Pythia Una suite di 16 LLM per la ricerca approfondita
Pythia 16 LLM suite for in-depth research.

Oggi i grandi modelli di linguaggio e i chatbot basati su LLM come ChatGPT e GPT-4 si sono integrati bene nella nostra vita quotidiana.
Tuttavia, i modelli di trasformatori autoaggressivi solo decoder sono stati ampiamente utilizzati per applicazioni generative di NLP molto prima che le applicazioni LLM diventassero mainstream. Può essere utile capire come evolvono durante l’addestramento e come cambia la loro performance man mano che aumentano di dimensioni.
Pythia, un progetto di Eleuther AI, è una suite di 16 grandi modelli di linguaggio che forniscono riproducibilità per lo studio, l’analisi e ulteriori ricerche. Questo articolo è un’introduzione a Pythia.
- Trasformare l’IA con LangChain una rivoluzione nel trattamento dei dati testuali
- Tipi di Assicurazione Medica e Tecnologie Moderne
- Prevenire la cecità degli occhi prevedendo le fasi della retinopatia diabetica
Cosa offre la suite Pythia?
Come accennato, Pythia è una suite di 16 grandi modelli di linguaggio – modelli di trasformatori autoaggressivi solo decoder – addestrati su un dataset pubblicamente disponibile. I modelli della suite hanno dimensioni che vanno da 70M a 12B parametri.
- L’intera suite è stata addestrata sugli stessi dati nello stesso ordine. Ciò facilita la riproducibilità del processo di addestramento. Possiamo quindi non solo replicare il processo di addestramento ma anche analizzare i modelli di linguaggio e studiare il loro comportamento in profondità.
- Offre inoltre strumenti per scaricare i caricatori di dati di addestramento e più di 154 checkpoint di modelli per ciascuno dei 16 modelli di linguaggio.
Dati di addestramento e processo di addestramento
Ora approfondiamo i dettagli della suite Pythia LLM.
Dataset di addestramento
La suite Pythia LLM è stata addestrata sui seguenti dataset:
- Pile dataset con 300B token
- Deduplicate Pile dataset con 207B token
Ci sono 8 diverse dimensioni dei modelli, con i modelli più piccoli e più grandi che hanno rispettivamente 70M e 12B parametri. Le altre dimensioni dei modelli includono 160M, 410M, 1B, 1.4B, 2.8B e 6.9B.
Ogniuno di questi modelli è stato addestrato sia sui dataset Pile che sui dataset Pile duplicati, risultando in un totale di 16 modelli. La tabella seguente mostra le dimensioni dei modelli e un sottoinsieme degli iperparametri.
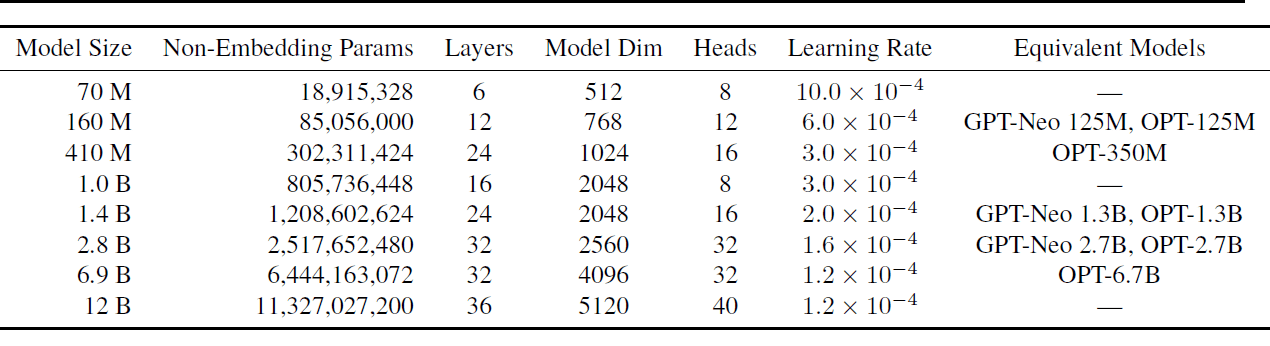
Per tutti i dettagli sugli iperparametri utilizzati, leggere Pythia: una suite per l’analisi di grandi modelli di linguaggio durante l’addestramento e la scalabilità.
Processo di addestramento
Ecco una panoramica dell’architettura e del processo di addestramento:
- Tutti i modelli hanno strati completamente densi e utilizzano attenzione flash.
- Per una maggiore interpretabilità vengono utilizzate matrici di embedding non collegate.
- Viene utilizzata una dimensione del batch di 1024 con una lunghezza della sequenza di 2048. Questa dimensione del batch elevata riduce notevolmente il tempo di addestramento sul clock.
- Il processo di addestramento utilizza anche tecniche di ottimizzazione come il parallelismo dati e tensori.
Per il processo di addestramento viene utilizzata la libreria GPT-Neo-X (che include funzionalità dalla libreria DeepSpeed) sviluppata da Eleuther AI.
Checkpoint dei modelli
Ci sono 154 checkpoint per ciascun modello. C’è un checkpoint ogni 1000 iterazioni. Inoltre, ci sono checkpoint a intervalli logaritmici più precoci nel processo di addestramento: 1, 2, 4, 8, 16, 32, 64, 128, 256 e 512.
Come si confronta Pythia con altri modelli di linguaggio?
La suite Pythia LLM è stata valutata rispetto ai benchmark disponibili di modellazione del linguaggio, inclusa la variante LAMBADA di OpenAI. Si è constatato che le prestazioni di Pythia sono paragonabili ai modelli di linguaggio OPT e BLOOM.
Vantaggi e Limitazioni
Il principale vantaggio della suite Pythia LLM è la riproducibilità. Il dataset è pubblicamente disponibile, così come i caricamenti dei dati pre-tokenizzati e 154 checkpoint del modello. È stata rilasciata anche la lista completa degli iperparametri. Ciò rende più semplice replicare l’addestramento e l’analisi del modello.
Nel [1], gli autori spiegano la loro motivazione nella scelta di un dataset in lingua inglese rispetto a un corpus di testo multilingue. Tuttavia, avere pipeline di addestramento riproducibili per modelli di linguaggio multilingue può essere utile. Specialmente per incoraggiare ulteriori ricerche e studio delle dinamiche dei modelli di linguaggio multilingue di grandi dimensioni.
Una Panoramica dei Case Studies
La ricerca presenta anche interessanti case studies che sfruttano la riproducibilità del processo di addestramento dei modelli di linguaggio di grandi dimensioni nella suite Pythia.
Gender Bias
Tutti i modelli di linguaggio di grandi dimensioni sono soggetti a bias e disinformazione. Lo studio si concentra sulla mitigazione del bias di genere modificando i dati di pretraining in modo che una percentuale fissa abbia pronomi di un genere specifico. Anche questo pretraining è riproducibile.
Memorizzazione
La memorizzazione nei modelli di linguaggio di grandi dimensioni è un’altra area ampiamente studiata. La memorizzazione della sequenza è modellata come un processo di punto di Poisson. Lo studio mira a capire se la posizione della sequenza specifica nel dataset di addestramento influisce sulla memorizzazione. È stato osservato che la posizione non influisce sulla memorizzazione.
Effetto delle Frequenze dei Termini di Pretraining
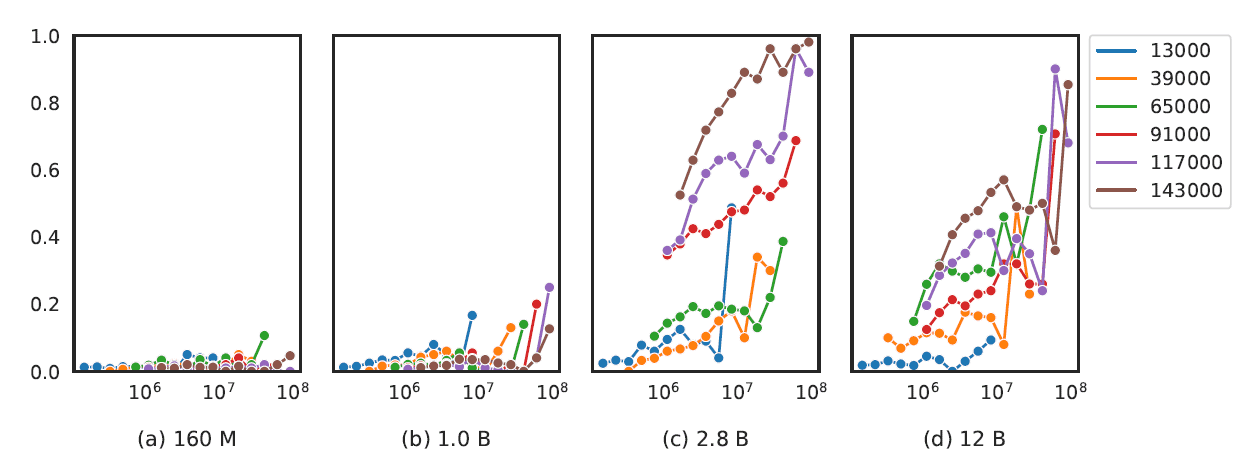
Per i modelli di linguaggio con 2,8 miliardi di parametri e oltre, si è scoperto che la presenza di termini specifici per una determinata attività nel corpus di pretraining migliora le prestazioni del modello su attività come la risposta alle domande.
Esiste anche una correlazione tra la dimensione del modello e le prestazioni su attività più complesse come l’aritmetica e il ragionamento matematico.
Riassunto e Prossimi Passi
Facciamo un riassunto dei punti chiave della nostra discussione.
- Pythia di Eleuther AI è una suite di 16 LLM addestrati su dataset Pile disponibili pubblicamente e dataset Pile deduplicati.
- La dimensione dei LLM varia da 70M a 12B di parametri.
- I dati di addestramento e i checkpoint del modello sono open-source ed è possibile ricostruire gli stessi caricamenti dei dati di addestramento. Quindi la suite LLM può essere utile per comprendere meglio le dinamiche di addestramento dei modelli di linguaggio di grandi dimensioni.
Come prossimo passo, puoi esplorare la suite Pythia di modelli e checkpoint del modello su Hugging Face Hub.
Riferimento
[1] Pythia: Un Suite per Analizzare i Grandi Modelli di Linguaggio Durante l’Addestramento e la Scalabilità, arXiv, 2023 Bala Priya C è una sviluppatrice e scrittrice tecnica dell’India. Le piace lavorare all’intersezione tra matematica, programmazione, data science e creazione di contenuti. Le sue aree di interesse ed esperienza includono DevOps, data science e elaborazione del linguaggio naturale. Ama leggere, scrivere, programmare e bere caffè! Attualmente sta lavorando per imparare e condividere le sue conoscenze con la community di sviluppatori scrivendo tutorial, guide pratiche, articoli di opinione e altro ancora.





