Apprendimento automatico con dati di addestramento decentralizzati utilizzando l’apprendimento federato su Amazon SageMaker
Apprendimento federato su Amazon SageMaker con dati decentralizzati
Il machine learning (ML) sta rivoluzionando le soluzioni in tutti i settori e sta generando nuove forme di insight e intelligenza dai dati. Molti algoritmi di ML vengono addestrati su grandi dataset, generalizzando i pattern che trova nei dati e inferendo risultati da quei pattern quando vengono elaborati nuovi record non visti in precedenza. Di solito, se il dataset o il modello è troppo grande per essere addestrato su un’unica istanza, il training distribuito consente l’utilizzo di più istanze all’interno di un cluster e la distribuzione di partizioni di dati o modelli su quelle istanze durante il processo di training. Il supporto nativo per il training distribuito viene offerto tramite l’SDK Amazon SageMaker, insieme a notebook di esempio in framework popolari.
Tuttavia, a volte a causa di regolamentazioni di sicurezza e privacy all’interno o tra le organizzazioni, i dati sono decentralizzati su più account o in diverse regioni e non possono essere centralizzati in un unico account o tra le regioni. In questo caso, dovrebbe essere preso in considerazione il federated learning (FL) per ottenere un modello generalizzato sull’intero dataset.
In questo post, discutiamo come implementare il federated learning su Amazon SageMaker per eseguire il machine learning con dati di training decentralizzati.
Cos’è il federated learning?
Il federated learning è un approccio di ML che consente a più sessioni di training separate eseguite in parallelo di attraversare grandi confini, ad esempio geografici, e aggregare i risultati per creare un modello generalizzato (modello globale) durante il processo. Più specificamente, ogni sessione di training utilizza il proprio dataset e ottiene il proprio modello locale. I modelli locali delle diverse sessioni di training vengono aggregati (ad esempio, aggregazione dei pesi del modello) in un modello globale durante il processo di training. Questo approccio è in contrasto con le tecniche di ML centralizzate in cui i dataset vengono uniti per una singola sessione di training.
- Presentando SafeCoder
- Apprendimento continuo al margine
- Scienziati ricreano una canzone dei Pink Floyd leggendo i segnali cerebrali degli ascoltatori
Federated learning vs training distribuito sul cloud
Quando questi due approcci vengono eseguiti sul cloud, il training distribuito avviene in una singola regione su un singolo account e i dati di training iniziano con una sessione di training o un job centralizzato. Durante il processo di training distribuito, il dataset viene suddiviso in sottoinsiemi più piccoli e, a seconda della strategia (parallelismo di dati o parallelismo di modelli), i sottoinsiemi vengono inviati a diversi nodi di training o passano attraverso nodi in un cluster di training, il che significa che i dati individuali non rimangono necessariamente in un solo nodo del cluster.
Al contrario, con il federated learning, il training di solito avviene su più account separati o su diverse regioni. Ogni account o regione ha le proprie istanze di training. I dati di training sono decentralizzati tra account o regioni dall’inizio alla fine e i dati individuali vengono letti solo dalla rispettiva sessione di training o job tra account o regioni diverse durante il processo di federated learning.
Framework di federated learning Flower
Sono disponibili diversi framework open-source per il federated learning, come FATE, Flower, PySyft, OpenFL, FedML, NVFlare e Tensorflow Federated. Quando si sceglie un framework FL, si tiene di solito conto del supporto per la categoria di modello, il framework di ML e il dispositivo o il sistema operativo. È anche necessario considerare l’estensibilità e la dimensione del pacchetto del framework FL per eseguirlo in modo efficiente sul cloud. In questo post, scegliamo un framework facilmente estensibile, personalizzabile e leggero, Flower, per implementare il FL utilizzando SageMaker.
Flower è un framework FL completo che si distingue dagli altri framework esistenti offrendo nuove funzionalità per eseguire esperimenti FL su larga scala e consente scenari di dispositivi FL eterogenei. FL risolve sfide legate alla privacy dei dati e alla scalabilità in scenari in cui non è possibile condividere i dati.
Principi di progettazione e implementazione di Flower FL
Flower FL è indipendente dal linguaggio e dal framework di ML per design, è completamente estensibile e può incorporare algoritmi, strategie di training e protocolli di comunicazione emergenti. Flower è open source con licenza Apache 2.0.
L’architettura concettuale dell’implementazione di FL è descritta nel paper “Flower: A friendly Federated Learning Framework” e viene evidenziata nella figura seguente.
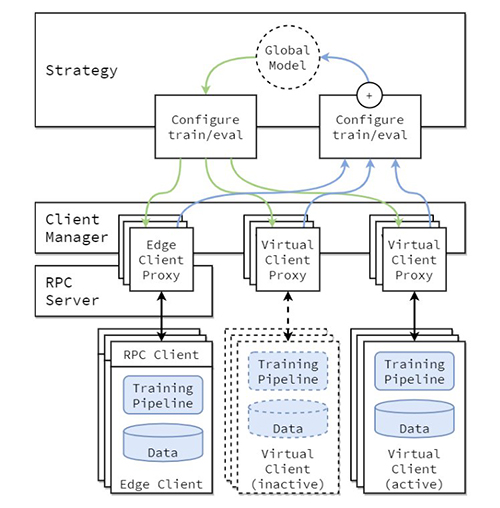
In questa architettura, i client edge risiedono su dispositivi edge reali e comunicano con il server tramite RPC. I client virtuali, d’altra parte, consumano quasi zero risorse quando sono inattivi e caricano solo il modello e i dati in memoria quando il client viene selezionato per il training o la valutazione.
Il server Flower costruisce la strategia e le configurazioni da inviare ai client Flower. Serializza questi dizionari di configurazione (o config dict) nella loro rappresentazione ProtoBuf, li trasporta al client utilizzando gRPC e poi li deserializza in dizionari Python.
Strategie Flower FL
Flower consente la personalizzazione del processo di apprendimento attraverso l’astrazione della strategia. La strategia definisce l’intero processo di federazione specificando l’inizializzazione dei parametri (se inizializzati dal server o dal client), il numero minimo di client disponibili necessari per inizializzare una esecuzione, il peso dei contributi del client e i dettagli di allenamento e valutazione.
Flower ha un’implementazione estesa degli algoritmi di averaging FL e uno stack di comunicazione robusto. Per un elenco degli algoritmi di averaging implementati e dei relativi articoli di ricerca associati, fare riferimento alla seguente tabella, tratta da Flower: un framework friendly per il Federated Learning.

Apprendimento federato con SageMaker: Architettura della soluzione
Un’architettura di apprendimento federato che utilizza SageMaker con il framework Flower è implementata su flussi gRPC bidirezionali (foundation). gRPC definisce i tipi di messaggi scambiati e utilizza compilatori per generare un’implementazione efficiente per Python, ma può anche generare l’implementazione per altri linguaggi, come Java o C++.
I client Flower ricevono istruzioni (messaggi) come array di byte grezzi tramite la rete. Quindi i client deserializzano ed eseguono l’istruzione (addestramento sui dati locali). I risultati (parametri e pesi del modello) vengono quindi serializzati e comunicati al server.
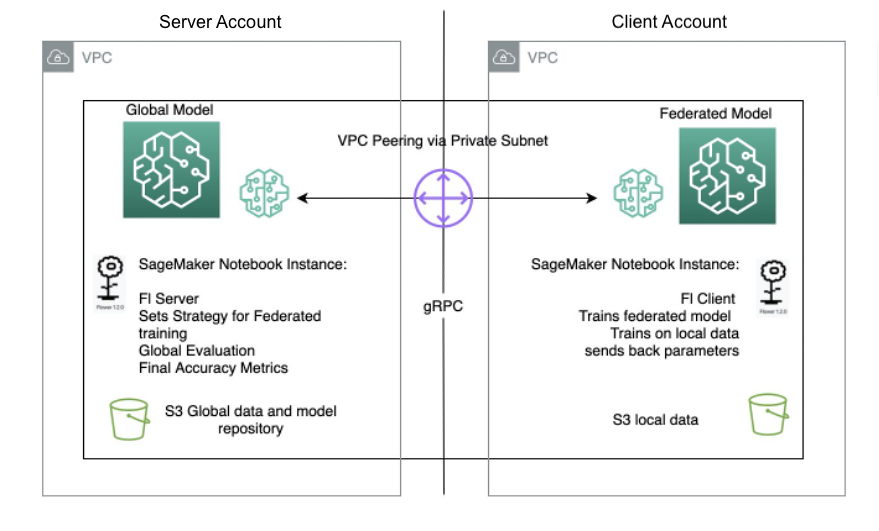
L’architettura server/client per Flower FL è definita in SageMaker utilizzando istanze di notebook in diversi account nella stessa regione del server Flower e del client Flower. Le strategie di addestramento e valutazione sono definite anche sul server, così come i parametri globali, quindi la configurazione viene serializzata e inviata al client tramite peering VPC.
L’istanza del client del notebook avvia un lavoro di addestramento SageMaker che esegue uno script personalizzato per avviare l’istanziazione del client Flower, che deserializza e legge la configurazione del server, avvia il lavoro di addestramento e invia la risposta dei parametri.
L’ultimo passaggio avviene sul server quando viene attivata la valutazione dei parametri aggregati appena completato il numero di esecuzioni e client specificato nella strategia del server. La valutazione avviene su un set di dati di test esistente solo sul server e vengono prodotte nuove metriche di accuratezza migliorate.
Il seguente diagramma illustra l’architettura della configurazione FL su SageMaker con il pacchetto Flower.
Implementare l’apprendimento federato utilizzando SageMaker
SageMaker è un servizio di ML completamente gestito. Con SageMaker, gli scienziati dei dati e gli sviluppatori possono creare e addestrare rapidamente modelli di ML, per poi distribuirli in un ambiente ospitato pronto per la produzione.
In questo post, mostriamo come utilizzare la piattaforma ML gestita per fornire un ambiente di esperienza notebook e eseguire l’apprendimento federato tra account AWS, utilizzando i lavori di addestramento SageMaker. I dati di addestramento grezzi non lasciano mai l’account che possiede i dati e solo i pesi derivati vengono inviati tramite la connessione peered.
Evidenziamo i seguenti componenti principali in questo post:
- Networking – SageMaker consente di configurare rapidamente la configurazione predefinita della rete, consentendo anche la personalizzazione completa della rete in base alle esigenze dell’organizzazione. Utilizziamo una configurazione di peering VPC all’interno della regione in questo esempio.
- Impostazioni di accesso tra account – Per consentire a un utente nell’account server di avviare un lavoro di addestramento del modello nell’account client, deleghiamo l’accesso tra account utilizzando i ruoli IAM (Identity and Access Management) di AWS. In questo modo, un utente nell’account server non deve uscire dall’account e accedere all’account client per eseguire azioni su SageMaker. Questa impostazione è solo per scopi di avvio di lavori di addestramento SageMaker e non ha alcun permesso di accesso o condivisione dei dati tra account.
- Implementazione del codice client di apprendimento federato nell’account client e del codice server nell’account server – Implementiamo il codice client di apprendimento federato nell’account client utilizzando il pacchetto Flower e l’addestramento gestito di SageMaker. Nel frattempo, implementiamo il codice server nell’account server utilizzando il pacchetto Flower.
Configurazione del peering VPC
Una connessione di peering VPC è una connessione di rete tra due VPC che consente di instradare il traffico tra di loro utilizzando indirizzi IPv4 privati o indirizzi IPv6. Le istanze in entrambe le VPC possono comunicare tra loro come se fossero nella stessa rete.
Per configurare una connessione di peering VPC, prima crea una richiesta di collegamento con un’altra VPC. Puoi richiedere una connessione di peering VPC con un’altra VPC nello stesso account o, nel nostro caso d’uso, connetterti a una VPC in un diverso account AWS. Per attivare la richiesta, il proprietario della VPC deve accettare la richiesta. Per ulteriori dettagli sulla connessione di peering VPC, consulta la creazione di una connessione di peering VPC.
Lanciare istanze notebook SageMaker in VPC
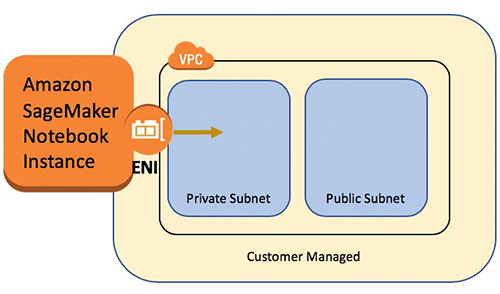
Un’istanza di notebook SageMaker fornisce un’applicazione notebook Jupyter tramite un’istanza Amazon Elastic Compute Cloud (Amazon EC2) di ML gestita completamente. I notebook Jupyter di SageMaker vengono utilizzati per eseguire l’esplorazione avanzata dei dati, creare lavori di formazione, distribuire modelli a SageMaker hosting e testare o convalidare i modelli.
L’istanza del notebook ha diverse configurazioni di rete disponibili. In questa configurazione, l’istanza del notebook viene eseguita all’interno di una subnet privata della VPC e non ha accesso diretto a Internet.
Configurare le impostazioni di accesso tra account
Le impostazioni di accesso tra account includono due passaggi per delegare l’accesso dall’account server all’account client utilizzando ruoli IAM:
- Crea un ruolo IAM nell’account client.
- Concedi accesso al ruolo nell’account server.
Per i passaggi dettagliati per configurare uno scenario simile, consulta la delega di accesso tra account AWS utilizzando ruoli IAM.
Nell’account client, creiamo un ruolo IAM chiamato FL-kickoff-client-job con la policy FL-sagemaker-actions allegata al ruolo. La policy FL-sagemaker-actions ha il seguente contenuto JSON:
{
"Version": "2012-10-17",
"Statement": [
{
"Effect": "Allow",
"Action": [
"sagemaker:CreateTrainingJob",
"sagemaker:DescribeTrainingJob",
"sagemaker:StopTrainingJob",
"sagemaker:UpdateTrainingJob"
],
"Resource": "*"
},
{
"Effect": "Allow",
"Action": [
"ec2:DescribeSubnets",
"ec2:DescribeVpcs",
"ec2:DescribeNetworkInterfaces"
],
"Resource": "*"
},
{
"Effect": "Allow",
"Action": [
"iam:GetRole",
"iam:PassRole"
],
"Resource": "arn:aws:iam::<client-account-number>:role/service-role/AmazonSageMaker-ExecutionRole-<xxxxxxxxxxxxxxx>"
}
]
}Successivamente, modifichiamo la policy di trust nelle relazioni di trust del ruolo FL-kickoff-client-job:
{
"Version": "2012-10-17",
"Statement": [
{
"Effect": "Allow",
"Principal": {
"AWS": "arn:aws:iam::<server-account-number>:root"
},
"Action": "sts:AssumeRole",
"Condition": {}
}
]
}Nell’account server, vengono aggiunti i permessi a un utente esistente (ad esempio, developer) per consentire il passaggio al ruolo FL-kickoff-client-job nell’account client. Per fare ciò, creiamo una policy inline chiamata FL-allow-kickoff-client-job e la allegiamo all’utente. Di seguito è riportato il contenuto JSON della policy:
{
"Version": "2012-10-17",
"Statement": {
"Effect": "Allow",
"Action": "sts:AssumeRole",
"Resource": "arn:aws:iam::<client-account-number>:role/FL-kickoff-client-job"
}
}Campione di dati e preparazione dei dati
In questo post, utilizziamo un dataset selezionato per il rilevamento delle frodi nei dati dei fornitori Medicare rilasciati dai Centers for Medicare & Medicaid Services (CMS). I dati vengono divisi in un dataset di addestramento e un dataset di test. Poiché la maggior parte dei dati non rappresenta frodi, applichiamo SMOTE per bilanciare il dataset di addestramento e, successivamente, dividiamo ulteriormente il dataset di addestramento in parti di addestramento e di convalida. I dati di addestramento e di convalida vengono caricati in un bucket di Amazon Simple Storage Service (Amazon S3) per l’addestramento del modello nell’account del cliente, mentre il dataset di test viene utilizzato solo nell’account del server a scopo di test. I dettagli del codice di preparazione dei dati si trovano nel notebook seguente.
Utilizzando le immagini Docker predefinite di SageMaker per il framework scikit-learn e il processo di addestramento gestito da SageMaker, addestriamo un modello di regressione logistica su questo dataset utilizzando l’apprendimento federato.
Implementare un client di apprendimento federato nell’account del cliente
Nell’istanza del notebook SageMaker dell’account del cliente, prepariamo uno script client.py e uno script utils.py. Il file client.py contiene il codice per il client, mentre il file utils.py contiene il codice per alcune delle funzioni di utilità necessarie per il nostro addestramento. Utilizziamo il pacchetto scikit-learn per costruire il modello di regressione logistica.
In client.py, definiamo un client Flower. Il client deriva dalla classe fl.client.NumPyClient. Deve definire i seguenti tre metodi:
- get_parameters – Restituisce i parametri attuali del modello locale. La funzione di utilità
get_model_parametersfarà questo. - fit – Definisce i passaggi per addestrare il modello sui dati di addestramento nell’account del client. Riceve anche i parametri del modello globale e altre informazioni di configurazione dal server. Aggiorniamo i parametri del modello locale utilizzando i parametri globali ricevuti e continuiamo ad addestrarlo sul dataset nell’account del client. Questo metodo invia anche i parametri del modello locale dopo l’addestramento, la dimensione del set di addestramento e un dizionario per comunicare valori arbitrari al server.
- evaluate – Valuta i parametri forniti utilizzando i dati di convalida nell’account del client. Restituisce la perdita insieme ad altri dettagli come la dimensione del set di convalida e l’accuratezza al server.
Ecco un frammento di codice per la definizione del client Flower:
"""Interfaccia del client"""
class FlowerClient(fl.client.NumPyClient):
def get_parameters(self, config):
return utils.get_model_parameters(model)
def fit(self, parameters, config):
utils.set_model_params(model, parameters)
with warnings.catch_warnings():
warnings.simplefilter("ignore")
model.fit(X_train, y_train)
return utils.get_model_parameters(model), len(X_train), {}
def evaluate(self, parameters, config):
utils.set_model_params(model, parameters)
loss = log_loss(y_test, model.predict_proba(X_test))
accuracy = model.score(X_test, y_test)
return loss, len(X_test), {"accuracy": accuracy}Successivamente utilizziamo la modalità script di SageMaker per preparare il resto del file client.py. Ciò include la definizione dei parametri che verranno passati all’addestramento di SageMaker, il caricamento dei dati di addestramento e convalida, l’inizializzazione e l’addestramento del modello sul client, la configurazione del client Flower per comunicare con il server e infine il salvataggio del modello addestrato.
utils.py include alcune funzioni di utilità che vengono chiamate in client.py:
- get_model_parameters – Restituisce i parametri del modello di regressione logistica di scikit-learn.
- set_model_params – Imposta i parametri del modello.
- set_initial_params – Inizializza i parametri del modello a zero. Questo è necessario perché il server richiede i parametri del modello iniziali dal client al momento del lancio. Tuttavia, nel framework scikit-learn, i parametri del modello di
LogisticRegressionnon vengono inizializzati fino a quando non viene chiamatomodel.fit(). - load_data – Carica i dati di addestramento e di test.
- save_model – Salva il modello come file
.joblib.
Poiché Flower non è un pacchetto installato nel container Docker predefinito di SageMaker per scikit-learn, elenchiamo flwr==1.3.0 in un file requirements.txt.
Abbiamo messo tutti e tre i file (client.py, utils.py e requirements.txt) in una cartella e li abbiamo compressi in formato tar zip. Il file .tar.gz (chiamato source.tar.gz in questo post) viene quindi caricato in un bucket S3 nell’account del client.
Implementare un server di apprendimento federato nell’account del server
Nell’account del server, prepariamo il codice su un notebook Jupyter. Questo include due parti: il server assume prima un ruolo per avviare un lavoro di addestramento nell’account del client, quindi il server federisce il modello utilizzando Flower.
Assumere un ruolo per eseguire il lavoro di addestramento nell’account del client
Utilizziamo la libreria Boto3 Python SDK per configurare un client AWS Security Token Service (AWS STS) per assumere il ruolo FL-kickoff-client-job e configurare un client SageMaker per eseguire un lavoro di addestramento nell’account del client utilizzando il processo di addestramento gestito da SageMaker:
sts_client = boto3.client('sts')
assumed_role_object = sts_client.assume_role(
RoleArn = "arn:aws:iam::<numero-account-client>:role/FL-kickoff-client-job",
RoleSessionName = "AssumeRoleSession1"
)
credentials = assumed_role_object['Credentials']
sagemaker_client = boto3.client(
'sagemaker',
aws_access_key_id = credentials['AccessKeyId'],
aws_secret_access_key = credentials['SecretAccessKey'],
aws_session_token = credentials['SessionToken'],
)Utilizzando il ruolo assunto, creiamo un lavoro di addestramento SageMaker nell’account del client. Il lavoro di addestramento utilizza il framework scikit-learn integrato in SageMaker. Nota che tutti i bucket S3 e il ruolo IAM di SageMaker nel seguente frammento di codice sono correlati all’account del client:
sagemaker_client.create_training_job(
TrainingJobName = training_job_name,
HyperParameters = {
"penalty": "l2",
"max-iter": "10",
"server-address":"<indirizzo-ip-server>:8080",
"sagemaker_program": "client.py",
"sagemaker_submit_directory": "s3://<bucket-codice-client-account-s3>/client_code/source.tar.gz",
},
AlgorithmSpecification = {
"TrainingImage": training_image,
"TrainingInputMode": "File",
},
RoleArn = "arn:aws:iam::<numero-account-client>:role/service-role/AmazonSageMaker-ExecutionRole-<xxxxxxxxxxxxxxx>",
InputDataConfig=[
{
"ChannelName": "train",
"DataSource": {
"S3DataSource": {
"S3DataType": "S3Prefix",
"S3Uri": "s3://<bucket-dati-client-account-s3>/data_prep/",
"S3DataDistributionType": "FullyReplicated",
}
},
},
],
OutputDataConfig = {
"S3OutputPath": "s3://<bucket-client-account-s3-per-artefatti-modello>/client_artifact/"
},
ResourceConfig = {
"InstanceType": "ml.m5.xlarge",
"InstanceCount": 1,
"VolumeSizeInGB": 10,
},
VpcConfig={
'SecurityGroupIds': [
"<gruppo-di-sicurezza-istanza-notebook-account-client>",
],
'Subnets': [
"<sottorete-istanza-notebook-account-client>",
]
},
StoppingCondition = {
"MaxRuntimeInSeconds": 86400
},
)Aggregare modelli locali in un modello globale utilizzando Flower
Prepariamo il codice per federare il modello sul server. Questo include la definizione della strategia per la federazione e i suoi parametri di inizializzazione. Utilizziamo le funzioni di utilità nello script utils.py descritto in precedenza per inizializzare e impostare i parametri del modello. Flower consente di definire le proprie funzioni di callback per personalizzare una strategia esistente. Utilizziamo la strategia FedAvg con callback personalizzate per la valutazione e la configurazione dell’adattamento. Ecco il codice seguente:
"""Inizializza il modello e la strategia di federazione, quindi avvia il server"""
model = LogisticRegression()
utils.set_initial_params(model)
strategy = fl.server.strategy.FedAvg(
min_available_clients = 1, # Numero minimo di client che devono essere connessi al server prima che possa iniziare un round di addestramento
min_fit_clients = 1, # Numero minimo di client da campionare per il prossimo round
min_evaluate_clients = 1,
evaluate_fn = get_evaluate_fn(model, X_test, y_test),
on_fit_config_fn = fit_round,
)
fl.server.start_server(
server_address = args.server_address,
strategy = strategy,
config = fl.server.ServerConfig(num_rounds=3) # esegui per 3 round
)
utils.save_model(args.model_dir, model)Le seguenti due funzioni vengono menzionate nel frammento di codice precedente:
- fit_round – Viene utilizzata per inviare il numero di round al client. Passiamo questa callback come parametro
on_fit_config_fndella strategia. Facciamo questo semplicemente per dimostrare l’uso del parametroon_fit_config_fn. - get_evaluate_fn – Viene utilizzata per la valutazione del modello sul server.
A scopo dimostrativo, utilizziamo il dataset di testing che abbiamo separato nella preparazione dei dati per valutare il modello federato dall’account del client e comunicare il risultato al client. Tuttavia, è importante notare che in quasi tutti i casi d’uso reali, i dati utilizzati nell’account del server non sono separati dal dataset utilizzato nell’account del client.
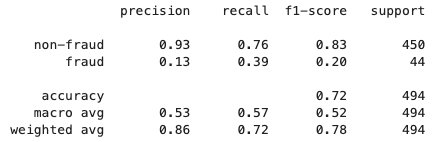
Dopo che il processo di federated learning è terminato, un file model.tar.gz viene salvato da SageMaker come artifact del modello in un bucket S3 nell’account del client. Nel frattempo, un file model.joblib viene salvato nell’istanza del notebook SageMaker nell’account del server. Infine, utilizziamo il dataset di testing per testare il modello finale (model.joblib) sul server. L’output di testing del modello finale è il seguente:
Pulizia
Dopo aver terminato, pulire le risorse sia nell’account del server che nell’account del client per evitare costi aggiuntivi:
- Arrestare le istanze del notebook SageMaker.
- Eliminare le connessioni di peering VPC e le VPC corrispondenti.
- Svuotare ed eliminare il bucket S3 creato per lo storage dei dati.
Conclusioni
In questo post, abbiamo illustrato come implementare il federated learning su SageMaker utilizzando il pacchetto Flower. Abbiamo mostrato come configurare il peering VPC, impostare l’accesso tra account e implementare il client e il server FL. Questo post è utile per coloro che hanno bisogno di addestrare modelli di ML su SageMaker utilizzando dati decentralizzati tra account con restrizioni sulla condivisione dei dati. Poiché il FL in questo post è implementato utilizzando SageMaker, è importante notare che molte altre funzionalità di SageMaker possono essere incorporate nel processo.
L’implementazione del federated learning su SageMaker può sfruttare tutte le funzionalità avanzate che SageMaker offre durante il ciclo di vita di ML. Ci sono altri modi per raggiungere o applicare il federated learning su AWS Cloud, come l’utilizzo di istanze EC2 o sull’edge. Per ulteriori dettagli su queste alternative, fare riferimento a Federated Learning on AWS with FedML e Applying Federated Learning for ML at the Edge.






