Esperimenti statistici con il resampling
Esperimenti con resampling statistico
Bootstrap e test di permutazione

Introduzione
La maggior parte delle persone che lavorano con i dati effettuano osservazioni e poi si domandano se queste osservazioni siano statisticamente significative. E a meno che uno non abbia una formazione formale sull’inferenza statistica e un’esperienza passata nell’esecuzione di test di significatività, il primo pensiero che viene in mente è quello di cercare uno statistico che possa fornire consigli su come condurre il test, o almeno confermare che il test sia stato eseguito correttamente e che i risultati siano validi.
Ci sono molte ragioni per questo. Per cominciare, spesso non è immediatamente ovvio quale test sia necessario, quali formule sono alla base dei principi del test, come utilizzare le formule e se il test può essere utilizzato in primo luogo, ad esempio perché i dati non soddisfano le condizioni necessarie come la normalità. Esistono pacchetti R e Python completi per la stima di una vasta gamma di modelli statistici e per l’esecuzione di test statistici, come statsmodels.
Tuttavia, senza una piena comprensione della teoria statistica, l’utilizzo di un pacchetto replicando un esempio dalla guida per l’utente lascia spesso un senso di insicurezza, in attesa di severe critiche una volta che l’approccio viene scrutinato da uno statistico esperto. Personalmente, sono un ingegnere che nel tempo è diventato un analista dei dati. Ho seguito corsi di statistica durante i miei studi universitari e post-laurea, ma non ho utilizzato molto la statistica perché non è tipicamente ciò che fa un ingegnere per vivere. Credo che lo stesso valga per molti altri analisti dei dati e scienziati dei dati, soprattutto se la loro formazione formale è ad esempio in ingegneria, informatica o chimica.
Ho deciso di scrivere questo articolo perché mi sono reso conto di recente che la simulazione può essere facilmente utilizzata al posto di metodi statistici più classici basati su formule. La maggior parte delle persone penserebbe probabilmente immediatamente al bootstrap per stimare l’incertezza della media. Ma non si tratta solo di bootstrap. L’utilizzo del campionamento all’interno dei test di permutazione casuale può fornire risposte a molti problemi di inferenza statistica. Tali test non sono generalmente molto difficili da scrivere ed eseguire. Si applicano universalmente a dati continui o binari, indipendentemente dalle dimensioni del campione e senza fare ipotesi sulla distribuzione dei dati. In questo senso, i test di permutazione sono non parametrici e l’unico requisito è la scambievolezza, cioè la probabilità di osservare una certa sequenza di valori è la stessa per qualsiasi permutazione della sequenza. Non è davvero chiedere molto.
- Tutto ciò che devi sapere sull’analisi sportiva nel 2023
- Applicazione web Linguistic Email Composer utilizzando OpenAI e Langchain
- Incontra LP-MusicCaps un approccio di generazione di didascalie pseudo a partire dai tag utilizzando modelli di linguaggio di grandi dimensioni per affrontare il problema della scarsità di dati nell’indicazione automatica delle musiche.
La mancanza di risorse informatiche è forse stata una delle ragioni per l’impressionante sviluppo dei test di inferenza statistica basati su formule nel passato. Campionare migliaia di volte un campione di dati con decine o migliaia di record era proibitivo allora, ma non lo è più. Questo significa che i metodi classici di inferenza statistica non sono più necessari? Certo che no. Ma avere la possibilità di eseguire un test di permutazione e confermare i risultati può essere rassicurante quando i risultati sono simili, o aiutare a capire quali ipotesi non sono valide quando si osservano discrepanze. Essere in grado di eseguire un test statistico da zero senza fare affidamento su un pacchetto dà anche un certo senso di potere.
I test di permutazione non sono ovviamente una novità, ma ho pensato che fosse una buona idea fornire alcuni esempi e il relativo codice. Ciò potrebbe alleviare la paura di alcuni esperti di dati là fuori e avvicinare l’inferenza statistica utilizzando la simulazione alla loro pratica quotidiana. L’articolo utilizza i test di permutazione per rispondere a due domande. Ci sono molti altri scenari in cui può essere utilizzato un test di permutazione e per domande più complesse la progettazione di un test di permutazione potrebbe non essere immediatamente ovvia. In questo senso, l’articolo non è esaustivo. Tuttavia, i principi sono gli stessi. Comprendendo le basi sarà più facile consultare una fonte autorevole su come progettare un test di permutazione per rispondere ad altre domande imprenditoriali più nuance. La mia intenzione è quella di stimolare un modo di pensare in cui la simulazione della distribuzione della popolazione è al centro e l’utilizzo dei tiri teorici consente di stimare quale è la probabilità che un effetto osservato si verifichi per caso. Di questo si tratta il test di ipotesi.
L’inferenza statistica parte da un’ipotesi, ad esempio un nuovo farmaco è più efficace contro una determinata malattia rispetto al trattamento tradizionale. L’efficacia potrebbe essere misurata verificando la riduzione di un determinato indice ematico (variabile continua) o contando il numero di animali in cui non può essere rilevata la malattia dopo il trattamento (variabile discreta) quando si utilizza il nuovo farmaco e il trattamento tradizionale (controllo). Tali confronti tra due gruppi, noti anche come test A/B, sono ampiamente discussi in tutti i testi di statistica classica e nei popolari blog tecnici come questo. Utilizzando l’esempio del design del farmaco, testeremo se il nuovo farmaco è più efficace rispetto al trattamento tradizionale (test A/B). Basandoci su questo, stimiamo quanti animali abbiamo bisogno per stabilire che il nuovo farmaco è più efficace, assumendo che in realtà sia più efficace dell’1% (o per un’altra dimensione dell’effetto) rispetto al trattamento tradizionale. Sebbene le due domande sembrino non correlate, non lo sono. Riutilizzeremo il codice dalla prima per rispondere alla seconda. Tutto il codice può essere trovato nel mio repository del blog.
Accolgo con favore i commenti, ma per favore siano costruttivi. Non pretendo di essere uno statistico e la mia intenzione è quella di aiutare gli altri a passare attraverso un processo di apprendimento simile quando si tratta di test di permutazione.
Test A/B
Torniamo alla prima domanda, ovvero se il nuovo farmaco è più efficace del trattamento tradizionale. Quando eseguiamo un esperimento, gli animali malati vengono assegnati a due gruppi, a seconda del trattamento che ricevono. Gli animali vengono assegnati ai gruppi in modo casuale e quindi ogni differenza osservata nell’efficacia del trattamento è dovuta all’efficacia del farmaco o perché è capitato per caso che gli animali con un sistema immunitario più forte siano stati assegnati al gruppo del nuovo farmaco. Queste sono le due situazioni che dobbiamo districare. In altre parole, vogliamo verificare se il caso casuale può spiegare eventuali benefici osservati nell’uso del nuovo farmaco.
Immaginiamo alcuni numeri immaginari per fare un’illustrazione:
La variabile di risposta è binaria, ovvero il trattamento è stato o meno efficace. Il test di permutazione funzionerebbe allo stesso modo se la variabile di risposta fosse continua (non è il caso dei test statistici classici!), ma la tabella sopra conterrà medie e deviazioni standard invece di conteggi.
Intenzionalmente non utilizziamo gruppi di trattamento delle stesse dimensioni, poiché questo non è un requisito per il test di permutazione. Questo ipotetico test A/B coinvolge un gran numero di animali e sembra che il nuovo farmaco sia promettente. Il nuovo farmaco è efficace al 1,5% in più rispetto al trattamento tradizionale. Dato il grande campione, questo sembra significativo. Torneremo su questo punto. Come esseri umani, tendiamo a considerare significative cose che potrebbero non esserlo. Ecco perché è così importante standardizzare i test di ipotesi.
“Pensa all’ipotesi nulla come se non fosse successo nulla, ovvero il caso può spiegare tutto.”
Nel test A/B, utilizziamo un’ipotesi di base che non è stato osservato nulla di speciale. Questa è anche nota come ipotesi nulla. La persona che esegue il test di solito spera di dimostrare che l’ipotesi nulla non è valida, ovvero che è stata fatta una scoperta. In altre parole, l’ipotesi alternativa è vera. Un modo per dimostrarlo è mostrare che il caso casuale ha una probabilità molto bassa di portare a una differenza tanto estrema quanto quella osservata. Stiamo già iniziando a vedere il collegamento con il test di permutazione.
Immagina una procedura in cui tutti gli animali trattati vengono raggruppati in un singolo gruppo (di 2487 + 1785 animali) e quindi divisi nuovamente in modo casuale in due gruppi con le stesse dimensioni dei due gruppi di trattamento originali. Per ogni animale sappiamo se il trattamento è stato efficace o meno e quindi possiamo calcolare la percentuale di animali curati per ogni gruppo. Utilizzando i dati osservati, abbiamo stabilito che il nuovo farmaco ha aumentato la percentuale di animali curati dall’80,34% all’81,79%, ovvero un aumento di quasi l’1,5%. Se campioniamo nuovamente i due gruppi molte volte, con quale frequenza vedremo che il nuovo farmaco porta a una percentuale maggiore di animali curati rispetto al trattamento tradizionale? Questo “con quale frequenza” è il famoso valore p nella deduzione statistica. Se accade spesso, ovvero il valore p è maggiore di una soglia con cui siamo a nostro agio (il livello di significatività altrettanto famoso, spesso del 5%), allora ciò che abbiamo osservato nell’esperimento può essere dovuto al caso e quindi l’ipotesi nulla non viene respinta. Se accade raramente, allora il caso da solo non può portare alla differenza osservata e quindi l’ipotesi nulla viene respinta (e puoi organizzare una festa se il tuo team ha scoperto il nuovo farmaco!). Se osservi attentamente ciò che abbiamo effettivamente fatto con le permutazioni, abbiamo simulato l’ipotesi nulla, ovvero che i due gruppi di trattamento sono equivalenti.
Rifletti nuovamente su come è stata formulata l’ipotesi nulla, poiché ciò determina come verrà condotto il test di permutazione. Nell’esempio sopra, vogliamo vedere con quale frequenza il caso ci farebbe credere che l’ipotesi alternativa sia vera, ovvero che il nuovo farmaco sia più efficace. Ciò significa che l’ipotesi nulla, che è complementare all’ipotesi alternativa, afferma che il nuovo farmaco è meno efficiente o altrettanto efficiente del trattamento tradizionale. Questo è anche noto come test unilaterale (rispetto a un test bilaterale, noto anche come test bidirezionale). Pensaci in un altro modo. Non vogliamo essere ingannati dal caso casuale facendoci credere che il nuovo farmaco sia più efficace. Essere ingannati nell’altra direzione non ha importanza, perché comunque non intendiamo sostituire il trattamento tradizionale. Il test bilaterale porterebbe a valori p più alti ed è quindi più conservativo perché ha una maggiore probabilità di respingere l’ipotesi nulla. Tuttavia, questo non significa che debba essere utilizzato se non è il test corretto da utilizzare.
Il test di permutazione può essere formulato nel caso più generale come segue. Supponiamo che ci siano Gᵢ, i=1,..,Nᴳ gruppi con cardinalità ∣ Gᵢ ∣, i=1,..,Nᴳ:
- Raggruppare tutti i punti dati di tutti i gruppi; ciò simula essenzialmente l’ipotesi nulla assumendo che non sia successo nulla.
- Assegnare casualmente ∣ G₁ ∣ punti al gruppo G₁ senza sostituzione, assegnare ∣ G₂ ∣ punti al gruppo G₂ senza sostituzione, .., fino a quando tutti i punti sono stati assegnati.
- Calcolare la statistica di interesse come calcolata nei campioni originali e registrare il risultato.
- Ripetere la procedura sopra un gran numero di volte e registrare ogni volta la statistica di interesse.
In sostanza, la procedura sopra costruisce una distribuzione con la statistica di interesse. La probabilità di osservare un valore che è almeno altrettanto estremo della differenza osservata è il p-value. Se il p-value è grande, allora il caso può facilmente produrre la differenza osservata e non abbiamo fatto alcuna scoperta (ancora).
Pensa al p-value come alla probabilità di osservare un risultato altrettanto estremo della nostra osservazione se l’ipotesi nulla fosse vera.
La formulazione sopra è piuttosto generica. Tornando al nostro esempio, abbiamo solo due gruppi, uno per il nuovo farmaco e uno per il trattamento tradizionale. Il codice per eseguire il test di permutazione è riportato di seguito.
Facciamo 10.000 permutazioni, che richiedono circa 30 secondi sul mio computer. La domanda chiave è: con quale frequenza il caso rende il nuovo farmaco efficace almeno dell’1,5% rispetto al trattamento tradizionale? Possiamo visualizzare l’istogramma delle differenze di efficacia simulate e calcolare anche il p-value come mostrato di seguito.
Questo dà il seguente istogramma:

Le barre rosse indicano quando il nuovo farmaco è stato trovato più efficace del trattamento tradizionale per caso. Questo non sembra così raro. Il p-value è 0,1084. Presumendo che avessimo intenzione di eseguire il test con un livello di significatività di a=0,05, ciò significa che l’ipotesi nulla non può essere respinta. Nulla da festeggiare in questo momento. Se hai organizzato una festa, deve essere cancellata. O forse rimandata.
Pensa a a come al tasso di falsi positivi, cioè assumendo che l’ipotesi nulla sia vera, concluderemmo che c’è una differenza statisticamente significativa nel 5% dei casi se eseguissimo l’esperimento ripetutamente.
C’è qualche motivo per essere ottimisti. Il test A/B che abbiamo appena eseguito può avere due possibili esiti: o c’è un effetto (nel nostro caso il nuovo farmaco è più efficace del trattamento tradizionale) o non ci sono prove sufficienti per concludere che ci sia un effetto. Il test non conclude che non ci sia alcun effetto. Il nuovo farmaco potrebbe essere più efficace dopo tutto. Possiamo solo dimostrarlo ancora al livello di significatività scelto con i dati finora. Il test ci ha essenzialmente protetto da un falso positivo (noto anche come errore di tipo 1); ma potrebbe essere che abbiamo un falso negativo (noto anche come errore di tipo 2). Questo è ciò che il team spera.
C’è un’altra domanda che potremmo fare. Di quale differenza osservata avremmo bisogno per concludere che il nuovo farmaco è più efficace del trattamento tradizionale? Chiaramente l’1,5% non è sufficiente, ma quanto sarebbe sufficiente? La risposta può essere facilmente ottenuta dall’istogramma prodotto. Possiamo “spostare” la linea verticale corrispondente alla differenza osservata verso destra, fino a quando la coda con le barre rosse rappresenta il 5% dell’area totale; o in altre parole utilizzare il 95° percentile np.percentile(differences, 95), che restituisce 0,0203 o 2,03%. Un po’ più del 1,5% che abbiamo osservato sfortunatamente, ma non troppo lontano.
Utilizzando un livello di significatività del 0,05, non respingeremmo l’ipotesi nulla se l’aumento dell’efficacia del trattamento con il nuovo farmaco è nell’intervallo (-∞, 0,0203]. Questo è noto anche come intervallo di confidenza: il insieme di valori della statistica osservata che non respingerebbe l’ipotesi nulla. Poiché abbiamo utilizzato un livello di significatività del 5%, si tratta di un intervallo di confidenza del 95%. Presumendo che il nuovo farmaco non sia più efficiente, quindi eseguire l’esperimento più volte fornirà una differenza di efficacia all’interno dell’intervallo di confidenza il 95% delle volte. Questo è ciò che l’intervallo di confidenza ci dice. Il p-value supererà a solo se l’intervallo di confidenza contiene l’aumento dell’efficacia osservato, il che significa che l’ipotesi nulla non può essere respinta. Questi due modi di verificare se l’ipotesi nulla può essere respinta sono ovviamente equivalenti.
Con il numero di animali finora testati non possiamo respingere l’ipotesi nulla, ma non siamo molto lontani dal limite dell’intervallo di confidenza. Il team è ottimista, ma abbiamo bisogno di raccogliere prove più convincenti che il nuovo farmaco sia più efficace. Ma di quanto più prove abbiamo bisogno? Torneremo su questo nel prossimo paragrafo, poiché l’esecuzione di una simulazione con il campionamento casuale può aiutarci a rispondere a questa domanda anche!
Prima di concludere questa sezione, è importante notare che potremmo anche utilizzare un test statistico classico per approssimare il valore p. La tabella presentata sopra è anche conosciuta come tabella di contingenza, che fornisce l’interrelazione tra due variabili e può essere utilizzata per stabilire se vi è un’interazione tra di esse. L’indipendenza delle due variabili può essere esaminata utilizzando un test del chi-quadro a partire dalla matrice di contingenza, ma è necessaria attenzione per non eseguire un test a due code (non ho provato a fondo, ma sembra che scipy utilizzi di default un test a due code; questo comporterà valori p più alti). Non è bello sapere come eseguire un test di permutazione prima di immergersi nella guida dell’utente delle librerie statistiche?
Stima della potenza
Sicuramente si sarebbe delusi dal fatto che non possiamo dimostrare che l’aumentata efficacia del nuovo farmaco sia statisticamente significativa. Potrebbe anche essere che il nuovo farmaco sia veramente migliore, dopo tutto. Siamo disposti a fare più lavoro trattando più animali, ma quanti animali avremmo bisogno? Ecco dove entra in gioco la potenza.
La potenza è la probabilità di rilevare una data dimensione dell’effetto per una data dimensione del campione e livello di significatività. Supponiamo che ci aspettiamo che il nuovo farmaco aumenti l’efficacia del trattamento del 1,5% rispetto al trattamento tradizionale. Supponendo che abbiamo trattato 3000 animali con ciascun trattamento e abbiamo fissato il livello di significatività al 0,05, la potenza del test è dell’80%. Ciò significa che se ripetiamo l’esperimento molte volte, vedremo che in 4 su 5 esperimenti concludiamo che il nuovo farmaco è più efficace del trattamento tradizionale. In altre parole, il tasso di falsi negativi (errore di tipo II) è del 20%. I numeri sopra sono ovviamente ipotetici. Quello che è importante è che le quattro quantità: dimensione del campione, dimensione dell’effetto, livello di significatività e potenza sono correlate e fissando tre di esse permette di calcolare la quarta. Lo scenario più tipico è calcolare la dimensione del campione dalle altre tre. Questo è ciò che indaghiamo in questa sezione. Come semplificazione, assumiamo che in ogni esperimento trattiamo lo stesso numero di animali con il nuovo farmaco e il trattamento tradizionale.
La procedura sottostante cerca di costruire una curva con la potenza come funzione della dimensione del campione:
- Crea un set di dati sintetico con animali supposti aver subito il trattamento tradizionale in modo che l’efficacia del trattamento sia più o meno quella che sappiamo essere (qui sotto, l’ho impostata a 0,8034 che corrisponde alla matrice di contingenza sopra).
- Crea un set di dati sintetico con animali supposti aver subito il trattamento con il nuovo farmaco aggiungendo la dimensione dell’effetto che vorremmo indagare (qui sotto, l’ho impostata a 0,015 e 0,020 per vedere il suo effetto sui risultati).
- Prendi un campione di bootstrap di dimensione n_campioni da ciascun set di dati sintetici (qui sotto ho impostato i valori 3000, 4000, 5000, 6000 e 7000).
- Esegui un test di permutazione per la significatività statistica utilizzando l’approccio stabilito nella sezione precedente e registra se la differenza nell’efficacia del trattamento è statisticamente significativa o meno.
- Continua a generare campioni di bootstrap e calcola con quale frequenza la differenza nell’efficacia del trattamento è statisticamente significativa; questa è la potenza del test.
Questa è ovviamente una simulazione più lunga e quindi limitiamo il numero di campioni di bootstrap a 200, mentre il numero di permutazioni nel test di significatività viene anche ridotto a 500 rispetto alla sezione precedente.
Eseguire questa simulazione di bootstrap/permutazione richiede circa un’ora su una macchina modesta e potrebbe beneficiare della multiprocessing che va oltre lo scopo di questo articolo. Possiamo visualizzare facilmente i risultati utilizzando matplotlib:
Ciò produce questo grafico:
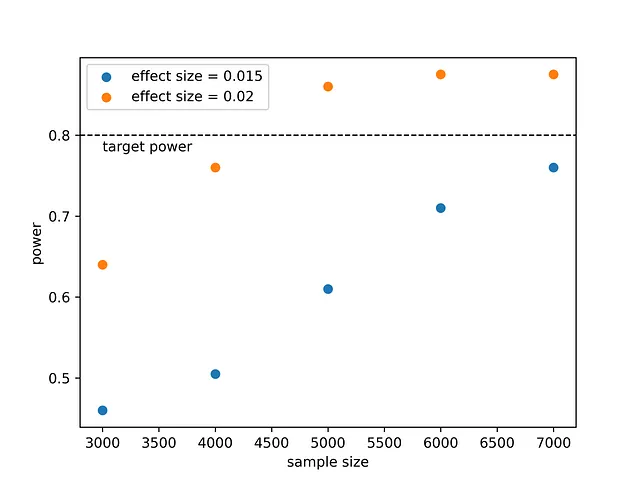
Cosa impariamo da questo? Se ci aspettiamo che il nuovo farmaco sia più efficace del 1,5%, allora per dimostrarlo con una potenza dell’80% avremmo bisogno di trattare più di 7000 animali. Se la dimensione dell’effetto è più grande, ad esempio 2%, avremmo bisogno di lavorare di meno poiché ~4500 animali sarebbero sufficienti. Questo è intuitivo. È più facile rilevare un effetto grande rispetto a un effetto piccolo. Decidere di eseguire un esperimento così grande richiede un’analisi costo/beneficio, ma almeno ora sappiamo cosa serve per dimostrare che il nuovo farmaco è più efficace.
Possiamo anche utilizzare statsmodels per calcolare la dimensione del campione richiesta:
Questo stampa:
dimensione dell'effetto: 0.015, dimensione del campione: 8426.09dimensione dell'effetto: 0.020, dimensione del campione: 4690.38I risultati della simulazione sembrano coerenti. Nella simulazione siamo arrivati a una dimensione del campione di 7000 che non era sufficiente per raggiungere una potenza del 0.8 quando la dimensione dell’effetto era del 1.5%, come si può vedere anche utilizzando la funzione proportion_effectsize.
Pensieri conclusivi
Spero che abbiate apprezzato questo articolo. Personalmente trovo gratificante poter indagare tutti questi concetti statistici da zero utilizzando semplici metodi di bootstrapping e permutazioni.
Prima di concludere, è necessario fare una nota di cautela. Questo articolo pone molta enfasi sul valore p che sta diventando sempre più criticato. La verità è che l’importanza del valore p è stata storicamente esagerata. Il valore p indica quanto i dati siano incompatibili con un modello statistico o un test di permutazione che rappresenta l’ipotesi nulla. Il valore p non è la probabilità che l’ipotesi alternativa sia vera. Inoltre, un valore p che mostra che il valore nullo può essere respinto non significa che la dimensione dell’effetto sia importante. Una dimensione dell’effetto piccola può essere statisticamente significativa, ma così piccola che non è importante.
Riferimenti
- Introductory Statistics and Analytics: A Resampling Perspective di Peter Bruce (Wiley, 2014)
- Practical Statistics for Data Scientists: 50+ Essential Concepts Using R and Python di Peter Bruce, Andrew Bruce, Peter Gedeck (O’Reilly, 2020)
- Interpreting A/B test results: false positives and statistical significance, un blog tecnologico di Netflix





