Serie temporali per il cambiamento climatico previsione della domanda origine-destinazione
Time series for climate change, demand forecasting, origin-destination.
L’estrazione dei dati dei veicoli per contrastare il cambiamento climatico
Questo è il Parte 8 della serie Time Series per il cambiamento climatico. Elenco degli articoli:
- Parte 1: Previsione dell’energia eolica
- Parte 2: Previsione dell’irraggiamento solare
- Parte 3: Previsione di grandi onde oceaniche
- Parte 4: Previsione della domanda di energia
- Parte 5: Previsione degli eventi meteorologici estremi
- Parte 6: Utilizzo del Deep Learning per l’agricoltura di precisione
- Parte 7: Riduzione degli sprechi alimentari con il clustering
I dati dei veicoli per la modellizzazione della mobilità
L’estrazione dei dati dei veicoli è un compito chiave nei sistemi di trasporto intelligenti. I dati dei veicoli fluttuanti si riferiscono ai dati raccolti dai veicoli dotati di dispositivi GPS. Questi dispositivi forniscono informazioni sulla posizione e sulla velocità dei veicoli.
La comprensione dei modelli di mobilità all’interno delle città è un compito importante nel trasporto. Ad esempio, aiuta a ridurre la congestione e l’attività di trasporto complessiva. Meno tempo nel traffico significa meno gas serra emessi. Quindi, i modelli accurati hanno un impatto positivo sul cambiamento climatico.
La diffusione dei dispositivi GPS ha prodotto molti set di dati relativi alla mobilità. Tuttavia, imparare dai dati GPS è un problema difficile. Le dipendenze spaziali sono difficili ma fondamentali da catturare. Ci sono anche dipendenze temporali, ad esempio, le ore di punta. I modelli di mobilità differiscono anche a seconda che sia un giorno feriale o meno.
- 10 Plugin di ChatGPT per la Scheda di Trucchi della Scienza dei Dati
- La sfida di comprendere l’immagine complessiva di AI.
- Evitare il Burnout durante il cambio di carriera in Data Science
Stimare il flusso di origine e destinazione

I dati dei veicoli fluttuanti offrono molte possibilità per la modellizzazione della mobilità. Una di queste possibilità è il problema del conteggio del flusso di origine-destinazione (OD).
Il conteggio del flusso OD si riferisce alla stima di quante auto attraversano una data sottoregione per raggiungere un’altra in un dato periodo. Questo compito è rilevante per diverse ragioni. Le compagnie di taxi possono allocare dinamicamente la loro flotta in base alla domanda prevista in una particolare zona.
Pratico: Prevedere la domanda OD a San Francisco
Nel resto di questo articolo, prevedremo la domanda di passeggeri dei taxi a San Francisco, USA. Affronteremo questo problema come un compito di conteggio del flusso OD.
Il codice completo utilizzato in questo tutorial è disponibile su Github:
- https://github.com/vcerqueira/tsa4climate
Insieme di dati
Utilizzeremo un insieme di dati raccolti da una flotta di taxi a San Francisco, California, USA. L’insieme di dati contiene dati GPS di 536 taxi per un periodo di 21 giorni. In totale, ci sono 121 milioni di tracce GPS divise in 464045 viaggi. Puoi controllare il riferimento [1] per ulteriori dettagli.
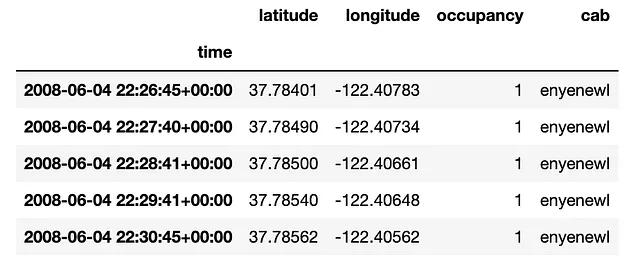
Ad ogni passo temporale e per ogni taxi, abbiamo informazioni sulle sue coordinate e se un passeggero lo occupa.
Definizione del problema
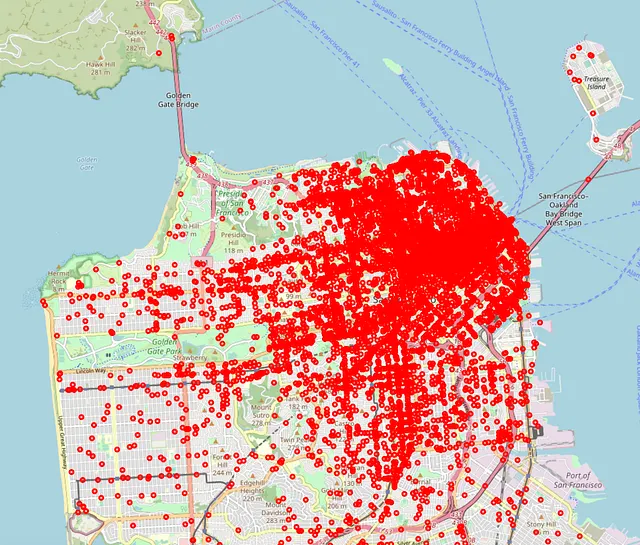
Il nostro obiettivo è modellare dove le persone si spostano date le loro origini. La stima del conteggio del flusso OD può essere divisa in quattro sottotasks:
- Decomposizione della griglia spaziale
- Selezione delle coppie origine-destinazione
- Discretizzazione temporale
- Modellazione e previsione
Approfondiamo ogni problema in ordine.
Decomposizione della griglia spaziale
La decomposizione spaziale è una comune fase di pre-elaborazione per la stima del flusso delle OD. L’idea è quella di suddividere la mappa in celle di griglia, che rappresentano una piccola parte della città. Quindi, possiamo contare quanti individui attraversano ogni possibile coppia di celle di griglia.
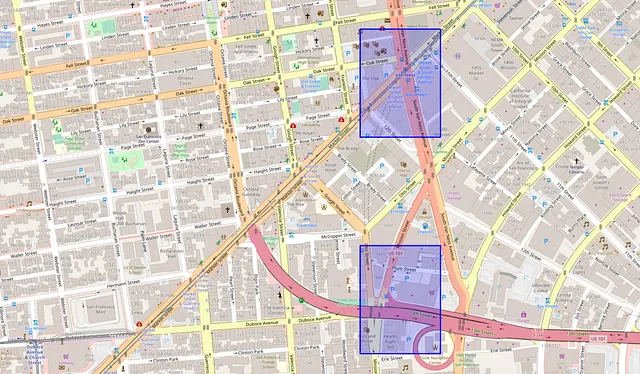
In questo caso di studio, abbiamo suddiviso la mappa della città in 10000 celle di griglia come segue:
import pandas as pdfrom src.spatial import SpatialGridDecomposition, prune_coordinates# lettura del datasettrips_df = pd.read_csv('trips.csv', parse_dates=['time'])# rimozione dei dati anomalistitrips_df = prune_coordinates(trips_df=trips_df, lhs_thr=0.01, rhs_thr=0.99)# decomposizione della griglia con 10000 cellegrid = SpatialGridDecomposition(n_cells=10000)# impostazione del bounding boxgrid.set_bounding_box(lat=trips_df.latitude, lon=trips_df.longitude)# decomposizione della grigliagrid.grid_decomposition()Nel codice sopra, rimuoviamo le posizioni anomale. Queste possono verificarsi a causa di malfunzionamenti del GPS.
Ottenere i viaggi più popolari
Dopo il processo di decomposizione spaziale, otteniamo l’origine e la destinazione di ogni viaggio in taxi quando sono occupati da un passeggero.
from src.spatial import ODFlowCounts# ottenere le coordinate di origine e destinazione per ogni viaggiodf_group = trips_df.groupby(['cab', 'cab_trip_id'])trip_points = df_group.apply(lambda x: ODFlowCounts.get_od_coordinates(x))trip_points.reset_index(drop=True, inplace=True)L’idea è quella di ricostruire il dataset per contenere le seguenti informazioni: origine, destinazione e timestamp di origine di ogni viaggio dei passeggeri. Questi dati costituiscono la base per il nostro modello di conteggio del flusso origine-destinazione (OD).
Questi dati ci consentono di contare quanti viaggi vanno dalla cella A alla cella B:
# ottenere il centroide delle celle di origine e destinazioneod_pairs = trip_points.apply(lambda x: ODFlowCounts.get_od_centroids(x, grid.centroid_df), axis=1)Per semplicità, otteniamo le prime 50 coppie di celle di griglia OD con il maggior numero di viaggi. Prendere questo sottoinsieme è facoltativo. Tuttavia, le coppie OD con pochi viaggi mostreranno una domanda sparsa nel tempo, che è difficile da modellare. Inoltre, i viaggi con bassa domanda potrebbero non essere utili dal punto di vista della gestione della flotta.
flow_count = od_pairs.value_counts().reset_index()flow_count = flow_count.rename({0: 'count'}, axis=1)top_od_pairs = flow_count.head(50)Discretizzazione temporale
Dopo aver individuato le migliori coppie OD in termini di domanda, le discretizziamo nel tempo. Ciò viene fatto contando quanti viaggi avvengono in ogni ora per ogni coppia principale. Ciò può essere fatto come segue:
# preparazione dei dati trip_points = pd.concat([trip_points, od_pairs], axis=1)trip_points = trip_points.sort_values('time_start')trip_points.reset_index(drop=True, inplace=True)# ottenere le celle di origine e destinazione per ogni viaggio e l'ora di inizio dell'originetrip_starts = []for i, pair in top_od_pairs.iterrows(): origin_match = trip_points['origin'] == pair['origin'] dest_match = trip_points['destination'] == pair['destination'] od_trip_df = trip_points.loc[origin_match & dest_match, :] od_trip_df.loc[:, 'pair'] = i trip_starts.append(od_trip_df[['time_start', 'time_end', 'pair']])trip_starts_df = pd.concat(trip_starts, axis=0).reset_index(drop=True)# ulteriore elaborazione dei datiod_count_series = {}for pair, data in trip_starts_df.groupby('pair'): new_index = pd.date_range( start=data.time_start.values[0], end=data.time_end.values[-1], freq='H', tz='UTC' ) od_trip_counts = pd.Series(0, index=new_index) for _, r in data.iterrows(): dt = r['time_start'] - new_index dt_secs = dt.total_seconds() valid_idx = np.where(dt_secs >= 0)[0] idx = valid_idx[dt_secs[valid_idx].argmin()] od_trip_counts[new_index[idx]] += 1 od_count_series[pair] = od_trip_counts.resample('H').mean()od_df = pd.DataFrame(od_count_series)Ciò porta ad un insieme di serie temporali, una per ogni coppia OD principale. Ecco il grafico delle serie temporali per quattro coppie di esempio:
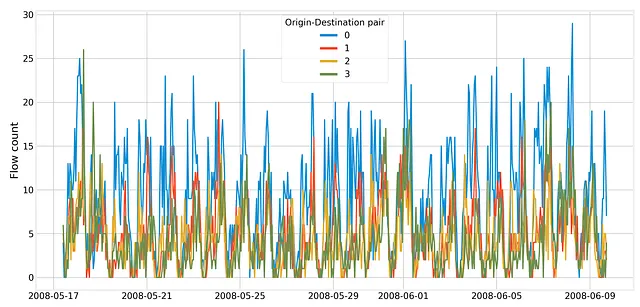
Le serie temporali mostrano una stagionalità giornaliera, che è per lo più determinata dalle ore di punta.
Previsione
L’insieme di serie temporali che deriva dalla discretizzazione temporale può essere utilizzato per la previsione. Possiamo costruire un modello per prevedere quanti passeggeri vogliono effettuare il viaggio relativo ad una data coppia OD.
Ecco come si può fare per una coppia OD di esempio:
from pmdarima.arima import auto_arima# prendiamo la prima coppia OD come esempioserie = od_df[0].dropna()# costruiamo un modello ARIMAmodel = auto_arima(y=series, m=24)Sopra, abbiamo costruito un modello di previsione basato su ARIMA. Il modello prevede la domanda di passeggeri nell’ora successiva data la domanda recente del passato. Usiamo il metodo ARIMA per semplicità, ma possono essere utilizzati altri approcci come il deep learning.
Approfondire con le reti neurali grafiche
L’approccio sopra descritto è un modo semplice ma efficace per risolvere i problemi di conteggio del flusso OD. Tuttavia, considera ogni coppia OD come una serie temporale separata.
In realtà, ogni coppia è correlata con le coppie OD vicine o le strade circostanti. A causa di ciò, le reti neurali grafiche sono sempre più utilizzate per prevedere le condizioni del traffico. La rete stradale viene modellata come un grafo e le reti neurali possono catturare interazioni complesse al suo interno. Puoi controllare questo esempio di Keras per imparare come implementare questo tipo di metodo.
Punti chiave
- La modellizzazione della mobilità è un compito importante nei sistemi di trasporto intelligente;
- I modelli di conteggio del flusso OD possono aiutare a ridurre il traffico nelle città, riducendo così le emissioni di gas serra;
- Puoi affrontare i problemi di conteggio del flusso OD con un approccio basato sulla decomposizione spaziale e sulla discretizzazione temporale. Ciò porta ad un insieme di serie temporali per ogni coppia OD, che possono essere utilizzate per la previsione.
Grazie per la lettura, e ci vediamo nella prossima storia!
Riferimenti
[1] Dataset di tracce di mobilità di taxi a San Francisco, USA. (Licenza CC BY 4.0)
[2] Moreira-Matias, Luís, et al. “Time-evolving OD matrix estimation using high-speed GPS data streams.” Expert systems with Applications 44 (2016): 275-288.





