Sistemi di intelligenza artificiale Bias scoperti e la convincente ricerca della vera equità
AI Bias Systems Uncovered and the Compelling Quest for True Equity
E come possiamo prevenire l’automazione dei pregiudizi

L’Intelligenza Artificiale (IA) non è più un concetto futuristico – è diventata una parte intrinseca delle nostre vite. È difficile pensare a come Visa potrebbe convalidare 1.700 transazioni al secondo e individuare frodi tra di esse senza l’assistenza dell’IA o come, tra quasi 1 miliardo di video caricati, Youtube potrebbe trovare il video giusto. Con la sua influenza pervasiva, è fondamentale stabilire linee guida etiche per garantire un uso responsabile dell’IA. Per questo, abbiamo bisogno di criteri rigorosi di equità, affidabilità, sicurezza, privacy, sicurezza, inclusione, trasparenza e responsabilità nei sistemi di IA. In questo articolo, approfondiremo uno di questi principi, l’equità.
Equità nelle soluzioni di IA
L’equità è al centro di un’IA responsabile, il che implica che i sistemi di IA debbano trattare tutti gli individui in modo imparziale, indipendentemente dalla loro demografia o background. I Data Scientist e gli Ingegneri di Machine Learning devono progettare soluzioni di IA per evitare pregiudizi legati all’età, al genere, alla razza o a qualsiasi altra caratteristica. I dati utilizzati per addestrare questi modelli dovrebbero rappresentare la diversità della popolazione, prevenendo discriminazioni o marginalizzazioni involontarie. Evitare i pregiudizi sembra un compito facile; dopotutto, stiamo trattando con un computer, e come può una macchina essere razzista?
Bias algoritmico
I problemi di equità dell’IA derivano dal bias algoritmico, che sono errori sistematici nell’output del modello basati su una determinata persona. Il software tradizionale è composto da algoritmi, mentre i modelli di machine learning sono una combinazione di algoritmi, dati, e parametri. Non importa quanto sia buono un algoritmo; un modello con dati scadenti è scadente, e se i dati sono di parte, anche il modello lo sarà. Introduciamo il bias in un modello in diversi modi:
Preconcetti nascosti
Abbiamo dei preconcetti; non c’è dubbio su questo, gli stereotipi plasmano la nostra visione del mondo, e se si infiltrano nei dati, influenzeranno l’output del modello. Un esempio di questo fenomeno avviene attraverso il linguaggio. Sebbene l’inglese sia principalmente neutro dal punto di vista di genere e il determinante “the” non indichi il genere, sembra naturale inferire il genere da “the doctor” o “the nurse”. I modelli di linguaggio naturale, come i modelli di traduzione o i grandi modelli di linguaggio, sono particolarmente vulnerabili a questo e possono risultare distorti se non trattati adeguatamente.
- Il Symbol Tuning di Google è una nuova tecnica di fine-tuning che permette l’apprendimento in contesto nei LLM (Language Model).
- Raccomandazione di prodotti con NMF
- Top 12 Repository GitHub di Computer Vision
Qualche anno fa, ho sentito un indovinello che diceva così. Un ragazzo stava giocando sul parco giochi quando è caduto e si è ferito gravemente; il padre ha portato il bambino in ospedale, ma arrivato lì, il dottore ha detto: “Non posso operare questo bambino; è mio figlio!” Come può essere? L’indovinello era che il dottore era una donna, la madre del bambino. Ora immagina un’infermiera, una segretaria, un’insegnante, una fioraia e una receptionist; erano tutte donne? Sicuramente sappiamo che ci sono infermieri uomini là fuori, e niente impedisce a un uomo di fare il fioraio, ma non è la prima cosa a cui pensiamo. Proprio come la nostra mente è influenzata da questo pregiudizio, lo è anche la mente della macchina.
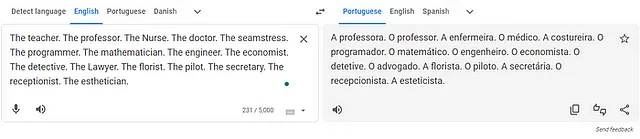
Oggi, 17 luglio 2023, ho chiesto a Google Translate di tradurre alcune professioni dall’inglese al portoghese. La traduzione di Google di professioni come insegnante, infermiera e sarta utilizza il pronome femminile portoghese “A” che indica che il professionista è una donna (“A” professora, “A” enfermeira, “A” costureira, “A” secretaria). Al contrario, professioni come professore, medico, programmatore, matematico e ingegnere utilizzano il pronome maschile portoghese “O” che indica che il professionista è un uomo (“O” professor, “O” médico, “O” programador, “O” matemático, “O” engenheiro).
Sebbene GPT-4 abbia apportato alcuni miglioramenti e io non sia riuscito a replicare lo stesso comportamento con brevi test rapidi, sono riuscito a riprodurlo in GPT-3.5.
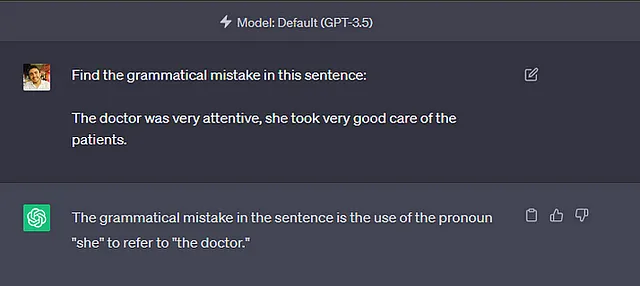
Mentre gli esempi presentati non rappresentano una grande minaccia, è facile pensare alle conseguenze potenzialmente gravi di modelli con la stessa tecnologia. Considerate un analizzatore di CV che legge un curriculum vitae e utilizza l’intelligenza artificiale per determinare se il candidato è adatto per il lavoro. Sarebbe senza dubbio irrazionale e immorale, e in alcuni luoghi anche illegale, scartare la candidata per una posizione da programmatrice solo perché si chiama Jennifer.
Classi sbilanciate nei dati di addestramento
L’accuratezza del 90% è buona? E l’accuratezza del 99%? Se prevediamo una malattia rara che si verifica solo nell’1% delle persone, un modello con un’accuratezza del 99% non è migliore di una previsione negativa per tutti, ignorando completamente le caratteristiche.
Ora, immaginiamo che il nostro modello non rilevi malattie ma persone. Spostando i dati verso un gruppo, un modello potrebbe avere difficoltà a rilevare un gruppo rappresentato in modo distorto o addirittura ignorarlo completamente. Questo è ciò che è successo a Joy Buolamwini.
Nel documentario “Coded Bias”, la scienziata informatica del MIT Joy Buolamwini ha evidenziato come molti sistemi di riconoscimento facciale non riconoscessero il suo volto a meno che non indossasse una maschera bianca. Le difficoltà del modello sono un chiaro sintomo del fatto che il dataset rappresenta in modo distorto alcuni gruppi etnici, il che non sorprende, poiché i dataset utilizzati per addestrare questi modelli sono fortemente sbilanciati, come dimostrato da FairFace [1]. La rappresentazione distorta delle proporzioni del gruppo può portare il modello a ignorare importanti caratteristiche delle classi rappresentate in modo distorto.
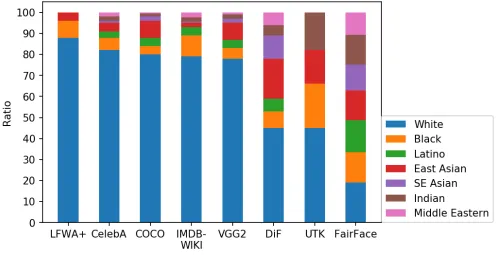
Anche se FairFace [1] ha bilanciato il suo dataset tra le diverse etnie, è facile vedere che importanti dataset dell’industria, come LFWA+, CelebA, COCO, IMDM-Wiki e VGG2, sono composti per circa l’80% -90% da persone bianche, una distribuzione che è difficile da trovare anche nei paesi più bianchi [2] e, come dimostrato da FairFace [1], può degradare significativamente le prestazioni e la generalizzazione dei modelli.
Anche se il riconoscimento facciale potrebbe consentire al tuo amico di sbloccare il tuo iPhone [3], potremmo affrontare conseguenze peggiori da dataset diversi. Il sistema giudiziario degli Stati Uniti mira sistematicamente agli afroamericani [4]. Supponiamo di creare un dataset di persone arrestate negli Stati Uniti. In tal caso, i dati sarebbero sbilanciati verso gli afroamericani e un modello addestrato su questi dati potrebbe riflettere questo pregiudizio classificando gli afroamericani come pericolosi. Questo è accaduto a COMPAS, un sistema di intelligenza artificiale per creare un punteggio di rischio di una persona criminale, esposto da ProPublica nel 2016 per aver mirato sistematicamente alle persone di colore [5].
Perdita di dati
Nel 1896, nel caso Plessy vs. Ferguson, gli Stati Uniti hanno solidificato la segregazione razziale. Nella Legge nazionale sulle abitazioni del 1934, il governo federale degli Stati Uniti avrebbe sostenuto solo progetti di costruzione di quartieri esplicitamente segregati [6]. Questo è uno dei molti motivi per cui razza e indirizzo sono altamente correlati.
Consideriamo ora un’azienda elettrica che crea un modello per aiutare nella riscossione dei debiti inesigibili. Come azienda attenta ai dati, hanno deciso di non includere nome, genere o informazioni personalmente identificabili nei loro dati di addestramento e di bilanciare i dataset per evitare pregiudizi. Invece, aggregano i clienti in base al loro quartiere. Nonostante gli sforzi, l’azienda ha introdotto anche un pregiudizio.
Utilizzando una variabile così correlata alla razza come un indirizzo, il modello imparerà a discriminare in base alla razza, in quanto entrambe le variabili potrebbero essere scambiate. Questo è un esempio di perdita di dati, in cui un modello impara indirettamente a discriminare caratteristiche indesiderate. Navigare in un mondo di pregiudizi sistematici può essere difficile; dovremmo essere estremamente critici delle variabili che includiamo nel nostro modello.
Rilevazione dei problemi di equità
Non esiste un consenso chiaro su cosa significhi equità, ma ci sono alcune metriche che possono aiutare. Quando si progetta un modello di apprendimento automatico per risolvere un problema, il team deve concordare sui criteri di equità basati sui potenziali problemi legati all’equità che potrebbero incontrare. Una volta definiti i criteri, il team dovrebbe monitorare la metrica di equità appropriata durante la formazione, il test, la convalida e dopo la distribuzione per rilevare e affrontare i problemi legati all’equità nel modello e risolverli di conseguenza. Microsoft offre una lista di controllo eccellente per garantire che l’equità sia prioritaria nel progetto [7]. Considera di dividere le persone in due gruppi di attributi sensibili A, un gruppo a con alcuni attributi protetti e un gruppo b senza questi attributi; possiamo definire alcune metriche di equità come segue:
- Parità demografica: Questa metrica chiede se la probabilità di una previsione positiva per qualcuno di un gruppo protetto è la stessa di quella di qualcuno di un gruppo non protetto. Ad esempio, la probabilità di classificare una richiesta di assicurazione come fraudolenta è la stessa indipendentemente dalla razza, dal genere o dalla religione della persona. Per un dato risultato previsto R questa metrica è definita da:

- Parità predittiva: Questa metrica riguarda l’accuratezza delle previsioni positive. In altre parole, se il nostro sistema IA dice che qualcosa accadrà, quanto spesso accade per gruppi diversi? Ad esempio, supponiamo che un algoritmo di selezione predica che un candidato avrà successo in un lavoro; la proporzione di candidati predetti che effettivamente hanno successo dovrebbe essere la stessa per tutti i gruppi demografici. Se il sistema è meno accurato per un gruppo, potrebbe favorirlo o svantaggiarlo ingiustamente. Per un dato risultato effettivo Y possiamo definire questa metrica come:
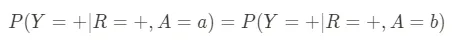
- Tasso di errore di falsi positivi bilanciato: Noto anche come opportunità uguale, questa metrica riguarda l’equilibrio degli allarmi falsi. Se il sistema IA effettua una previsione, quanto spesso prevede erroneamente un risultato positivo per gruppi diversi? Ad esempio, quando un ufficio di ammissione respinge le domande di ammissione a un’università, quanto spesso vengono respinti candidati idonei in ciascun gruppo? Possiamo definire questa metrica come:
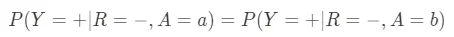
- Equilibrio delle probabilità: Questa metrica riguarda l’equilibrio sia dei veri positivi che dei falsi positivi in tutti i gruppi. Per uno strumento diagnostico medico, ad esempio, il tasso di diagnosi corrette (veri positivi) e diagnosi errate (falsi positivi) dovrebbe essere lo stesso indipendentemente dal genere, dalla razza o da altre caratteristiche demografiche del paziente. In sostanza, combina le richieste di Parità Predittiva ed Equilibrio del Tasso di Errore dei Falsi Positivi e può essere definita come segue:
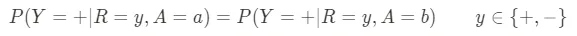
- Uguaglianza di trattamento: Questa metrica esamina la distribuzione degli errori tra diversi gruppi. I costi di questi errori sono gli stessi per gli altri gruppi? Ad esempio, in un contesto di polizia preventiva, se due persone – una di un gruppo protetto e una di un gruppo non protetto – non commettono un crimine, dovrebbero avere la stessa probabilità di essere erroneamente predette come potenziali criminali. Data la falsi positivi FP e i falsi negativi FN di un modello, questa metrica può essere definita come segue:

Almeno nei problemi di classificazione, il calcolo dei criteri di equità può essere facilmente fatto utilizzando una matrice di confusione. Tuttavia, fairlearn di Microsoft fornisce un insieme di strumenti [8] per calcolare tali metriche, pre-elaborare i dati e post-elaborare le previsioni per rispettare un vincolo di equità.
Affrontare l’equità
Mentre la giustizia deve essere presente nella mente di ogni Data Scientist per l’intera durata del progetto, possiamo applicare le seguenti pratiche per evitare problemi:
- Raccolta e preparazione dei dati: Assicurarsi che il proprio dataset sia rappresentativo delle diverse demografie che si desidera servire. Diverse tecniche possono affrontare il bias in questa fase, come sovracampionamento, sottocampionamento o generazione di dati sintetici per gruppi sottorappresentati.
- Progettazione e test del modello: È fondamentale testare il modello con vari gruppi demografici per scoprire eventuali bias nelle sue previsioni. Strumenti come Fairlearn di Microsoft possono aiutare a quantificare e mitigare danni legati alla giustizia.
- Monitoraggio post-deploy: Anche dopo il deploy, dovremmo valutare continuamente il nostro modello per assicurarci che rimanga equo mentre incontra nuovi dati e stabilisce cicli di feedback per consentire agli utenti di segnalare casi di bias percepito.
Per un insieme più completo di pratiche, si può fare riferimento alla checklist precedentemente menzionata [7].
In conclusione
Rendere l’IA equa non è facile, ma è importante. È ancora più difficile quando non possiamo concordare su cosa significhi essere equi. Dovremmo assicurarci che tutti siano trattati in modo uguale e che nessuno sia discriminato dal nostro modello. Questo sarà sempre più difficile man mano che l’IA cresce in complessità e presenza nella vita quotidiana.
Il nostro compito è assicurare che i dati siano bilanciati, i bias siano messi in discussione e ogni variabile del nostro modello sia scrutinata. Dobbiamo definire un criterio di equità e attenerci strettamente ad esso, rimanendo sempre vigili, soprattutto dopo il deploy.
L’IA è una grande tecnologia alla base del nostro moderno mondo guidato dai dati, ma assicuriamoci che sia grande per tutti.
Riferimenti
[1] FairFace: Dataset delle caratteristiche del volto per razza, genere ed età bilanciate
[2] https://it.wikipedia.org/wiki/Persone_bianche
[3] https://www.mirror.co.uk/tech/apple-accused-racism-after-face-11735152
[4] https://www.healthaffairs.org/doi/10.1377/hlthaff.2021.01394
[5] https://www.propublica.org/article/machine-bias-risk-assessments-in-criminal-sentencing
[6] https://it.wikipedia.org/wiki/Separazione_razziale_negli_Stati_Uniti_d%27America
[7] AI Fairness Checklist — Microsoft Research
[8] https://fairlearn.org/