Incontra ToolLLM un framework generale per la costruzione di dati e l’addestramento di modelli che migliora l’utilizzo dell’API dei grandi modelli di linguaggio.
ToolLLM è un framework che migliora l'utilizzo dell'API dei grandi modelli di linguaggio per la costruzione e l'addestramento di dati e modelli.


Per connettersi in modo efficiente con numerosi strumenti (API) e completare compiti difficili, l’apprendimento degli strumenti cerca di sfruttare il potenziale dei grandi modelli di linguaggio (LLM). I LLM possono aumentare significativamente il loro valore e acquisire la capacità di agire come intermediari efficaci tra i consumatori e l’ampio ecosistema delle applicazioni, collegandosi alle API. Sebbene l’addestramento delle istruzioni abbia permesso ai LLM open source, come LLaMA e Vicuna, di sviluppare una vasta gamma di capacità, devono ancora gestire compiti di livello superiore come comprendere le istruzioni dell’utente e interfacciarsi efficacemente con gli strumenti (API). Ciò perché l’addestramento delle istruzioni attuale si concentra principalmente su compiti linguistici semplici (come una conversazione informale) piuttosto che sul dominio dell’uso degli strumenti.
D’altra parte, i moderni modelli di linguaggio di ultima generazione (SOTA), come GPT-4, che hanno dimostrato eccellenti abilità nell’uso degli strumenti, sono proprietari e opachi nelle loro modalità di funzionamento interne. A causa di questo, la portata dell’innovazione e dello sviluppo guidati dalla comunità e la democratizzazione della tecnologia dell’IA sono limitate. Ritengono fondamentale che i LLM open source siano in grado di comprendere in modo adeguato una varietà di API in questo contesto. Sebbene studi precedenti abbiano indagato sulla creazione di dati di addestramento delle istruzioni per l’uso degli strumenti, i loro vincoli intrinseci impediscono loro di stimolare completamente le capacità di utilizzo degli strumenti all’interno dei LLM. (1) API limitate: ignorano sia le API del mondo reale (come RESTAPI) che una gamma ristretta di API con una diversità insufficiente; (2) scenario limitato: i lavori esistenti si limitano a istruzioni che utilizzano un singolo strumento. Al contrario, le impostazioni del mondo reale potrebbero richiedere la combinazione di molti strumenti per l’esecuzione di strumenti multi-round per completare un compito impegnativo.
Inoltre, spesso si presuppongono che gli utenti predeterminino l’insieme di API ottimale per un determinato comando, il che è impossibile quando viene offerto un gran numero di API; (3) pianificazione e ragionamento scadenti: gli studi esistenti utilizzano un meccanismo di sollecitazione semplice per il ragionamento del modello (come chain-of-thought (CoT) o ReACT), che non è in grado di elicitarle completamente le capacità codificate nei LLM e quindi non è in grado di gestire istruzioni complesse. Questo problema è particolarmente grave per i LLM open source poiché hanno capacità di ragionamento molto peggiori rispetto ai LLM SOTA. Inoltre, alcuni lavori non utilizzano nemmeno le API per ottenere risposte autentiche, che sono dati cruciali per lo sviluppo successivo del modello. Presentano ToolLLM, un framework generale per l’uso degli strumenti di produzione di dati, addestramento del modello e valutazione, per stimolare le capacità di utilizzo degli strumenti all’interno dei LLM open source.
- Apprendimenti dalla costruzione della piattaforma di ML presso Stitch Fix
- Sistemi di intelligenza artificiale Bias scoperti e la convincente ricerca della vera equità
- Il Symbol Tuning di Google è una nuova tecnica di fine-tuning che permette l’apprendimento in contesto nei LLM (Language Model).
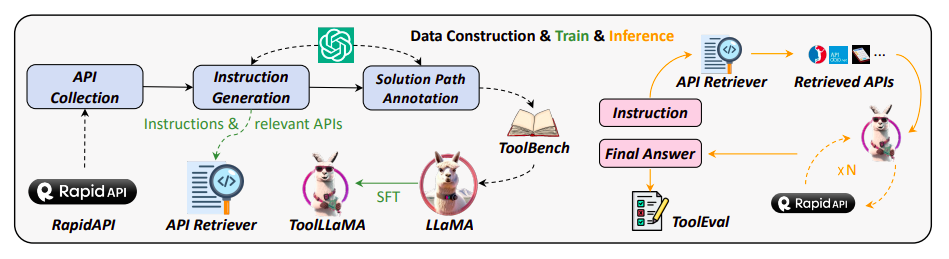
Il recuperatore di API suggerisce API pertinenti a ToolLLaMA durante l’inferenza delle istruzioni e ToolLLaMA effettua una serie di chiamate API per arrivare al risultato finale. ToolEval valuta l’intero processo di deliberazione.
Prima raccolgono un dataset di addestramento delle istruzioni di alta qualità chiamato ToolBench, come mostrato in Figura 1. Il più recente ChatGPT (gpt-3.5-turbo-16k), che è stato aggiornato con migliori capacità di chiamata di funzione1, viene utilizzato per generarlo automaticamente. La Tabella 1 fornisce il confronto tra ToolBench e gli sforzi precedenti. In particolare, ci sono tre fasi per la creazione di ToolBench:
• Raccolta API: raccolgono 16.464 API REST (representational state transfer) da RapidAPI2. Questa piattaforma ospita un numero considerevole di API del mondo reale messe a disposizione dagli sviluppatori. Queste API coprono 49 aree distinte, tra cui commercio elettronico, social networking e meteo. Estraggono una documentazione API completa da RapidAPI per ciascuna API, compresi riepiloghi delle funzionalità, input necessari, esempi di codice per le chiamate API, ecc. Per far sì che il modello generalizzi alle API non incontrate durante l’addestramento, si aspettano che i LLM imparino a utilizzare le API comprendendo questi documenti.
• Generazione di istruzioni: Iniziano selezionando alcune API dall’intera collezione e poi chiedono a ChatGPT di sviluppare varie istruzioni per queste API. Vengono selezionate istruzioni che coprono scenari singolo-strumento e multi-strumento per coprire situazioni reali. Ciò assicura che il loro modello impari come gestire vari strumenti individualmente e come combinarli per completare compiti impegnativi.
• Annotazione del percorso di soluzione: Evidenziano le risposte eccellenti a queste direttive. Ogni risposta può comportare diverse iterazioni di ragionamento del modello e richieste di API in tempo reale per raggiungere la conclusione finale. Anche il modello LLM più avanzato, ovvero GPT-4, ha un basso tasso di successo per comandi complicati a causa delle difficoltà intrinseche dell’apprendimento degli strumenti, rendendo inefficace la raccolta di dati. Per fare ciò, creano un albero di decisione unico basato su una ricerca in profondità (DFSDT) per migliorare la capacità dei LLM di pianificazione e ragionamento. Rispetto alla catena di pensiero tradizionale (CoT) e a ReACT, DFSDT consente ai LLM di valutare una varietà di ragionamenti e decidere se tornare indietro o continuare lungo un percorso valido. Negli studi, DFSDT completa efficacemente quelle istruzioni difficili che non possono essere risposte utilizzando CoT o ReACT e aumenta notevolmente l’efficienza dell’annotazione.
Ricercatori dell’Università Tsinghua, ModelBest Inc., Università Renmin della Cina, Università di Yale, WeChat AI, Tencent Inc. e Zhihu Inc. hanno creato ToolEval, un valutatore automatico supportato da ChatGPT, per valutare le capacità degli LLM nell’uso degli strumenti. Include due metriche cruciali: (1) tasso di vittoria, che confronta il valore e l’utilità di due possibili approcci alla soluzione, e (2) tasso di successo, che misura la capacità di eseguire un’istruzione con risorse limitate in modo efficace. Dimostrano che ToolEval è fortemente correlato alla valutazione umana e offre una valutazione accurata, scalabile e coerente dell’apprendimento degli strumenti. Ottengono ToolLLaMA ottimizzando LLaMA su ToolBench.
Dopo l’analisi utilizzando il loro ToolEval, arrivano alle seguenti conclusioni:
• La capacità di ToolLLaMA di gestire sia istruzioni semplici per strumenti singoli che istruzioni complesse per strumenti multipli è interessante. È sufficiente la documentazione delle API per permettere a ToolLLaMA di generalizzare con successo a nuove API, il che lo rende unico nel campo. Questa adattabilità consente agli utenti di incorporare nuove API in modo fluido, aumentando l’utilità del modello nelle applicazioni reali. Nonostante sia stato ottimizzato su poco più di 12.000 istanze, ToolLLaMA raggiunge prestazioni comparabili al “modello di riferimento” ChatGPT nell’uso degli strumenti.
• Dimostrano come il loro DFSDT funzioni come un metodo decisionale ampio per migliorare la capacità di ragionamento dei LLM.
DFSDT supera ReACT estendendo lo spazio di ricerca considerando vari percorsi di ragionamento. Inoltre, chiedono a ChatGPT di suggerire API pertinenti per ogni istruzione e quindi addestrano un recupero di API neurale utilizzando questi dati. Nella pratica, questa soluzione elimina la necessità di selezione manuale da un vasto pool di API. Possono integrare efficacemente ToolLLaMA e il recupero di API. Come si può vedere nella Figura 1, il recupero di API suggerisce una serie di API pertinenti in risposta a un’istruzione, che viene quindi inoltrata a ToolLLaMA per prendere decisioni a più livelli per determinare la risposta finale. Dimostrano che il recupero di API mostra un’incredibile precisione di recupero, restituendo API strettamente corrispondenti ai dati effettivi mentre seleziona tra un vasto pool di API. In conclusione, questo studio mira a consentire agli LLM open-source di eseguire comandi complessi utilizzando una varietà di API in situazioni reali. Si prevede che questo lavoro approfondirà ulteriormente la relazione tra l’uso degli strumenti e l’adattamento delle istruzioni. Forniscono anche una demo insieme al codice sorgente sulla loro pagina GitHub.