Come Misurare lo Spostamento Negli Embedding di ML
Measuring Displacement in ML Embeddings
Abbiamo valutato cinque metodi di rilevamento della variazione delle incorporazioni
Perché monitorare la variazione delle incorporazioni?
Quando i sistemi di apprendimento automatico sono in produzione, spesso non si ottengono immediatamente le etichette di verità. Il modello prevede o classifica qualcosa, ma non si sa quanto sia accurato. Bisogna aspettare un po’ (o molto!) per ottenere le etichette e misurare la vera qualità del modello.
Certo, niente batte la misurazione delle prestazioni effettive. Ma se non è possibile a causa del ritardo del feedback, ci sono preziosi indizi da osservare. Uno di questi è la rilevazione della variazione della previsione del modello (“La produzione del modello sembra diversa da prima?”) e degli input del modello (“I dati forniti al modello sono diversi”?).
Rilevare la variazione della previsione e dei dati può servire come avviso precoce. È utile vedere se il modello sta ricevendo nuovi input che potrebbe non essere in grado di gestire. Comprendere che c’è un cambiamento nell’ambiente può anche aiutare a identificare modi per migliorare il modello.
Che tipo di problemi si possono rilevare? Ad esempio, se il tuo modello sta facendo classificazione di testo, potresti voler notare se c’è un nuovo argomento, un cambiamento di sentimenti, un cambiamento nell’equilibrio delle classi, testi in una nuova lingua o quando inizi a ricevere molti input di spam o corrotti.
- Apprendere dal Machine Learning | Vincent Warmerdam Calmcode, Explosion, Data Science
- Funzioni di Finestra Un Must-Know per gli Ingegneri e gli Scienziati dei Dati.
- Rendi i tuoi grafici fantastici con UTF-8
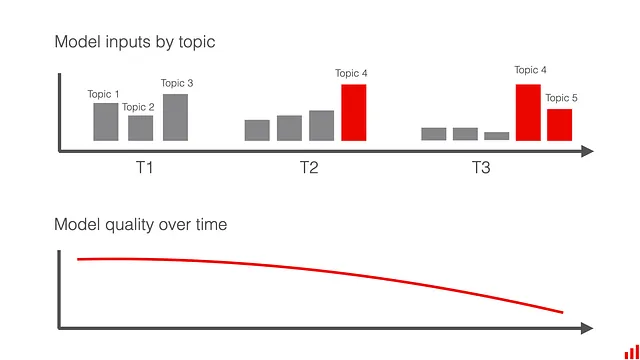
Ma come rilevare esattamente questo cambiamento?
Se si lavora con dati strutturati, ci sono molti metodi che si possono usare per rilevare la variazione: dal tracciamento delle statistiche descrittive delle uscite del modello (intervallo minimo-massimo, la quota di classi previste, ecc.) a metodi di rilevamento della variazione della distribuzione più sofisticati, da test statistici come Kholmogorov-Smirnov a metriche di distanza come la distanza di Wasserstein.
Tuttavia, se si lavora con applicazioni basate su NLP o LLM, si lavora con dati non strutturati. Spesso sotto forma di rappresentazioni numeriche – incorporazioni. Come si può rilevare la variazione in queste rappresentazioni numeriche?

Questo è un argomento piuttosto nuovo e non ci sono ancora metodi “best practice”. Per contribuire a plasmare l’intuizione su diversi approcci di rilevamento della variazione delle incorporazioni, abbiamo condotto una serie di esperimenti. In questo articolo, forniremo una panoramica dei metodi che abbiamo valutato e presenteremo Evidently, una libreria open-source Python per rilevare la variazione delle incorporazioni, tra le altre cose.
Fondamenti del rilevamento della variazione
L’idea alla base del rilevamento della variazione è di ottenere un avviso quando “i dati cambiano significativamente”. L’attenzione è rivolta all’intera distribuzione.
Ciò è diverso dal rilevamento degli outlier, quando si vogliono rilevare i singoli punti dati che differiscono dal resto.
Per misurare la variazione, è necessario decidere quale è il tuo dataset di riferimento. Spesso, è possibile confrontare i tuoi dati di produzione attuali con i dati di convalida o con un periodo passato che si considera rappresentativo. Ad esempio, è possibile confrontare i dati di questa settimana con quelli della settimana precedente e spostare il riferimento man mano che si procede.
Questa scelta è specifica del caso d’uso: è necessario formulare un’aspettativa su quanto stabili o volatili siano i tuoi dati e scegliere i dati di riferimento che catturino adeguatamente ciò che ci si aspetta sia una distribuzione “tipica” dei dati di input e delle risposte del modello.
È inoltre necessario scegliere il metodo di rilevamento della variazione e regolare la soglia di avviso. Ci sono diversi modi per confrontare i dataset tra loro e i gradi di variazione che si considerano significativi. A volte ti preoccupi per una piccola deviazione e a volte solo per una spostamento significativo. Per regolarlo, è possibile modellare il proprio framework di rilevamento della variazione utilizzando dati storici o, alternativamente, partire da un valore di default sensato e poi regolarlo man mano che si procede.
Veniamo ai dettagli su “come”. Diciamo che stai lavorando con un caso d’uso di classificazione del testo e vuoi confrontare come i tuoi dataset (rappresentati come incorporazioni) cambiano settimana dopo settimana. Hai due dataset di incorporazioni da confrontare. Come misuri esattamente la “differenza” tra di essi?
Esamineremo le cinque possibili approcci.
Distanza euclidea
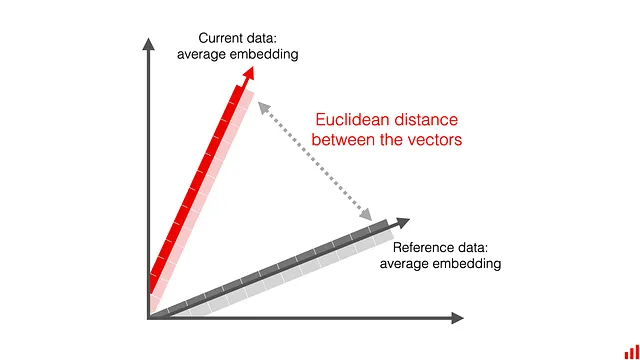
Puoi calcolare la media dei due embedding e ottenere un embedding rappresentativo per ogni dataset. Successivamente, misuri la distanza euclidea tra di essi. In questo modo, confronti “quanto distanti” sono due vettori l’uno dall’altro in uno spazio multidimensionale.
La distanza euclidea è una metrica diretta e familiare: misura la lunghezza della linea che connette i due embedding. Ci sono anche altre metriche di distanza che puoi utilizzare, come la distanza Cosine, Manhattan o Chebyshev.
Come punteggio di drift, riceverai un numero che può variare da 0 (per embedding identici) all’infinito. Più il valore è alto, più distanti sono i due insiemi di dati.
Questo comportamento è intuitivo, ma uno svantaggio possibile è che la distanza euclidea è una misura assoluta. Ciò rende più difficile impostare una soglia di allarme specifica per il drift: la definizione di “lontano” varierà in base al caso d’uso e al modello di embedding utilizzato. Devi regolare la soglia individualmente per i diversi modelli che monitori.
Distanza Cosine
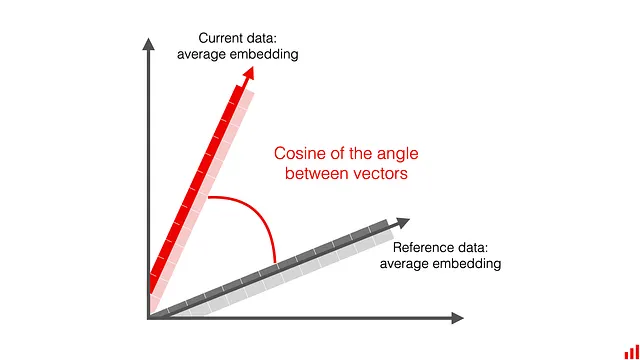
La distanza Cosine è un’altra popolare metrica di distanza. Invece di misurare la “lunghezza”, calcola il coseno dell’angolo tra i vettori.
La similarità Cosine è ampiamente utilizzata nell’apprendimento automatico in compiti come la ricerca, il recupero delle informazioni o i sistemi di raccomandazione. Per misurare la distanza, devi sottrarre il coseno da 1.
Distanza Cosine = 1 — Similarità Cosine
Se i due insiemi di dati sono uguali, la similarità Cosine sarà 1 e la distanza sarà 0. La distanza può assumere valori da 0 a 2.
Nelle nostre esperienze, abbiamo scoperto che la soglia potrebbe non essere molto intuitiva da regolare, poiché può assumere valori anche bassi come 0,001 per un cambiamento che vuoi già rilevare. Scegli saggiamente la soglia! Un altro svantaggio è che non funziona se si applicano metodi di riduzione della dimensionalità come PCA, portando a risultati imprevedibili.
Rilevamento di drift basato sul modello

Il metodo di rilevamento di drift basato sul classificatore segue un’idea diversa. Invece di misurare la distanza tra le medie degli embedding, puoi addestrare un modello di classificazione che cerca di identificare a quale distribuzione appartiene ogni embedding.
Se il modello può prevedere con sicurezza da quale distribuzione proviene l’embedding specifico, è probabile che i due insiemi di dati siano sufficientemente diversi.
Puoi misurare lo score ROC AUC del modello di classificazione calcolato su un dataset di validazione come punteggio di drift e impostare di conseguenza una soglia. Uno score superiore a 0,5 mostra almeno qualche potere predittivo e uno score di 1 corrisponde a “drift assoluto” quando il modello può sempre identificare a quale distribuzione appartengono i dati.
Puoi leggere di più sul metodo nel paper “Failing Loudly: An Empirical Study of Methods for Detecting Dataset Shift”.
In base alle nostre esperienze, questo metodo è un’ottima scelta predefinita. Funziona in modo coerente per diversi insiemi di dati e modelli di embedding che abbiamo testato, sia con che senza PCA. Ha anche una soglia intuitiva con cui qualsiasi data scientist è familiare.
Percentuale di componenti derivati
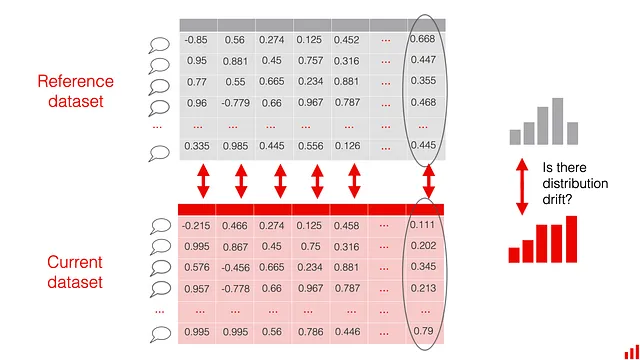
L’idea alla base di questo metodo è quella di trattare gli embedding come dati tabulari strutturati e applicare metodi numerici di rilevamento di drift, come quelli che si utilizzano per rilevare il drift in funzionalità numeriche. Le singole componenti di ogni embedding sono trattate come “colonne” in un dataset strutturato.
Certo, a differenza delle caratteristiche numeriche, queste “colonne” non hanno significato interpretabile. Sono alcune coordinate del vettore di input. Tuttavia, è comunque possibile misurare quante di queste coordinate si disperdono. Se molte si disperdono, è probabile che ci sia un cambiamento significativo nei dati.
Per applicare questo metodo, prima devi calcolare la dispersione in ogni componente. Nei nostri esperimenti, abbiamo utilizzato la distanza di Wasserstein (Earth-Mover) con la soglia del 0,1. L’intuizione dietro a questa metrica è che quando imposti la soglia a 0,1, noterai i cambiamenti nelle dimensioni delle “deviazioni standard del 0,1” di un valore specifico.
Poi puoi misurare la quota complessiva delle componenti che si disperdono. Ad esempio, se la lunghezza del tuo vettore è di 400, puoi impostare la soglia al 20%. Se oltre 80 componenti si disperdono, riceverai un avviso di rilevamento della dispersione.
Il vantaggio di questo metodo è che puoi misurare la dispersione su una scala da 0 a 1. Puoi anche riutilizzare tecniche familiari che potresti già usare per rilevare la dispersione dei dati tabulari. (Ci sono diversi metodi come la divergenza K-L o vari test statistici).
Tuttavia, per alcuni questo potrebbe essere un limite: hai molti parametri da impostare. Puoi regolare il metodo di rilevamento della dispersione sottostante, la sua soglia e la quota di componenti che si disperdono da cui reagire.
Tutto sommato, riteniamo che questo metodo abbia i suoi meriti: è anche coerente con diversi modelli di incorporamento e ha una velocità di calcolo ragionevole.
Massima discrepanza media (MMD)
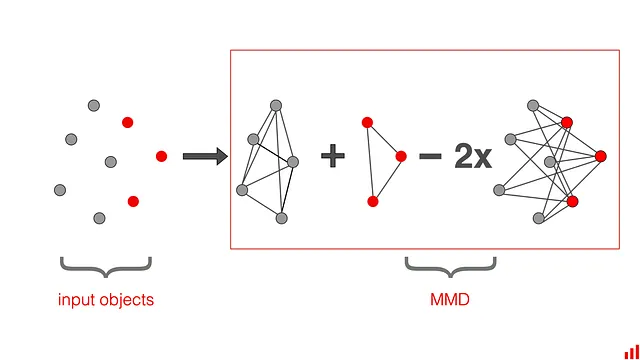
Puoi usare MMD per misurare la distanza multidimensionale tra le medie dei vettori. L’obiettivo è distinguere tra due distribuzioni di probabilità p e q basate sulle medie di incorporamento µp e µq delle distribuzioni nello spazio di Hilbert del kernel di riproduzione F.
Formalmente:
Ecco un altro modo per rappresentare MMD, dove K è uno spazio di Hilbert del kernel di riproduzione:
Puoi pensare a K come a una misura di vicinanza. Più gli oggetti sono simili, maggiore è questo valore. Se le due distribuzioni sono uguali, MMD dovrebbe essere 0. Se le due distribuzioni sono diverse, MMD aumenterà.
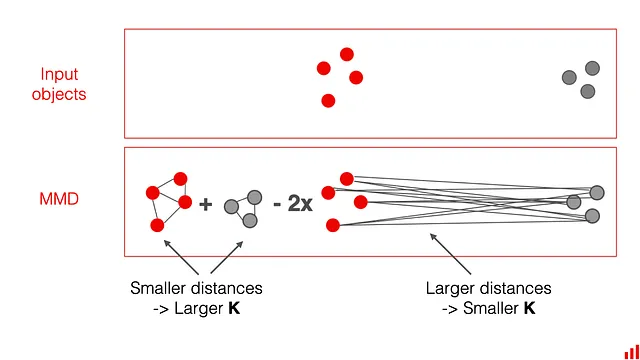
Puoi leggere di più nell’articolo “Un metodo di kernel per il problema a due campioni”.
Puoi usare la misura MMD come punteggio di dispersione. Lo svantaggio di questo approccio è che molti non sono familiari con il metodo e la soglia non è interpretabile. Il calcolo di solito richiede più tempo rispetto ad altri metodi. Ti consigliamo di usarlo se hai una ragione e una solida comprensione della matematica alla base.
Quale metodo scegliere?
Per dare un’idea dei metodi, abbiamo eseguito una serie di esperimenti introducendo uno spostamento artificiale in tre set di dati e stimando i risultati di dispersione man mano che aumentavamo lo spostamento. Abbiamo anche testato la velocità di calcolo.
Puoi trovare tutto il codice e i dettagli degli esperimenti in un blog separato.
Ecco le nostre suggerimenti:
- La rilevazione della dispersione basata sul modello e l’uso della curva ROC AUC come soglia di rilevazione della dispersione sono un’ottima scelta predefinita.
- Il tracciamento della quota di componenti di incorporamento dispersi su una scala da 0 a 1 è al secondo posto. Ricorda solo di regolare le soglie se applichi una riduzione della dimensionalità.
- Se vuoi misurare la “dimensione” della dispersione nel tempo, una metrica come la distanza euclidea è una buona scelta. Tuttavia, devi decidere come progettare l’allerta poiché gestirai valori di distanza assoluti.

È importante tenere a mente che il rilevamento della deriva è un euristico. È un proxy per possibili problemi. Potrebbe essere necessario sperimentare l’approccio: non solo scegliere il metodo ma anche regolare la soglia per i propri dati. È inoltre necessario riflettere sulla scelta della finestra di riferimento e fare un’assunzione informata su quale cambiamento si considera significativo. Questo dipenderà dalla tolleranza agli errori, dal caso d’uso e dalle aspettative su quanto bene il modello si generalizza.
Puoi anche separare il rilevamento della deriva dal debugging. Una volta ricevuto l’allarme sulla possibile deriva dell’embedding, il passo successivo è indagare su cosa è cambiato esattamente. In questo caso, devi inevitabilmente guardare indietro ai dati grezzi.
Se possibile, puoi persino iniziare valutando la deriva nei dati grezzi in primo luogo. In questo modo, puoi ottenere informazioni preziose: come identificare le parole principali che aiutano il modello di classificazione a decidere a quale distribuzione appartengono i testi, o tracciare descrittori di testo interpretabili – come la lunghezza o la quota di parole OOV.

Evidently open-source
Abbiamo implementato tutti i metodi di rilevamento della deriva menzionati in Evidently, una libreria Python open-source per valutare, testare e monitorare i modelli di machine learning.
Puoi eseguirlo in qualsiasi ambiente Python. Basta passare un DataFrame, selezionare quali colonne contengono gli embedding e scegliere il metodo di rilevamento della deriva (o andare con i valori predefiniti!) Puoi anche implementare questi controlli come parte di una pipeline e utilizzare altri 100+ controlli per la qualità dei dati e del modello.
Puoi esplorare il tutorial di avvio per capire le capacità di Evidently o passare direttamente a un esempio di codice sul rilevamento della deriva dell’embedding.
Conclusioni
- Il rilevamento della deriva è uno strumento prezioso per il monitoraggio dei modelli di machine learning in produzione. Aiuta a rilevare i cambiamenti nei dati di input e nelle previsioni del modello. Puoi fare affidamento su di esso come indicatore proxy della qualità del modello e come modo per segnalare potenziali cambiamenti.
- Il rilevamento della deriva non si limita a lavorare con dati tabulari. Puoi anche monitorare la deriva negli embedding di machine learning, ad esempio quando esegui applicazioni NLP o LLM-based.
- In questo articolo, abbiamo presentato 5 diversi metodi per il monitoraggio degli embedding, tra cui la distanza euclidea e coseno, la discrepanza massima media, il rilevamento della deriva basato sul modello e il tracciamento della quota di embedding derivate utilizzando metodi numerici di rilevamento della deriva. Tutti questi metodi sono implementati nella libreria Python open-source Evidently.
- Raccomandiamo il rilevamento della deriva basato sul modello come approccio predefinito sensato. Ciò è dovuto alla capacità di utilizzare il punteggio ROC AUC come misura interpretabile di rilevamento della deriva che è facile da regolare e lavorare. Questo metodo funziona anche in modo coerente su diversi dataset e modelli di embedding, il che lo rende conveniente da usare nella pratica in diversi progetti.
Questo articolo si basa sulla ricerca pubblicata sul blog di Evidently. Grazie a Olga Filippova per aver coautore l’articolo.





