Il tuo modello è buono? Un’analisi approfondita delle metriche avanzate di Amazon SageMaker Canvas
Analisi metriche avanzate di Amazon SageMaker Canvas per valutare il tuo modello
Se sei un analista aziendale, capire il comportamento dei clienti è probabilmente una delle cose più importanti che ti interessano. Comprendere le ragioni e i meccanismi dietro le decisioni di acquisto dei clienti può facilitare la crescita del fatturato. Tuttavia, la perdita di clienti (comunemente chiamata churn dei clienti) rappresenta sempre un rischio. Ottenere informazioni su perché i clienti se ne vanno può essere altrettanto cruciale per mantenere i profitti e il fatturato.
Anche se l’apprendimento automatico (ML) può fornire informazioni preziose, gli esperti di ML erano necessari per costruire modelli di previsione del churn dei clienti fino all’introduzione di Amazon SageMaker Canvas.
SageMaker Canvas è un servizio gestito low-code/no-code che ti consente di creare modelli di ML in grado di risolvere molti problemi aziendali senza scrivere una sola riga di codice. Ti consente anche di valutare i modelli utilizzando metriche avanzate come se fossi un data scientist.
In questo post, mostriamo come un analista aziendale può valutare e comprendere un modello di churn di classificazione creato con SageMaker Canvas utilizzando la scheda Advanced metrics. Spieghiamo le metriche e mostriamo tecniche per gestire i dati al fine di ottenere migliori prestazioni del modello.
- Crea flussi di lavoro di piegamento delle proteine per accelerare la scoperta di farmaci su Amazon SageMaker
- Cos’è snowChat?
- Intelligenza Artificiale che aiuta nella lotta contro gli incendi boschivi
Prerequisiti
Se desideri implementare tutte o alcune delle attività descritte in questo post, è necessario un account AWS con accesso a SageMaker Canvas. Fai riferimento a Prevedi il churn dei clienti con machine learning no-code utilizzando Amazon SageMaker Canvas per comprendere i concetti di base di SageMaker Canvas, il modello di churn e il dataset.
Introduzione alla valutazione delle prestazioni del modello
Come linea guida generale, quando devi valutare le prestazioni di un modello, stai cercando di misurare quanto bene il modello predirà qualcosa quando vedrà nuovi dati. Questa previsione viene chiamata inferenza. Inizi ad addestrare il modello utilizzando dati esistenti, quindi chiedi al modello di prevedere l’outcome su dati che non ha ancora visto. Quanto accuratamente il modello prevede questo outcome è ciò su cui ti concentri per comprendere le prestazioni del modello.
Se il modello non ha visto i nuovi dati, come si può sapere se la previsione è buona o cattiva? Bene, l’idea è effettivamente utilizzare dati storici in cui i risultati sono già noti e confrontare questi valori con i valori previsti dal modello. Questo è reso possibile separando una parte dei dati storici di addestramento in modo che possa essere confrontata con ciò che il modello prevede per quei valori.
Nell’esempio del churn dei clienti (che è un problema di classificazione categorica), si parte da un dataset storico che descrive i clienti con molte caratteristiche (una in ogni record). Una delle caratteristiche, chiamata Churn, può essere True o False, descrivendo se il cliente ha lasciato il servizio o meno. Per valutare l’accuratezza del modello, dividiamo questo dataset e addestriamo il modello utilizzando una parte (il dataset di addestramento), quindi chiediamo al modello di prevedere l’outcome (classificare il cliente come Churn o meno) utilizzando l’altra parte (il dataset di test). Confrontiamo quindi la previsione del modello con la verità di riferimento contenuta nel dataset di test.
Interpretazione delle metriche avanzate
In questa sezione, discutiamo delle metriche avanzate in SageMaker Canvas che possono aiutarti a comprendere le prestazioni del modello.
Matrice di confusione
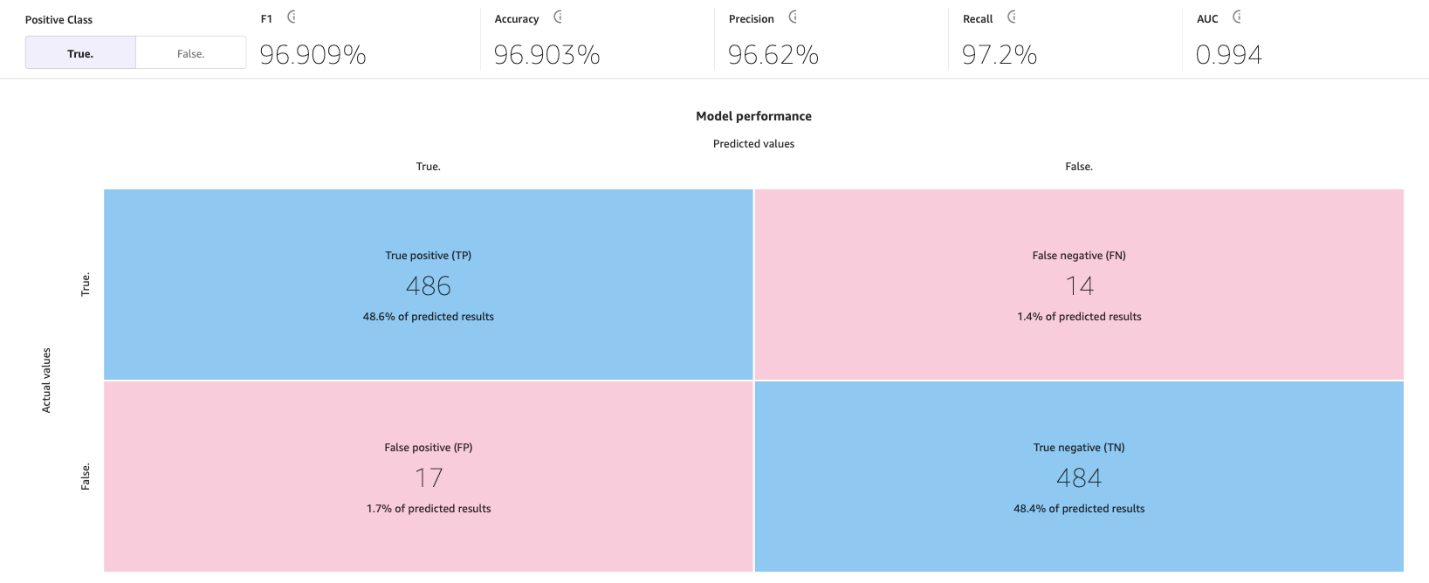
SageMaker Canvas utilizza le matrici di confusione per aiutarti a visualizzare quando un modello genera previsioni corrette. In una matrice di confusione, i risultati sono organizzati per confrontare i valori previsti con i valori storici (noti) effettivi. L’esempio seguente spiega come funziona una matrice di confusione per un modello di previsione a due categorie che prevede etichette positive e negative:
- Vero positivo – Il modello ha previsto correttamente il positivo quando l’etichetta vera era positiva
- Vero negativo – Il modello ha previsto correttamente il negativo quando l’etichetta vera era negativa
- Falso positivo – Il modello ha previsto erroneamente il positivo quando l’etichetta vera era negativa
- Falso negativo – Il modello ha previsto erroneamente il negativo quando l’etichetta vera era positiva
L’immagine seguente è un esempio di una matrice di confusione per due categorie. Nel nostro modello di churn, i valori effettivi provengono dal dataset di test e i valori previsti provengono dalla nostra richiesta al modello.
Accuratezza
L’accuratezza è la percentuale di previsioni corrette su tutte le righe o campioni del dataset di test. Sono i campioni veri che sono stati previsti come True, più i campioni falsi che sono stati correttamente previsti come False, divisi per il numero totale di campioni nel dataset.
È una delle metriche più importanti da capire perché ti dirà in quale percentuale il modello ha predetto correttamente, ma può essere fuorviante in alcuni casi. Ad esempio:
- Sbilanciamento delle classi – Quando le classi nel tuo dataset non sono distribuite in modo uniforme (hai un numero sproporzionato di campioni di una classe e pochissimi di altre), l’accuratezza può essere fuorviante. In tali casi, anche un modello che semplicemente predice la classe maggioritaria per ogni istanza può ottenere un’alta accuratezza.
- Classificazione sensibile al costo – In alcune applicazioni, il costo di una classificazione errata per diverse classi può essere diverso. Ad esempio, se stessimo prevedendo se un farmaco può aggravare una condizione, un falso negativo (ad esempio, prevedere che il farmaco potrebbe non aggravare quando in realtà lo fa) può essere più costoso di un falso positivo (ad esempio, prevedere che il farmaco potrebbe aggravare quando in realtà non lo fa).
Precisione, richiamo e punteggio F1
La precisione è la frazione dei veri positivi (TP) rispetto a tutti i positivi predetti (TP + FP). Misura la proporzione di predizioni positive che sono effettivamente corrette.
Il richiamo è la frazione dei veri positivi (TP) rispetto a tutti i positivi reali (TP + FN). Misura la proporzione di istanze positive che sono state correttamente predette come positive dal modello.
Il punteggio F1 combina precisione e richiamo per fornire un singolo punteggio che bilancia il compromesso tra di essi. Viene definito come la media armonica di precisione e richiamo:
Punteggio F1 = 2 * (precisione * richiamo) / (precisione + richiamo)
Il punteggio F1 varia da 0 a 1, con un punteggio più alto che indica una migliore performance. Un punteggio F1 perfetto di 1 indica che il modello ha raggiunto sia una precisione perfetta che un richiamo perfetto, mentre un punteggio di 0 indica che le predizioni del modello sono completamente sbagliate.
Il punteggio F1 fornisce una valutazione bilanciata delle performance del modello. Considera precisione e richiamo, fornendo una metrica di valutazione più informativa che riflette la capacità del modello di classificare correttamente le istanze positive ed evitare falsi positivi e falsi negativi.
Ad esempio, nella diagnosi medica, nella rilevazione delle frodi e nell’analisi dei sentimenti, il punteggio F1 è particolarmente rilevante. Nella diagnosi medica, identificare accuratamente la presenza di una specifica malattia o condizione è cruciale e i falsi negativi o falsi positivi possono avere conseguenze significative. Il punteggio F1 tiene conto sia della precisione (la capacità di identificare correttamente i casi positivi) che del richiamo (la capacità di trovare tutti i casi positivi), fornendo una valutazione bilanciata delle performance del modello nel rilevare la malattia. Allo stesso modo, nella rilevazione delle frodi, dove il numero di casi effettivi di frode è relativamente basso rispetto ai casi non fraudolenti (classi sbilanciate), l’accuratezza da sola può essere fuorviante a causa di un elevato numero di veri negativi. Il punteggio F1 fornisce una misura completa della capacità del modello di rilevare sia casi fraudolenti che non fraudolenti, considerando sia la precisione che il richiamo. E nell’analisi dei sentimenti, se il dataset è sbilanciato, l’accuratezza potrebbe non riflettere accuratamente le performance del modello nella classificazione delle istanze della classe di sentimento positivo.
AUC (area sotto la curva)
La metrica AUC valuta la capacità di un modello di classificazione binaria di distinguere tra classi positive e negative in tutti i threshold di classificazione. Un threshold è un valore utilizzato dal modello per prendere una decisione tra le due possibili classi, convertendo la probabilità di un campione che fa parte di una classe in una decisione binaria. Per calcolare l’AUC, il tasso dei veri positivi (TPR) e il tasso dei falsi positivi (FPR) vengono rappresentati in un grafico in diverse impostazioni di threshold. Il TPR misura la proporzione di veri positivi su tutti i positivi reali, mentre il FPR misura la proporzione di falsi positivi su tutti i negativi reali. La curva risultante, chiamata curva caratteristica di funzionamento del ricevitore (ROC), fornisce una rappresentazione visiva del TPR e del FPR in diverse impostazioni di threshold. Il valore AUC, che varia da 0 a 1, rappresenta l’area sotto la curva ROC. Valori di AUC più alti indicano una migliore performance, con un classificatore perfetto che raggiunge un AUC di 1.
Il grafico seguente mostra la curva ROC, con il TPR come asse Y e il FPR come asse X. Più la curva si avvicina all’angolo in alto a sinistra del grafico, migliori sono le performance del modello nella classificazione dei dati in categorie.
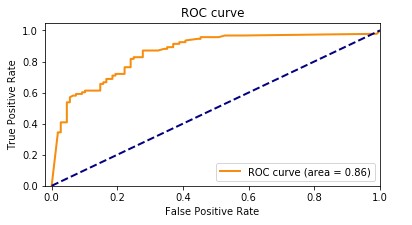
Per chiarire, vediamo un esempio. Pensiamo a un modello di rilevamento delle frodi. Di solito, questi modelli vengono addestrati su set di dati sbilanciati. Questo perché di solito quasi tutte le transazioni nel set di dati sono non fraudolente, con solo poche etichettate come frodi. In questo caso, la sola accuratezza potrebbe non catturare adeguatamente le prestazioni del modello perché è probabilmente fortemente influenzata dall’abbondanza di casi non fraudolenti, portando a punteggi di accuratezza ingannevolmente alti.
In questo caso, l’AUC sarebbe una metrica migliore per valutare le prestazioni del modello perché fornisce una valutazione completa della capacità di un modello di distinguere tra transazioni fraudolente e non fraudolente. Offre una valutazione più sfumata, tenendo conto del compromesso tra tasso di veri positivi e tasso di falsi positivi a vari soglie di classificazione.
Come il punteggio F1, è particolarmente utile quando il set di dati è sbilanciato. Misura il compromesso tra TPR e FPR e mostra quanto bene il modello può differenziare tra le due classi indipendentemente dalla loro distribuzione. Ciò significa che anche se una classe è significativamente più piccola dell’altra, la curva ROC valuta le prestazioni del modello in modo equilibrato considerando entrambe le classi allo stesso modo.
Argomenti chiave aggiuntivi
Le metriche avanzate non sono gli unici strumenti importanti a tua disposizione per valutare e migliorare le prestazioni dei modelli di apprendimento automatico. La preparazione dei dati, l’ingegneria delle caratteristiche e l’analisi dell’impatto delle caratteristiche sono tecniche essenziali per la costruzione del modello. Queste attività svolgono un ruolo cruciale nell’estrazione di informazioni significative dai dati grezzi e nel miglioramento delle prestazioni del modello, portando a risultati più robusti e illuminanti.
Preparazione dei dati e ingegneria delle caratteristiche
L’ingegneria delle caratteristiche è il processo di selezione, trasformazione e creazione di nuove variabili (caratteristiche) dai dati grezzi e svolge un ruolo chiave nel miglioramento delle prestazioni di un modello di apprendimento automatico. La selezione delle variabili o delle caratteristiche più rilevanti dai dati disponibili comporta la rimozione di caratteristiche irrilevanti o ridondanti che non contribuiscono al potere predittivo del modello. La trasformazione delle caratteristiche dei dati in un formato adatto include la ridimensionamento, la normalizzazione e la gestione dei valori mancanti. Infine, la creazione di nuove caratteristiche dai dati esistenti avviene attraverso trasformazioni matematiche, combinazione o interazione di diverse caratteristiche o creazione di nuove caratteristiche a partire da conoscenze specifiche del dominio.
Analisi dell’importanza delle caratteristiche
SageMaker Canvas genera un’analisi dell’importanza delle caratteristiche che spiega l’impatto che ciascuna colonna nel tuo set di dati ha sul modello. Quando generi previsioni, puoi vedere l’impatto delle colonne che identifica quali colonne hanno maggiore impatto su ciascuna previsione. Ciò ti fornirà informazioni su quali caratteristiche meritano di far parte del tuo modello finale e quali dovrebbero essere scartate. L’impatto delle colonne è un punteggio percentuale che indica quanto peso ha una colonna nel fare previsioni rispetto alle altre colonne. Per un impatto di colonna del 25%, Canvas valuta la previsione come 25% per la colonna e 75% per le altre colonne.
Approcci per migliorare l’accuratezza del modello
Anche se ci sono metodi multipli per migliorare l’accuratezza del modello, i data scientist e i praticanti di apprendimento automatico di solito seguono uno dei due approcci discussi in questa sezione, utilizzando gli strumenti e le metriche descritte in precedenza.
Approccio centrato sul modello
In questo approccio, i dati rimangono sempre gli stessi e vengono utilizzati per migliorare iterativamente il modello per ottenere i risultati desiderati. Gli strumenti utilizzati con questo approccio includono:
- Prova di più algoritmi di apprendimento automatico rilevanti
- Regolazione e ottimizzazione dell’algoritmo e degli iperparametri
- Diversi metodi di ensemble di modelli
- Utilizzo di modelli pre-addestrati (SageMaker fornisce vari modelli incorporati o pre-addestrati per aiutare i praticanti di apprendimento automatico)
- AutoML, che è ciò che SageMaker Canvas fa dietro le quinte (utilizzando Amazon SageMaker Autopilot), che comprende tutti i punti precedenti
Approccio centrato sui dati
In questo approccio, l’attenzione è sulla preparazione dei dati, sul miglioramento della qualità dei dati e sulla modifica iterativa dei dati per migliorare le prestazioni:
- Esplorazione delle statistiche del set di dati utilizzato per addestrare il modello, nota anche come analisi esplorativa dei dati (EDA)
- Miglioramento della qualità dei dati (pulizia dei dati, imputazione dei valori mancanti, rilevamento e gestione degli outlier)
- Selezione delle caratteristiche
- Ingegneria delle caratteristiche
- Aumento dei dati
Migliorare le prestazioni del modello con Canvas
Iniziamo con l’approccio centrato sui dati. Utilizziamo la funzionalità di anteprima del modello per eseguire un’analisi esplorativa dei dati iniziale. Questo ci fornisce una base che possiamo utilizzare per eseguire l’aumento dei dati, generando una nuova base e infine ottenendo il miglior modello con un approccio centrato sul modello utilizzando la funzionalità di costruzione standard.
Utilizziamo il dataset sintetico di un operatore di telefonia mobile. Questo dataset di esempio contiene 5.000 record, in cui ogni record utilizza 21 attributi per descrivere il profilo del cliente. Consulta Predici il churn dei clienti con machine learning senza codice utilizzando Amazon SageMaker Canvas per una descrizione completa.
Anteprima del modello in un approccio centrato sui dati
Come primo passo, apriamo il dataset, selezioniamo la colonna da predire come Churn? e generiamo un modello di anteprima scegliendo Anteprima modello.
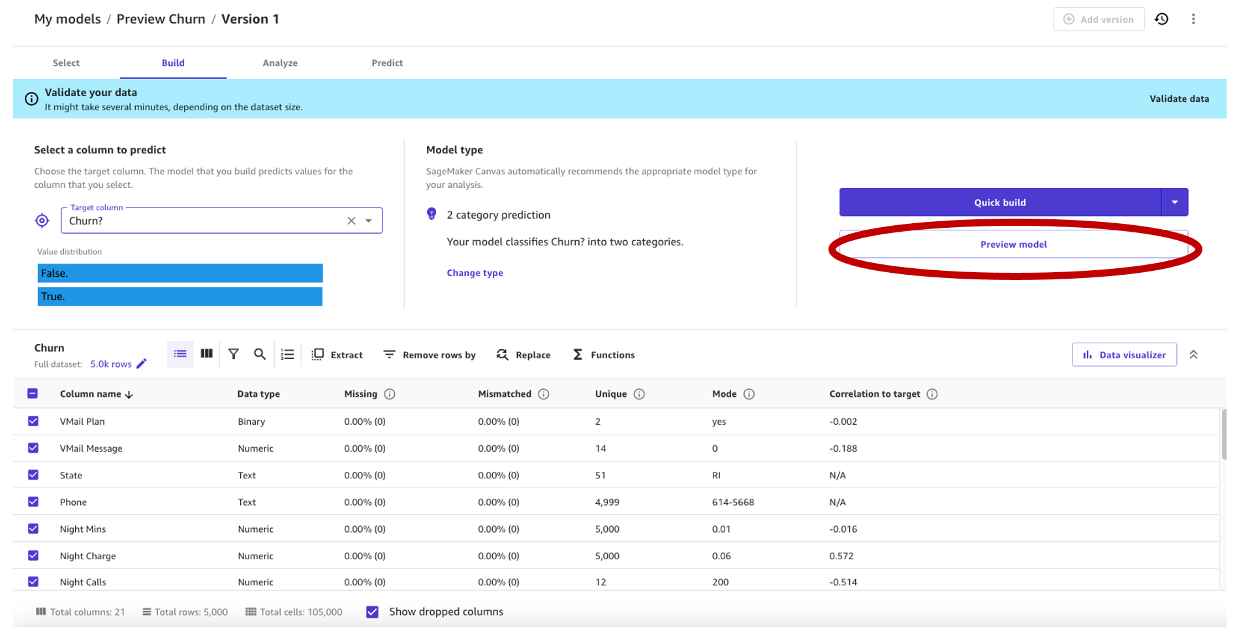
Il pannello Anteprima modello mostrerà il progresso fino a quando il modello di anteprima non sarà pronto.
Quando il modello è pronto, SageMaker Canvas genera un’analisi dell’importanza delle caratteristiche.
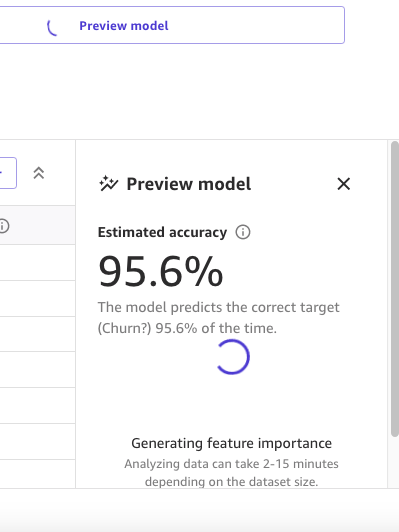
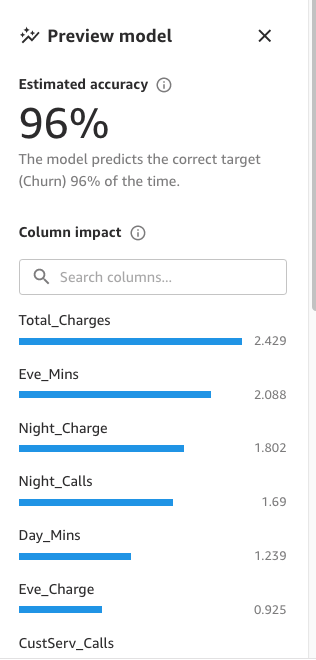
Infine, quando è completo, il pannello mostrerà un elenco di colonne con il loro impatto sul modello. Questi sono utili per capire quanto sono rilevanti le caratteristiche nelle nostre previsioni. L’impatto della colonna è un punteggio percentuale che indica quanto peso ha una colonna nel fare previsioni rispetto alle altre colonne. Nell’esempio seguente, per la colonna Night Calls, SageMaker Canvas assegna un peso alla previsione del 4,04% per la colonna e del 95,9% per le altre colonne. Più alto è il valore, maggiore è l’incidenza.
Come possiamo vedere, il modello di anteprima ha un’accuratezza del 95,6%. Cerchiamo di migliorare le prestazioni del modello utilizzando un approccio centrato sui dati. Effettuiamo la preparazione dei dati e utilizziamo tecniche di ingegneria delle caratteristiche per migliorare le prestazioni.
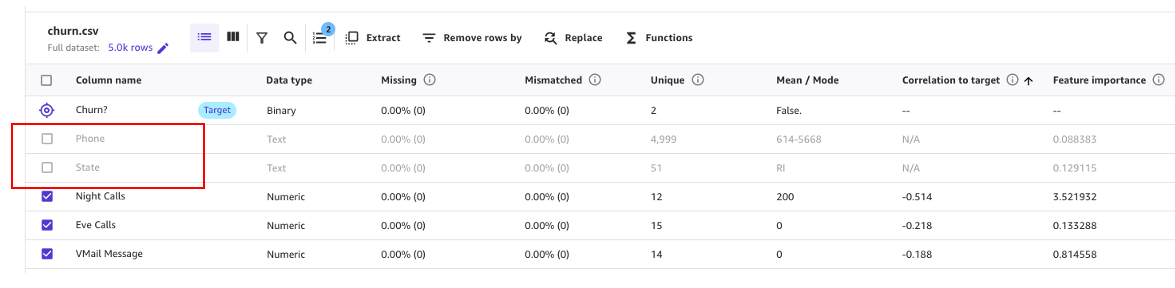
Come mostrato nella seguente schermata, possiamo osservare che le colonne Phone e State hanno molto meno impatto sulla nostra previsione. Pertanto, useremo queste informazioni come input per la nostra prossima fase, la preparazione dei dati.

SageMaker Canvas fornisce trasformazioni dei dati di ML con le quali puoi pulire, trasformare e preparare i tuoi dati per la costruzione del modello. Puoi utilizzare queste trasformazioni sui tuoi dataset senza codice e saranno aggiunte alla ricetta del modello, che è un registro della preparazione dei dati effettuata sui tuoi dati prima della costruzione del modello.
Nota che le trasformazioni dei dati che utilizzi modificano solo i dati di input durante la costruzione di un modello e non modificano il tuo dataset o l’origine dei dati originale.
Le seguenti trasformazioni sono disponibili in SageMaker Canvas per preparare i tuoi dati per la costruzione:
- Estrazione di date e orari
- Eliminazione di colonne
- Filtro righe
- Funzioni e operatori
- Gestione righe
- Rinomina colonne
- Rimuovi righe
- Sostituisci valori
- Ricampiona dati di serie temporali
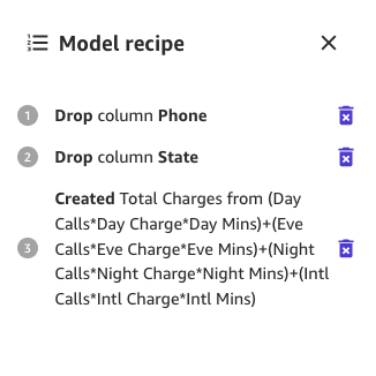
Iniziamo eliminando le colonne che abbiamo scoperto avere poco impatto sulla nostra previsione.
Ad esempio, in questo dataset, il numero di telefono è solo l’equivalente di un numero di conto: è inutile o addirittura dannoso per prevedere la probabilità di churn di altri account. Allo stesso modo, lo stato del cliente non influisce molto sul nostro modello. Rimuoviamo quindi le colonne Phone e State deselezionando quelle caratteristiche in Nome colonna.
Ora, effettuiamo alcune ulteriori trasformazioni dei dati e ingegneria delle caratteristiche.
Ad esempio, abbiamo notato nella nostra analisi precedente che l’importo addebitato ai clienti ha un impatto diretto sul churn. Creiamo quindi una nuova colonna che calcola gli addebiti totali ai nostri clienti combinando Charge, Mins e Calls per Day, Eve, Night e Intl. Per farlo, utilizziamo le formule personalizzate in SageMaker Canvas.
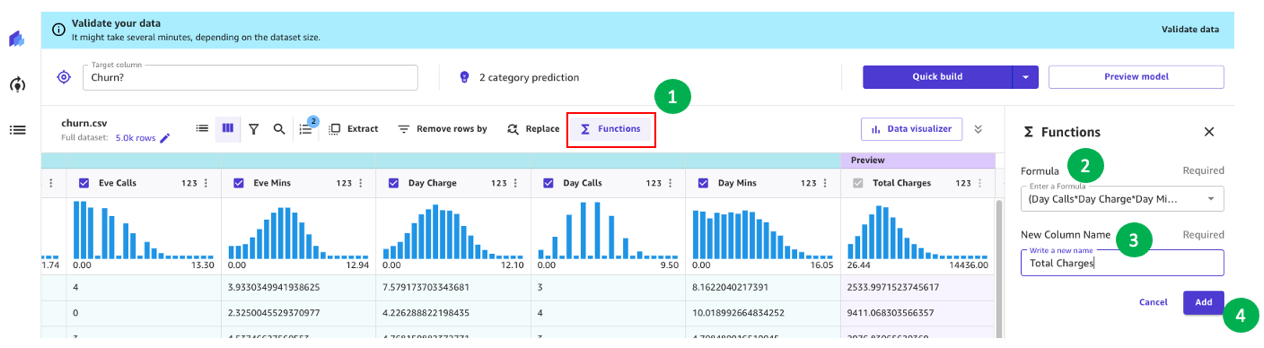
Cominciamo scegliendo Funzioni, quindi aggiungiamo alla casella di testo della formula il seguente testo:
(Chiamate diurne*Tariffa diurna*Minuti diurni)+(Chiamate serali*Tariffa serale*Minuti serali)+(Chiamate notturne*Tariffa notturna*Minuti notturni)+(Chiamate internazionali*Tariffa internazionale*Minuti internazionali)
Dai al nuovo campo un nome (ad esempio, Total Charges) e scegli Aggiungi dopo che l’anteprima è stata generata. La ricetta del modello dovrebbe ora apparire come mostrato nella seguente schermata.
Quando questa preparazione dei dati è completa, addestriamo un nuovo modello di anteprima per vedere se il modello è migliorato. Scegli Anteprima modello di nuovo e il riquadro in basso a destra mostrerà il progresso.

Quando l’addestramento è terminato, procederà al ricalcolo dell’accuratezza prevista e creerà anche un’analisi dell’impatto di una nuova colonna.
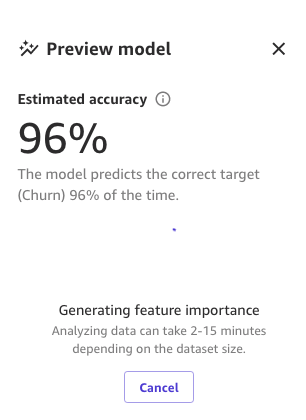
E infine, quando l’intero processo è completo, possiamo vedere lo stesso riquadro che abbiamo visto in precedenza ma con la nuova accuratezza del modello di anteprima. Puoi notare che l’accuratezza del modello è aumentata dello 0,4% (dal 95,6% al 96%).
I numeri nelle immagini precedenti possono essere diversi dai tuoi perché l’apprendimento automatico introduce una certa casualità nel processo di addestramento dei modelli, il che può portare a risultati diversi in costruzioni diverse.
Approccio centrato sul modello per creare il modello
Canvas offre due opzioni per creare i tuoi modelli:
- Costruzione standard – Costruisce il miglior modello da un processo ottimizzato in cui la velocità viene scambiata per una maggiore accuratezza. Utilizza Auto-ML, che automatizza varie attività di apprendimento automatico, inclusa la selezione del modello, la prova di vari algoritmi pertinenti al tuo caso d’uso di apprendimento automatico, la messa a punto dei parametri e la creazione di rapporti di spiegabilità del modello.
- Costruzione rapida – Costruisce un modello semplice in una frazione del tempo rispetto a una costruzione standard, ma l’accuratezza viene scambiata per la velocità. Il modello rapido è utile quando si itera per capire più rapidamente l’impatto dei cambiamenti dei dati sull’accuratezza del modello.
Continuiamo a utilizzare un approccio di costruzione standard.
Costruzione standard
Come abbiamo visto in precedenza, la costruzione standard costruisce il miglior modello da un processo ottimizzato per massimizzare l’accuratezza.
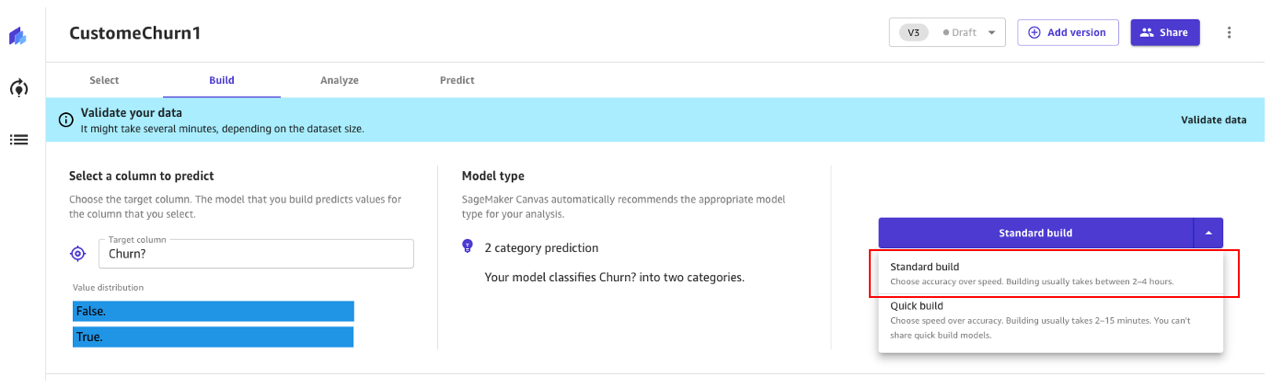
Il processo di creazione del nostro modello di churn richiede circa 45 minuti. Durante questo tempo, Canvas testa centinaia di pipeline candidate, selezionando il miglior modello. Nella seguente schermata, possiamo vedere il tempo di costruzione previsto e il progresso.
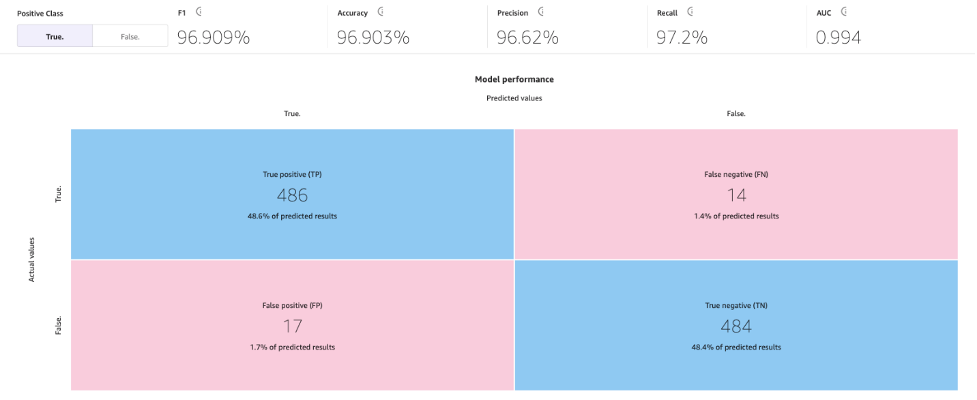
Con il processo di costruzione standard, il nostro modello di apprendimento automatico ha migliorato l’accuratezza del modello al 96,903%, il che è un miglioramento significativo.

Esplora metriche avanzate
Esploriamo il modello utilizzando la scheda Metriche avanzate. Nella scheda Punteggio, scegli Metriche avanzate.

Questa pagina mostrerà la seguente matrice di confusione insieme alle metriche avanzate: punteggio F1, precisione, richiamo, punteggio F1 e AUC.
Genera previsioni
Ora che le metriche sembrano buone, possiamo eseguire una previsione interattiva nella scheda Previsione, sia in batch che in previsione singola (in tempo reale).
Abbiamo due opzioni:
- Utilizzare questo modello per eseguire previsioni in batch o singole
- Inviare il modello a Amazon Sagemaker Studio per condividerlo con i data scientist
Pulire
Per evitare future spese di sessione, effettua il logout da SageMaker Canvas.

Conclusione
SageMaker Canvas fornisce strumenti potenti che ti consentono di costruire e valutare l’accuratezza dei modelli, migliorandone le prestazioni senza la necessità di codifica o competenze specializzate in data science e ML. Come abbiamo visto nell’esempio attraverso la creazione di un modello di churn del cliente, combinando questi strumenti con un approccio centrato sui dati e sui modelli che utilizza metriche avanzate, gli analisti aziendali possono creare e valutare modelli di previsione. Con un’interfaccia visiva, sei anche in grado di generare previsioni di ML accurate da solo. Ti incoraggiamo a consultare i riferimenti e vedere quanti di questi concetti possono essere applicati ad altri tipi di problemi di ML.
Riferimenti
- Prevedi il churn dei clienti con machine learning senza codice utilizzando Amazon SageMaker Canvas
- Costruisci, condividi, distribuisci: come gli analisti aziendali e i data scientist raggiungono un time-to-market più veloce utilizzando ML senza codice e Amazon SageMaker Canvas
- Personalizzazione e riutilizzo di modelli generati da Amazon SageMaker Autopilot
- Amazon SageMaker Canvas Immersion Day Workshop
- Gestisci i flussi di lavoro di AutoML con AWS Step Functions e AutoGluon su Amazon SageMaker






