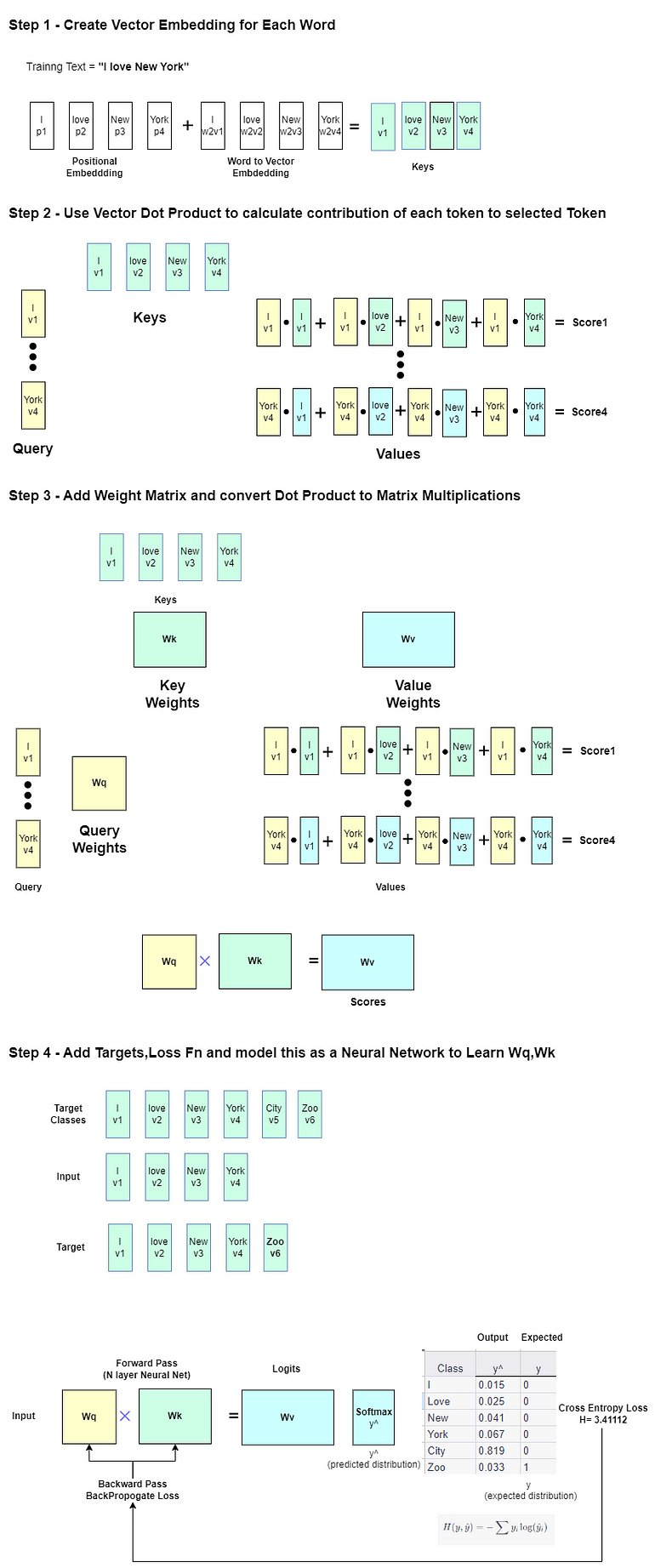
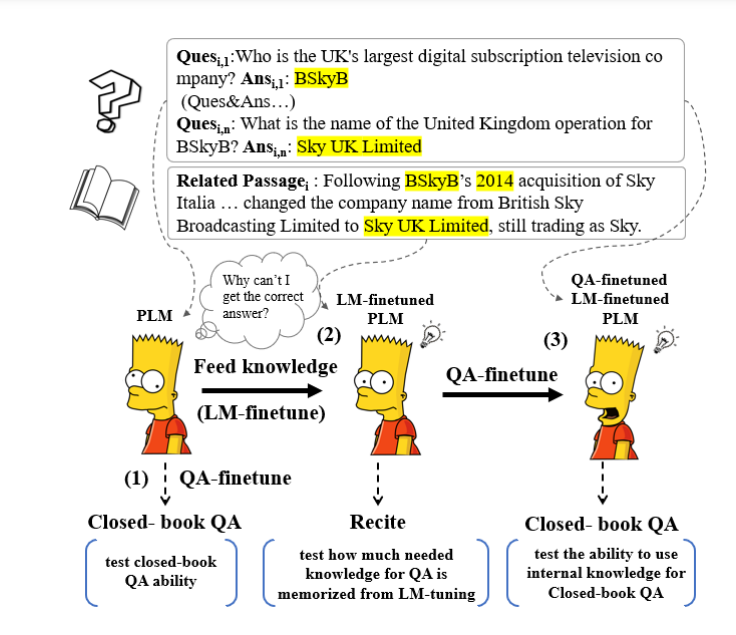
Semplificazione dell’analisi delle serie temporali per i data scientist
Semplificazione analisi serie temporali per data scientist

Nota dell’editore: Jeff Tao è un relatore per ODSC West 2023 questo autunno. Assicurati di dare un’occhiata al suo intervento, “Cos’è un database di serie temporali e perché ne ho bisogno?” lì!
La maggior parte dei data scientist è familiare con il concetto di dati di serie temporali e lavora spesso con essi. Il database di serie temporali (TSDB), tuttavia, è ancora uno strumento sottoutilizzato nella comunità della scienza dei dati. Anche se configurare un database per eseguire le tue analisi può sembrare un compito arduo, i moderni database di serie temporali open source possono offrire significativi vantaggi a qualsiasi scienziato che esegue analisi di serie temporali su un grande set di dati, e con molto meno sforzo di quanto si possa immaginare.
Di solito, l’analisi di serie temporali viene eseguita su file CSV o data lake. Queste soluzioni possono sembrare più semplici rispetto ai database tradizionali perché possono archiviare essenzialmente qualsiasi tipo di dati senza la necessità di uno schema predefinito. Tuttavia, rendono più difficile mantenere il contesto di ogni punto dati – ad esempio, la posizione di un rilevatore di dati, la temperatura al momento della raccolta o una serie di altri elementi che devono essere preservati per garantire che la tua analisi sia corretta. Inoltre, la flessibilità dei data lake in termini di organizzazione dei dati può avere l’effetto collaterale indesiderato di rendere quei dati difficili da interrogare o filtrare.
- Saturn Un nuovo approccio per l’addestramento di grandi modelli di linguaggio e altre reti neurali
- Costruire un assistente alimentato da ChatGPT e abilitato alla voce utilizzando React e Express
- Stendi le tue ali Falcon 180B è qui
Un database di serie temporali appositamente progettato, d’altra parte, può facilmente mantenere questo tipo di metadati sotto forma di tag o etichette associate a ciascuna serie temporale. La pulizia e la trasformazione dei dati diventano anche compiti semplici con un TSDB: ad esempio, allineare i timestamp di più set di dati può essere eseguito rapidamente con funzioni di interpolazione o aggregazione integrate nel database. E il recupero dei dati è semplice con un linguaggio di query come SQL, in cui è possibile filtrare per valore, tag, intervallo di tempo e altro ancora.
TDengine è un esempio di database di serie temporali che semplifica il processo di analisi dei dati di serie temporali su larga scala in modo che i data scientist possano dedicare più tempo alla loro attività. Elabora e archivia rapidamente enormi set di dati con elevate prestazioni e scalabilità, e con una piccola conoscenza di SQL puoi gestire i tuoi dati in modo molto più comodo rispetto ai file CSV tradizionali. Inoltre, puoi iniziare con TDengine in soli 60 secondi e la sua edizione open source è gratuita da scaricare e utilizzare.
Sono inclusi per impostazione predefinita una varietà di funzioni di serie temporali, come somme cumulative, medie ponderate nel tempo e medie mobili, e puoi anche creare funzioni definite dall’utente (UDF) in Python o C. Il supporto per progetti popolari dell’ecosistema Python come pandas e Jupyter garantisce che tu possa inserire e recuperare facilmente i tuoi dati, e l’integrazione senza soluzione di continuità con strumenti di visualizzazione come Grafana ti consente di mostrare il tuo lavoro in modi innovativi e generare nuove intuizioni.
Se desideri saperne di più sui database di serie temporali e su come possono aiutarti ad analizzare i dati di serie temporali in modo più efficiente, ti incoraggio a partecipare alla mia prossima sessione “Cos’è un database di serie temporali e perché ne ho bisogno?” a ODSC West 2023. La sessione includerà un codice di esempio e una dimostrazione, dopodiché sarò felice di rispondere a qualsiasi domanda che tu possa avere sull’argomento.
Riguardo all’autore:
 Jeff Tao è il fondatore e CEO di TDengine. Ha una formazione come tecnologo e imprenditore seriale, avendo precedentemente svolto attività di ricerca e sviluppo su Internet mobile presso Motorola e 3Com e fondato due startup tecnologiche di successo. Prevedendo la crescita esplosiva dei dati di serie temporali generati da macchine e sensori che sta avvenendo ora, ha fondato TDengine nel maggio 2017 per sviluppare un database di serie temporali ad alte prestazioni appositamente progettato per le moderne aziende IoT e IIoT.
Jeff Tao è il fondatore e CEO di TDengine. Ha una formazione come tecnologo e imprenditore seriale, avendo precedentemente svolto attività di ricerca e sviluppo su Internet mobile presso Motorola e 3Com e fondato due startup tecnologiche di successo. Prevedendo la crescita esplosiva dei dati di serie temporali generati da macchine e sensori che sta avvenendo ora, ha fondato TDengine nel maggio 2017 per sviluppare un database di serie temporali ad alte prestazioni appositamente progettato per le moderne aziende IoT e IIoT.