Introduzione alle rappresentazioni di frasi dell’IA
Introduzione alle rappresentazioni dell'IA
Colmare il divario tra computer e linguaggio: come le incorporazioni di frasi di IA rivoluzionano il NLP
In questo post del blog, cerchiamo di svelare il modo in cui i computer comprendono le frasi e i documenti. Per iniziare questa discussione, faremo un salto indietro nel tempo, partendo dai primi metodi di rappresentazione delle frasi utilizzando vettori n-gram e vettori TF-IDF. Le sezioni successive discuteranno dei metodi che aggregano i vettori delle parole dalle sacche neurali di parole fino ai trasformatori di frasi e ai modelli di linguaggio che vediamo oggi. Ci sono molte tecnologie interessanti da esaminare. Iniziamo il nostro viaggio con gli eleganti e semplici n-grammi.
1. Vettori n-gram
I computer non comprendono le parole, ma comprendono i numeri. Pertanto, dobbiamo convertire parole e frasi in vettori quando vengono processati da un computer. Una delle prime rappresentazioni di una frase come vettore può essere fatta risalire a un articolo del 1948 di Claude Shannon, padre della teoria dell’informazione. In questo lavoro fondamentale, le frasi venivano rappresentate come un vettore n-gram di parole. Cosa significa?
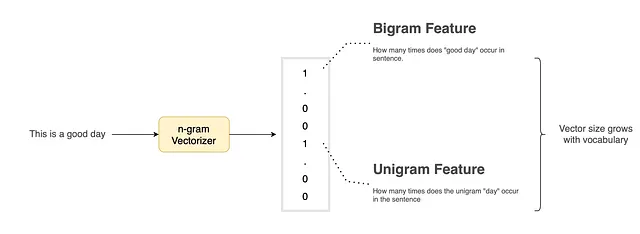
Considera la frase “Questo è un bel giorno”. Possiamo suddividere questa frase nei seguenti n-grammi:
- Unigrammi: Questo, è, un, bel, giorno
- Bigrammi: Questo è, è un, un bel, bel giorno
- Trigrammi: questo è un, è un bel, un bel giorno
- e molti altri…
In generale, una frase può essere scomposta nei suoi n-grammi costituenti, iterando da 1 a n. Nella costruzione del vettore, ogni numero in questo vettore rappresenta se l’n-gramma era presente o meno nella frase. Alcuni metodi potrebbero invece utilizzare il conteggio dell’n-gramma presente nella frase. Una rappresentazione vettoriale di esempio di una frase è mostrata nella Figura 1 sopra.
- Perfeziona il tuo LLM senza sfruttare al massimo la tua GPU
- Calcola facilmente i costi dell’API OpenAI con Tiktoken
- Una guida completa sui termini di interazione nella previsione delle serie temporali
2. TF-IDF
Un altro metodo precoce ma popolare per rappresentare frasi e documenti consisteva nel determinare il vettore TF-IDF di una frase o il “Term Frequency — Inverse Document Frequency”. In questo caso, contavamo il numero di volte che una parola appare nella frase per…






