SQL per Data Science Comprendere e Sfruttare le Join
SQL per Data Science Join

La data science è un campo interdisciplinare che si basa molto sull’estrazione di informazioni e sulla presa di decisioni informate da grandi quantità di dati. Uno degli strumenti fondamentali nel toolkit di un data scientist è SQL (Structured Query Language), un linguaggio di programmazione progettato per gestire e manipolare database relazionali.
In questo articolo, mi concentrerò su una delle funzionalità più potenti di SQL: le joins.
- 10 Migliori Scribes Medici AI
- L’Impatto dell’IA Generativa sul Futuro del Lavoro 5 Chiavi di Lettura dal Rapporto McKinsey
- Questo articolo sull’IA propone un paradigma efficace per addestrare la navigazione visione-e-linguaggio su larga scala (VLN) e valuta quantitativamente l’influenza di ciascun componente nel processo.
Cosa sono le Joins in SQL?
Le Joins in SQL ti consentono di combinare dati da più tabelle di database basandoti su colonne comuni. In questo modo, puoi unire le informazioni e creare connessioni significative tra set di dati correlati.
Tipi di Joins in SQL
Esistono diversi tipi di Joins in SQL:
- Inner join
- Left outer join
- Right outer join
- Full outer join
- Cross join
Spieghiamo ognuno di questi tipi.
SQL Inner Join
Un inner join restituisce solo le righe in cui c’è una corrispondenza in entrambe le tabelle che vengono unite. Combina le righe di due tabelle basandosi su una chiave o una colonna in comune, scartando le righe non corrispondenti.
Visualizziamo questo nel seguente modo. 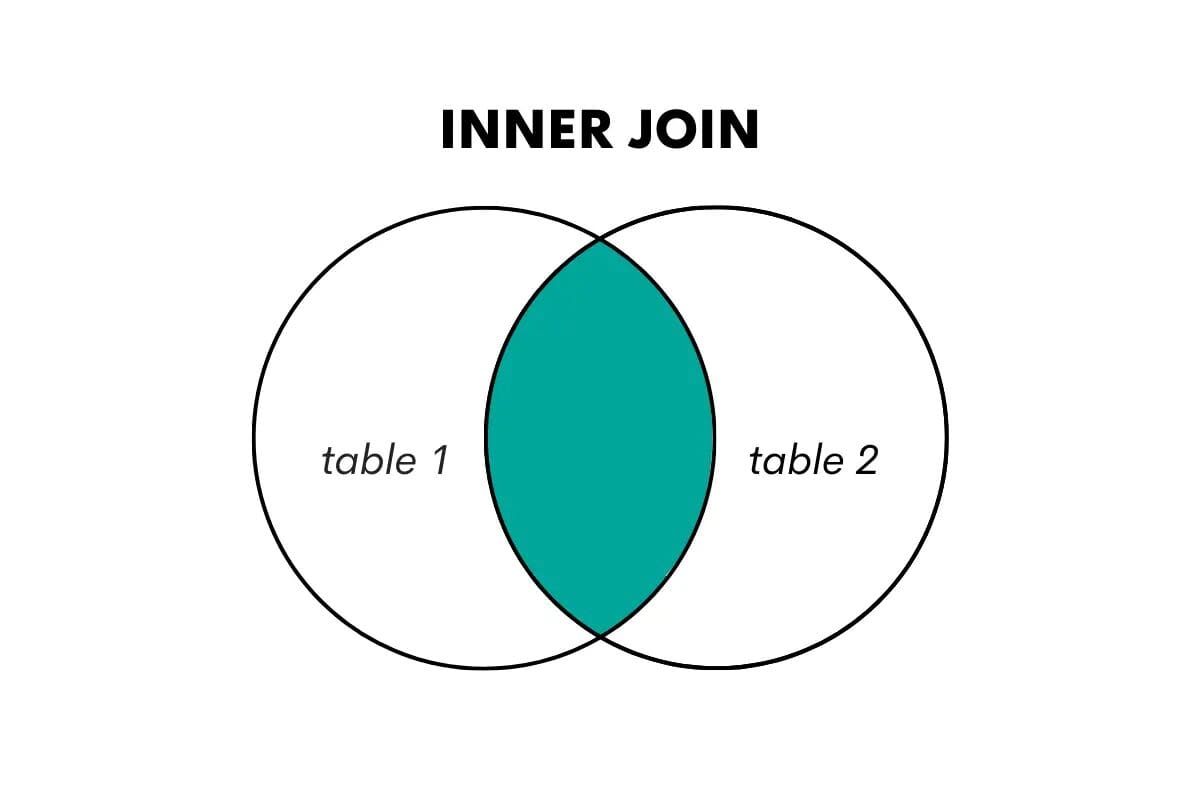
In SQL, questo tipo di join viene eseguito utilizzando le parole chiave JOIN o INNER JOIN.
SQL Left Outer Join
Un left outer join restituisce tutte le righe dalla tabella di sinistra (o la prima tabella) e le righe corrispondenti dalla tabella di destra (o la seconda tabella). Se non c’è una corrispondenza, restituisce valori NULL per le colonne della tabella di destra.
Possiamo visualizzarlo in questo modo.
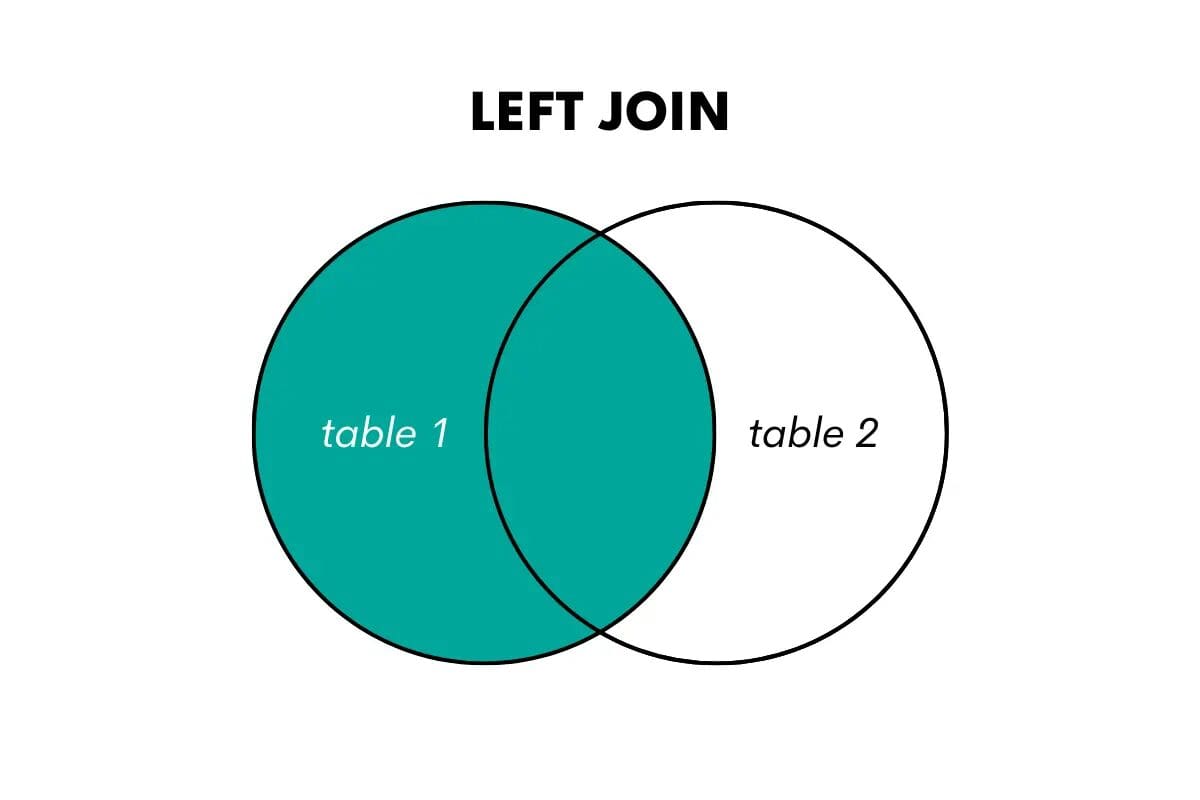
Quando si desidera utilizzare questo join in SQL, è possibile farlo utilizzando le parole chiave LEFT OUTER JOIN o LEFT JOIN. Ecco un articolo che parla di left join vs left outer join.
SQL Right Outer Join
Un right join è l’opposto di un left join. Restituisce tutte le righe dalla tabella di destra e le righe corrispondenti dalla tabella di sinistra. Se non c’è una corrispondenza, restituisce valori NULL per le colonne della tabella di sinistra.
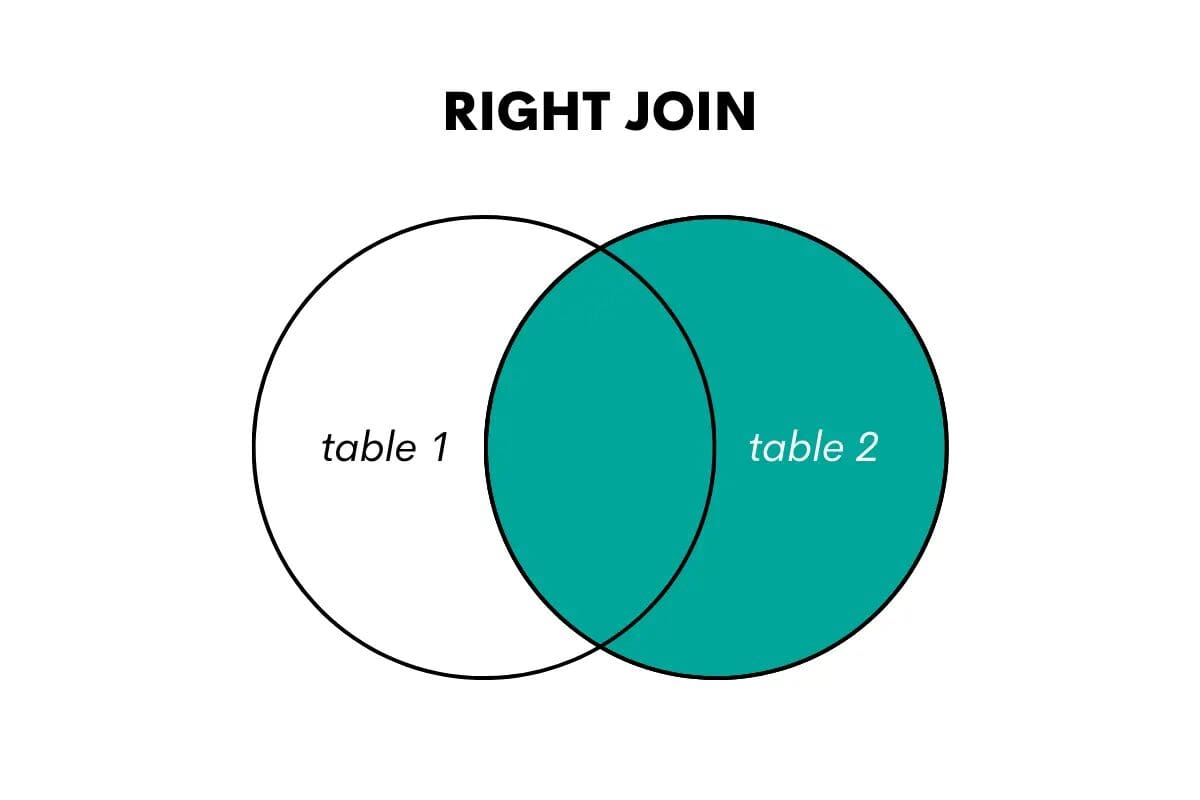
In SQL, questo tipo di join viene eseguito utilizzando le parole chiave RIGHT OUTER JOIN o RIGHT JOIN.
SQL Full Outer Join
Un full outer join restituisce tutte le righe da entrambe le tabelle, combinando le righe corrispondenti quando possibile e inserendo valori NULL per le righe non corrispondenti.
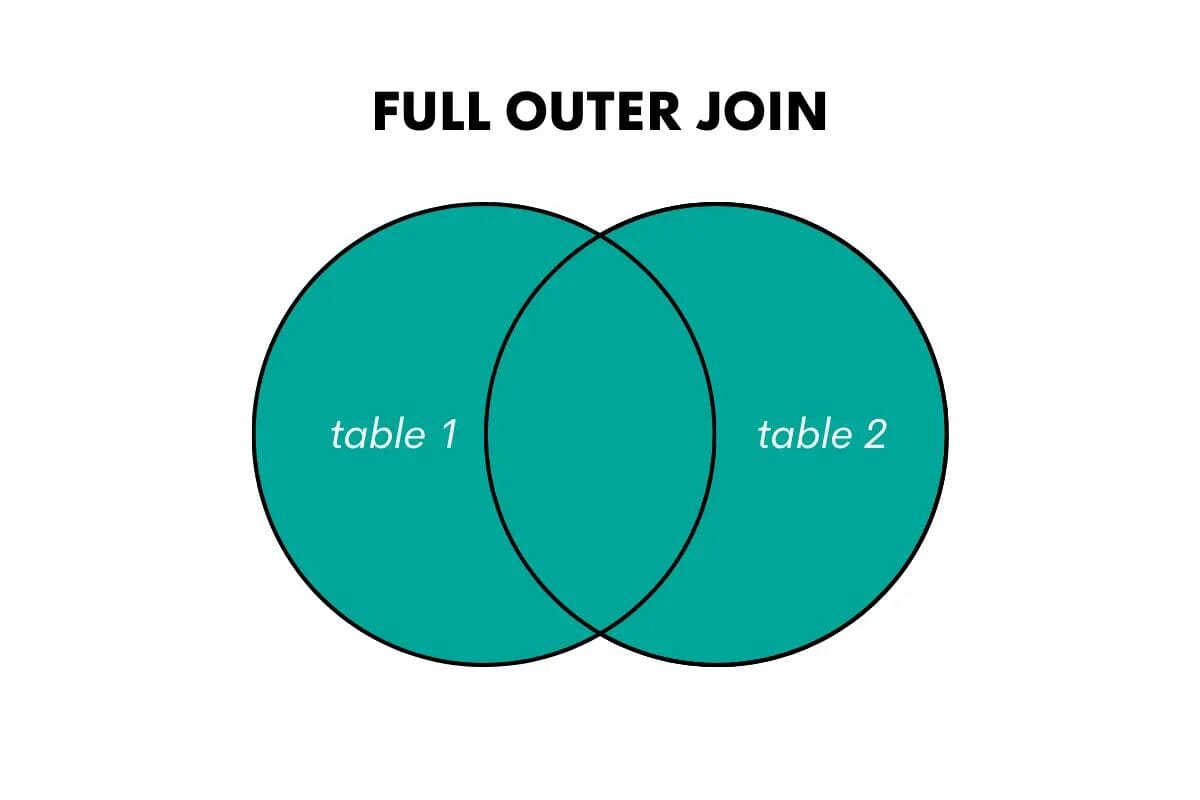
Le parole chiave in SQL per questo join sono FULL OUTER JOIN o FULL JOIN.
SQL Cross Join
Questo tipo di join combina tutte le righe di una tabella con tutte le righe della seconda tabella. In altre parole, restituisce il prodotto cartesiano, ovvero tutte le possibili combinazioni delle righe delle due tabelle.
Ecco la visualizzazione che faciliterà la comprensione.
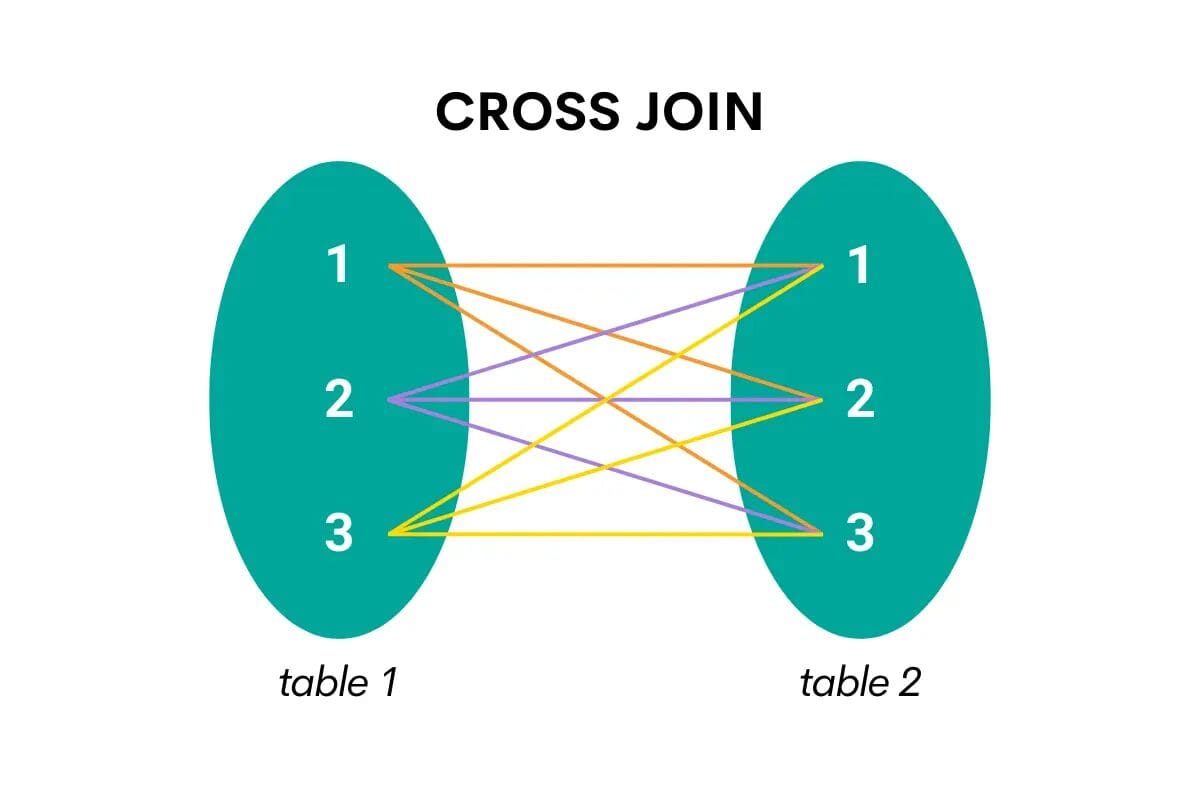
Quando si effettua un cross-join in SQL, la parola chiave è CROSS JOIN.
Comprensione della sintassi di un Join in SQL
Per eseguire un join in SQL, è necessario specificare le tabelle che vogliamo unire, le colonne utilizzate per il matching e il tipo di join che vogliamo eseguire. La sintassi di base per unire le tabelle in SQL è la seguente:
SELECT colonne
FROM tabella1
JOIN tabella2
ON tabella1.colonna = tabella2.colonna;
Questo esempio mostra come utilizzare il JOIN.
Si fa riferimento alla prima (o sinistra) tabella nella clausola FROM. Poi si segue con JOIN e si fa riferimento alla seconda (o destra) tabella.
Poi viene la condizione di unione nella clausola ON. Qui si specifica quali colonne verranno utilizzate per unire le due tabelle. Di solito, si tratta di una colonna condivisa che è una chiave primaria in una tabella e una chiave esterna nella seconda tabella.
Nota: Una chiave primaria è un identificatore univoco per ogni record in una tabella. Una chiave esterna stabilisce un collegamento tra due tabelle, cioè è una colonna nella seconda tabella che fa riferimento alla prima tabella. Ti mostreremo negli esempi cosa significa.
Se si desidera utilizzare LEFT JOIN, RIGHT JOIN o FULL JOIN, è sufficiente utilizzare queste parole chiave al posto di JOIN – tutto il resto del codice è esattamente lo stesso!
Le cose sono leggermente diverse con il CROSS JOIN. Per sua natura, unisce tutte le combinazioni di righe delle due tabelle. Ecco perché la clausola ON non è necessaria e la sintassi è la seguente.
SELECT colonne
FROM tabella1
CROSS JOIN tabella2;
In altre parole, si fa semplicemente riferimento a una tabella in FROM e alla seconda in CROSS JOIN.
In alternativa, è possibile fare riferimento a entrambe le tabelle in FROM e separarle con una virgola – questa è una forma abbreviata per CROSS JOIN.
SELECT colonne
FROM tabella1, tabella2;
Self Join: Un tipo speciale di unione in SQL
C’è anche un modo specifico di unire le tabelle – unire la tabella con se stessa. Questo è anche chiamato auto unione della tabella.
Non è esattamente un tipo distinto di join, poiché uno qualsiasi dei tipi di join menzionati in precedenza può essere utilizzato anche per l’auto unione.
La sintassi per l’auto unione è simile a quella che ti ho mostrato in precedenza. La differenza principale è che la stessa tabella viene referenziata in FROM e JOIN.
SELECT colonne
FROM tabella1 t1
JOIN tabella1 t2
ON t1.colonna = t2.colonna;
Inoltre, è necessario dare due alias alla tabella per distinguerli. Quello che stai facendo è unire la tabella con se stessa e trattarla come due tabelle.
Volevo solo menzionarlo qui, ma non entrerò nei dettagli. Se sei interessato all’auto unione, consulta questa guida illustrata sull’auto unione in SQL.
Esempi di Join in SQL
È ora di mostrarti come funziona tutto quello che ho menzionato nella pratica. Utilizzerò le domande di intervista sul JOIN SQL di StrataScratch per mostrare ogni tipo di join distinto in SQL.
1. Esempio di JOIN
Questa domanda di Microsoft ti chiede di elencare ogni progetto e calcolare il budget del progetto per dipendente.
Progetti Costosi
“Dati un elenco di progetti e dipendenti mappati per ogni progetto, calcola l’importo del budget del progetto allocato per ogni dipendente. L’output dovrebbe includere il titolo del progetto e il budget del progetto arrotondato all’intero più vicino. Ordina la lista per progetti con il budget più alto per dipendente per primo.”
Dati
La domanda fornisce due tabelle.
ms_projects
| id: | int |
| title: | varchar |
| budget: | int |
ms_emp_projects
| emp_id: | int |
| project_id: | int |
Ora, la colonna id nella tabella ms_projects è la chiave primaria della tabella. La stessa colonna si può trovare nella tabella ms_emp_projects, sebbene con un nome diverso: project_id. Questa è la chiave esterna della tabella, che fa riferimento alla prima tabella.
Utilizzerò queste due colonne per unire le tabelle nella mia soluzione.
Codice
SELECT title AS project,
ROUND((budget/COUNT(emp_id)::FLOAT)::NUMERIC, 0) AS budget_emp_ratio
FROM ms_projects a
JOIN ms_emp_projects b
ON a.id = b.project_id
GROUP BY title, budget
ORDER BY budget_emp_ratio DESC;
Ho unito le due tabelle utilizzando il JOIN. La tabella ms_projects è referenziata in FROM, mentre ms_emp_projects è referenziata dopo il JOIN. Ho assegnato un alias a entrambe le tabelle, permettendomi di non utilizzare i nomi lunghi delle tabelle in seguito.
Ora, devo specificare le colonne su cui voglio unire le tabelle. Ho già menzionato quali colonne sono la chiave primaria in una tabella e la chiave esterna in un’altra tabella, quindi le utilizzerò qui.
Uguaglio queste due colonne perché voglio ottenere tutti i dati in cui l’ID del progetto è lo stesso. Ho anche utilizzato gli alias delle tabelle davanti a ciascuna colonna.
Ora che ho accesso ai dati in entrambe le tabelle, posso elencare le colonne in SELECT. La prima colonna è il nome del progetto, e la seconda colonna è calcolata.
Questo calcolo utilizza la funzione COUNT() per contare il numero di dipendenti per ogni progetto. Quindi divido il budget di ogni progetto per il numero di dipendenti. Converto anche il risultato in valori decimali e lo arrotondo a zero decimali.
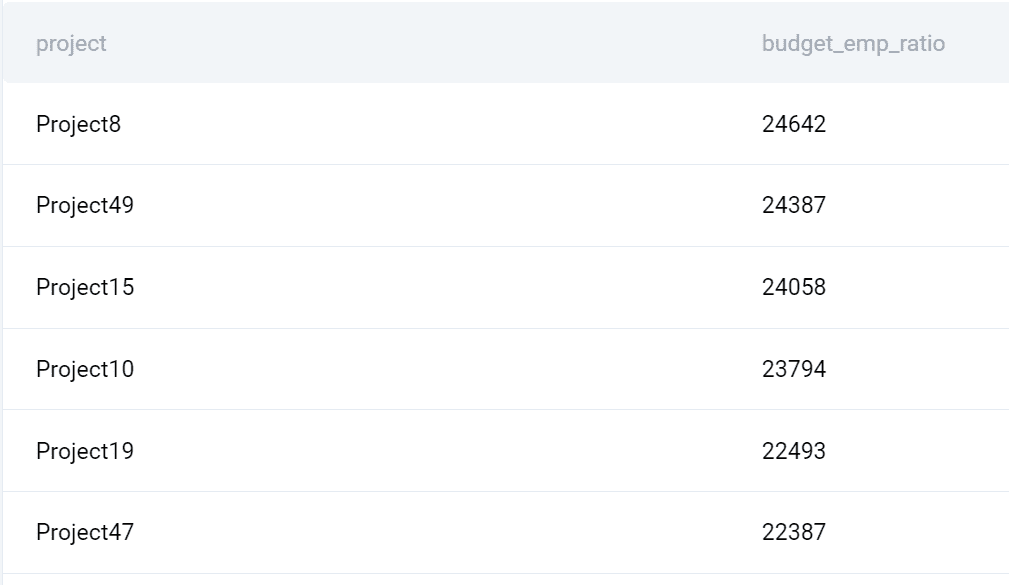
Risultato
Ecco cosa restituisce la query.
2. Esempio LEFT JOIN
Esercitiamoci su questa unione con la domanda di intervista di Airbnb. Vuole che tu trovi il numero di ordini, il numero di clienti e il costo totale degli ordini per ogni città.
Clienti, Ordini e Dettagli
“Trova il numero di ordini, il numero di clienti e il costo totale degli ordini per ogni città. Includi solo le città che hanno effettuato almeno 5 ordini e conta tutti i clienti in ogni città anche se non hanno effettuato un ordine.
Restituisci ogni calcolo insieme al nome della città corrispondente.”
Dati
Ti sono fornite le tabelle customers e orders.
customers
| id: | int |
| first_name: | varchar |
| last_name: | varchar |
| city: | varchar |
| address: | varchar |
| phone_number: | varchar |
orders
| id: | int |
| cust_id: | int |
| order_date: | datetime |
| order_details: | varchar |
| total_order_cost: | int |
Le colonne condivise sono id dalla tabella customers e cust_id dalla tabella orders. Utilizzerò queste colonne per unire le tabelle.
Codice
Ecco come risolvere questa domanda utilizzando LEFT JOIN.
SELECT c.city,
COUNT(DISTINCT o.id) AS numero_ordini_per_città,
COUNT(DISTINCT c.id) AS numero_clienti_per_città,
SUM(o.total_order_cost) AS costo_ordini_per_città
FROM customers c
LEFT JOIN orders o ON c.id = o.cust_id
GROUP BY c.city
HAVING COUNT(o.id) >=5;
Faccio riferimento alla tabella customers in FROM (questa è la nostra tabella sinistra) e la unisco con orders sulle colonne di ID del cliente.
Ora posso selezionare la città, utilizzare COUNT() per ottenere il numero di ordini e clienti per città e utilizzare SUM() per calcolare il costo totale degli ordini per città.
Per ottenere tutti questi calcoli per città, raggruppo l’output per città.
C’è una richiesta aggiuntiva nella domanda: “Includi solo le città che hanno effettuato almeno 5 ordini…” Utilizzo HAVING per mostrare solo le città con cinque o più ordini per ottenere questo risultato.
La domanda è, perché ho usato LEFT JOIN e non JOIN? La risposta è nella domanda: “…e contare tutti i clienti in ogni città anche se non hanno effettuato un ordine.” È possibile che non tutti i clienti abbiano effettuato ordini. Ciò significa che voglio visualizzare tutti i clienti dalla tabella customers, che si adatta perfettamente alla definizione di LEFT JOIN.
Se avessi usato JOIN, il risultato sarebbe stato errato, poiché avrei perso i clienti che non hanno effettuato alcun ordine.
Nota: La complessità delle join in SQL non è riflessa nella loro sintassi ma nella loro semantica! Come hai visto, ogni join è scritta allo stesso modo, cambia solo la parola chiave. Tuttavia, ogni join funziona in modo diverso e, quindi, può produrre risultati diversi a seconda dei dati. Per questo motivo, è fondamentale che tu comprenda appieno cosa fa ogni join e scegli quella che restituirà esattamente ciò che desideri!
Output
Ora, diamo un’occhiata all’output.

3. Esempio RIGHT JOIN
Il RIGHT JOIN è l’immagine speculare del LEFT JOIN. Ecco perché avrei potuto risolvere facilmente il problema precedente utilizzando il RIGHT JOIN. Vediamo come farlo.
Dati
Le tabelle rimangono le stesse; utilizzerò solo un tipo di join diverso.
Codice
SELECT c.city,
COUNT(DISTINCT o.id) AS numero_ordini_per_città,
COUNT(DISTINCT c.id) AS numero_clienti_per_città,
SUM(o.total_order_cost) AS costo_ordini_per_città
FROM orders o
RIGHT JOIN customers c ON o.cust_id = c.id
GROUP BY c.city
HAVING COUNT(o.id) >=5;
Ecco cosa è cambiato. Poiché sto usando RIGHT JOIN, ho invertito l’ordine delle tabelle. Ora la tabella orders diventa quella di sinistra e la tabella customers quella di destra. La condizione di unione rimane la stessa. Ho appena invertito l’ordine delle colonne per riflettere l’ordine delle tabelle, ma non è necessario farlo.
Scambiando l’ordine delle tabelle e utilizzando RIGHT JOIN, otterrò nuovamente tutti i clienti, anche se non hanno effettuato ordini.
Il resto della query è lo stesso dell’esempio precedente. Lo stesso vale per l’output.
Nota: Nella pratica, RIGHT JOIN viene utilizzato relativamente raramente. Il LEFT JOIN sembra più naturale agli utenti di SQL, quindi lo usano molto più spesso. Tutto ciò che può essere fatto con RIGHT JOIN può essere fatto anche con LEFT JOIN. Per questo motivo, non esiste una situazione specifica in cui potrebbe essere preferito RIGHT JOIN.
Output
4. Esempio FULL JOIN
La domanda di Salesforce e Tesla vuole che tu conti la differenza netta tra il numero di prodotti lanciati dalle aziende nel 2020 e il numero di prodotti lanciati dalle aziende nell’anno precedente.
Nuovi prodotti
“Viene fornita una tabella con i lanci di prodotti per azienda per anno. Scrivi una query per contare la differenza netta tra il numero di prodotti lanciati dalle aziende nel 2020 e il numero di prodotti lanciati nell’anno precedente. Restituisci il nome delle aziende e la differenza netta dei prodotti lanciati per il 2020 rispetto all’anno precedente.”
Dati
La domanda fornisce una tabella con le seguenti colonne.
car_launches
| year: | int |
| company_name: | varchar |
| product_name: | varchar |
Come farò ad unire le tabelle quando c’è solo una tabella? Hmm, vediamo anche questo!
Codice
Questa query è un po’ più complicata, quindi la rivelerò gradualmente.
SELECT company_name,
product_name AS brand_2020
FROM car_launches
WHERE YEAR = 2020;
La prima istruzione SELECT trova il nome dell’azienda e il nome del prodotto nel 2020. Questa query verrà successivamente trasformata in una sottoquery.
La domanda vuole che tu trovi la differenza tra il 2020 e il 2019. Quindi scriviamo la stessa query ma per il 2019.
SELECT company_name,
product_name AS brand_2019
FROM car_launches
WHERE YEAR = 2019;
Ora trasformerò queste query in sottoquery e le unirò utilizzando il FULL OUTER JOIN.
SELECT *
FROM
(SELECT company_name,
product_name AS brand_2020
FROM car_launches
WHERE YEAR = 2020) a
FULL OUTER JOIN
(SELECT company_name,
product_name AS brand_2019
FROM car_launches
WHERE YEAR = 2019) b
ON a.company_name = b.company_name;
Le sottoquery possono essere trattate come tabelle e, pertanto, possono essere unite. Ho dato alla prima sottoquery un alias e l’ho inserita nella clausola FROM. Poi uso il FULL OUTER JOIN per unirla alla seconda sottoquery sulla colonna del nome dell’azienda.
Utilizzando questo tipo di join SQL, otterrò tutte le aziende e i prodotti del 2020 uniti a tutte le aziende e i prodotti del 2019.
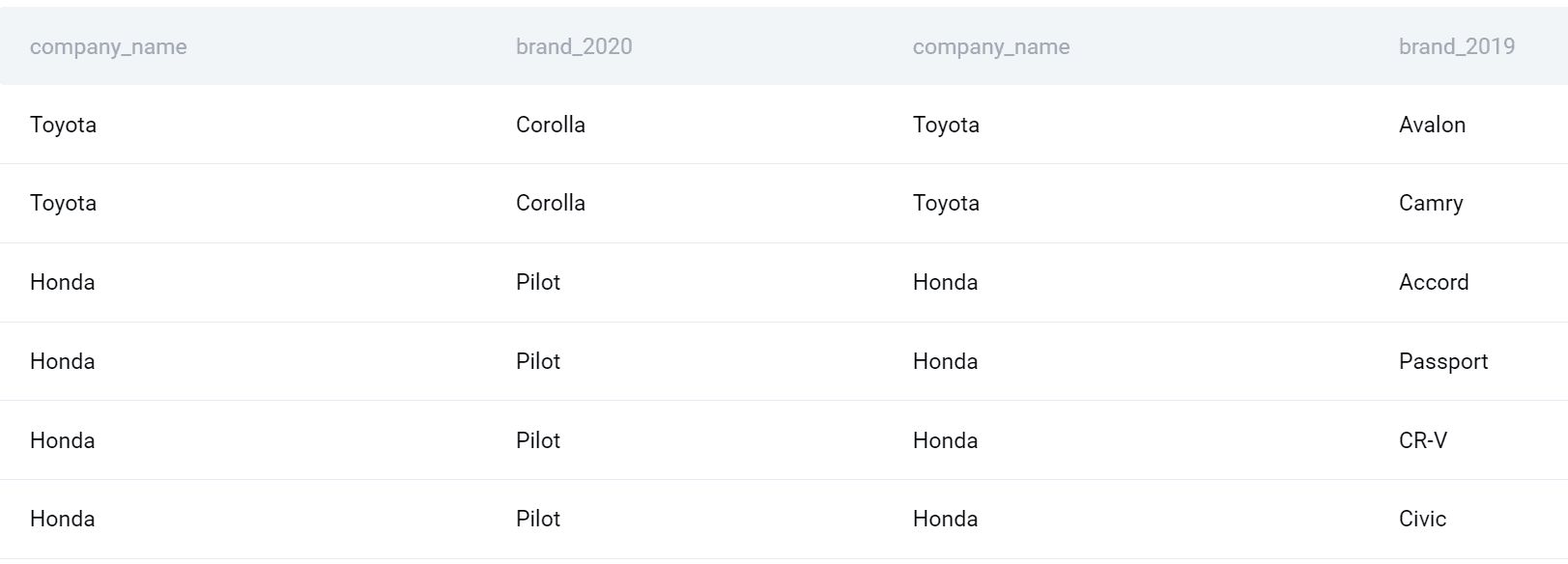
Ora posso finalizzare la mia query. Selezioniamo il nome dell’azienda. Inoltre, utilizzo la funzione COUNT() per trovare il numero di prodotti lanciati in ogni anno e poi lo sottraggo per ottenere la differenza. Infine, raggruppo l’output per azienda e lo ordino anche per azienda in ordine alfabetico.
Ecco l’intera query.
SELECT a.company_name,
(COUNT(DISTINCT a.brand_2020)-COUNT(DISTINCT b.brand_2019)) AS net_products
FROM
(SELECT company_name,
product_name AS brand_2020
FROM car_launches
WHERE YEAR = 2020) a
FULL OUTER JOIN
(SELECT company_name,
product_name AS brand_2019
FROM car_launches
WHERE YEAR = 2019) b
ON a.company_name = b.company_name
GROUP BY a.company_name
ORDER BY company_name;
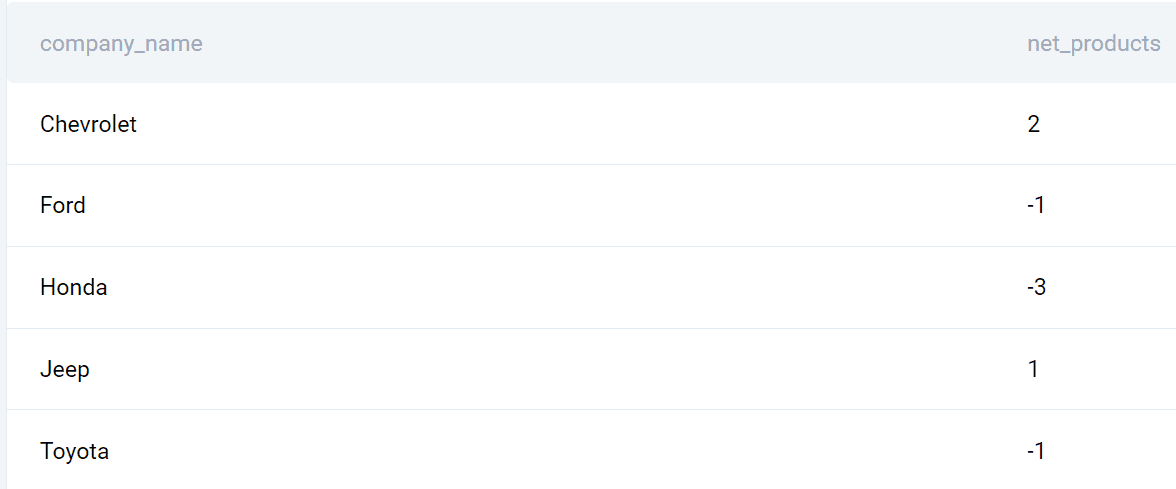
Output
Ecco l’elenco delle aziende e la differenza dei prodotti lanciati tra il 2020 e il 2019.
5. Esempio di CROSS JOIN
Questa domanda di Deloitte è ottima per mostrare come funziona il CROSS JOIN.
Massimo di due numeri
“Dato una singola colonna di numeri, considera tutte le possibili permutazioni di due numeri assumendo che le coppie di numeri (x,y) e (y,x) siano due diverse permutazioni. Poi, per ogni permutazione, trova il massimo dei due numeri.
Output tre colonne: il primo numero, il secondo numero e il massimo dei due.”
La domanda vuole che tu trovi tutte le possibili permutazioni di due numeri assumendo che le coppie di numeri (x,y) e (y,x) siano due diverse permutazioni. Poi, dobbiamo trovare il massimo dei numeri per ogni permutazione.
Dati
La domanda ci fornisce una tabella con una colonna.
deloitte_numeri
| numero: | int |
Codice
Questo codice è un esempio di CROSS JOIN, ma anche di self join.
SELECT dn1.numero AS numero1,
dn2.numero AS numero2,
CASE
WHEN dn1.numero > dn2.numero THEN dn1.numero
ELSE dn2.numero
END AS numero_massimo
FROM deloitte_numeri AS dn1
CROSS JOIN deloitte_numeri AS dn2;
Faccio riferimento alla tabella in FROM e le do un alias. Poi faccio un CROSS JOIN con se stessa facendo riferimento ad essa dopo CROSS JOIN e dando alla tabella un altro alias.
Ora è possibile utilizzare una tabella come se fossero due. Seleziono la colonna numero da ciascuna tabella. Poi uso la dichiarazione CASE per impostare una condizione che mostrerà il numero massimo dei due numeri.
Perché viene utilizzato il CROSS JOIN qui? Ricorda, è un tipo di join SQL che mostrerà tutte le combinazioni di tutte le righe di tutte le tabelle. Ecco esattamente ciò che la domanda sta chiedendo!
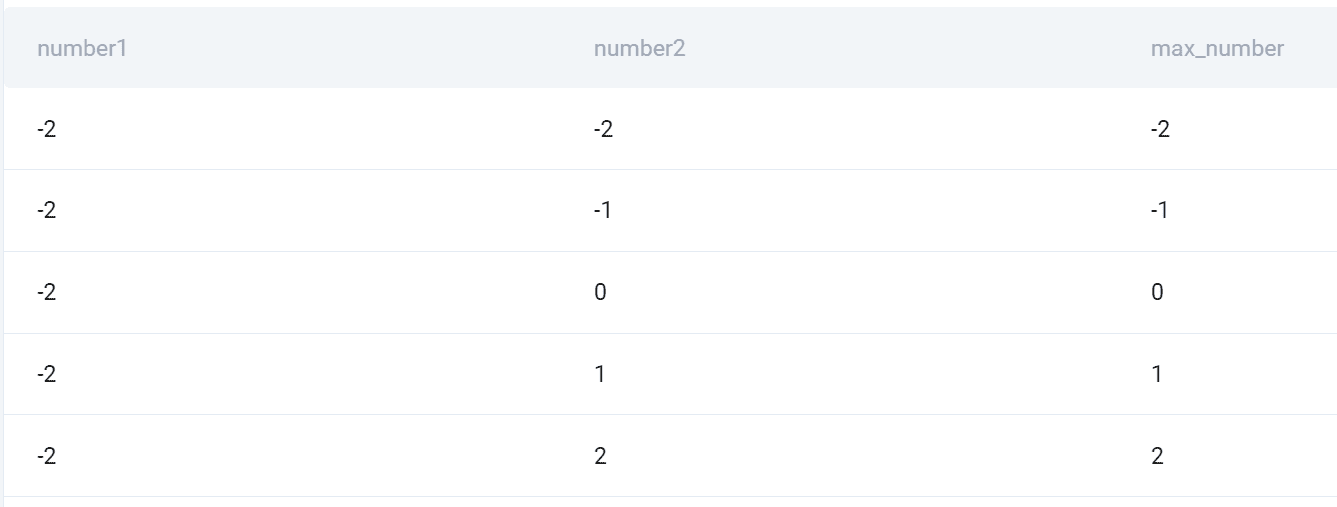
Output
Ecco lo snapshot di tutte le combinazioni e il numero maggiore dei due.
Utilizzo di SQL Joins per la scienza dei dati
Ora che sai come utilizzare i JOIN SQL, la domanda è come utilizzare quella conoscenza nella scienza dei dati.
I JOIN SQL svolgono un ruolo fondamentale nelle attività di scienza dei dati come l’esplorazione dei dati, la pulizia dei dati e l’ingegneria delle feature.
Ecco alcuni esempi di come i JOIN SQL possono essere sfruttati:
- Unione dei dati: Unire le tabelle consente di mettere insieme diverse fonti di dati, consentendoti di analizzare relazioni e correlazioni tra più dataset. Ad esempio, unire una tabella dei clienti con una tabella delle transazioni può fornire informazioni sul comportamento dei clienti e sui modelli di acquisto.
- Convalida dei dati: I JOIN possono essere utilizzati per convalidare la qualità e l’integrità dei dati. Confrontando i dati di diverse tabelle, è possibile individuare incongruenze, valori mancanti o outlier. Questo ti aiuta nella pulizia dei dati e garantisce che i dati utilizzati per l’analisi siano accurati e affidabili.
- Ingegneria delle feature: I JOIN possono essere strumentali nella creazione di nuove feature per i modelli di machine learning. Unendo tabelle rilevanti, è possibile estrarre informazioni significative e generare feature che catturano relazioni importanti all’interno dei dati. Questo può migliorare la capacità predittiva dei tuoi modelli.
- Aggregazione e analisi: I JOIN ti consentono di eseguire aggregazioni e analisi complesse su più tabelle. Unendo dati da varie fonti, è possibile ottenere una visione completa dei dati e ricavare informazioni preziose. Ad esempio, unire una tabella delle vendite con una tabella dei prodotti può aiutarti ad analizzare le prestazioni delle vendite per categoria di prodotto o per regione.
Linee guida per le join in SQL
Come ho già detto, la complessità delle join non si riflette nella loro sintassi. Hai visto che la sintassi è relativamente semplice.
Le linee guida per le join riflettono anche questo concetto, in quanto non si occupano della codifica in sé, ma di ciò che fa la join e come si comporta.
Per ottenere il massimo dalle join in SQL, considera le seguenti linee guida:
- Comprendi i tuoi dati: Familiarizzati con la struttura e le relazioni all’interno dei tuoi dati. Questo ti aiuterà a scegliere il tipo di join appropriato e a selezionare le colonne corrette per il matching.
- Usa gli indici: Se le tue tabelle sono grandi o spesso unite, considera l’aggiunta di indici sulle colonne utilizzate per l’unione. Gli indici possono migliorare significativamente le prestazioni delle query.
- Considera le prestazioni: Unire tabelle di grandi dimensioni o più tabelle può richiedere molto tempo computazionale. Ottimizza le tue query filtrando i dati, utilizzando tipi di join appropriati e prendendo in considerazione l’uso di tabelle temporanee o subquery.
- Testa e convalida: Verifica sempre i risultati delle join per assicurarti la correttezza. Esegui controlli di validità e verifica che i dati uniti siano coerenti con le tue aspettative e la logica aziendale.
Conclusione
Le join in SQL sono un concetto fondamentale che ti permette, come data scientist, di unire e analizzare dati da diverse fonti. Comprendendo i diversi tipi di join in SQL, padroneggiando la loro sintassi e sfruttandoli in modo efficace, i data scientist possono ottenere preziose informazioni, convalidare la qualità dei dati e prendere decisioni basate sui dati.
Ti ho mostrato come farlo in cinque esempi. Ora spetta a te sfruttare il potere di SQL e delle join per i tuoi progetti di data science e ottenere risultati migliori. Nate Rosidi è un data scientist e specializzato in strategia di prodotto. È anche un professore a contratto che insegna analisi dati ed è il fondatore di StrataScratch, una piattaforma che aiuta i data scientist a prepararsi per i colloqui di lavoro con vere domande di intervista dalle migliori aziende. Puoi connetterti con lui su Twitter: StrataScratch o LinkedIn.