Immersione profonda nella modalità Copy-on-Write di pandas Parte I
Immersione profonda in Copy-on-Write di pandas Parte I
Spiegazione di come funziona internamente la Copy-on-Write

Introduzione
pandas 2.0 è stato rilasciato all’inizio di aprile e ha portato molte migliorie alla nuova modalità Copy-on-Write (CoW). Si prevede che questa funzionalità diventerà quella predefinita in pandas 3.0, prevista per aprile 2024 al momento. Non ci sono piani per una modalità legacy o non-CoW.
Questa serie di articoli spiegherà come funziona internamente la Copy-on-Write per aiutare gli utenti a capire cosa sta succedendo, mostrando come utilizzarla in modo efficace e illustrando come adattare il proprio codice. Ci saranno esempi su come sfruttare il meccanismo per ottenere le migliori prestazioni e verranno mostrati anche un paio di anti-pattern che comportano rallentamenti inutili. Ho scritto una breve introduzione alla Copy-on-Write qualche mese fa.
Ho scritto anche un breve post che spiega la struttura dei dati di pandas, che ti aiuterà a capire alcuni termini necessari per la CoW.
Faccio parte del team principale di pandas e sono stato fortemente coinvolto nell’implementazione e nell’ottimizzazione della CoW fino ad ora. Sono un ingegnere open source per Coiled, dove lavoro su Dask, incluso il miglioramento dell’integrazione con pandas e la garanzia che Dask sia conforme alla CoW.
- LLM ottimizzati per la previsione del sentiment — Come analizzare e valutare
- Analisi di grafi di grandi dimensioni con PageRank
- Creare un ChatBot personalizzato basato su AI utilizzando Langchain, Weviate e Streamlit
Come la Copy-on-Write cambia il comportamento di pandas
Molti di voi probabilmente conoscono le seguenti limitazioni di pandas:
import pandas as pddf = pd.DataFrame({"student_id": [1, 2, 3], "grade": ["A", "C", "D"]})Selezioniamo la colonna “grade” e sovrascriviamo la prima riga con "E".
grades = df["grade"]grades.iloc[0] = "E"df student_id grade0 1 E1 2 C2 3 DPurtroppo, questo ha aggiornato anche df e non solo grades, il che potrebbe introdurre bug difficili da individuare. La CoW impedisce questo comportamento e assicura che venga aggiornato solo df. Vediamo anche un avviso di SettingWithCopyWarning che qui non ci aiuta.
Guardiamo un esempio di ChainedIndexing che non fa nulla:
df[df["student_id"] > 2]["grades"] = "F"df student_id grade0 1 A1 2 C2 3 DIn questo esempio otteniamo nuovamente un avviso di SettingWithCopyWarning, ma in realtà non succede nulla a df. Tutti questi problemi derivano dalle regole di copia e visualizzazione in NumPy, che è ciò che pandas utilizza internamente. Gli utenti di pandas devono essere consapevoli di queste regole e di come si applicano ai DataFrame di pandas per capire perché pattern di codice simili producono risultati diversi.
La CoW risolve tutte queste inconsistenze. Gli utenti possono aggiornare solo un oggetto alla volta quando la CoW è abilitata, ad esempio df rimarrebbe invariato nel nostro primo esempio poiché viene aggiornato solo grades in quel momento e il secondo esempio genera un ChainedAssignmentError invece di non fare nulla. In generale, non sarà possibile aggiornare due oggetti contemporaneamente, ad esempio, ogni oggetto si comporta come se fosse una copia dell’oggetto precedente.
Ci sono molti altri casi del genere, ma non è l’obiettivo di questo articolo analizzarli tutti.
Come funziona
Esaminiamo la Copy-on-Write in modo più dettagliato e evidenziamo alcuni fatti importanti da conoscere. Questa è la parte principale di questo articolo ed è piuttosto tecnica.
La Copy-on-Write promette che qualsiasi DataFrame o Series derivato da un altro in qualsiasi modo si comporti sempre come una copia. Ciò significa che non è possibile modificare più di un oggetto con una singola operazione, ad esempio il nostro primo esempio sopra modificherebbe solo grades.
Un approccio molto difensivo per garantire ciò sarebbe copiare il DataFrame e i suoi dati in ogni operazione, evitando così le visualizzazioni in pandas. Questo garantirebbe la semantica di CoW ma comporterebbe anche un enorme penalità delle prestazioni, quindi questa non era un’opzione praticabile.
Adesso approfondiremo il meccanismo che assicura che nessun oggetto venga aggiornato con una singola operazione e che i nostri dati non vengano copiati inutilmente. La seconda parte è ciò che rende interessante l’implementazione.
Dobbiamo sapere esattamente quando scatenare una copia per evitare copie che non sono assolutamente necessarie. Le copie potenziali sono necessarie solo se cerchiamo di mutare i valori di un oggetto pandas senza copiare i suoi dati. Dobbiamo scatenare una copia se i dati di questo oggetto sono condivisi con un altro oggetto pandas. Ciò significa che dobbiamo tenere traccia se un array NumPy è referenziato da due DataFrame (in generale, dobbiamo essere consapevoli se un array NumPy è referenziato da due oggetti pandas, ma utilizzerò il termine DataFrame per semplicità).
df = pd.DataFrame({"student_id": [1, 2, 3], "grade": [1, 2, 3]})df2 = df[:]Questo statement crea un DataFrame df e una vista di questo DataFrame df2. Vista significa che entrambi i DataFrame sono supportati dallo stesso array NumPy sottostante. Quando lo guardiamo con CoW, df deve essere consapevole che df2 fa riferimento anche al suo array NumPy. Ma questo non è sufficiente. df2 deve anche essere consapevole che df fa riferimento al suo array NumPy. Se entrambi gli oggetti sono consapevoli che esiste un altro DataFrame che fa riferimento allo stesso array NumPy, possiamo scatenare una copia nel caso in cui uno di essi venga modificato, ad esempio:
df.iloc[0, 0] = 100Qui df viene modificato inplace. df sa che c’è un altro oggetto che fa riferimento agli stessi dati, ad esempio scatena una copia. Non sa quale oggetto fa riferimento agli stessi dati, sa solo che c’è un altro oggetto là fuori.
Diamo un’occhiata a come possiamo ottenere questo. Abbiamo creato una classe interna BlockValuesRefs che viene utilizzata per memorizzare queste informazioni, essa punta a tutti i DataFrames che fanno riferimento a un dato array NumPy.
Ci sono tre tipi di operazioni diverse che possono creare un DataFrame:
- Un DataFrame viene creato da dati esterni, ad esempio tramite
pd.DataFrame(...)o tramite qualsiasi metodo di I/O. - Un nuovo DataFrame viene creato tramite un’operazione di pandas che scatena una copia dei dati originali, ad esempio
dropnacrea una copia in quasi tutti i casi. - Un nuovo DataFrame viene creato tramite un’operazione di pandas che non scatena una copia dei dati originali, ad esempio
df2 = df.reset_index().
I primi due casi sono semplici. Quando il DataFrame viene creato, gli array NumPy che lo supportano sono collegati a un nuovo oggetto BlockValuesRefs. Questi array sono referenziati solo dal nuovo oggetto, quindi non dobbiamo tenere traccia di altri oggetti. L’oggetto crea un weakref che punta al Block che avvolge l’array NumPy e memorizza questo riferimento internamente. Il concetto di Blocchi è spiegato qui.
Un weakref crea un riferimento a qualsiasi oggetto Python. Non mantiene vivo questo oggetto quando normalmente uscirebbe dallo scope.
import weakrefclass Dummy: def __init__(self, a): self.a = aIn[1]: obj = Dummy(1)In[2]: ref = weakref.ref(obj)In[3]: ref()Out[3]: <__main__.Dummy object at 0x108187d60>In[4]: obj = Dummy(2)In questo esempio viene creato un oggetto Dummy e un riferimento debole a questo oggetto. Successivamente, assegniamo un altro oggetto alla stessa variabile, ad esempio l’oggetto iniziale esce dallo scope e viene raccolto come spazzatura. Il riferimento debole non interferisce con questo processo. Se risolvi il riferimento debole, punterà a
Noneinvece dell’oggetto originale.
In[5]: ref()Out[5]: NoneIn questo modo ci assicuriamo di non mantenere in vita alcun array che altrimenti verrebbe raccolto come spazzatura.
Diamo un’occhiata a come questi oggetti sono organizzati:
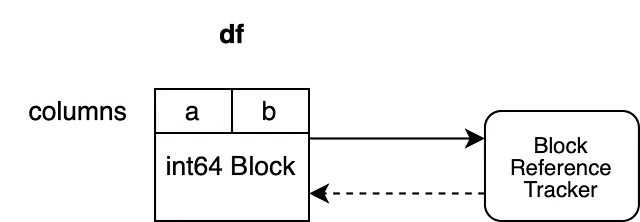
Il nostro esempio ha due colonne "a" e "b", entrambe con dtype "int64". Sono supportate da un unico blocco che contiene i dati per entrambe le colonne. Il blocco tiene un riferimento diretto all’oggetto di tracciamento dei riferimenti, garantendo che rimanga in vita finché il blocco non viene raccolto come spazzatura. L’oggetto di tracciamento dei riferimenti tiene un riferimento debole al blocco. Questo permette all’oggetto di tracciamento di monitorare il ciclo di vita di questo blocco ma non impedisce la raccolta come spazzatura. L’oggetto di tracciamento dei riferimenti non tiene ancora un riferimento debole ad alcun altro blocco.
Questi sono i casi semplici. Sappiamo che nessun altro oggetto pandas condivide lo stesso array NumPy, quindi possiamo semplicemente istanziare un nuovo oggetto di tracciamento dei riferimenti.
Il terzo caso è più complicato. Il nuovo oggetto visualizza gli stessi dati dell’oggetto originale. Ciò significa che entrambi gli oggetti puntano alla stessa memoria. La nostra operazione creerà un nuovo blocco che fa riferimento allo stesso array NumPy, questo viene chiamato una copia superficiale. Ora dobbiamo registrare questo nuovo blocco nella nostra meccanica di tracciamento dei riferimenti. Registriamo il nuovo blocco con l’oggetto di tracciamento dei riferimenti che è collegato all’oggetto vecchio.
df2 = df.reset_index(drop=True)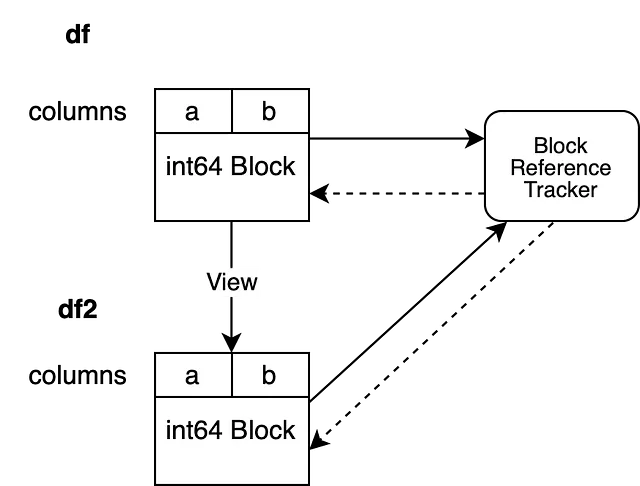
Ora il nostro BlockValuesRefs punta al blocco che supporta il df iniziale e al blocco appena creato che supporta il df2. Ciò garantisce che siamo sempre consapevoli di tutti i DataFrame che puntano alla stessa memoria.
Possiamo ora chiedere all’oggetto di tracciamento dei riferimenti quante volte viene fatto riferimento allo stesso array NumPy. L’oggetto di tracciamento dei riferimenti valuta i riferimenti deboli e ci dice che più di un oggetto fa riferimento agli stessi dati. Ciò ci permette di scatenare una copia internamente se uno di essi viene modificato sul posto.
df2.iloc[0, 0] = 100Il blocco in df2 viene copiato attraverso una copia profonda, creando un nuovo blocco che ha i propri dati e un oggetto di tracciamento dei riferimenti. Il blocco originale che supportava df2 può ora essere raccolto come spazzatura, garantendo che gli array che supportano df e df2 non condividano alcuna memoria.
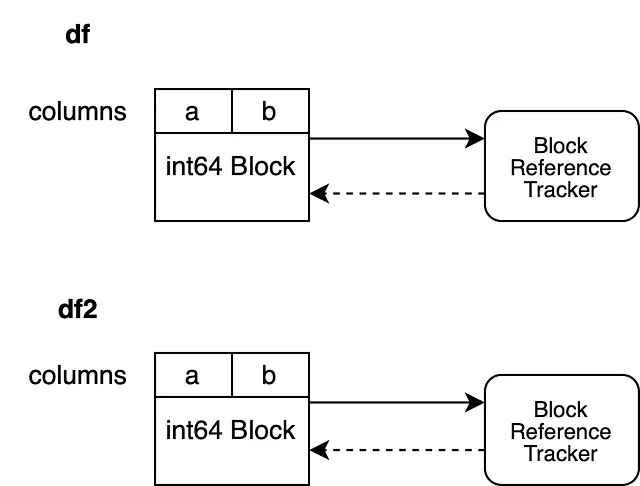
Guardiamo uno scenario diverso.
df = Nonedf2.iloc[0, 0] = 100df viene invalidato prima di modificare df2. Di conseguenza, il weakref del nostro oggetto di tracciamento dei riferimenti, che punta al blocco che supportava df, valuta a None. Ciò ci consente di modificare df2 senza scatenare una copia.
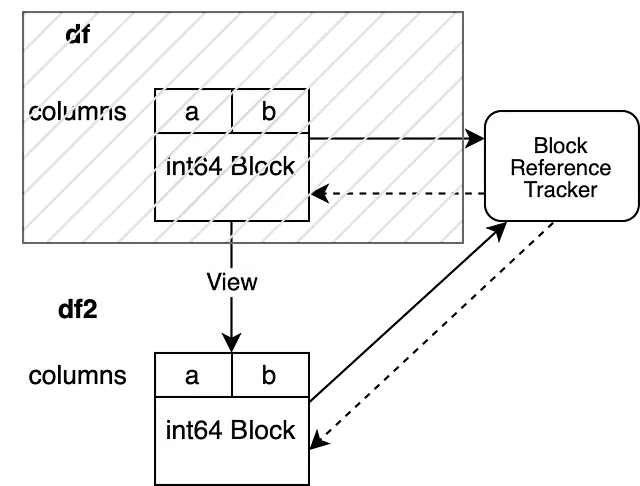
Il nostro oggetto di tracciamento dei riferimenti punta a un solo DataFrame, il che ci consente di eseguire l’operazione inplace senza scatenare una copia.
reset_index sopra crea una vista. Il meccanismo è un po’ più semplice se abbiamo un’operazione che scatena una copia internamente.
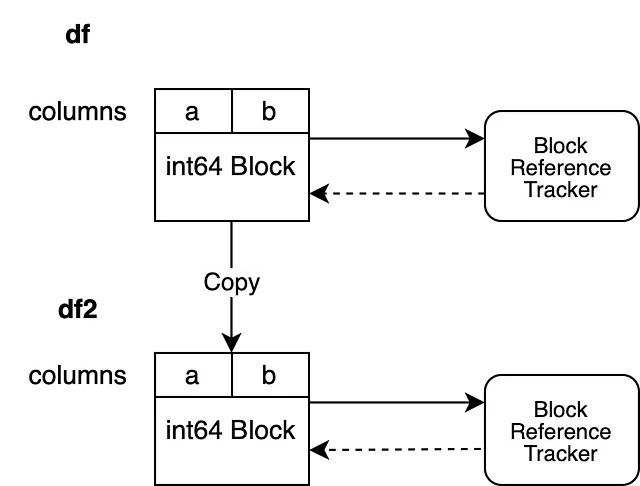
df2 = df.copy()Questo istantaneamente istanzia un nuovo oggetto di tracciamento dei riferimenti per il nostro DataFrame df2.
Conclusioni
Abbiamo investigato come funziona il meccanismo di tracciamento Copy-on-Write e quando viene attivata una copia. Il meccanismo ritarda le copie in pandas il più possibile, il che è molto diverso dal comportamento non-CoW. Il meccanismo di tracciamento dei riferimenti tiene traccia di tutti i DataFrame che condividono memoria, consentendo un comportamento più coerente in pandas.
La prossima parte di questa serie spiegherà le tecniche utilizzate per rendere questo meccanismo più efficiente.
Grazie per la lettura. Non esitate a contattarci per condividere le vostre opinioni e feedback su Copy-on-Write.