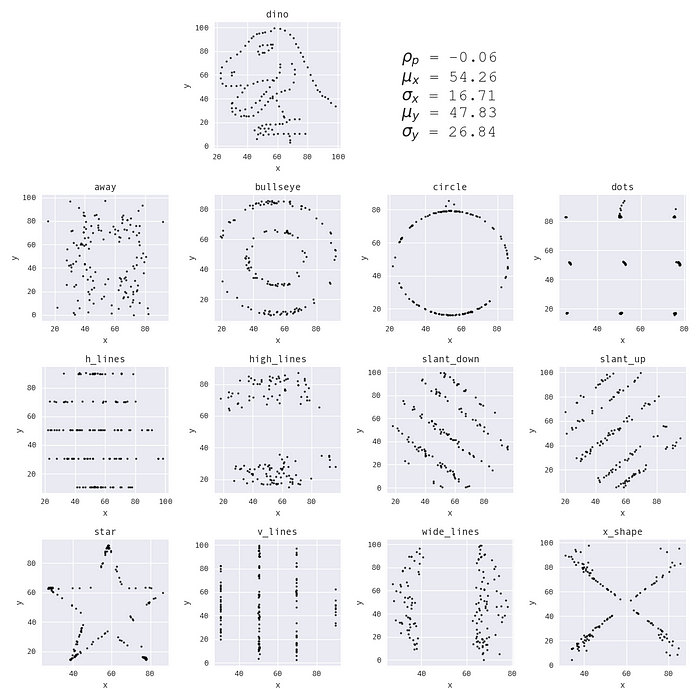
Volevo utilizzare questo fattore sorpresa nel mio workshop su Pandas per motivare la sezione sulla visualizzazione dei dati. Dopo la sezione sulla manipolazione dei dati, è cruciale sottolineare l’importanza della visualizzazione dei dati in questo momento perché la creazione di visualizzazioni può essere più complicata. Le persone sono spesso tentate di prendere la scorciatoia e utilizzare solo statistiche riassuntive per descrivere i dati. Tuttavia, l’utilizzo del dinosauro per l’animazione sembrava fuori tema per il workshop, che presenta immagini di panda in tutto – avevo bisogno di creare un dataset a forma di panda. Fornisco alcuni consigli su come passare da un’idea a un dataset di input qui.
Un nuovo dataset di partenza a forma di panda.
Ho presto capito che degli strumenti visivi personalizzati e d’impatto avrebbero giovato non solo al mio workshop, ma anche a chi impara e insegna l’analisi dei dati. Così nel 2023, ho esplorato come il codice dei ricercatori di Autodesk potesse essere generalizzato a un dataset arbitrario, cioè invece del Datasaurus o del panda. Questo mi ha portato a creare Data Morph, un pacchetto Python open source che può essere utilizzato per trasformare un dataset di input di punti 2D in forme selezionate, preservando le statistiche riassuntive fino a un determinato numero di cifre decimali utilizzando la stessa tecnica di ricottura simulata.
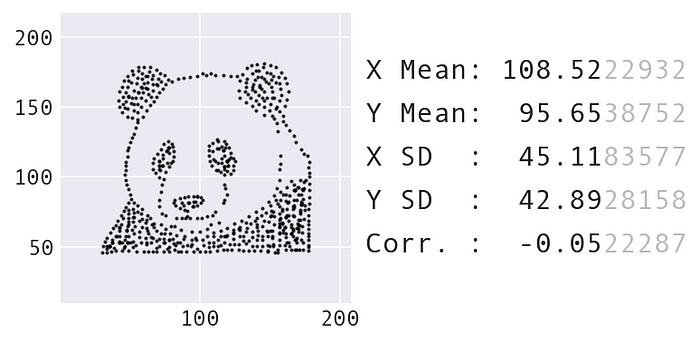
Era necessario effettuare significativi refactoring per generalizzare il codice Same Stats, Different Graphs in modo che funzionasse con un input diverso. Tutta la logica per le forme target (pensa al centro e al raggio di un cerchio, agli estremi di una linea, ecc.) era codificata nel codice ed era quindi specifica per i dataset inclusi nel codice del team di Autodesk. La posizione e gli attributi delle forme target devono essere calcolati dal dataset di partenza, con alcune forme che sono molto più semplici da codificare rispetto ad altre. Ad esempio, per trasformarsi nella forma di un cerchio, il centro del cerchio può essere la media dei valori di x e y; il raggio può essere un multiplo della deviazione standard (x o y, scegli uno):
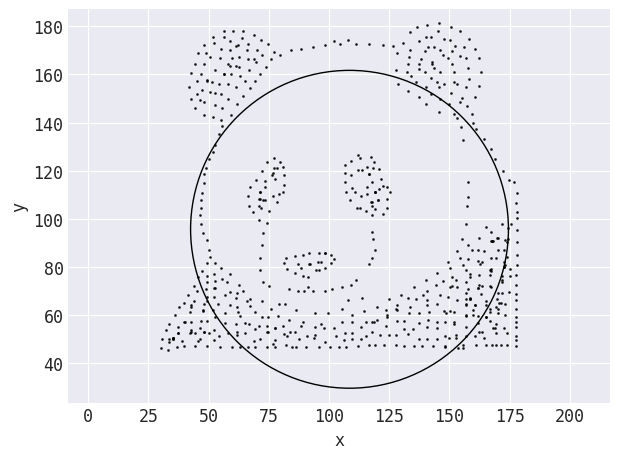
La forma target che Data Morph calcola quando cerca di trasformare il panda mostrato in precedenza in un cerchio. Le distanze sono calcolate dai punti alla linea che forma il cerchio.
Data Morph fornisce una gerarchia di classi di forme per consentire la creazione di forme composite (ad esempio, la forma del cerchio viene utilizzata per creare una forma a bersaglio, che comprende due cerchi concentrici) e centralizzare il calcolo della distanza per un codice efficiente. Tuttavia, per alcune forme, l’utilizzo delle informazioni dai dati non funziona esattamente: a volte i punti devono spostarsi al di fuori dei limiti del dataset di partenza. Per gestire questa logica, Data Morph include alcuni calcoli automatici dei limiti a cui si collegano forme e funzionalità di tracciamento:
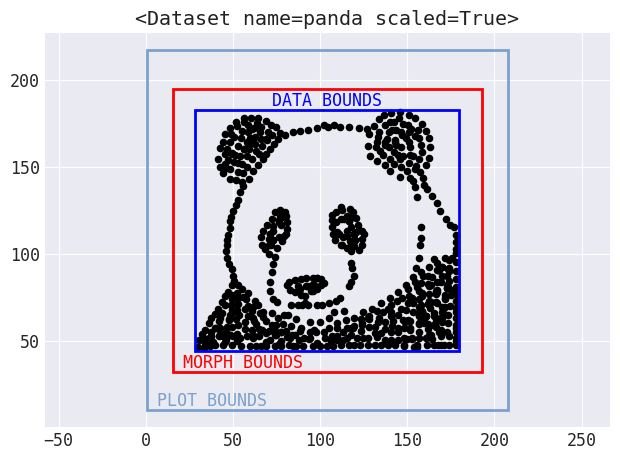
I limiti vengono calcolati automaticamente per l’utilizzo nella trasformazione e nel tracciamento.
Un’altra grande modifica è stata quella di ridurre al minimo la quantità massima che i punti potevano spostarsi nel tempo, anziché mantenerla statica, il che produce un effetto visivo migliore durante lo spostamento dei punti. Ecco un esempio di trasformazione del dataset del panda in una stella:
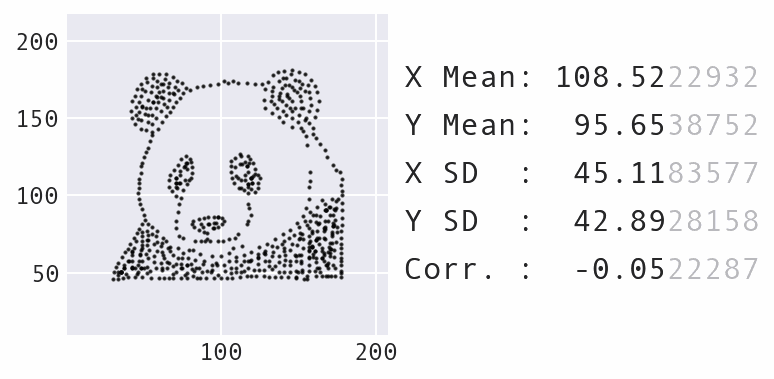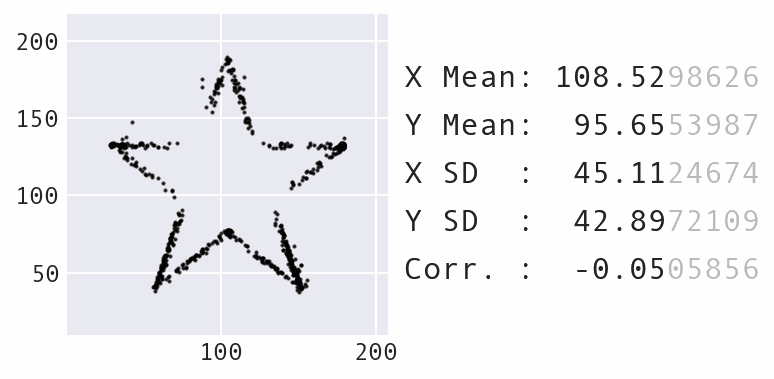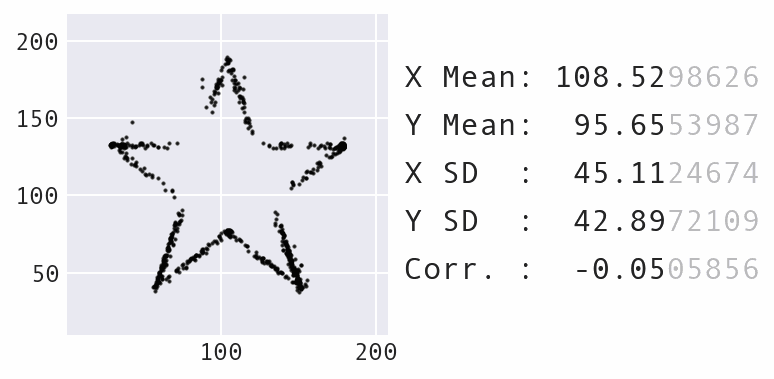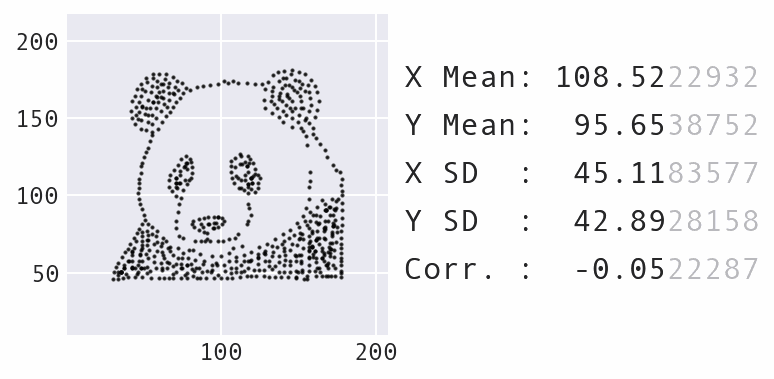
Trasformazione del dataset del panda in una stella con Data Morph.
Come mostra l’animazione sopra, il panda e la stella non solo hanno le stesse statistiche riassuntive, ma anche tutti i dataset incontrati lungo il percorso nel processo di trasformazione. Unendo questo al fatto che il panda può anche essere trasformato in diverse altre forme riconoscibili, come il cerchio mostrato in precedenza, si ottiene un numero infinito di possibili dataset che corrispondono alle statistiche riassuntive.
Tuttavia, ci sono alcune limitazioni: non è sempre possibile trasformare un dataset in tutte le forme target offerte da Data Morph. Se non ci sono punti dalla forma di partenza in una specifica regione che fa parte della forma target, potrebbe non essere possibile spingere i punti lì senza alterare le statistiche riassuntive. Ad esempio, quando si trasforma un qualche dataset di input nella forma di un rettangolo, potrebbero mancare alcune parti delle linee. Una volta che sperimenti con diversi dataset di input, acquisirai intuizioni su quali forme funzioneranno e quali no (e perché).
Al momento della stesura, Data Morph include 6 forme di partenza predefinite e 15 forme target, con l’aggiunta di ulteriori forme in futuro. La trasformazione è semplice come questo:
$ pip install data-morph-ai
$ data-morph --start-shape panda --target-shape starForme di partenza arbitrarie/personalizzate possono essere fornite tramite file CSV, come questo (vedi la documentazione qui per consigli su come crearne uno tuo):
Un esempio creato utilizzando un file CSV.
Data Morph fornisce anche documentazione sull’utilizzo sia della CLI che dell’interprete Python, una suite di test, codice modulare e una gerarchia di classi flessibile per aggiungere nuove forme di destinazione. Ulteriori informazioni sulle migliorie principali possono essere trovate nelle note sulla versione qui.
La prossima volta che ti trovi a spiegare o insegnare statistiche di sintesi, ti invito a utilizzare Data Morph per creare un’animazione divertente e personalizzata per sottolineare l’importanza di visualizzare i dati. Chiedi agli studenti o ai partecipanti di creare le loro animazioni. Vedere numerosi esempi che partono da forme familiari (ad esempio, il logo o la mascotte della tua scuola, ecc.) manterrà questo concetto importante sempre in mente. Se alla fine utilizzi Data Morph con un dataset personalizzato e/o per scopi didattici, mi piacerebbe saperne di più: taggami nei tuoi post su LinkedIn o Twitter.
Felice trasformazione!
Articolo originariamente pubblicato qui. Ripubblicato con il permesso dell’autore.
 Stefanie Molin è un ingegnere informatico e scienziato dei dati presso Bloomberg a New York City, dove affronta problemi complessi legati alla sicurezza delle informazioni, in particolare quelli legati alla manipolazione/visualizzazione dei dati, alla creazione di strumenti per la raccolta di dati e alla condivisione delle conoscenze. È anche autrice di “Hands-On Data Analysis with Pandas”, attualmente alla sua seconda edizione. Ha conseguito una laurea in ingegneria delle operazioni presso la Fu Foundation School of Engineering and Applied Science dell’Università di Columbia, nonché un master in informatica, con una specializzazione in apprendimento automatico, presso il Georgia Tech. Nel suo tempo libero ama viaggiare per il mondo, inventare nuove ricette e imparare nuovi linguaggi parlati tra persone e computer.
Stefanie Molin è un ingegnere informatico e scienziato dei dati presso Bloomberg a New York City, dove affronta problemi complessi legati alla sicurezza delle informazioni, in particolare quelli legati alla manipolazione/visualizzazione dei dati, alla creazione di strumenti per la raccolta di dati e alla condivisione delle conoscenze. È anche autrice di “Hands-On Data Analysis with Pandas”, attualmente alla sua seconda edizione. Ha conseguito una laurea in ingegneria delle operazioni presso la Fu Foundation School of Engineering and Applied Science dell’Università di Columbia, nonché un master in informatica, con una specializzazione in apprendimento automatico, presso il Georgia Tech. Nel suo tempo libero ama viaggiare per il mondo, inventare nuove ricette e imparare nuovi linguaggi parlati tra persone e computer.