Sfruttare l’apprendimento automatico per lo sviluppo di una strategia di marketing efficace
Usare l'apprendimento automatico per una strategia di marketing efficace
Consigli e trucchi per la costruzione di una strategia di marketing di successo utilizzando l’Apprendimento Automatico

I modelli di attribuzione del marketing sono ampiamente utilizzati oggi per la costruzione di strategie di marketing. Le strategie si basano sull’assegnazione del credito a ciascun punto di contatto lungo tutti i percorsi dei clienti. Esistono molti tipi diversi di modelli, anche se possono essere classificati in 2 gruppi: modelli di attribuzione a singolo punto di contatto e modelli di attribuzione a più punti di contatto. Di solito, è possibile interpretare e implementare facilmente questi modelli. Possono essere persino utili in casi rari. Tuttavia, la maggior parte di essi non è in grado di costruire autonomamente una solida strategia di marketing. Il problema sta nel fatto che tutti questi modelli operano basandosi su regole che potrebbero non essere applicabili a determinati dati/settori, oppure si basano su una quantità limitata di dati, portando a una perdita di preziose informazioni. Per saperne di più sui tipi di modelli di attribuzione del marketing, consulta il mio articolo precedente.
Oggi vorrei discutere di come abbiamo utilizzato l’apprendimento automatico per sviluppare una strategia di marketing, i dati che abbiamo utilizzato e i risultati che abbiamo ottenuto. In questo articolo affronteremo le seguenti domande:
- Dove è meglio ottenere i dati?
- Come preparare i dati per l’addestramento del modello?
- Come utilizzare efficacemente le previsioni del modello e trarre conclusioni significative?
Presenterò tutto questo utilizzando i dati di uno dei nostri clienti, con alcune parti modificate. Queste modifiche non influenzeranno i risultati complessivi. Chiamiamo questa azienda XYZ. La pubblicazione di questi dati è stata autorizzata dal cliente.
Dati
Esistono diversi modi per ottenere i log del traffico dai siti web. Questi metodi non sempre forniscono informazioni esaustive che potresti richiedere per l’analisi. Tuttavia, a volte è possibile integrare una fonte in un’altra, mentre altre volte è possibile accumulare e combinare manualmente i dati da più fonti. Puoi anche scrivere script tu stesso per raccogliere le informazioni necessarie. Ora, parliamo un po’ delle fonti attualmente più richieste e dei dati che puoi ottenere da esse:
- Optimizzazione del controllore PID Un approccio di discesa del gradiente
- Input vocale e linguaggio naturale per la tua app mobile utilizzando LLM
- Introduzione alle rappresentazioni di frasi dell’IA
Google Analytics
Google Analytics (GA4) è una piattaforma potente che ti offre accesso a diversi strumenti di analisi del sito web e ti consente di misurare l’interazione e il traffico delle tue app e siti web. Di solito utilizza l’attribuzione dell’ultimo clic, tuttavia puoi costruire il tuo modello di attribuzione personalizzato utilizzando i seguenti dati GA4:
- eventi automatici (come ad_click, ad_impression, app_exception, file_download, first_visit, page_view, ecc.);
- misurazioni migliorate (scroll, click, video_start, video_progress, ecc.);
- eventi consigliati (add_to_cart, begin_checkout, add_payment_info, purchase, add_to_wishlist, ecc.);
- eventi personalizzati.
Google Analytics offre eventi diversi per settori diversi.
Meta Pixel
Meta Pixel è uno strumento che ti consente di tracciare la promozione degli annunci e l’attività dei visitatori sul tuo sito web. Ti fornisce alcune informazioni su come il tuo pubblico interagisce con i tuoi annunci su Facebook e Instagram e dati su come questi utenti si comportano sul tuo sito web dopo aver cliccato su un annuncio. In generale, otterrai gli stessi dati che ottieni quando utilizzi Google Analytics. Tuttavia, Meta Pixel è più focalizzato sul retargeting, quindi avrai più strumenti per quello rispetto a Google Analytics.
Yandex Metrika
Yandex Metrika ha le stesse caratteristiche dei servizi sopra citati. Tuttavia, ha i suoi pro e contro. Come svantaggio, Yandex Metrika ha un limite di richieste elaborate da un singolo account (5.000 richieste/giorno). Allo stesso tempo, Google Analytics ha un limite di 200.000 richieste/giorno. E il vantaggio è che Yandex Metrika ha Webvisor, che ti aiuta a ottenere tutti i movimenti del mouse.
Non sono tutti i servizi disponibili che puoi utilizzare per ottenere i dati degli utenti. Anche se ogni fonte di dati rappresenta molti tipi di dati, quindi quando scegli una fonte di dati, puoi prestare attenzione a fattori come la facilità di configurazione dei report e l’integrazione con altri prodotti. Abbiamo scelto Google Analytics (GA4) perché fornisce dati completi e strumenti convenienti. Inoltre, i dati si integrano facilmente con BigQuery e utilizziamo l’infrastruttura di Google Cloud. Quindi i dati grezzi sono i seguenti:
Preparazione dei dati
Tornando al compito in questione, il nostro obiettivo è determinare quali campagne pubblicitarie sono più attraenti per gli investimenti al fine di ridurre le spese nell’allocazione del budget mantenendo o aumentando i livelli di ricavo. Pertanto, la rappresentazione dei dati di GA4 è conveniente per noi perché contiene informazioni su ogni azione/contatto dell’utente, come:
- Clic sui pulsanti
- Scorrimento
- Visualizzazioni di foto
- Ricerche, ecc.
A loro volta, tutte queste azioni possono essere ulteriormente trasformate in micro-conversioni, che è esattamente ciò di cui abbiamo bisogno. Utilizzeremo questo insieme di micro-conversioni per prevedere la probabilità che un utente effettui un acquisto in ogni sessione.
Nel risolvere un compito del genere, le seguenti micro-conversioni possono essere di interesse:
- Visita alla pagina di vendita
- Visualizzazione di prodotti popolari o chiave
- Ricerca di una specifica taglia
- Visualizzazione delle foto del prodotto
- Visualizzazione di tutte le foto del prodotto
- Revisione delle informazioni sulle modalità di cura del prodotto
- Aggiunta di un prodotto al carrello, ecc.
In realtà, è possibile creare qualsiasi numero di micro-conversioni personalizzate. La scelta delle micro-conversioni dipende molto dalle caratteristiche specifiche del tuo negozio/attività.
Alla fine, abbiamo scelto le seguenti caratteristiche e micro-conversioni per il nostro modello. Il numero totale di tutte le nostre caratteristiche è 97. Questo è il sottoinsieme delle nostre caratteristiche:
Puoi vedere molte caratteristiche connesse a UTM, che significano quanto segue:
- utm_source è il nome della piattaforma o dello strumento utilizzato per creare il VoAGI;
- utm_VoAGI identifica il tipo o il canale di alto livello del traffico;
- utm_campaign è il nome della campagna di marketing;
- le altre funzionalità utm si riferiscono al primo punto di contatto all’interno del percorso dell’utente o della sessione.
Torniamo alla discussione sulle altre caratteristiche. Alcune delle colonne sono disponibili nei dati grezzi, quindi non devi fare nulla con esse. Tuttavia, alcune colonne non sono pronte per l’uso e devi prima eseguire alcune manipolazioni. Ecco un esempio di come abbiamo ottenuto una micro-conversione, come l’aggiunta di un prodotto al carrello:
Modello
Vorrei ricordarti che utilizzando il modello, vogliamo ottenere la probabilità che un utente effettui un acquisto in ogni punto di contatto. Quindi, convertiremo questo in probabilità di effettuare un acquisto all’interno di una sessione. Pertanto, abbiamo utilizzato un modello di classificazione in cui abbiamo utilizzato predict_proba per ottenere la probabilità di acquisto in ogni interazione dell’utente. Dopo aver provato diversi modelli, dal lineare all’addestramento, abbiamo deciso di utilizzare il CatBoostClassifier. Prima di implementare e ritracciare il modello quotidianamente, è stata eseguita una messa a punto degli iperparametri. Non entreremo nei dettagli della creazione del modello poiché abbiamo seguito un approccio classico di messa a punto degli iperparametri, addestramento successivo del modello e calcolo delle metriche rilevanti.
Attualmente il modello viene addestrato utilizzando i dati di un mese, poiché il cambiamento di questa durata a un periodo più lungo o più breve non ha mostrato un miglioramento significativo. Inoltre, utilizziamo una soglia 0.1 per determinare un acquisto. Abbiamo specificamente utilizzato questo valore perché è 10 volte superiore alla probabilità di acquisto di base del nostro cliente. Questo ci serve come trigger per considerare questi eventi e indagare se è stato effettuato un acquisto e, se no, perché. In altre parole, tutte le azioni in cui la probabilità del modello > 0.1 vengono classificate come un acquisto. Di conseguenza, abbiamo ottenuto i seguenti valori per le metriche di richiamo e accuratezza:
Richiamo sul TEST: 0.947
Accuratezza sul TEST: 0.999In base alle metriche ottenute, possiamo vedere che stiamo ancora perdendo alcuni acquisti. È possibile che i percorsi per questi acquisti differiscano dal tipico percorso dell’utente.
Quindi, abbiamo tutte le caratteristiche e le probabilità del modello e ora vogliamo creare un rapporto e capire quali campagne pubblicitarie sono sottostimate e quali sono sovrastimate. Per ottenere la campagna pubblicitaria, combiniamo le caratteristiche utm_source, utm_VoAGI e utm_campaign. Quindi, prenderemo la probabilità massima all’interno di ogni sessione dell’utente e la moltiplicheremo per il valore medio dell’ordine nello stesso periodo temporale del dataset di test. Successivamente, genereremo un rapporto calcolando la somma per ogni campagna pubblicitaria.
Ci fornisce il seguente rapporto:
Ora dobbiamo passare alle metriche di marketing. Poiché vogliamo misurare il successo delle campagne di marketing, possiamo considerare le seguenti metriche, spesso utilizzate dai marketer:
- ROAS (Return on Ad Spend) è una metrica di marketing che misura l’efficacia di una campagna di pubblicità digitale;
- CRR (Cost Revenue Ratio) misura il rapporto tra le spese operative e i ricavi generati da un’attività.
Le calcoleremo utilizzando i nostri dati e le confrontiamo con i valori ROAS e CRR che i marketer ottengono tipicamente utilizzando l’attribuzione all’ultimo clic.
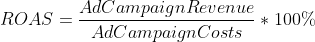
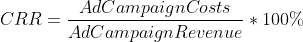
Dato che vediamo solo tre campagne a pagamento nel periodo analizzato, troveremo le metriche per queste campagne in GA4 e aggiungeremo il ROAS e il CRR basati sull’attribuzione all’ultimo clic. Abbiamo discusso il motivo per cui l’attribuzione all’ultimo clic non è un approccio esatto per valutare il contributo della campagna pubblicitaria nell’articolo precedente.
E utilizzando le formule sopra menzionate, calcoleremo il rapporto finale con il ROAS e il CRR previsti:
Ora abbiamo tutti i dati per trarre conclusioni sulle campagne pubblicitarie:
- Possiamo vedere che la campagna “google/cpc/mg_ga_brand_all_categories_every_usa_0_rem_s_bas” è sopravvalutata, poiché il suo ROAS previsto è due volte inferiore al ROAS basato sull’attribuzione all’ultimo clic. Molto probabilmente, gli utenti spesso effettuano acquisti dopo aver fatto clic su questa campagna pubblicitaria, ma sono già clienti fidelizzati.
- La campagna pubblicitaria “instagram / cpc / 010323_main” è sottovalutata, poiché il suo ROAS previsto è quattro volte superiore al ROAS effettivo.
- E la campagna “google / cpc / mg_ga_brand_all_categories_every_latvia_0_rem_s_bas” ha un ROAS previsto simile al ROAS effettivo.
E con questi dati, puoi sviluppare autonomamente strategie di marketing per il prossimo periodo. Inoltre, non devi dimenticare che le strategie di marketing richiedono test. Tuttavia, questo va oltre l’ambito del nostro articolo.
In questo articolo, abbiamo discusso come l’apprendimento automatico può essere utilizzato per creare una strategia di marketing. Abbiamo affrontato il tema della selezione dei dati, la preelaborazione dei dati per la modellizzazione, il processo di modellizzazione stesso e l’ottenimento di informazioni dai risultati ottenuti. Se stai lavorando anche a un compito simile, gli approcci utilizzati da te sarebbero anche di mio interesse.
Grazie per aver letto!
Spero che le informazioni condivise oggi ti siano state utili. Se desideri contattarmi, non esitare a aggiungermi su LinkedIn.






