Le 5 efficaci modalità per trovare e risolvere i problemi dei dati
5 effective ways to find and solve data problems.
Scoprire anomalie e incoerenze nascoste
Secondo un sondaggio di Gartner, quasi il 60% delle organizzazioni non misura il costo finanziario annuale dei dati di bassa qualità. Credo che l’altro 40% stia mentendo. Nella mia esperienza, la perdita dovuta alla qualità dei dati raramente viene quantificata dalle organizzazioni, anche se colpisce quotidianamente.
Non penso che il nostro stato sia dovuto a una mancanza di impegno; è più perché non sappiamo da dove cominciare. Come le cattive abitudini, cercare di risolvere tutti i problemi contemporaneamente o in un progetto di un anno porterà a fallimenti. È necessario un cambiamento culturale di responsabilità, processi chiari e un po’ di aiuto tecnologico.
Oggi, approfondiremo cinque modi per trovare e risolvere i problemi. Andiamo!
1. Verificare i dati che arrivano dai sistemi di origine
Come la maggior parte delle grandi organizzazioni, se hai vecchi sistemi di origine arcaici che alimentano le informazioni del tuo datawarehouse/lake, sai che i dati di origine sono un grande problema.
- Come creare bellissimi grafici a barre con Seaborn e Matplotlib (inclusa l’animazione)
- PyLogik per la de-identificazione dei dati delle immagini mediche.
- Mappatura in avanti e all’indietro per la visione artificiale
Se i sistemi sono vecchi, potrebbe essere inflessibile nell’accettare i cambiamenti. In questo caso, quando i dati vengono ricevuti o messi in coda nel tuo data warehouse, l’applicazione di un controllo di duplicazione e riconciliazione garantirà che tu catch i problemi prima che inquinino il tuo patrimonio dati più ampio.
Una volta trovato il problema, puoi o respingere quei record dannosi dal flusso successivo o gestire il problema nella progettazione della tua pipeline. Finché sai che il problema dei dati esiste, puoi avvertire gli utenti, evitando quindi di prendere decisioni sbagliate.
Come esempio, quando ricevi un file di dati del cliente da una fonte, si consiglia di eseguire un controllo di completezza. Questo garantirà che i campi essenziali come last_name, date_of_birth e address siano completamente popolati. Se mancano dati, è consigliabile scartare quei record dal tuo bucket di analisi. In alternativa, è possibile aggiungere record predefiniti per le informazioni mancanti. Ad esempio, puoi aggiungere 01/01/1800 come data di nascita predefinita, poiché questo ti aiuterà a identificare i record che mancano di informazioni critiche, facilitando così una migliore presa di decisione durante l’analisi.
2. Risolvere i problemi dei dati nei tavoli esistenti
Nel tempo, la qualità dei dati si deteriora a causa della mancanza di processi di governance. Alcune chiavi sono state riciclate, sono state aggiunte informazioni duplicate o sono stati applicati patch, il che ha peggiorato le cose.
Un semplice profilo dei dati può fornire lo stato attuale dei dati in una determinata tabella. Ora – concentrandosi sugli attributi / colonne principali che hanno questi problemi. La chiave è isolare il problema il più possibile. Una volta determinati gli attributi, applicare una correzione una tantum. Ad esempio, se i dati sono duplicati, concorda con i responsabili dei dati su come arrivare a un singolo record. Oppure, se i dati sono imprecisi come data di nascita, date di inizio e di fine ecc., Convenite sulla sostituzione corretta e applicate la correzione.
Una volta applicata la correzione, è necessario operazionalizzare questo processo per evitare ulteriori deterioramenti della qualità dei dati. Questo lavoro di pulizia può essere eseguito quotidianamente e corregge i dati eseguendo dichiarazioni di aggiornamento. O potrebbe essere un intervento manuale da parte di un utente finale che valuta una tabella di audit.
Come esempio, se la tua tabella dei dati del cliente ha record duplicati del cliente, puoi usare un tool di qualità dei dati per profilare i tuoi dati. Ciò ti aiuterà a identificare i duplicati e determinare perché si verificano. I duplicati potrebbero essere causati dall’invio delle stesse informazioni da parte della fonte più volte, da codice di pipeline di dati scadente o da un processo aziendale. Una volta identificati i duplicati e la loro causa radice, puoi unire i record o eliminare il record ridondante. Se non riesci a risolvere la causa radice, puoi impostare un lavoro di pulizia per eseguire regolarmente un controllo di duplicati, corrispondere ai clienti, unirli e cancellare il record ridondante (gestione dei dati principali).
3. Ricreare pipeline di dati mal progettate
I problemi dei dati a volte possono derivare da pipeline di dati mal progettate o inefficienti. Puoi migliorare il flusso di dati, le trasformazioni e i processi di integrazione rivalutando e ricostruendo queste pipeline.
Le pipeline mal progettate possono soffrire di collo di bottiglia che rallentano l’elaborazione tempestiva dei dati, o trasformazioni di dati complicate e processi di integrazione possono introdurre errori e incoerenze. L’analisi della pipeline è fondamentale per isolare il problema e applicare una correzione.
Per i problemi di bottleneck, il pipeline può essere riprogettato per eseguire su più nodi o per problemi di trasformazione dei dati; il pipeline può essere suddiviso in varie fasi (evitando join ridondanti, interrogando grandi tabelle più volte, ecc.) per ridurre la complessità complessiva.
Ad esempio, se si riscontrano lunghi tempi di aggiornamento della tabella dei dati dei clienti, valutare il pipeline suddividendo i suoi componenti sarà utile. Dopo una più attenta ispezione, si scoprirà che la progettazione del pipeline è complessa a causa della sua dipendenza da più tabelle, riferimenti di ricerca e della generazione di un output di record principale. Per migliorare le prestazioni e isolare il problema, si consiglia di progettare e testare ogni componente del pipeline. Questo processo potrebbe rivelare che specifici join di tabelle richiedono più tempo del previsto. A questo punto, è possibile esaminare la tabella e determinare se esegue un join cartesiano (incrociato) o se viene letta più volte a causa della progettazione del join. Una volta individuato il problema, è possibile scomporlo ulteriormente e rimuovere quei join o creare altre tabelle di staging per semplificare il pipeline.
4. Sfruttare i dashboard di visualizzazione dei dati
La parte difficile nella risoluzione dei problemi è prima di tutto trovarli. E ascolterai il solito discorso dei fornitori sulla loro tecnologia come la prossima grande cosa che risolverà da sola i problemi dei dati. La verità è che hai bisogno di un posto dove visualizzare i problemi.
Un semplice profilo dei dati con un dashboard ancora più semplice che mostra i valori anomali, le lacune, le incongruenze e la asimmetria farà il lavoro. Un punto dati anomalo che indica una transazione insolitamente grande può essere facilmente identificato in un grafico a dispersione che mostra gli importi delle transazioni dei clienti nel tempo.
Un grafico a linee che rappresenta il traffico del sito web giornaliero che mostra improvvisi cali o periodi di attività zero potrebbe indicare punti dati mancanti o drastici cambiamenti nei dati.
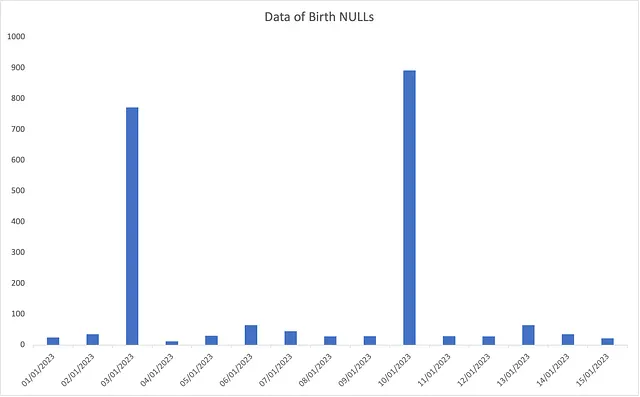
Ad esempio, se si hanno problemi con i dati incompleti dei clienti nella tabella, si consideri l’utilizzo di un dashboard di visualizzazione per evidenziare i valori NULL in colonne specifiche come la data di nascita. Un grafico a barre giornaliero può monitorare questo attributo e rilevare eventuali picchi improvvisi nei dati, come mostrato di seguito.
5. Machine Learning per rilevamento e risoluzione
Con l’avanzare dell’era dell’automazione, l’ML può essere utilizzato per migliorare la qualità dei dati. Addestrando i modelli sui dati storici, gli algoritmi di machine learning possono apprendere pattern e anomalie, consentendo l’identificazione e la risoluzione automatizzate dei problemi di dati.
L’apprendimento automatico può anche automatizzare i processi di pulizia dei dati identificando e correggendo problemi di dati comuni. Ad esempio, i modelli possono imputare i valori mancanti, correggere gli errori di formattazione o standardizzare i dati inconsistenti.
Ad esempio, un modello di rilevamento delle anomalie può essere creato utilizzando un set di dati di addestramento della tabella dei dati storici dei clienti. Il modello apprende i pattern e le caratteristiche delle normali date di nascita in base alla distribuzione e alle proprietà statistiche dei dati di addestramento. Il modello stabilisce una soglia di normalità per la colonna “Data di nascita” utilizzando i dati di addestramento. Questa soglia è tipicamente basata su misure statistiche come la media, la deviazione standard o l’intervallo delle date di nascita osservate nel dataset di addestramento. Il modello valuta i nuovi record dei clienti nella fase di rilevamento delle anomalie e confronta le loro date di nascita con la soglia di normalità stabilita. Se una data di nascita cade al di fuori della soglia o si discosta significativamente dai pattern attesi, viene segnalata come anomalia.
Conclusione
Investire nella risoluzione dei problemi di dati ripagherà per tutti i casi di utilizzo dell’analisi e dell’IA a valle. “Spazzatura in, spazzatura fuori”. Queste cinque modalità dovrebbero aiutarti ad iniziare il tuo percorso di risoluzione dei problemi di dati.
Tuttavia, se vuoi imparare come implementare tutti gli aspetti fondamentali della qualità dei dati, consulta la mia Ultimate Data Quality Handbook.
Ultimate Data Quality Handbook
Sblocca il potere dei dati: l’Ultimate Data Quality Handbook è la tua guida completa per raggiungere l’eccellenza dei dati…
hanzalaqureshi.gumroad.com
Se non sei ancora iscritto a Nisoo, considera l’iscrizione utilizzando il mio link di referral. È più economico di Netflix e oggettivamente un utilizzo del tuo tempo molto migliore. Se usi il mio link, guadagno una piccola commissione e tu accedi a storie illimitate su Nisoo, vincente.



