7 Passaggi per Padroneggiare le Tecniche di Pulizia e Preelaborazione dei Dati
7 Passi per Pulizia e Preelaborazione dei Dati
Padroneggiare le tecniche di pulizia e pre-elaborazione dei dati è fondamentale per risolvere molti progetti di data science. Una semplice dimostrazione di quanto sia importante può essere trovata nel meme sulle aspettative di uno studente che studia data science prima di lavorare, confrontato con la realtà del lavoro di data scientist.
Tendiamo ad idealizzare la posizione lavorativa prima di avere un’esperienza concreta, ma la realtà è sempre diversa da ciò che ci aspettiamo realmente. Quando si lavora con un problema del mondo reale, non c’è documentazione sui dati e il dataset è molto sporco. Prima di tutto, è necessario scavare a fondo nel problema, capire quali indizi ci mancano e quali informazioni si possono estrarre.
Dopo aver compreso il problema, è necessario preparare il dataset per il modello di machine learning poiché i dati nella loro condizione iniziale non sono mai sufficienti. In questo articolo, mostrerò sette passaggi che possono aiutarti nella pre-elaborazione e pulizia del tuo dataset.
- Esperimenti statistici con il resampling
- Tutto ciò che devi sapere sull’analisi sportiva nel 2023
- Applicazione web Linguistic Email Composer utilizzando OpenAI e Langchain
Passaggio 1: Analisi Esplorativa dei Dati
Il primo passaggio in un progetto di data science è l’analisi esplorativa, che aiuta a comprendere il problema e prendere decisioni nei passaggi successivi. Spesso viene saltata, ma è l’errore peggiore perché si perderà molto tempo in seguito per trovare il motivo per cui il modello restituisce errori o non si comporta come previsto.
In base alla mia esperienza come data scientist, dividerei l’analisi esplorativa in tre parti:
- Verificare la struttura del dataset, le statistiche, i valori mancanti, i duplicati, i valori unici delle variabili categoriche
- Comprendere il significato e la distribuzione delle variabili
- Studiare le relazioni tra le variabili
Per analizzare come il dataset è organizzato, ci sono i seguenti metodi di Pandas che possono aiutarti:
df.head()
df.info()
df.isnull().sum()
df.duplicated().sum()
df.describe([x*0.1 for x in range(10)])
for c in list(df):
print(df[c].value_counts())
Quando si cerca di capire le variabili, è utile suddividere l’analisi in due parti ulteriori: caratteristiche numeriche e caratteristiche categoriche. Prima, ci possiamo concentrare sulle caratteristiche numeriche che possono essere visualizzate tramite istogrammi e boxplot. Dopo, è il turno delle variabili categoriche. Nel caso si tratti di un problema binario, è meglio iniziare controllando se le classi sono bilanciate. Successivamente, possiamo concentrare la nostra attenzione sulle variabili categoriche rimanenti utilizzando i grafici a barre. Alla fine, possiamo finalmente controllare la correlazione tra ogni coppia di variabili numeriche. Altre visualizzazioni utili possono essere i grafici a dispersione e i boxplot per osservare le relazioni tra una variabile numerica e una variabile categorica.
Passaggio 2: Gestione dei Valori Mancanti
Nel primo passaggio, abbiamo già verificato se ci sono valori mancanti in ogni variabile. Nel caso ci siano valori mancanti, è necessario capire come gestire il problema. Il modo più semplice sarebbe quello di rimuovere le variabili o le righe che contengono valori NaN, ma preferiremmo evitarlo perché rischiamo di perdere informazioni utili che possono aiutare il nostro modello di machine learning a risolvere il problema.
Se stiamo gestendo una variabile numerica, ci sono diversi approcci per riempirla. Il metodo più popolare consiste nel riempire i valori mancanti con la media/mediana di quella caratteristica:
df['age'].fillna(df['age'].mean())
df['age'].fillna(df['age'].median())
Un altro modo è sostituire gli spazi vuoti con imputazioni raggruppate:
df['price'].fillna(df.groupby('type_building')['price'].transform('mean'),
inplace=True)
Può essere una migliore opzione nel caso ci sia una forte relazione tra una caratteristica numerica e una caratteristica categorica.
Allo stesso modo, possiamo riempire i valori mancanti delle variabili categoriche in base alla moda di quella variabile:
df['type_building'].fillna(df['type_building'].mode()[0])
Passaggio 3: Gestione dei Duplicati e degli Outlier
Se ci sono duplicati all’interno del dataset, è meglio eliminare le righe duplicate:
df = df.drop_duplicates()
Mentre decidere come gestire i duplicati è semplice, affrontare gli outlier può essere una sfida. Devi chiederti “Eliminare o non eliminare gli outlier?”.
Gli outlier dovrebbero essere eliminati se sei sicuro che forniscono solo informazioni rumorose. Ad esempio, il dataset contiene due persone con 200 anni, mentre l’intervallo di età è compreso tra 0 e 90. In quel caso, è meglio rimuovere questi due punti dati.
df = df[df.Age<=90]
Purtroppo, nella maggior parte dei casi rimuovere gli outlier può comportare la perdita di informazioni importanti. Il modo più efficiente è applicare la trasformazione logaritmica alla caratteristica numerica.
Un’altra tecnica che ho scoperto durante la mia ultima esperienza è il metodo del clipping. In questa tecnica, si scelgono il limite superiore e il limite inferiore, che possono essere il percentile 0,1 e il percentile 0,9. I valori della caratteristica al di sotto del limite inferiore verranno sostituiti con il valore del limite inferiore, mentre i valori della variabile al di sopra del limite superiore verranno sostituiti con il valore del limite superiore.
for c in colonne_con_outlier:
trasformazione= 'clipped_'+ c
limite_inferiore = df[c].quantile(0.10)
limite_superiore = df[c].quantile(0.90)
df[trasformazione] = df[c].clip(limite_inferiore, limite_superiore, axis = 0)
Passaggio 4: Codifica delle caratteristiche categoriche
La fase successiva consiste nel convertire le caratteristiche categoriche in caratteristiche numeriche. Infatti, il modello di apprendimento automatico è in grado di lavorare solo con numeri, non con stringhe.
Prima di procedere, è necessario distinguere due tipi di variabili categoriche: variabili non ordinali e variabili ordinali.
Esempi di variabili non ordinali sono il genere, lo stato civile, il tipo di lavoro. Quindi, è non ordinale se la variabile non segue un ordine, diversamente dalle caratteristiche ordinali. Un esempio di variabili ordinali può essere l’istruzione con valori “infanzia”, “primaria”, “secondaria” e “terziaria”, e il reddito con livelli “basso”, “VoAGI” e “alto”.
Quando si tratta di variabili non ordinali, la tecnica più popolare da prendere in considerazione per convertire queste variabili in numeriche è la codifica One-Hot.
In questo metodo, si crea una nuova variabile binaria per ogni livello della caratteristica categorica. Il valore di ogni variabile binaria è 1 quando il nome del livello coincide con il valore del livello, altrimenti è 0.
from sklearn.preprocessing import OneHotEncoder
dati_da_codificare = df[colonne_da_codificare]
codificatore = OneHotEncoder(dtype='int')
dati_codificati = codificatore.fit_transform(dati_da_codificare)
variabili_dummy = codificatore.get_feature_names_out(colonne_da_codificare)
df_codificato = pd.DataFrame(dati_codificati.toarray(), columns=codificatore.get_feature_names_out(colonne_da_codificare))
df_finale = pd.concat([df.drop(colonne_da_codificare, axis=1), df_codificato], axis=1)
Quando la variabile è ordinale, la tecnica più comune utilizzata è la codifica ordinale, che consiste nel convertire i valori unici della variabile categorica in interi che seguono un ordine. Ad esempio, i livelli “basso”, “VoAGI” e “Alto” del reddito verranno codificati rispettivamente come 0, 1 e 2.
from sklearn.preprocessing import OrdinalEncoder
dati_da_codificare = df[colonne_da_codificare]
codificatore = OrdinalEncoder(dtype='int')
dati_codificati = codificatore.fit_transform(dati_da_codificare)
df_codificato = pd.DataFrame(dati_codificati.toarray(), columns=["Reddito"])
df_finale = pd.concat([df.drop(colonne_da_codificare, axis=1), df_codificato], axis=1)
Ci sono altre possibili tecniche di codifica se vuoi esplorare qui. Puoi dare un’occhiata qui nel caso tu sia interessato a alternative.
Passaggio 5: Suddividere il dataset in set di allenamento e di test
È arrivato il momento di dividere il dataset in tre sottoinsiemi fissi: la scelta più comune è utilizzare il 60% per l’allenamento, il 20% per la validazione e il 20% per il test. Man mano che la quantità di dati aumenta, la percentuale per l’allenamento aumenta e la percentuale per la validazione e il test diminuisce.
È importante avere tre sottoinsiemi perché l’insieme di addestramento viene utilizzato per addestrare il modello, mentre i sottoinsiemi di convalida e di prova possono essere utili per capire come il modello si sta comportando su nuovi dati.
Per suddividere il dataset, possiamo utilizzare la funzione train_test_split di scikit-learn:
from sklearn.model_selection import train_test_split
X = final_df.drop(['y'],axis=1)
y = final_df['y']
train_idx, test_idx,_,_ = train_test_split(X.index,y,test_size=0.2,random_state=123)
train_idx, val_idx,_,_ = train_test_split(train_idx,y_train,test_size=0.2,random_state=123)
df_train = final_df[final_df.index.isin(train_idx)]
df_test = final_df[final_df.index.isin(test_idx)]
df_val = final_df[final_df.index.isin(val_idx)]
Nel caso in cui ci troviamo di fronte a un problema di classificazione e le classi non sono bilanciate, è meglio impostare l’argomento stratify per assicurarsi che ci sia la stessa proporzione di classi nei sottoinsiemi di addestramento, convalida e prova.
train_idx, test_idx,y_train,_ = train_test_split(X.index,y,test_size=0.2,stratify=y,random_state=123)
train_idx, val_idx,_,_ = train_test_split(train_idx,y_train,test_size=0.2,stratify=y_train,random_state=123)
Questa cross-validazione stratificata aiuta anche a garantire che ci sia la stessa percentuale di variabili target nei tre sottoinsiemi e fornisce prestazioni più accurate del modello.
Passo 6: Feature Scaling
Esistono modelli di apprendimento automatico, come la regressione lineare, la regressione logistica, il KNN, la support vector machine e le reti neurali, che richiedono la normalizzazione delle variabili. La normalizzazione delle caratteristiche serve solo a far sì che le variabili siano nella stessa gamma, senza modificare la distribuzione.
Le tre tecniche di normalizzazione delle caratteristiche più popolari sono la normalizzazione, la standardizzazione e la scalatura robusta.
La normalizzazione, chiamata anche scalatura min-max, consiste nel mappare il valore di una variabile in un intervallo compreso tra 0 e 1. Questo è possibile sottraendo il minimo della caratteristica dal valore della caratteristica e, quindi, dividendo per la differenza tra il massimo e il minimo di quella caratteristica.
from sklearn.preprocessing import MinMaxScaler
sc=MinMaxScaler()
df_train[numeric_features]=sc.fit_transform(df_train[numeric_features])
df_test[numeric_features]=sc.transform(df_test[numeric_features])
df_val[numeric_features]=sc.transform(df_val[numeric_features])
Un altro approccio comune è la standardizzazione, che ridimensiona i valori di una colonna rispettando le proprietà di una distribuzione normale standard, caratterizzata da una media pari a 0 e una varianza pari a 1.
from sklearn.preprocessing import StandardScaler
sc=StandardScaler()
df_train[numeric_features]=sc.fit_transform(df_train[numeric_features])
df_test[numeric_features]=sc.transform(df_test[numeric_features])
df_val[numeric_features]=sc.transform(df_val[numeric_features])
Se la caratteristica contiene outlier che non possono essere rimossi, un metodo preferibile è la scalatura robusta, che ridimensiona i valori di una caratteristica in base a statistiche robuste, come la mediana, il primo quartile e il terzo quartile. Il valore riscalato viene ottenuto sottraendo la mediana dal valore originale e, quindi, dividendo per l’intervallo interquartile, che è la differenza tra il 75° e il 25° quartile della caratteristica.
from sklearn.preprocessing import RobustScaler
sc=RobustScaler()
df_train[numeric_features]=sc.fit_transform(df_train[numeric_features])
df_test[numeric_features]=sc.transform(df_test[numeric_features])
df_val[numeric_features]=sc.transform(df_val[numeric_features])
In generale, è preferibile calcolare le statistiche basate sull’insieme di addestramento e poi utilizzarle per ridimensionare i valori sia sull’insieme di addestramento, di convalida e di prova. Questo perché supponiamo di avere solo i dati di addestramento e, successivamente, vogliamo testare il nostro modello su nuovi dati, che dovrebbero avere una distribuzione simile all’insieme di addestramento.
Passo 7: Gestire i dati non bilanciati
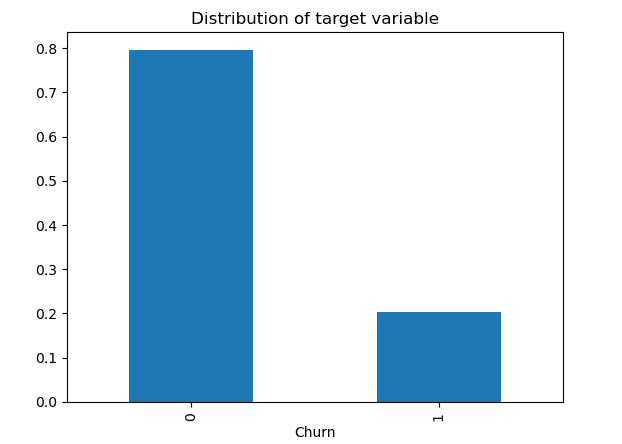
Questa fase è inclusa solo quando stiamo lavorando su un problema di classificazione e abbiamo scoperto che le classi sono sbilanciate.
Nel caso in cui ci sia una leggera differenza tra le classi, ad esempio la classe 1 contiene il 40% delle osservazioni e la classe 2 contiene il restante 60%, non è necessario applicare tecniche di sovra-campionamento o sotto-campionamento per modificare il numero di campioni in una delle classi. Possiamo semplicemente evitare di guardare all’accuratezza poiché è una buona misura solo quando il dataset è bilanciato e dovremmo preoccuparci solo delle misure di valutazione, come la precisione, il richiamo e lo score F1.
Ma può accadere che la classe positiva abbia una proporzione molto bassa di punti dati (0,2) rispetto alla classe negativa (0,8). L’apprendimento automatico potrebbe non funzionare bene con la classe con meno osservazioni, portando al fallimento nel risolvere il compito.
Per superare questo problema, ci sono due possibilità: sotto-campionare la classe maggioritaria e sovra-campionare la classe minoritaria. Il sotto-campionamento consiste nel ridurre il numero di campioni rimuovendo casualmente alcuni punti dati dalla classe maggioritaria, mentre la sovra-campionatura aumenta il numero di osservazioni nella classe minoritaria aggiungendo casualmente punti dati dalla classe meno frequente. Esiste imblearn che consente di bilanciare il dataset con poche righe di codice:
# sotto-campionamento
from imblearn.over_sampling import RandomUnderSampler,RandomOverSampler
undersample = RandomUnderSampler(sampling_strategy='majority')
X_train, y_train = undersample.fit_resample(df_train.drop(['y'],axis=1),df_train['y'])
# sovra-campionamento
oversample = RandomOverSampler(sampling_strategy='minority')
X_train, y_train = oversample.fit_resample(df_train.drop(['y'],axis=1),df_train['y'])
Tuttavia, rimuovere o duplicare alcune delle osservazioni può essere inefficace a volte nel migliorare le prestazioni del modello. Sarebbe meglio creare nuovi punti dati artificiali nella classe minoritaria. Una tecnica proposta per risolvere questo problema è SMOTE, che è nota per generare record sintetici nella classe meno rappresentata. Come KNN, l’idea è identificare i k vicini più prossimi delle osservazioni appartenenti alla classe minoritaria, basandosi su una particolare distanza, come t. Dopo di che, un nuovo punto viene generato in una posizione casuale tra questi k vicini più prossimi. Questo processo continuerà a creare nuovi punti fino a quando il dataset sarà completamente bilanciato.
from imblearn.over_sampling import SMOTE
resampler = SMOTE(random_state=123)
X_train, y_train = resampler.fit_resample(df_train.drop(['y'],axis=1),df_train['y'])
Vorrei sottolineare che questi approcci dovrebbero essere applicati solo per campionare il set di addestramento. Vogliamo che il nostro modello di apprendimento automatico impari in modo robusto e, quindi, possiamo applicarlo per fare previsioni su nuovi dati.
Considerazioni finali
Spero che tu abbia trovato utile questo tutorial esaustivo. Può essere difficile iniziare il nostro primo progetto di data science senza essere a conoscenza di tutte queste tecniche. Puoi trovare tutto il mio codice qui.
Ci sono sicuramente altri metodi che non ho trattato nell’articolo, ma ho preferito concentrarmi sui più popolari e conosciuti. Hai altre suggerimenti? Lasciali nei commenti se hai suggerimenti interessanti.
Risorse utili:
- Una guida pratica per l’analisi esplorativa dei dati
- Quali modelli richiedono dati normalizzati?
- Sovra-campionamento e sotto-campionamento casuale per la classificazione sbilanciata
Eugenia Anello è attualmente una ricercatrice presso il Dipartimento di Ingegneria dell’Informazione dell’Università di Padova, Italia. Il suo progetto di ricerca è incentrato sull’apprendimento continuo combinato con il rilevamento delle anomalie.





