Il Symbol Tuning di Google è una nuova tecnica di fine-tuning che permette l’apprendimento in contesto nei LLM (Language Model).
Il Symbol Tuning di Google è una tecnica di fine-tuning per LLM (Language Model) che consente l'apprendimento in contesto.
Il nuovo metodo può diventare la base di nuove tecniche di fine-tuning.

Recentemente ho avviato una newsletter educativa focalizzata sull’intelligenza artificiale, che conta già più di 160.000 abbonati. TheSequence è una newsletter orientata all’apprendimento automatico (machine learning) che richiede solo 5 minuti di lettura e non contiene fronzoli (cioè niente hype, niente notizie, ecc). Lo scopo è quello di tenerti aggiornato sui progetti di apprendimento automatico, articoli di ricerca e concetti. Prova a iscriverti qui di seguito:
TheSequence | Jesus Rodriguez | Substack
La migliore fonte per rimanere aggiornato sugli sviluppi nell’apprendimento automatico, intelligenza artificiale e dati…
thesequence.substack.com
Grazie alla scalabilità dei modelli di linguaggio, l’apprendimento automatico ha vissuto un’enorme crescita rivoluzionaria, consentendo il completamento di complesse attività di ragionamento attraverso l’apprendimento in contesto. Tuttavia, rimane ancora un problema latente: i modelli di linguaggio mostrano sensibilità alle variazioni delle istruzioni, suggerendo una mancanza di ragionamento robusto. Questi modelli spesso richiedono un’attenta progettazione delle istruzioni o del linguaggio didattico, e talvolta mostrano comportamenti peculiari come la performance invariata nonostante l’esposizione a etichette errate. Nella loro ultima ricerca, Google svela una caratteristica fondamentale dell’intelligenza umana: la capacità di apprendere nuove attività attraverso il ragionamento con pochi esempi.
Il documento innovativo di Google, intitolato “Symbol tuning improves in-context learning in language models”, introduce un nuovo metodo di fine-tuning chiamato symbol tuning. Questa tecnica accentua le corrispondenze tra input ed etichette, portando a significativi miglioramenti nell’apprendimento in contesto per i modelli Flan-PaLM in diverse situazioni.
- Raccomandazione di prodotti con NMF
- Top 12 Repository GitHub di Computer Vision
- 7 Passaggi per Padroneggiare le Tecniche di Pulizia e Preelaborazione dei Dati

Symbol Tuning
Google Research introduce “Symbol Tuning”, una potente tecnica di fine-tuning che affronta le limitazioni dei metodi di fine-tuning tradizionali basati sulle istruzioni. Mentre il fine-tuning basato sulle istruzioni può migliorare le prestazioni del modello e la comprensione in contesto, presenta uno svantaggio: i modelli potrebbero non essere stimolati ad imparare dagli esempi poiché le attività sono definite in modo ridondante attraverso istruzioni ed etichette in linguaggio naturale. Ad esempio, nei compiti di analisi del sentiment, i modelli possono semplicemente fare affidamento sulle istruzioni fornite, ignorando completamente gli esempi.
Symbol tuning si dimostra particolarmente utile per attività di apprendimento in contesto precedentemente non viste, eccellendo dove i metodi tradizionali falliscono a causa di prompt insufficientemente specificati privi di istruzioni o etichette in linguaggio naturale. Inoltre, i modelli sintonizzati con i simboli dimostrano una straordinaria capacità di ragionamento algoritmico.
L’aspetto più notevole è il notevole miglioramento nella gestione delle etichette invertite presentate in contesto. Questo risultato evidenzia la capacità superiore del modello di sfruttare le informazioni in contesto, superando persino le conoscenze preesistenti.
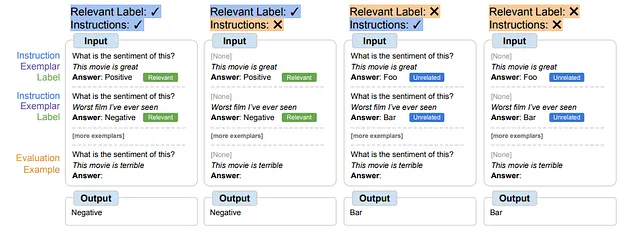
Symbol tuning offre una soluzione attraverso il fine-tuning dei modelli su esempi privi di istruzioni e sostituendo le etichette in linguaggio naturale con etichette semanticamente non correlate come “Foo”, “Bar”, ecc. In questa configurazione, il compito diventa ambiguo senza consultare gli esempi in contesto. Il ragionamento su questi esempi diventa cruciale per il successo. Di conseguenza, i modelli sintonizzati con i simboli mostrano un miglioramento delle prestazioni nei compiti che richiedono un ragionamento sottile tra gli esempi in contesto e le loro etichette.
Per valutare l’efficacia del symbol tuning, i ricercatori hanno utilizzato 22 set di dati di elaborazione del linguaggio naturale (NLP) disponibili pubblicamente con compiti di classificazione, considerando etichette discrete. Le etichette sono state riassegnate a scelte casuali tra un gruppo di circa 30.000 etichette arbitrarie appartenenti a tre categorie: numeri interi, combinazioni di caratteri e parole.

Gli esperimenti hanno coinvolto il symbol tuning sui modelli Flan-PaLM, nello specifico Flan-PaLM-8B, Flan-PaLM-62B e Flan-PaLM-540B. Inoltre, è stato testato Flan-cont-PaLM-62B (abbreviato in 62B-c), che rappresenta Flan-PaLM-62B su una scala di 1,3 trilioni di token anziché i soliti 780 miliardi di token.
La procedura di sintonizzazione dei simboli richiede che i modelli si impegnino nel ragionamento con esempi in contesto per svolgere efficacemente i compiti, poiché i prompt sono progettati per evitare l’apprendimento esclusivamente dalle etichette o istruzioni rilevanti. I modelli sintonizzati sui simboli eccellono in contesti che richiedono un ragionamento complesso tra esempi in contesto e etichette. Per esplorare questi contesti, sono state definite quattro scenari di apprendimento in contesto, variando il livello di ragionamento richiesto tra input ed etichette per l’apprendimento del compito (a seconda della disponibilità di istruzioni/etichette rilevanti).
I risultati hanno dimostrato miglioramenti delle prestazioni in tutti i contesti per i modelli da 62B in poi, con miglioramenti modesti nei contesti con etichette di linguaggio naturale rilevanti (che vanno dal +0,8% al +4,2%) e miglioramenti sostanziali nei contesti senza tali etichette (che vanno dal +5,5% al +15,5%). In modo sorprendente, quando le etichette rilevanti non erano disponibili, il modello Flan-PaLM-8B sintonizzato sui simboli ha superato le prestazioni del modello Flan-PaLM-62B e il modello Flan-PaLM-62B sintonizzato sui simboli ha superato il modello Flan-PaLM-540B. Ciò suggerisce che la sintonizzazione dei simboli permette ai modelli più piccoli di raggiungere le prestazioni dei modelli più grandi in questi compiti, riducendo significativamente i requisiti di elaborazione inferenziale (risparmiando approssimativamente ∼10 volte in elaborazione).

In generale, la sintonizzazione dei simboli mostra miglioramenti significativi nei compiti di apprendimento in contesto, in particolare per i prompt poco specificati. La tecnica mostra anche prestazioni migliori rispetto alla tradizionale sintonizzazione fine nei compiti di ragionamento ed è in grado di utilizzare meglio le informazioni in contesto per sovrascrivere le conoscenze precedenti. Nel complesso, la sintonizzazione dei simboli può diventare una delle tecniche di sintonizzazione fine più interessanti.






