NLP Moderno Una panoramica dettagliata. Parte 4 Gli ultimi sviluppi
NLP Moderno ultimi sviluppi
Nel mondo attuale, chiunque abbia una connessione al web ha sentito parlare di uno strumento chiamato ChatGPT, che ha creato il caos ovunque, e alcuni hanno persino cercato di usarlo per compiti diversi nella loro vita quotidiana. Molti lo considerano la rivoluzione che può rispondere a qualsiasi domanda o dubbio. Ma ti sei mai chiesto come siamo arrivati fin qui? Come l’IA è diventata in grado di rispondere alla maggior parte delle domande e richieste che hai?
Cerchiamo di fare un po’ di chiarezza. Prima di iniziare, i concetti che discuteremo in tutto l’articolo presuppongono concetti di lavori precedenti come Transformers e GPT 2. Se non conosci questi lavori, ne ho già parlato; leggili brevemente.
Quindi, immergiamoci.
- Il Modello POE dei Sistemi Hardware Bio-Ispirati
- NVIDIA aiuta a creare un forum per stabilire lo standard OpenUSD per i mondi in 3D
- Creatura 3D affettuosa prende vita nella collaborazione padre-figlio questa settimana ‘Nello Studio NVIDIA
In questo articolo parleremo di GPT 3, 3.5 e chatGPT. Prima di iniziare a parlare di GPT3, permettimi di farti conoscere un altro lavoro di OpenAI, che è stato importante per l’evoluzione di GPT3.
Generazione di sequenze lunghe con Sparse Transformers
Nel 2019, i transformers hanno iniziato a diventare estremamente popolari e sono stati utilizzati per numerosi lavori. Un problema è emerso man mano che la lunghezza del contesto di input aumentava. Poiché i transformers utilizzano l’attenzione sull’intera lunghezza dell’input, il tempo e le risorse di memoria richiesti aumentano quadraticamente all’aumentare della lunghezza dell’input. La complessità temporale diventa O(N²) poiché per ogni token o parola, il modello fa attenzione a tutte le altre parole, quindi O(N) per ogni parola, per tutte le parole, diventa N x O(N) = O(N²). Questo rende l’apprendimento presto incomprensibile. OpenAI ha pubblicato questo articolo nel 2019, per affrontare questo problema di tempo in espansione.
L’idea era quella di introdurre un cambiamento di modellazione che riducesse la complessità temporale a N^(1+ 1/p) dove p è l’elemento di fattorizzazione con un valore >1, di solito p=2, senza compromettere le prestazioni. Così, alla fine, diventa O(N*sqrt(N)).
Osservazioni: Si è visto che, sebbene il meccanismo di attenzione presti attenzione a tutti i pixel o parole per un determinato token, ciò non è sempre necessario come si può vedere nella figura sottostante.

Si è scoperto che poiché i livelli stavano già apprendendo l’attenzione sparsa basata su righe e colonne e si stavano stabilendo modelli dipendenti dai dati, è stato possibile introdurre kernel pesati sparsi per costruire una matrice di attenzione senza influire troppo sulle prestazioni del modello.
Idea: Gli autori hanno suddiviso l’auto-attenzione completa in 2 fasi, con 2 kernel diversi basati su osservazioni su come l’attenzione è distribuita. Gli autori hanno scoperto che per l’attenzione alle immagini, generalmente viene data attenzione a un certo modello, ma per dati non di immagini come audio e testo, non esiste un modello fisso per il kernel. I kernel decisi sono mostrati nell’immagine sottostante.
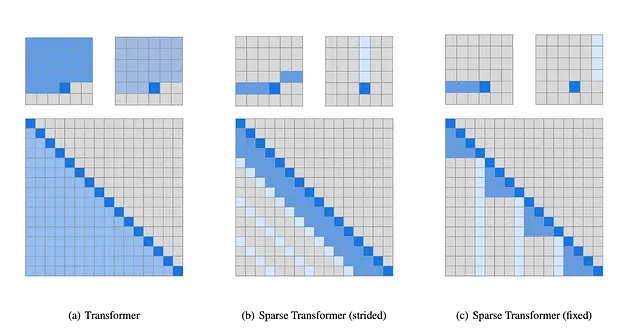
La prima immagine (a) mostra l’auto-attenzione del transformer reale, in cui, per produrre un token di output, il modello fa attenzione a tutti i passaggi o token che si verificano prima della posizione di output. Gli autori hanno fattorizzato l’auto-attenzione reale in due diversi kernel di attenzione, come in (b) e (c ).
(B) Kernel a passo: In questo caso, il modello fa attenzione alla riga e alla colonna della posizione di output. Questo tipo è utile per i casi basati su immagini.
(C ) Kernel fisso: In questo caso, il modello fa attenzione a una colonna fissa e agli elementi dopo l’elemento di colonna più recente. Questo tipo è utile per testo e audio.
Questi strati di attenzione fattorizzata hanno fornito risultati quasi uguali, ma hanno ridotto con successo il tempo di esecuzione e il consumo di memoria.
L’architettura del transformer sparso:
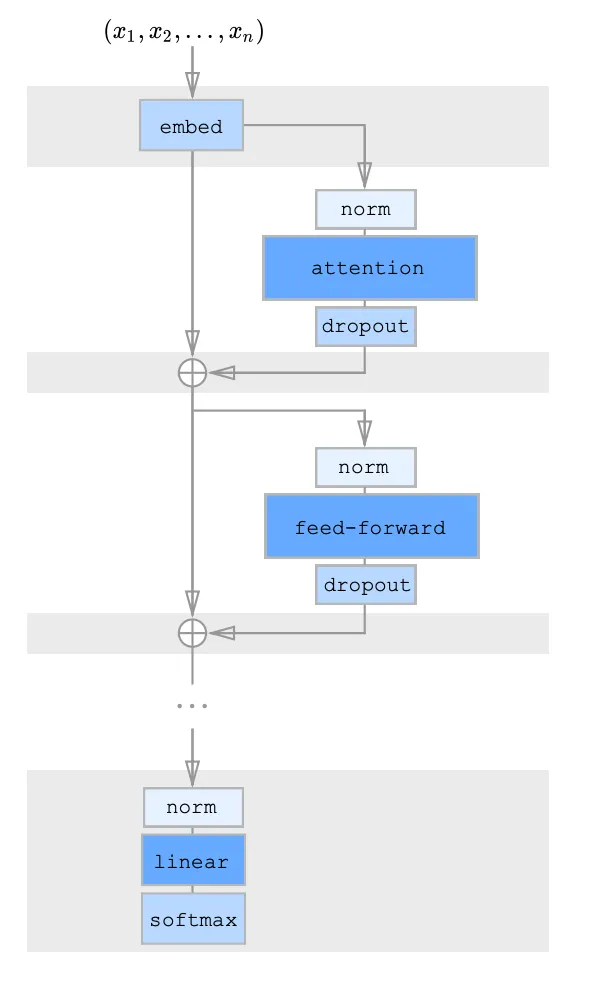
Gli autori hanno introdotto un’architettura residuale per combinare l’attenzione fattorizzata, rispetto all’architettura originale del modello transformer. Hanno proposto 3 approcci:
(1) Ogni blocco residuale avrà un tipo di kernel di attenzione fattorizzata, e li disporremo in modo alternato
(2) Ci sarà 1 testa di attenzione, che parteciperà congiuntamente alle posizioni date sia dai kernel e funzionerà come una testa unita.
(3) Ci saranno più teste di attenzione come nell’architettura originale, verranno effettuati meccanismi di attenzione multipli in modo parallelo e i risultati verranno concatenati per ottenere il risultato finale.
Questa idea architetturale è anche utilizzata in GPT 3.
Link all’articolo: https://arxiv.org/pdf/1904.10509.pdf
Importante conclusione: Utilizzando l’attenzione fattorizzata e la struttura residuale alternata, possiamo ridurre drasticamente i calcoli e il tempo pur mantenendo l’efficienza.
I modelli linguistici sono apprendisti a pochi esempi
Il lavoro menzionato è stato pubblicato da OpenAI nel 2020. Il modello proposto è uno dei modelli più grandi nel mondo del NLP. Il lavoro svolto ha aperto molte porte per il futuro del NLP, di cui oggi godiamo delle innovazioni. Gli autori hanno individuato 3 problemi con l’approccio corrente dei modelli.
(1) C’è un enorme bisogno di dati per addestrare i modelli, che sono specifici per compiti. Ma a volte non è possibile trovare queste grandi quantità di dati.
(2) I modelli vengono pre-addestrati su una grande distribuzione di dati come modello generalizzato, ma dopo il fine-tuning su un compito specifico, vengono proiettati su una distribuzione molto ristretta, il che rende il modello distorto, e se i dati sono pochi, c’è il rischio di overfitting e prestazioni scadenti.
(3) Come esseri umani, non abbiamo bisogno di troppi dati per imparare qualcosa, in generale abbiamo bisogno di poche dimostrazioni o anche di un suggerimento a volte per imparare, il che è molto diverso per le macchine. Se vogliamo che i modelli si comportino in modo simile agli esseri umani, il problema dei dati doveva essere risolto.
Per risolvere questi problemi, gli autori hanno capito che doveva essere addestrato un modello molto generalizzato. L’unico modo era un concetto chiamato Meta-Learning.
Meta-Learning
Meta-Learning è un campo in sviluppo nell’apprendimento automatico, che insegna ai modelli come apprendere, quindi è anche chiamato Imparare ad apprendere. Si è capito che gli esseri umani imparano nuove cose molto velocemente perché possiediamo conoscenze precedenti sulla maggior parte delle cose dalle nostre esperienze regolari, il che ci aiuta ad avere un’idea su come imparare, ma quando un modello inizia ad apprendere, non ha idea dei dati o dell’obiettivo, che costituisce la differenza. Questo viene spesso definito Condizionamento, che è una proprietà di qualsiasi essere vivente di imparare dalle esperienze passate e dagli stimoli. Si dice che ci siano 3 tipi principali di conoscenze precedenti,
- Conoscenza precedente di somiglianza
- Conoscenza precedente dei dati
- Conoscenza precedente dell’apprendimento
Il Meta-Learning pianifica di insegnare al modello in modo tale che sia possibile raggiungere ciò che gli umani possono fare. Viene spesso utilizzato anche per perfezionare gli algoritmi. Ci sono alcune possibilità viste con il Meta-Learning:
(A) Apprendimento a pochi esempi: chiamato anche apprendimento N-Vie-K-Esempi, in cui ci sono N classi e K campioni per ogni classe. Il modello viene addestrato sui campioni, da questi dati, chiamati set di supporto, ma l’apprendimento viene convalidato su un set separato chiamato set di query. Nota solo in questo caso, il back-propagation avviene su un set di supporto molto breve.

(B) Apprendimento a un solo esempio: è presente solo un campione per ogni classe N nel set di supporto, il modello deve eseguire sul set di query. C’è il back-propagation.
(C ) Apprendimento a zero esempi: non sono presenti campioni, il modello esegue direttamente sul set di query.
Quindi, in sostanza, un modello dati pre-addestrato può eseguire direttamente con meno o nessun dato per compiti specifici. La fase di pre-addestramento viene chiamata fase di Meta-Learning e la fase di apprendimento specifica viene chiamata fase di adattamento nell’universo del Meta-Learning. Per addestrare un meta-apprenditore, di solito si prendono in considerazione una miriade di diversi insiemi di dati e modelli per creare un ambiente generalizzato anziché un ambiente specifico per il compito.
C’è un intero flusso di apprendimento e algoritmi di meta-apprendimento, di cui non entrerò nel dettaglio, altrimenti diventerebbe troppo lungo. Ho appena accennato alle parti necessarie per comprendere GPT3.
Per implementare il meta-apprendimento nei modelli di linguaggio, gli autori hanno utilizzato un metodo chiamato apprendimento in contesto, che vedremo tra un attimo. L’idea è stata presa dal lavoro su GPT-2, che ha dimostrato che, se pre-addestrato su un enorme corpus di dati diversi, il modello impara l’abilità di catturare diverse dipendenze e riconoscimenti di pattern, il che gli consente di adattarsi molto rapidamente alle nuove specifiche attività con pochissime dimostrazioni.
Link ai documenti: https://arxiv.org/pdf/2004.05439.pdf
https://aclanthology.org/2022.acl-long.53.pdf
Ora, cos’è l’apprendimento in contesto?
Apprendimento in Contesto
L’apprendimento in contesto significa imparare da un’analogia. È molto simile a come noi umani impariamo. Di solito, ci sono 3 casi nell’apprendimento umano:
- Ci viene dato uno spunto, come ad esempio “Scrivi un paragrafo su un albero”.
- Ci viene dato uno spunto con una dimostrazione “Trova la somma: 1+2=34+5= <previsione>”.
- Ci viene dato uno spunto con più dimostrazioni “Trova la somma: 1+2=34+5= 96+7= <previsione>”.
L’apprendimento in contesto funziona allo stesso modo. Inseriamo uno spunto o uno spunto con una dimostrazione nel vettore di contesto del modello e il modello restituisce un risultato di previsione. Ora, in questo caso, non c’è retropropagazione o apprendimento. L’intero input con lo spunto e la dimostrazione viene inserito come stringa, nel vettore di input del modello. Si potrebbe dire che è una sorta di previsione basata sul condizionamento.
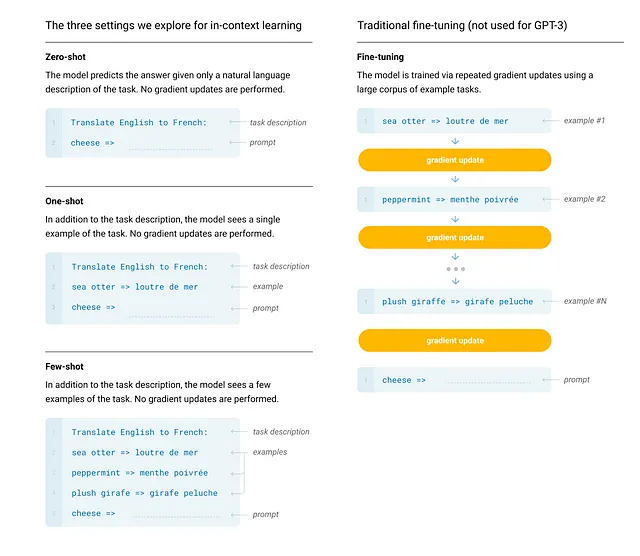
Ora, gli autori hanno definito 4 casi per valutare le prestazioni del modello:
- Finetuning come fatto nei casi precedenti, dopo il pre-addestramento, il modello viene addestrato su dati specifici per l’attività.
- Few-Shot Learning: In questo caso, su un modello pre-addestrato, viene fornito uno spunto con più dimostrazioni. Il numero di dimostrazioni varia da 10 a 100 a seconda di quanti possono essere inseriti nella lunghezza del contesto del vettore di input. Il modello fa previsioni basate sulle dimostrazioni. Non c’è retropropagazione.
- One-Shot Learning: In questo caso, viene fornito uno spunto con una sola dimostrazione al modello. Non c’è retropropagazione.
- Zero-Shot Learning: In questo caso, viene fornito solo uno spunto senza dimostrazione.
L’intuizione per addestrare il modello GPT è stata presa da un algoritmo molto comune chiamato Meta-apprendimento agnostico del modello.
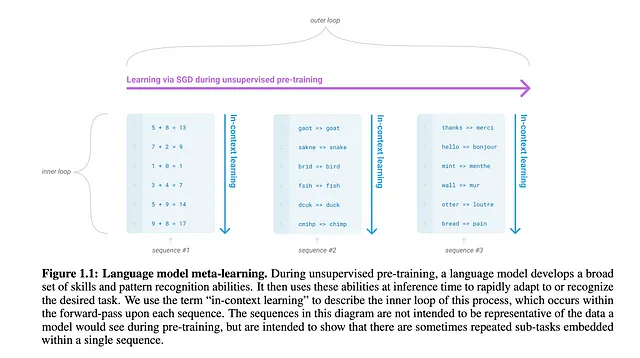
In MAML, in generale abbiamo modelli specifici per attività e un meta-apprendista generale, e cerchiamo di ridurre la perdita tra la previsione specifica per l’attività e le previsioni del meta-apprendista. L’apprendimento del modello specifico dell’attività è chiamato ciclo interno, e l’aggiornamento dei pesi del meta-apprendista, che apprende da molti modelli specifici per attività, è chiamato ciclo esterno.
In questo caso, gli autori hanno chiamato il ciclo interno, come apprendimento in contesto. È stato proiettato in questo modo perché, nel pre-addestramento, il modello viene addestrato utilizzando molti diversi set di dati, provenienti da domini diversi (chiamati sotto-attività). Per i domini, l’apprendimento avviene nel ciclo interno, ma il modello apprende la generalizzazione nel ciclo esterno.
Architettura: Gli autori hanno utilizzato lo stesso modello utilizzato in GPT-2, con una modifica che consiste nell’utilizzare attenzioni dense e sparse alternate come discussi per i trasformatori sparsi. Sono stati proposti 8 modelli con parametri che vanno da 125 milioni a 175 miliardi di parametri per valutare l’impatto delle dimensioni sulle prestazioni. Il modello con 175 miliardi di parametri è chiamato GPT3.
Dati di addestramento:
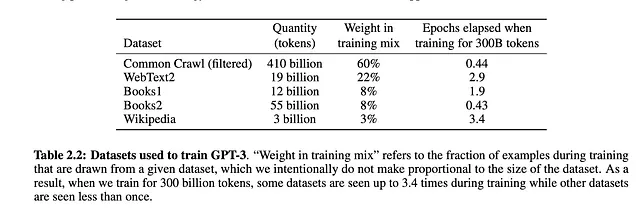
L’immagine sopra descrive i dataset utilizzati per addestrare i modelli. Gli autori hanno filtrato il dataset per rimuovere i dati di qualità inferiore, la duplicazione e la ridondanza.
Perché funziona l’apprendimento In-Context? Sono molto sicuro che questa sia la domanda nella mente di tutti. Come può un modello produrre un output solo con una dimostrazione?
Ci sono stati troppi studi, ma ancora le ragioni sono oggetto di studio da parte di diversi ricercatori in tutto il mondo. Parlerò dei risultati delle due scoperte di ricerca più influenti di Standford e Meta AI.
Link ai paper:
- Ripensando al ruolo delle dimostrazioni: cosa rende efficace l’apprendimento In-Context?: https://aclanthology.org/2022.emnlp-main.759.pdf
- Una spiegazione dell’apprendimento in contesto come inferenza bayesiana implicita: https://arxiv.org/pdf/2111.02080.pdf
Il secondo paper propone come funziona, e il primo fa uno studio completo dei fattori sui quali dipende la performance del modello. Entrambi utilizzano molti modelli di dimensioni dei parametri enormi. È stato provato che all’aumentare delle dimensioni del modello, aumentano anche la capacità di apprendimento e la performance del modello stesso.
“Una spiegazione dell’apprendimento in contesto come inferenza bayesiana implicita” fa un’ipotesi secondo cui, poiché i grandi modelli linguistici vengono pre-addestrati su un ampio set di dati diversi provenienti da fonti come Common Crawler, il modello si imbatte in numerosi argomenti e menzioni, che vengono forniti come sequenze di dati lunghe per prevedere la parola successiva, il modello impara a utilizzare l’attenzione e a capire le inferenze interne delle sequenze, il che porta il modello a ricordare questi argomenti nei suoi spazi di incorporamento dei parametri. Durante un’elaborazione specifica del compito, il modello riceve i dati, studia con attenzione e “localizza” il concetto nel suo spazio di incorporamento, per trovare la risposta. Le dimostrazioni e le indicazioni aiutano il meccanismo di attenzione a funzionare meglio, fornendo migliori risultati.
In “Ripensando al ruolo delle dimostrazioni: cosa rende efficace l’apprendimento In-Context?”, gli autori hanno studiato 6 modelli, tra cui GPT3, su 12 diversi dataset. Hanno osservato quanto segue:
- Modificare le etichette nella dimostrazione, ad esempio fornendo etichette casuali, ha avuto un effetto trascurabile sulla performance del modello.
- I ricercatori hanno sperimentato un numero variabile (k) di dimostrazioni di input-etichetta. Hanno scoperto che la performance del modello migliorava molto dove erano presenti le dimostrazioni rispetto a 0 dimostrazioni, anche se k è piccolo (k=4), ma l’aumento delle prestazioni diventa molto lento al di sopra di k ≥ 8.
- Il formato di input migliorava le prestazioni.
Dagli esperimenti sono stati tratti 4 conclusioni che ci dicono come e perché l’apprendimento In-Context funziona:
- La mappatura input-etichetta
- La distribuzione degli input
- La distribuzione degli insiemi di etichette
- Il formato dell’input
GPT3 addestrato con il meta-apprendimento basato su contesto è riuscito a comportarsi più vicino al comportamento umano basato su indicazioni e dimostrazioni con apprendimento a pochi esempi e a raggiungere le prestazioni SOTA per compiti come la traduzione, la risposta alle domande e il completamento, ma non è riuscito a fornire guadagni consistenti nel ragionamento del buon senso.
Link al paper: https://arxiv.org/pdf/2005.14165.pdf
Successivamente, parleremo dell’aggiornamento di GPT 3, che ha dato origine a ChatGPT.
Addestrare modelli linguistici a seguire le istruzioni con il feedback umano: InstructGPT
Dopo aver rilasciato GPT3, i ricercatori di OpenAI hanno capito che anche se i grandi modelli linguistici possono essere performanti, non significa necessariamente che operino in base all’intento dell’utente, al contrario, i risultati generati da GPT3 possono essere falsi, tossici e non allineati abbastanza per aiutare le persone. Per rimediare alla situazione, gli autori hanno ridotto il modello GPT3 con 175 miliardi di parametri, 100 volte, per creare un modello con 1.3 miliardi di parametri chiamato GPT3.5 o InstructGPT. Il modello è stato raffinato con l’aiuto del feedback umano per allinearsi meglio con l’intento umano. Gli autori volevano che il modello fornisse risposte oneste, utili e innocue.
Per rendere il modello più adatto all’interazione umana, gli autori hanno introdotto un metodo da un lavoro precedente, che utilizza l’apprendimento per rinforzo con il feedback umano. È stata utilizzata la tecnica di ottimizzazione della politica proximal o PPO.
Per addestrare il modello InstructGPT, gli autori hanno utilizzato 4 passaggi, il primo passaggio è il semplice modellamento del linguaggio per il pre-addestramento seguito da 3 passaggi. Gli autori hanno iniziato con un modello GPT3 pre-addestrato dopo questo passaggio.
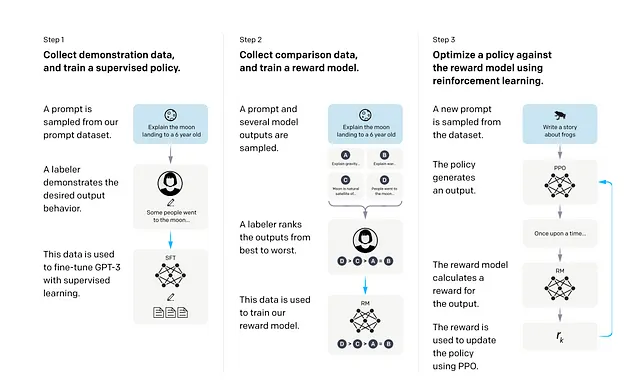
- Il primo passaggio consisteva in una breve fase di affinamento supervisionato. Gli autori hanno creato un portale pre-GPT3.5, dove gli utenti hanno pubblicato i loro stimoli e dimostrazioni. Inoltre, OpenAI ha assunto 40 collaboratori dopo un processo di selezione e li ha incaricati di scrivere alcuni stimoli e dimostrazioni. Si è cercato di garantire che i compiti avessero abbastanza diversità, inclusa la generazione, la risposta alle domande, il dialogo, la sintesi, le estrazioni e altri compiti di linguaggio naturale, al fine di evitare distorsioni nella fase di affinamento. Sono stati eliminati anche gli stimoli dei compiti poco chiari nel loro scopo. Il modello GPT3 pre-addestrato è stato affinato su questi dati con un drop-out del 0.2 per 16 epoche.
- Nel secondo passaggio, viene addestrato un modello di ricompensa per l’apprendimento per rinforzo, che interagirà con il modello principale nella fase finale di addestramento PPO. Ora, nel caso di un modello generativo, potrebbe generare più output alimentando gli stessi input. In questo passaggio, il modello affinato dal primo passaggio è stato alimentato con gli input, ha prodotto più output e i collaboratori o gli annotatori hanno contrassegnato l’output preferito. In questo modo è stato creato un dataset. L’ultimo strato del modello GPT3 affinato è stato rimosso e il modello è stato modificato per prendere un prompt e una risposta e produrre un valore di ricompensa scalare. Il dataset creato dagli annotatori è stato utilizzato per addestrare il modello di ricompensa. Per addestrare il modello di ricompensa, la dimensione del modello GPT3 è stata ridotta da 175 miliardi di parametri a 6 miliardi di parametri, poiché si è visto che addestrare un modello così grande richiedeva molto tempo e poteva essere instabile a volte. La ricompensa scalare è formulata come la differenza di log-odds con la probabilità della risposta prodotta dal modello rispetto alla risposta preferita dall’annotatore. In questo modo viene introdotto il meccanismo di feedback umano.
- Nell’ultimo e definitivo passaggio, gli autori prendono il modello affinato dal passaggio 1 e ne riducono la dimensione a 1.3 miliardi di parametri, che viene poi nuovamente affinato utilizzando un algoritmo di rinforzo PPO in un ambiente bandit. Questo significa fondamentalmente che al modello viene fornito un prompt arbitrario dall’utente e il modello produce una risposta. Il modello di ricompensa prende la risposta e fornisce una ricompensa scalare. Il modello apprendista cerca di trovare una politica ottimale per massimizzare la ricompensa rispetto al modello di ricompensa.
Risultati: Questi sono stati osservati quando InstructGPT è stato valutato in base all’obiettivo di un comportamento e una performance allineati alle esigenze umane:
- Gli annotatori preferiscono significativamente gli output di InstructGPT rispetto agli output di GPT-3.
- I modelli di InstructGPT mostrano miglioramenti nella veridicità rispetto a GPT-3.
- InstructGPT mostra piccoli miglioramenti nella tossicità rispetto a GPT-3, ma nessun pregiudizio.
- L’InstructGPT non riflette sui modelli di linguaggio su cui è addestrato quando predice dataset pubblici.
- Il modello esegue bene la generalizzazione dei principi quando testato su dati al di fuori del dominio di affinamento.
- InstructGPT commette ancora errori semplici. Ad esempio, InstructGPT può ancora non seguire le istruzioni, inventare fatti, dare risposte lunghe e incerte a domande semplici o non riuscire a rilevare istruzioni con premesse false.
Link al paper: https://arxiv.org/pdf/2203.02155.pdf
ChatGPT
Dopo il successo immediato del modello InstructGPT, OpenAI ha deciso di affinare ulteriormente il modello InstructGPT su testi conversazionali più generali, per introdurre caratteristiche basate su chatbot nel modello. Così è nato chatGPT, che è più simile a un essere umano e possiede migliori capacità conversazionali. Quindi, chatGPT è stato creato per un compito specifico ed è una versione molto più piccola del modello originale GPT3.
Conclusioni
ChatGPT ha avuto un impatto significativo nel mondo della tecnologia come strumento che può rivoluzionare le cose. Dopo il successo, ora OpenAI, con il supporto di Microsoft, ha rilasciato anche GPT-4, che estende la potenza di GPT anche alle immagini. Le specifiche del modello non sono state rilasciate per motivi di sicurezza. Google, d’altra parte, ha lanciato anche la sua avventura nel mondo dei chatbot con BARD, che è alimentato dai modelli sottostanti LAMDA o Language Models for Dialog Applications. Anche l’obiettivo di LAMDA è molto simile a quello di chatGPT, ovvero costruire un chatbot che possa essere allineato alle esigenze umane e che possa produrre risposte veritiere e non tossiche.
Link agli articoli:
GPT4: https://arxiv.org/pdf/2303.08774.pdf
LAMDA: https://arxiv.org/pdf/2201.08239.pdf
Oltre a questi, ci sono stati anche diversi miglioramenti come XLNet e Ernie. I colossi tecnologici sono alla ricerca di miglioramenti costanti nel campo con la speranza di un futuro tecnicamente più forte.
Spero che questo sia utile. Buona lettura!!