I Gioielli Sottovalutati Pt.1 8 Metodi di Pandas Che Ti Renderanno un Esperto
8 Metodi Pandas per Esperti Gioielli Sottovalutati Pt.1
Sottovalutato, poco apprezzato e poco esplorato
“Tra il rumore della folla, sono le parole pronunciate dolcemente a contenere la saggezza nascosta 💎”
Dimentica ChatGPT per un po’. Per alcuni di noi, ci stanchiamo di cercare costantemente una soluzione su Google ogni volta che vogliamo eseguire un’operazione semplice di Pandas. Sembra che ci siano numerose modi per fare la stessa cosa, quale è quale? Avere molte possibili soluzioni da scegliere è ovviamente fantastico, ma con esse arriva anche l’incoerenza e la confusione nel capire cosa dovrebbe fare la riga di codice.
Ci sono 1000 possibili percorsi per raggiungere Roma, forse anche di più. La domanda è, segui il percorso nascosto o prendi la strada complicata?

Ecco la conclusione di questo post. Ti guiderò su come mettere in pratica questi metodi lavorando sul dataset di bike sharing da UCI Machine Learning¹. Adottando questi metodi, non solo ottimizzerai il tuo codice di manipolazione dei dati, ma acquisirai anche una comprensione più approfondita del codice che scrivi. Cominciamo importando il dataset e facendo una rapida visualizzazione del DataFrame!
- Lavorare con MS SQL Server in Julia
- Ottimizza efficacemente il tuo modello di regressione con l’ottimizzazione iperparametrica bayesiana
- Machine Learning a Effetti Misti per Dati Longitudinali e Panel con GPBoost (Parte III)
import numpy as npimport pandas as pdimport matplotlib.pyplot as pltbike = (pd .read_csv("../../dataset/bike_sharing/day.csv") )bike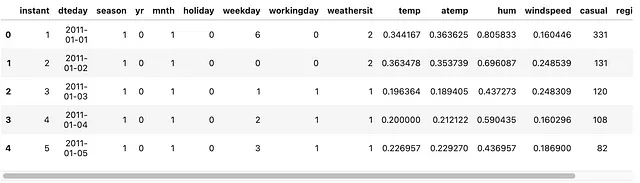
Indice
- Metodo #1:
.assign() - Metodo #2:
.groupby() - Metodo #3:
.agg() - Metodo #4:
.transform() - Metodo #5:
.pivot_table() - Metodo #6:
.resample() - Metodo #7:
.unstack() - Metodo #8:
.pipe()
☕️ Metodo #1: .assign()
Dimentica di usare operazioni come df["new_col"] = e df.new_col = per creare nuove colonne. Ecco perché dovresti usare il metodo .assign() — restituisce un oggetto DataFrame, che ti consente di continuare la catena di operazioni per manipolare ulteriormente il tuo DataFrame. A differenza del metodo .assign(), le due famigerate operazioni sopra restituiscono un None, il che significa che non puoi concatenare ulteriormente la tua operazione.
Se non sei convinto, lascia che riproponga l’antico nemico — SettingWithCopyWarning. Sono abbastanza sicuro che ognuno di noi si sia imbattuto in questo a un certo punto.

Basta con l’avvertimento, voglio rimuovere le brutte caselle rosse dal mio notebook!
Usando .assign(), aggiungiamo alcune nuove colonne come ratio_casual_registered, avg_temp e ratio_squared
(bike .assign(ratio_casual_registered = bike.casual.div(bike.registered), avg_temp = bike.temp.add(bike.atemp).div(2), ratio_squared = lambda df_: df_.ratio_casual_registered.pow(2)))In breve, ecco cosa fa il metodo sopra:
- Possiamo creare tante nuove colonne quanto vogliamo utilizzando il metodo
.assign(), separate da virgola. - La funzione lambda quando crea la colonna
ratio_squaredserve per accedere al DataFrame più recente dopo aver aggiunto la colonnaratio_casual_registered. Ad esempio, se non utilizziamo una funzione lambda per accedere al DataFrame più recentedf_, ma continuiamo conbike.ratio_casual_registered.pow(2), otterremmo un errore in quanto il DataFrame originale non ha la colonnaratio_casual_registered, anche dopo averla aggiunta nel metodo.assign()prima di creareratio_squared. Se non riesci a capire questo concetto per decidere se utilizzare o meno una funzione lambda, il mio suggerimento è di utilizzarne una! - Bonus! Ti lascio alcuni modi non comuni per eseguire operazioni aritmetiche utilizzando metodi.
☕️ Metodo #2: .groupby()
Beh, il metodo .groupby() non è comunemente utilizzato, ma è necessario per iniziare prima di approfondire i prossimi metodi. Una cosa che spesso passa inosservata e di cui non si parla è che il metodo .groupby() ha una natura pigra. Ciò significa che il metodo viene valutato in modo pigro. In altre parole, non viene valutato immediatamente, ed è per questo che spesso si vede <pandas.core.groupby.generic.DataFrameGroupBy object at 0x14fdc3610> subito dopo aver chiamato il metodo .groupby()
Dalla documentazione di Pandas DataFrame², il valore da inserire nel parametro by può essere una mappatura, una funzione, una label, un pd.Grouper o una lista di questi. Tuttavia, quello più comune che probabilmente incontri è raggruppare per nomi di colonne (lista di nomi di Serie separati da virgola). Dopo l’operazione .groupby(), possiamo eseguire operazioni come .mean(), .median(), o applicare una funzione personalizzata utilizzando .apply().
Il valore delle colonne specificate che forniamo al parametro
bynel metodo.groupby()diventerà l’indice del risultato. Se specifichiamo più di 1 colonna per il raggruppamento, otterremo un MultiIndex.
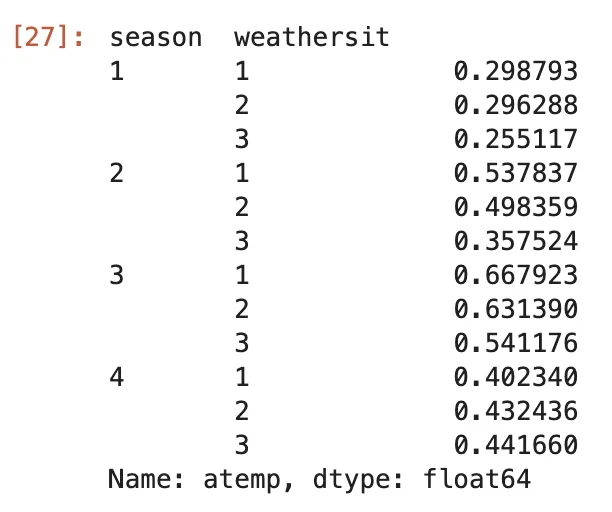
(bike .groupby(['season', 'weathersit']) .mean(numeric_only=True) #versione alternativa: apply(lambda df_: df_.mean(numeric_only=True)) .atemp)Qui abbiamo raggruppato il nostro DataFrame per la colonna season e weathersit. Quindi, calcoliamo il valore medio e selezioniamo solo la colonna atemp.
☕️ Metodo #3: .agg()
Se sei abbastanza meticoloso da scavare nella documentazione di Pandas², potresti incontrare sia il metodo .agg() che .aggregate(). Potresti chiederti qual è la differenza e quando utilizzarli? Risparmia tempo! Sono la stessa cosa, .agg() è solo un alias per .aggregate().
.agg() ha un parametro func, che letteralmente accetta una funzione, un nome di funzione come stringa o una lista di funzioni. A proposito, puoi anche aggregare diverse funzioni sulle colonne! Continuiamo con il nostro esempio di prima!
#Esempio 1: Aggregazione utilizzando più di 1 funzione(bike .groupby(['season']) .agg(['mean', 'median']) .atemp)#Esempio 2: Aggregazione utilizzando funzioni diverse per colonne diverse(bike .groupby(['season']) .agg(Media=('temp', 'mean'), Mediana=('atemp', np.median)))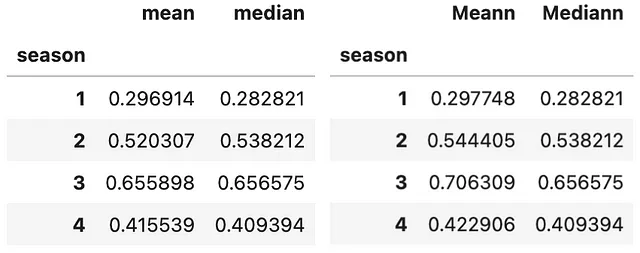
☕️ Metodo n. 4: .transform()
Con .agg(), il risultato che otteniamo ha una dimensionalità ridotta rispetto all’insieme di dati iniziale. In termini semplici, la dimensione dei dati si riduce con un minor numero di righe e colonne, contenenti le informazioni aggregate. Se ciò che desideri è riassumere i dati raggruppati e ottenere valori aggregati, allora la soluzione è .groupby().
Con .transform(), anche noi iniziamo con l’intenzione di fare l’aggregazione delle informazioni. Tuttavia, invece di creare un riassunto delle informazioni, vogliamo che l’output abbia la stessa forma del DataFrame originale, senza ridurre le dimensioni del DataFrame originale.
Coloro che hanno esperienza con i sistemi di database come SQL potrebbero trovare simile l’idea dietro .transform() a quella di Window Function. Vediamo come funziona .transform() sull’esempio sopra!
(bike .assign(media_atemp_stagione = lambda df_: df_ .groupby(['stagione']) .atemp .transform(np.mean, numeric_only=True)))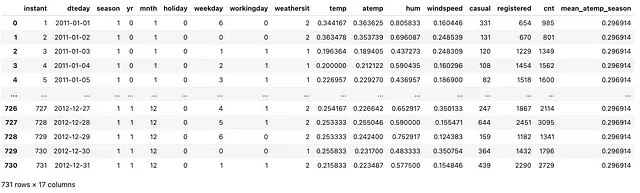
Come si può vedere sopra, abbiamo creato una nuova colonna con il nome di colonna – media_atemp_stagione – dove riempiamo la colonna con l’aggregato (media) della colonna atemp. Quindi, ogni volta che la stagione è 1, abbiamo lo stesso valore per media_atemp_stagione. Nota l’importante osservazione che manteniamo la dimensione originale dell’insieme di dati più una colonna aggiuntiva!
☕️ Metodo n. 5: .pivot_table()
Ecco un bonus per coloro che sono ossessionati da Microsoft Excel. Potresti essere tentato di utilizzare .pivot_table() per creare una tabella riassuntiva. Beh, ovviamente, questo metodo funziona anche! Ma ecco un consiglio, .groupby() è più versatile e viene utilizzato per una gamma più ampia di operazioni oltre alla sola ristrutturazione, come il filtraggio, la trasformazione o l’applicazione di calcoli specifici per gruppi.
Ecco come utilizzare .pivot_table() in breve. Specifica la/e colonna/e che vuoi aggregare nell’argomento values. Successivamente, specifica l’indice della tabella riassuntiva che desideri creare utilizzando un sottoinsieme del DataFrame originale. Questo può essere più di una colonna e la tabella riassuntiva sarà un DataFrame di MultiIndex. Successivamente, specifica le colonne della tabella riassuntiva che desideri creare utilizzando un sottoinsieme del DataFrame originale che non è stato selezionato come indice. Infine, non dimenticare di specificare l’aggfunc! Diamo un’occhiata rapida!
(bike .pivot_table(values=['temp', 'atemp'], index=['stagione'], columns=['workingday'], aggfunc=np.mean))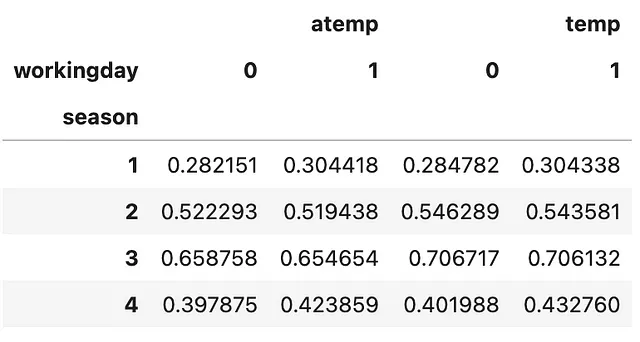
☕️ Metodo n. 6: .resample()
Parlando in termini generali, il metodo .resample() può essere considerato come un raggruppamento e una aggregazione specificamente per i dati di serie temporali, dove
L’indice del DataFrame o della Serie è un oggetto simile a una data e ora.
Ciò ti consente di raggruppare e aggregare i dati in base a diverse frequenze temporali, come orarie, giornaliere, settimanali, mensili, ecc. In generale, .resample() può accettare DateOffset, Timedelta o str come regola per eseguire il campionamento. Applichiamolo al nostro esempio precedente.
def tweak_bike(bike: pd.DataFrame) -> pd.DataFrame: return (bike .drop(columns=['instant']) .assign(dteday=lambda df_: pd.to_datetime(df_.dteday)) .set_index('dteday') )bike = tweak_bike(bike)(bike .resample('M') .temp .mean())In breve, ciò che facciamo qui sopra è eliminare la colonna instant, sovrascrivere la colonna dteday con la colonna dteday convertita da tipo object a tipo datetime64[ns], e infine impostare questa colonna datetime64[ns] come indice del DataFrame.
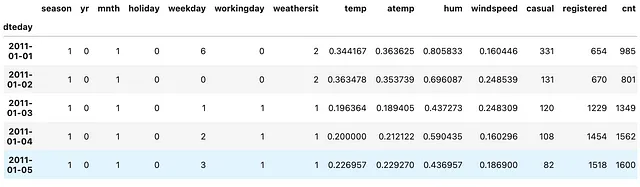
(bike .resample('M') .temp .mean())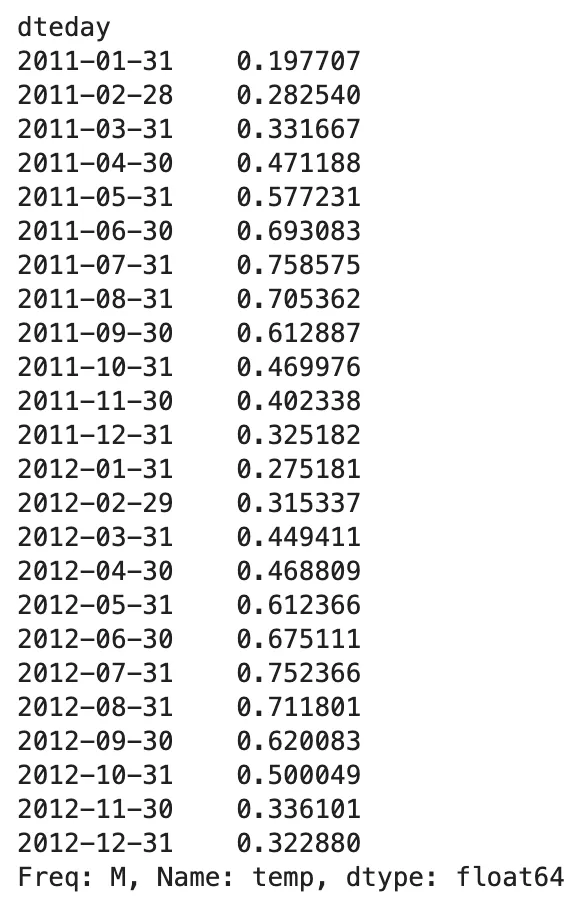
Qui otteniamo un riepilogo statistico descrittivo (media) della caratteristica temp con frequenza mensile. Prova e gioca con il metodo .resample() utilizzando diverse frequenze come Q, 2M, A e così via,
☕️ Metodo #7: .unstack()
Siamo quasi alla fine! Lascia che ti mostri perché .unstack() è sia potente che utile. Ma prima di farlo, torniamo a uno degli esempi precedenti in cui vogliamo trovare la temperatura media in diverse stagioni e situazioni meteorologiche utilizzando .groupby() e .agg()
(bike .groupby(['season', 'weathersit']) .agg('mean') .temp)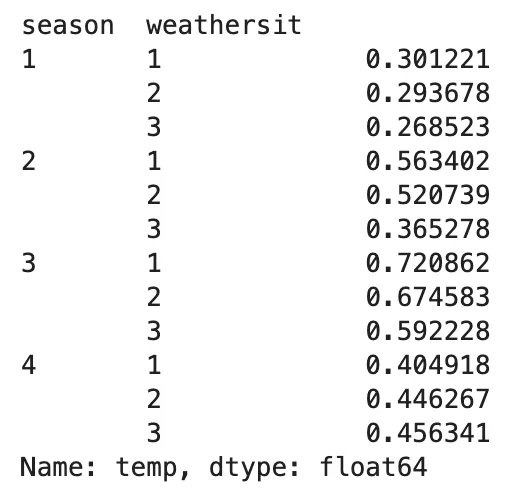
Ora, visualizziamo questo utilizzando un grafico a linea prodotto minimamente concatenando i metodi .plot e .line() al codice precedente. Dietro le quinte, Pandas si basa sul backend di tracciamento di Matplotlib per svolgere il compito di tracciamento. Questo dà il seguente risultato, che nessuno di noi voleva poiché l’asse x del grafico è raggruppato per il MultiIndex, rendendolo più difficile da interpretare e meno significativo.
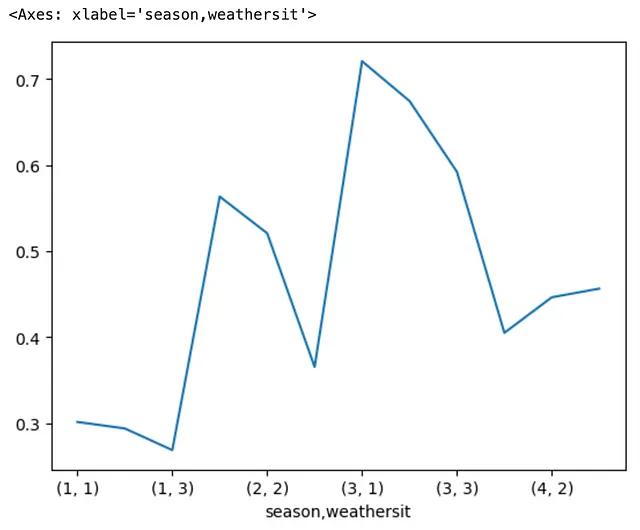
Confronta il grafico sopra e quello sotto dopo aver introdotto il metodo .unstack().
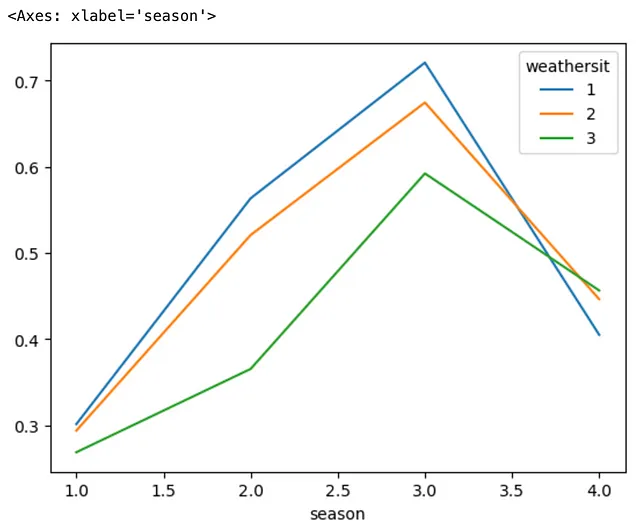
(bike .groupby(['season', 'weathersit']) .agg('mean') .temp .unstack() .plot .line())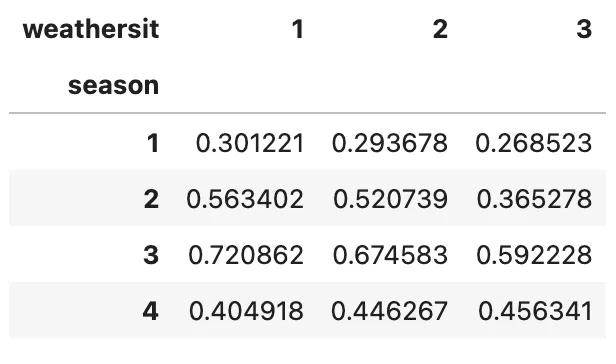
In breve, ciò che il metodo .unstack() fa è scomporre l’indice più interno del DataFrame MultiIndex, che in questo caso è weathersit. Questo cosiddetto indice non impilato diventa le colonne del nuovo DataFrame, il che consente al nostro tracciamento del grafico a linea di fornire un risultato più significativo a scopo di confronto.
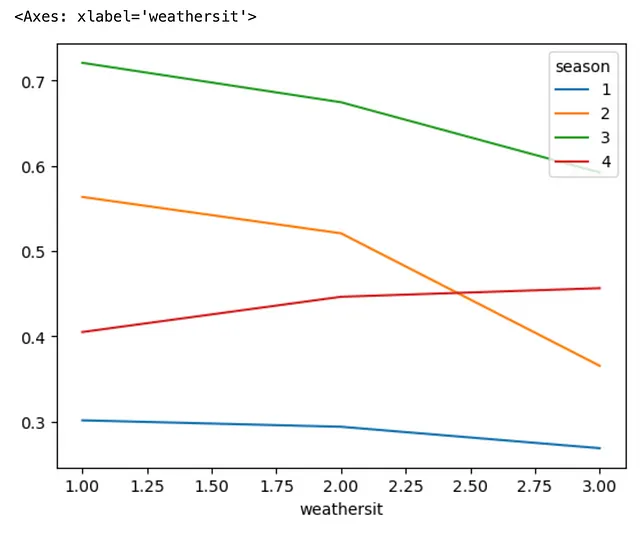
Puoi anche scomporre l’indice più esterno anziché l’indice più interno del DataFrame, specificando l’argomento level=0 come parte del metodo .unstack(). Vediamo come possiamo ottenere questo.
(bike .groupby(['season', 'weathersit']) .agg('mean') .temp .unstack(level=0) .plot .line())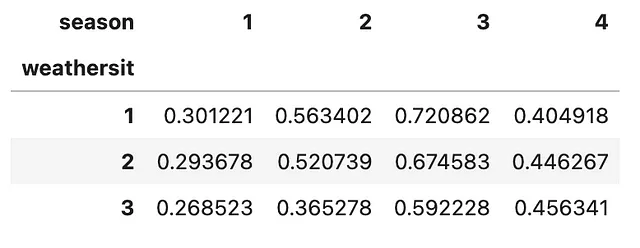
☕️ Metodo n. 8: .pipe()
Dalla mia osservazione, quasi mai vedrai persone comuni implementare questo metodo nel loro codice Pandas quando cerchi online. Per una ragione, .pipe() ha in qualche modo la sua misteriosa aura inesplicabile che non la rende amichevole per principianti e intermedi. Quando vai alla documentazione di Pandas², la breve spiegazione che troverai è “Applica funzioni concatenabili che si aspettano Serie o DataFrames”. Penso che questa spiegazione sia un po’ confusa e non molto utile, soprattutto se non hai mai lavorato con il chaining prima.
In breve, quello che .pipe() ti offre è la possibilità di continuare la tua tecnica di concatenazione di metodi usando una funzione, nel caso in cui non riesci a trovare una soluzione diretta per eseguire un’operazione e restituire un DataFrame.
Il metodo .pipe() prende in input una funzione, in questo modo puoi definire un metodo fuori dalla catena e poi fare riferimento al metodo come argomento del metodo .pipe().
Con
.pipe(), puoi passare un DataFrame o una Serie come primo argomento a una funzione personalizzata, e la funzione verrà applicata all’oggetto passato, seguito da eventuali argomenti aggiuntivi specificati successivamente.
La maggior parte delle volte, vedrai una funzione lambda di una sola riga all’interno del metodo .pipe() per comodità (ad es. ottenere accesso al DataFrame più recente dopo alcune modifiche nel processo di concatenazione).
Lasciami illustrare con un esempio semplificato. Supponiamo che vogliamo ottenere informazioni sulla seguente domanda: “Per l’anno 2012, qual è la proporzione di giorni lavorativi per stagione, rispetto al totale dei giorni lavorativi di quell’anno?”
(bike .loc[bike.index.year == 2012] .groupby(['season']) .workingday .agg(sum) .pipe(lambda x: x.div(x.sum())))Qui, usiamo .pipe() per iniettare la funzione nel nostro metodo di concatenazione. Dato che dopo aver eseguito .agg(sum), non possiamo semplicemente continuare la concatenazione con .div(), il codice seguente non funzionerà poiché abbiamo perso l’accesso allo stato più recente del DataFrame dopo alcune modifiche attraverso il processo di concatenazione.
#Non funziona bene!(bike .loc[bike.index.year == 2012] .groupby(['season']) .workingday .agg(sum) .div(...))Suggerimenti: se non riesci a trovare un modo per continuare la concatenazione dei tuoi metodi, prova a pensare a come
.pipe()può aiutare! Nella maggior parte dei casi, lo farà!
Postfazione
Questo conclude la prima parte di The Underrated Gems 💎! Sono tutti metodi che non ho usato molto prima, forse a causa della mia cattiva abitudine di forzare il mio codice con il pensiero che “Finché funziona, va bene così!” Purtroppo, non è così!
Solo dopo aver dedicato del tempo per imparare come utilizzarli correttamente, si sono rivelati salva-vita, per dirla in modo modesto! Voglio anche ringraziare Matt Harrison e il suo libro Effective Pandas³ che ha completamente cambiato il modo in cui scrivo il mio codice Pandas. Ora posso dire che il mio codice è più conciso, leggibile e ha più senso.
Se hai appreso qualcosa di utile da questo articolo, considera di darmi un Follow su VoAGI. Facile, un articolo a settimana per tenerti aggiornato e stare un passo avanti!
Connettiti con me!
- LinkedIn 👔
- Twitter 🖊
Riferimenti
- Fanaee-T,Hadi. (2013). Bike Sharing Dataset. UCI Machine Learning Repository. https://doi.org/10.24432/C5W894.
- Documentazione di Pandas: https://pandas.pydata.org/docs/reference/frame.html
- Effective Pandas di Matt Harrison: https://store.metasnake.com/effective-pandas-book




