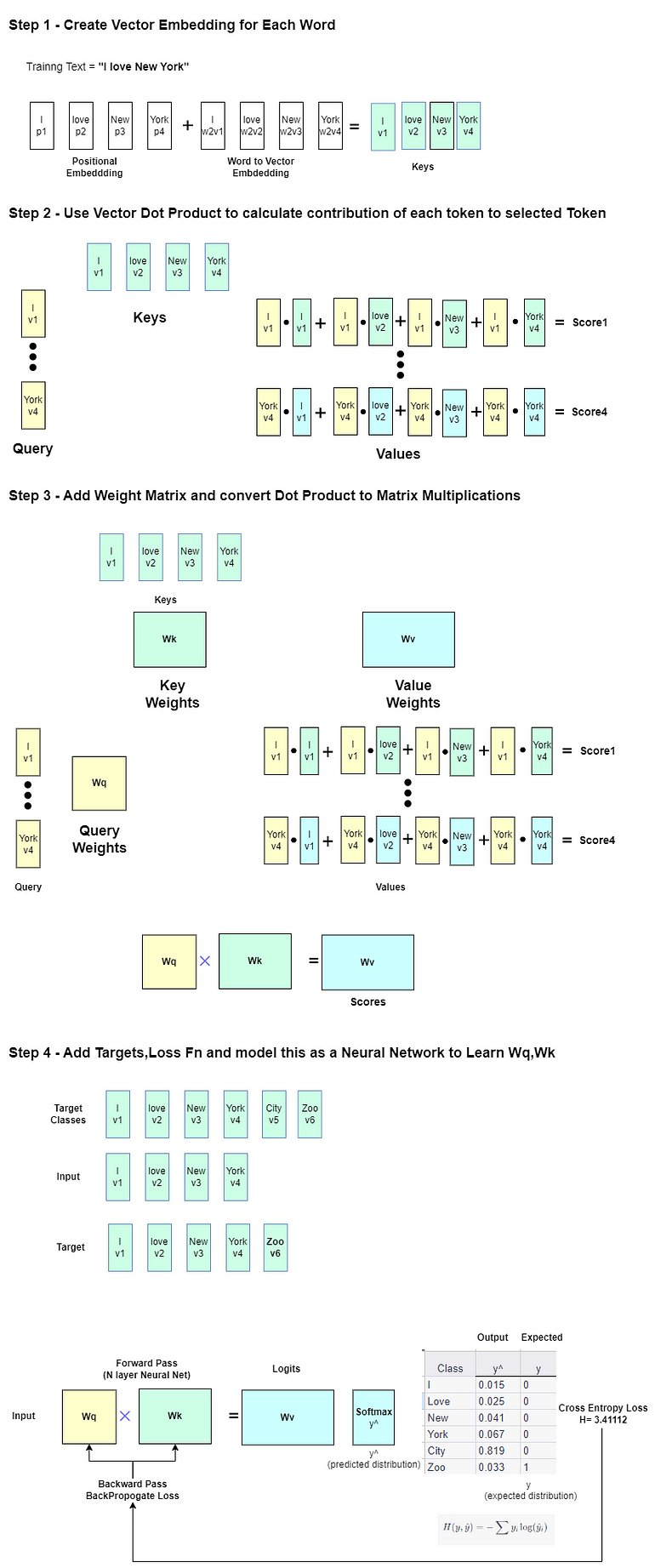
Saturn Un nuovo approccio per l’addestramento di grandi modelli di linguaggio e altre reti neurali
Saturn un nuovo approccio per addestrare grandi modelli di linguaggio e reti neurali.

Nota dell’editore: Kabir Nagrecha è un relatore per ODSC West 2023 quest’autunno. Assicurati di dare un’occhiata al suo intervento, “Democratizzare il fine-tuning dei modelli open-source di grandi dimensioni con l’ottimizzazione congiunta dei sistemi”.
La scala del modello è diventata un aspetto assolutamente essenziale della moderna pratica dell’apprendimento profondo. Il successo dei modelli di linguaggio di grandi dimensioni (LLM) con miliardi di parametri ha incoraggiato i praticanti a spingere i limiti delle dimensioni del modello. I ricercatori e i praticanti stanno ora costruendo architetture di modelli sempre più grandi e avidi di memoria per aumentare l’accuratezza e la qualità del modello.
Ma queste dimensioni introducono sfide infrastrutturali che non possono essere ignorate. Le richieste di risorse per l’addestramento del modello sono esplose. E se c’è una cosa che abbiamo imparato dalle nostre collaborazioni all’UCSD e dai nostri partner industriali, è che i lavori di apprendimento profondo non vengono mai eseguiti in modo isolato. Se stai addestrando un modello, probabilmente stai addestrandone una dozzina: l’ottimizzazione degli iperparametri, i cluster multiutente e l’esplorazione iterativa motivano tutti l’addestramento di modelli multipli, aumentando ulteriormente le richieste di calcolo.
- Costruire un assistente alimentato da ChatGPT e abilitato alla voce utilizzando React e Express
- Stendi le tue ali Falcon 180B è qui
- On-Policy vs. Off-Policy Monte Carlo, con visualizzazioni
In questo post del blog, presenteremo il nostro lavoro su Saturn, il nostro strumento recentemente open-source per addestrare contemporaneamente più modelli di grandi dimensioni. Saturn si integra perfettamente con strumenti standard del settore per l’addestramento di modelli di grandi dimensioni come HuggingFace, FSDP di PyTorch, GPipe di Google, FairScale, XFormers e altri. Dimostreremo come Saturn possa contribuire a ottimizzare l’esecuzione in questo nuovo e critico contesto, riducendo i costi e aumentando l’efficienza dell’addestramento.
Perché addestrare modelli di grandi dimensioni? E perché addestrarne molti?
“Aumentare le dimensioni dei nostri modelli ha sicuramente aumentato la nostra accuratezza. È diventata una regola generale: più grandi sono meglio.” (Utente di Saturn nell’industria)
Studi recenti hanno dimostrato che modelli più grandi tendono a ottenere prestazioni migliori su una varietà di benchmark.
 I modelli di linguaggio sono studenti con poche esempi (Brown et al., 2020)
I modelli di linguaggio sono studenti con poche esempi (Brown et al., 2020)
Quindi, se stai cercando di costruire il modello più accurato per alimentare la tua applicazione, probabilmente utilizzerai un’architettura di modello su larga scala, forse un modello LLaMA, forse GPT-J, forse anche GPT-2.
Sembra evidente che ci sia un’ampia motivazione per addestrare modelli di grandi dimensioni. Ma l’idea centrale di Saturn è ottimizzare contemporaneamente più modelli di grandi dimensioni.
“Probabilmente attraversiamo centinaia… forse migliaia di diverse iterazioni di modelli prima di spingere qualcosa in produzione. E questo processo si ripete quotidianamente per il retraining.” (Utente di Saturn sulle loro pipeline di produzione)
L’apprendimento profondo nella pratica consiste quasi sempre in più lavori di addestramento. I cluster industriali ricevono lavori da centinaia di utenti e pipeline. Le pipeline di produzione automatizzate potrebbero attivare dozzine di lavori di addestramento con diverse configurazioni (ad esempio, tassi di apprendimento, dimensioni dei batch, variazioni dell’architettura del modello) per trovare quello più accurato da implementare. I ricercatori individuali potrebbero inviare più lavori esplorativi per valutare approcci diversi. Alla fine della giornata, un cluster potrebbe aver ricevuto migliaia di lavori da gestire.
C’è un problema irrisolto là fuori, che interseca le sfide dell’addestramento di modelli di grandi dimensioni e dell’esecuzione di modelli multipli, che deve essere risolto. Con Saturn, ottimizziamo esplicitamente per questa configurazione.
Cos’è Saturn? E come posso usarlo?
Quando si affrontano contemporaneamente più modelli di grandi dimensioni, ci sono tre problemi critici da considerare.
Innanzitutto, la parallelizzazione. I modelli di grandi dimensioni di solito hanno bisogno di più GPU per la distribuzione della memoria e una maggiore velocità di addestramento. Progettare lo schema di esecuzione parallela è una sfida – ci sono decine (o addirittura centinaia!) di diverse tecniche! FSDP, parallelismo delle pipeline, parallelismo tridimensionale e altro ancora: la scelta migliore dipenderà dalle tue GPU, dalle interconnessioni, dall’architettura del modello e persino dagli iperparametri. È uno spazio difficile da navigare, ma scegliere l’approccio sbagliato può avere gravi implicazioni sulle prestazioni.
In secondo luogo, la assegnazione delle risorse. Data una cluster con 100 GPU e 30 lavori inviati, come dovrebbero essere distribuite le GPU tra i lavori? Ottimizzare la velocità richiede di trovare automaticamente un piano di distribuzione delle risorse ottimizzato.
In terzo luogo, la pianificazione. In che ordine dovrebbe essere eseguita l’esecuzione per ridurre al minimo i tempi di esecuzione end-to-end? Dovrebbe essere eseguito il Modello A prima del Modello B? O il Modello C prima del Modello A?
Si noti che ciascuno di questi problemi è collegato. Il piano di assegnazione delle risorse che si utilizza limiterà la pianificazione e influenzerà anche le selezioni di parallelismo ottimale, e viceversa. Quindi dobbiamo risolvere questo come un problema congiunto.
Ecco esattamente quello che fa Saturn. Con Saturn, puoi semplicemente inviare un batch di lavori di formazione e osservare come viene generato automaticamente un piano che risolve tutti questi problemi. Saturn esegue una scansione di profilazione rapida su tutti i tuoi lavori, quindi utilizza un risolutore di programmazione lineare a interi misti per produrre un piano ottimizzato per l’esecuzione. È facile estendere e registrare nuove tecniche di parallelizzazione, quindi non c’è rischio di rimanere indietro mentre la ricerca progredisce. In combinazione con alcuni meccanismi come l’introspezione per una pianificazione efficiente, è in grado di ridurre in modo significativo i tempi di esecuzione dei lavori multi-modello batch. Troviamo che nella pratica è in grado di ridurre i tempi di esecuzione e i costi fino a 2X rispetto alla pratica attuale, riducendo allo stesso tempo il carico di lavoro degli sviluppatori.
Utilizzare Saturn per eseguire i lavori in modo più efficiente è un processo semplice. Il nostro repository GitHub contiene un esempio di workflow, ma ecco una breve panoramica.
Innanzitutto, incapsula la funzione di caricamento/inizializzazione del modello nella costruzione “Task” di Saturn.
from saturn import Task
t1 = Task(load_model, load_dataloader, loss_function, hyperparameters)Successivamente, registra le tecniche di parallelizzazione che desideri utilizzare con la “Library” di Saturn.
from saturn.library import register
from saturn.core.executors.Technique import BaseTechnique
class MyExecutor(BaseTechnique):
def execute(task, gpus, task_id, batch_count):
# addestra il modello
return
def search(task, gpus, task_id):
# ottimizza i parametri interni
# questi vengono associati automaticamente al compito inviato
return parameters
register("my_parallelism", MyExecutor)Infine, invia un elenco di compiti per la profilazione e l’esecuzione.
from saturn.trial_runner.PerformanceEvaluator import search
from saturn import orchestrate
search([t1, t2, t3, t4]) # profila ed valuta ogni compito
orchestrate([t1, t2, t3, t4]) # coordina e gestisce l'esecuzioneConclusione e Considerazioni
Saturn consente accelerazioni significative di >2X per carichi di lavoro che addestrano contemporaneamente più modelli di grandi dimensioni. È perfettamente compatibile con strumenti standard come HuggingFace. La prossima volta che cerchi di ottimizzare un modello LLaMA o creare il tuo LLM, considera l’utilizzo di Saturn per ridurre i costi e accelerare i tempi di esecuzione! Se sei interessato a saperne di più, puoi trovare il nostro articolo su Saturn qui.
Attualmente stiamo cercando nuovi contributori e utenti da integrare, quindi se sei interessato a Saturn, dai un’occhiata al nostro repository open-source su GitHub all’indirizzo https://github.com/knagrecha/saturn!
Informazioni sull’autore/Relatore ODSC West 2023:
 Kabir Nagrecha è un candidato al dottorato presso UC San Diego, lavorando con i professori Arun Kumar e Hao Zhang. È il destinatario della Meta Research Fellowship, nonché delle borse di studio dell’Istituto di Data Science Halicioglu e della Jacobs School of Engineering presso UCSD.
Kabir Nagrecha è un candidato al dottorato presso UC San Diego, lavorando con i professori Arun Kumar e Hao Zhang. È il destinatario della Meta Research Fellowship, nonché delle borse di studio dell’Istituto di Data Science Halicioglu e della Jacobs School of Engineering presso UCSD.
Kabir è il più giovane studente di dottorato di UCSD, avendo iniziato il suo dottorato all’età di 17 anni. Ha lavorato in precedenza con aziende come Apple, Meta e Netflix per costruire l’infrastruttura di base che supporta servizi ampiamente utilizzati come Siri e gli algoritmi di raccomandazione di Netflix.
Linkedin: https://www.linkedin.com/in/kabir-nagrecha-952591152/
Sito web: https://kabirnagrecha.com/