AdaTape Modello fondamentale con calcolo adattivo e lettura e scrittura dinamiche
AdaTape Modello con calcolo adattivo e accesso dinamico ai dati
Pubblicato da Fuzhao Xue, Stagista di Ricerca, e Mostafa Dehghani, Scienziato di Ricerca, Google
La computazione adattiva si riferisce alla capacità di un sistema di apprendimento automatico di regolare il suo comportamento in risposta ai cambiamenti dell’ambiente. Mentre le reti neurali convenzionali hanno una funzione fissa e una capacità di calcolo, ovvero impiegano lo stesso numero di FLOP (operazioni in virgola mobile) per elaborare input diversi, un modello con calcolo adattivo e dinamico modula il budget computazionale che dedica all’elaborazione di ciascun input, in base alla complessità dell’input stesso.
La computazione adattiva nelle reti neurali è interessante per due ragioni principali. In primo luogo, il meccanismo che introduce l’adattività fornisce un bias induttivo che può svolgere un ruolo chiave nella risoluzione di alcune sfide. Ad esempio, abilitare diversi numeri di passaggi computazionali per diversi input può essere cruciale nella risoluzione di problemi aritmetici che richiedono la modellazione di gerarchie di diverse profondità. In secondo luogo, dà ai professionisti la possibilità di regolare il costo dell’inferenza attraverso una maggiore flessibilità offerta dalla computazione dinamica, poiché questi modelli possono essere adattati per impiegare più FLOP nell’elaborazione di un nuovo input.
Le reti neurali possono diventare adattive utilizzando diverse funzioni o budget computazionali per vari input. Una rete neurale profonda può essere considerata come una funzione che restituisce un risultato basato sia sull’input che sui suoi parametri. Per implementare tipi di funzioni adattive, un sottoinsieme di parametri viene attivato selettivamente in base all’input, un processo chiamato computazione condizionale. L’adattività basata sul tipo di funzione è stata esplorata in studi su mixture-of-experts, dove i parametri attivati in modo sparsificato per ciascun campione di input vengono determinati tramite il routing.
- Rivelato attacco informatico ai registri elettorali del Regno Unito
- La città più tecnologicamente avanzata degli Stati Uniti ha dubbi sulle auto a guida autonoma.
- La Cina stila regole per la tecnologia di riconoscimento facciale
Un’altra area di ricerca nella computazione adattiva coinvolge i budget di calcolo dinamici. A differenza delle reti neurali standard, come T5, GPT-3, PaLM e ViT, il cui budget di calcolo è fisso per diversi campioni, recenti ricerche hanno dimostrato che i budget di calcolo adattivi possono migliorare le prestazioni su compiti in cui i trasformatori sono carenti. Molti di questi lavori raggiungono l’adattività utilizzando la profondità dinamica per allocare il budget di calcolo. Ad esempio, l’algoritmo Adaptive Computation Time (ACT) è stato proposto per fornire un budget computazionale adattivo per le reti neurali ricorrenti. Il Universal Transformer estende l’algoritmo ACT ai trasformatori, rendendo il budget di calcolo dipendente dal numero di livelli del trasformatore utilizzati per ciascun esempio di input o token. Studi recenti, come PonderNet, seguono un approccio simile migliorando i meccanismi di arresto dinamici.
Nel paper “Adaptive Computation with Elastic Input Sequence”, introduciamo un nuovo modello che utilizza la computazione adattiva, chiamato AdaTape. Questo modello è un’architettura basata su trasformatori che utilizza un insieme dinamico di token per creare sequenze di input elastiche, offrendo una prospettiva unica sull’adattività rispetto ai lavori precedenti. AdaTape utilizza un meccanismo di lettura adattiva del nastro per determinare un numero variabile di token del nastro che vengono aggiunti a ciascun input in base alla complessità dell’input. AdaTape è molto semplice da implementare, fornisce una manopola efficace per aumentare l’accuratezza quando necessario, ma è anche molto più efficiente rispetto ad altre basi adattive perché inietta direttamente l’adattività nella sequenza di input anziché nella profondità del modello. Infine, AdaTape offre prestazioni migliori su compiti standard, come la classificazione delle immagini, così come su compiti algoritmici, mantenendo un vantaggioso rapporto qualità-prezzo.
Trasformatore di computazione adattiva con sequenza di input elastica
AdaTape utilizza sia tipi di funzioni adattive che un budget di calcolo dinamico. In particolare, per un batch di sequenze di input dopo la tokenizzazione (ad esempio, una proiezione lineare di patch non sovrapposte da un’immagine nel trasformatore di visione), AdaTape utilizza un vettore che rappresenta ciascun input per selezionare dinamicamente una sequenza di token del nastro di dimensione variabile.
AdaTape utilizza una banca di token, chiamata “banca del nastro”, per memorizzare tutti i token del nastro candidati che interagiscono con il modello attraverso il meccanismo di lettura adattiva del nastro. Esploriamo due diversi metodi per creare la banca del nastro: una banca guidata dall’input e una banca apprendibile.
L’idea generale della banca guidata dall’input è estrarre una banca di token dall’input utilizzando un approccio diverso dal tokenizzatore originale del modello per mappare l’input grezzo in una sequenza di token di input. Questo consente un accesso dinamico, su richiesta, alle informazioni dall’input che vengono ottenute utilizzando un punto di vista diverso, ad esempio una diversa risoluzione dell’immagine o un diverso livello di astrazione.
In alcuni casi, la tokenizzazione a un diverso livello di astrazione non è possibile, quindi una banca del nastro guidata dall’input non è fattibile, ad esempio quando è difficile suddividere ulteriormente ciascun nodo in un trasformatore di grafo. Per affrontare questo problema, AdaTape offre un approccio più generale per generare la banca del nastro utilizzando un insieme di vettori apprendibili come token del nastro. Questo approccio viene chiamato banca apprendibile e può essere considerato come uno strato di embedding in cui il modello può recuperare dinamicamente i token in base alla complessità dell’esempio di input. La banca apprendibile consente ad AdaTape di generare una banca del nastro più flessibile, fornendogli la capacità di regolare dinamicamente il suo budget di calcolo in base alla complessità di ciascun esempio di input, ad esempio gli esempi più complessi recuperano più token dalla banca, consentendo al modello non solo di utilizzare le conoscenze memorizzate nella banca, ma anche di impiegare più FLOP nell’elaborazione, poiché l’input è ora più grande.
Infine, i token del nastro selezionati vengono aggiunti all’input originale e forniti ai seguenti strati del transformer. Per ogni strato del transformer, viene utilizzata la stessa attenzione multi-head su tutti i token di input e del nastro. Tuttavia, vengono utilizzate due diverse reti feed-forward (FFN): una per tutti i token dell’input originale e un’altra per tutti i token del nastro. Abbiamo osservato una qualità leggermente migliore utilizzando reti feed-forward separate per i token di input e del nastro.
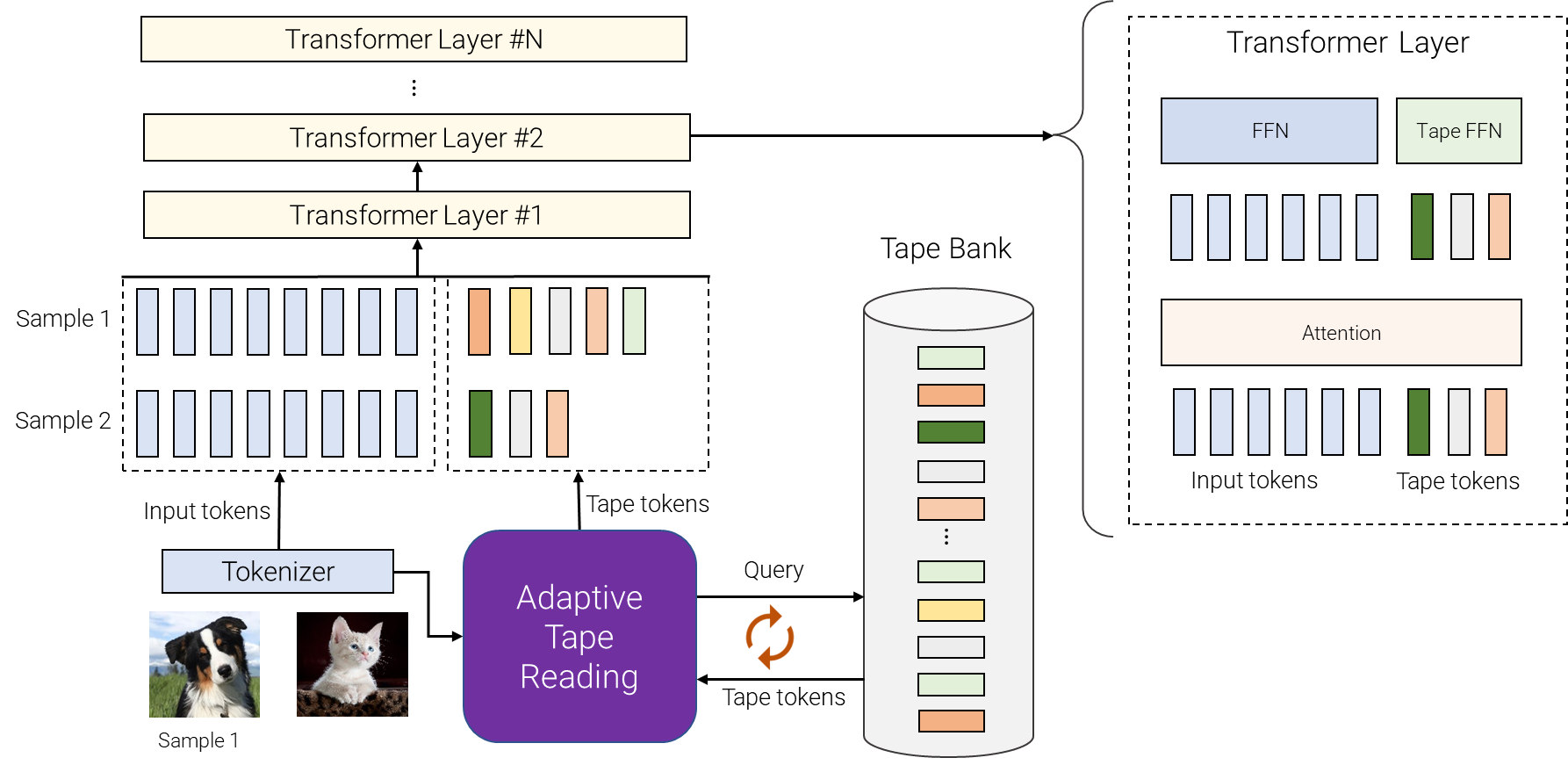 |
| Una panoramica di AdaTape. Per diverse campioni, selezioniamo un numero variabile di token diversi dalla banca dati del nastro. La banca dati del nastro può essere guidata dall’input, ad esempio, estrarrendo alcune informazioni extra a grana fine o può essere un insieme di vettori addestrabili. La lettura adattiva del nastro viene utilizzata per selezionare in modo ricorsivo diverse sequenze di token del nastro, con lunghezze variabili, per diversi input. Questi token vengono quindi semplicemente aggiunti agli input e forniti all’encoder del transformer. |
AdaTape fornisce un utile bias induttivo
Valutiamo AdaTape su parity, un compito molto sfidante per il Transformer standard, per studiare l’effetto dei bias induttivi in AdaTape. Con il compito di parity, dato una sequenza di 1s, 0s e -1s, il modello deve predire la parità o disparità del numero di 1s nella sequenza. La parity è il linguaggio regolare non-contatore più semplice o periodico, ma forse sorprendentemente, il compito non è risolvibile dal Transformer standard.
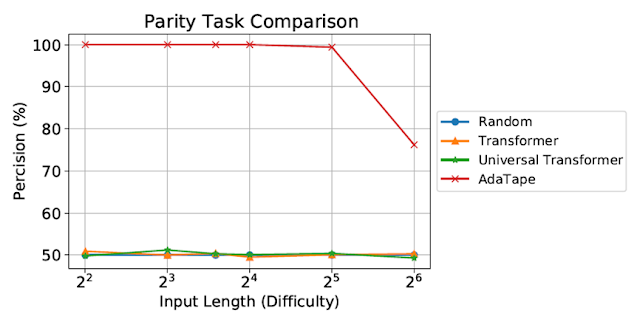 |
| Valutazione sul compito di parity. Il Transformer standard e il Universal Transformer non sono stati in grado di svolgere questo compito, entrambi mostrando prestazioni al livello di una linea di base di indovinamento casuale. |
Nonostante siano stati valutati su sequenze brevi e semplici, sia il Transformer standard che il Universal Transformer non sono stati in grado di svolgere il compito di parity in quanto non sono in grado di mantenere un contatore all’interno del modello. Tuttavia, AdaTape supera tutte le linee di base, in quanto incorpora una ricorrenza leggera nel suo meccanismo di selezione dell’input, fornendo un bias induttivo che consente il mantenimento implicito di un contatore, cosa non possibile nei Transformer standard.
Valutazione sulla classificazione delle immagini
Valutiamo anche AdaTape sul compito di classificazione delle immagini. Per farlo, abbiamo addestrato AdaTape su ImageNet-1K da zero. La figura sottostante mostra l’accuratezza di AdaTape e dei metodi di riferimento, inclusi A-ViT e Universal Transformer ViT (UViT e U2T) in relazione alla loro velocità (misurata come il numero di immagini elaborate da ciascun codice al secondo). In termini di trade-off tra qualità e costo, AdaTape si comporta molto meglio delle alternative basi di trasformazione adattiva. In termini di efficienza, modelli più grandi di AdaTape (in termini di conteggio dei parametri) sono più veloci delle basi più piccole. Tali risultati sono coerenti con le scoperte di lavori precedenti che mostrano che le architetture dei modelli adattivi in termini di profondità non sono adatte a molti acceleratori, come il TPU.
 |
| Valutiamo AdaTape addestrando ImageNet da zero. Per A-ViT, non solo riportiamo i loro risultati dal paper ma implementiamo anche A-ViT addestrandolo da zero, cioè A-ViT (Nostro). |
Uno studio sul comportamento di AdaTape
Oltre alle sue prestazioni nel compito di parità e su ImageNet-1K, abbiamo valutato il comportamento di selezione dei token di AdaTape con una banca guidata dall’input sul set di validazione di JFT-300M. Per comprendere meglio il comportamento del modello, abbiamo visualizzato i risultati della selezione dei token sulla banca guidata dall’input come mappe di calore, dove colori più chiari indicano che quella posizione viene selezionata più frequentemente. Le mappe di calore rivelano che AdaTape seleziona più frequentemente le patch centrali. Questo si allinea con la nostra conoscenza precedente, poiché le patch centrali sono tipicamente più informative, specialmente nel contesto di set di dati con immagini naturali, in cui l’oggetto principale si trova al centro dell’immagine. Questo risultato evidenzia l’intelligenza di AdaTape, in quanto è in grado di identificare ed assegnare priorità alle patch più informative per migliorare le sue prestazioni.
 |
| Visualizziamo la mappa di calore della selezione dei token di AdaTape-B/32 (sinistra) e AdaTape-B/16 (destra). Il colore più caldo/chiaro indica che la patch in quella posizione viene selezionata più frequentemente. |
Conclusione
AdaTape è caratterizzato da lunghezze di sequenza elastiche generate dal meccanismo di lettura del nastro adattivo. Ciò introduce anche un nuovo bias induttivo che consente ad AdaTape di avere il potenziale per risolvere compiti che sono sfidanti sia per i transformer standard che per i transformer adattivi esistenti. Attraverso una serie di esperimenti esaustivi su benchmark di riconoscimento delle immagini, dimostriamo che AdaTape supera i transformer standard e i transformer adattivi esistenti quando viene mantenuta costante la computazione.
Ringraziamenti
Uno degli autori di questo post, Mostafa Dehghani, ora lavora presso Google DeepMind.





