Tendenze lavorative nell’analisi dei dati NLP per l’analisi delle tendenze lavorative
Tendenze lavorative nell'analisi dei dati NLP per il monitoraggio delle tendenze del mercato del lavoro
Di Mahantesh Pattadkal & Andrea De Mauro
L’analisi dei dati ha conosciuto una crescita notevole negli ultimi anni, guidata dai progressi nell’utilizzo dei dati nei processi decisionali chiave. Anche la raccolta, conservazione e analisi dei dati sono progredite notevolmente grazie a questi sviluppi. Inoltre, la domanda di talenti nell’analisi dei dati è aumentata vertiginosamente, trasformando il mercato del lavoro in un’arena altamente competitiva per le persone che possiedono le competenze e l’esperienza necessarie.
La rapida espansione delle tecnologie basate sui dati ha portato conseguentemente ad una maggiore domanda di ruoli specializzati, come “data engineer”. Questo aumento della domanda si estende oltre l’ingegneria dei dati e comprende anche posizioni correlate come data scientist e data analyst.
Riconoscendo l’importanza di queste professioni, la nostra serie di articoli ha lo scopo di raccogliere dati reali provenienti da annunci di lavoro online e analizzarli per comprendere la natura della domanda per questi lavori, così come le diverse competenze richieste in ciascuna di queste categorie.
- Suggerimenti per navigare con successo i colloqui di lavoro per principianti nel campo della scienza dei dati
- Automatizza l’attività di progettazione grafica con il plugin ChatGPT Canva
- Sfruttare i modelli GPT per trasformare il linguaggio naturale in query SQL
In questo articolo, presentiamo un’applicazione basata su browser chiamata “Tendenze di lavoro nell’analisi dei dati” per la visualizzazione e l’analisi delle tendenze di lavoro nel mercato dell’analisi dei dati. Dopo aver estratto i dati da agenzie di lavoro online, utilizza tecniche di NLP per identificare le competenze chiave richieste nelle offerte di lavoro. La Figura 1 mostra un’istantanea dell’applicazione dati, esplorando le tendenze nel mercato del lavoro nell’analisi dei dati.

Per l’implementazione, abbiamo adottato la piattaforma di data science no-code: KNIME Analytics Platform. Questa piattaforma open-source e gratuita per la data science end-to-end si basa sulla programmazione visuale e offre un’ampia gamma di funzionalità, dalle operazioni puramente ETL e una vasta gamma di connettori per l’integrazione dei dati fino ad algoritmi di machine learning, inclusi il deep learning.
Il set di workflows alla base dell’applicazione è disponibile per il download gratuito dal KNIME Community Hub a “Tendenze di lavoro nell’analisi dei dati”. Un’istanza basata su browser può essere valutata su “Tendenze di lavoro nell’analisi dei dati”.
Applicazione “Tendenze di lavoro nell’analisi dei dati”
Questa applicazione è generata da quattro workflows mostrati nella Figura 2 da eseguire in sequenza per la seguente sequenza di passaggi:
- Web scraping per la raccolta dei dati
- Parsing e pulizia dei dati NLP
- Modello dei topic
- Analisi dell’attribuzione del ruolo di lavoro – competenze
I workflows sono disponibili nello spazio pubblico del KNIME Community Hub a “Tendenze di lavoro nell’analisi dei dati”.

- Il workflow “01_Web Scraping per la raccolta dei dati” esplora le offerte di lavoro online ed estrae le informazioni testuali in un formato strutturato
- Il workflow “02_Parsing e pulizia NLP” esegue le necessarie operazioni di pulizia e divide i lunghi testi in frasi più brevi
- Il workflow “03_Modello dei topic e esplorazione dell’applicazione dati” utilizza i dati puliti per creare un modello di topic e visualizzarne i risultati all’interno di un’applicazione dati
- Il workflow “04_Attribuzione delle competenze lavorative” valuta l’associazione delle competenze tra ruoli di lavoro, come Data Scientist, Data Engineer e Data Analyst, basandosi sui risultati LDA.
Web scraping per la raccolta dei dati
Al fine di avere una comprensione aggiornata delle competenze richieste nel mercato del lavoro, abbiamo optato per l’analisi di annunci di lavoro web scraping provenienti da agenzie di lavoro online. Date le variazioni regionali e la diversità delle lingue, ci siamo concentrati su annunci di lavoro negli Stati Uniti. Ciò garantisce che una parte significativa degli annunci di lavoro sia presentata in lingua inglese. Ci siamo inoltre concentrati su annunci di lavoro da febbraio 2023 ad aprile 2023.
Il flusso di lavoro KNIME “01_Web Scraping per la raccolta dei dati” nella Figura 3 attraversa una lista di URL di ricerche sui siti delle agenzie di lavoro.
Per estrarre gli annunci di lavoro pertinenti relativi all’Analisi dei dati, abbiamo utilizzato ricerche con sei parole chiave che coprono collettivamente il campo dell’analisi dei dati, ovvero: “big data”, “data science”, “business intelligence”, “data mining”, “machine learning” e “data analytics”. Le parole chiave di ricerca sono memorizzate in un file Excel e lette tramite il nodo Lettore Excel.
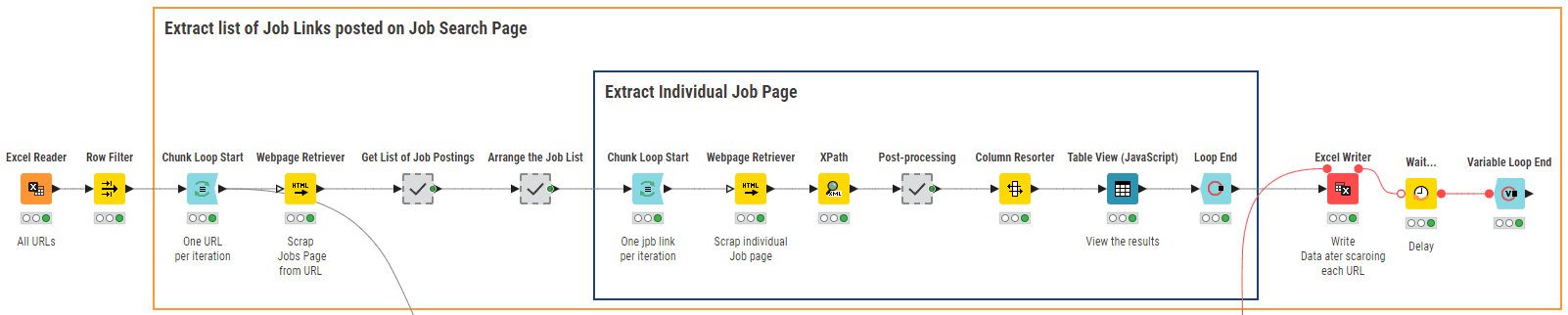
Il nodo principale di questo flusso di lavoro è il nodo Webpage Retriever. Viene utilizzato due volte. La prima volta (ciclo esterno), il nodo esplora il sito in base alla parola chiave fornita in input e produce l’elenco correlato di URL per gli annunci di lavoro pubblicati negli Stati Uniti nelle ultime 24 ore. La seconda volta (ciclo interno), il nodo recupera il contenuto testuale da ciascun URL dell’annuncio di lavoro. I nodi Xpath che seguono i nodi Webpage Retriever analizzano i testi estratti per raggiungere le informazioni desiderate, come il titolo del lavoro, le qualifiche richieste, la descrizione del lavoro, lo stipendio e le valutazioni dell’azienda. Infine, i risultati vengono scritti su un file locale per ulteriori analisi. La Figura 4 mostra un esempio degli annunci di lavoro estratti per febbraio 2023.

Analisi del linguaggio naturale (NLP) e pulizia dei dati
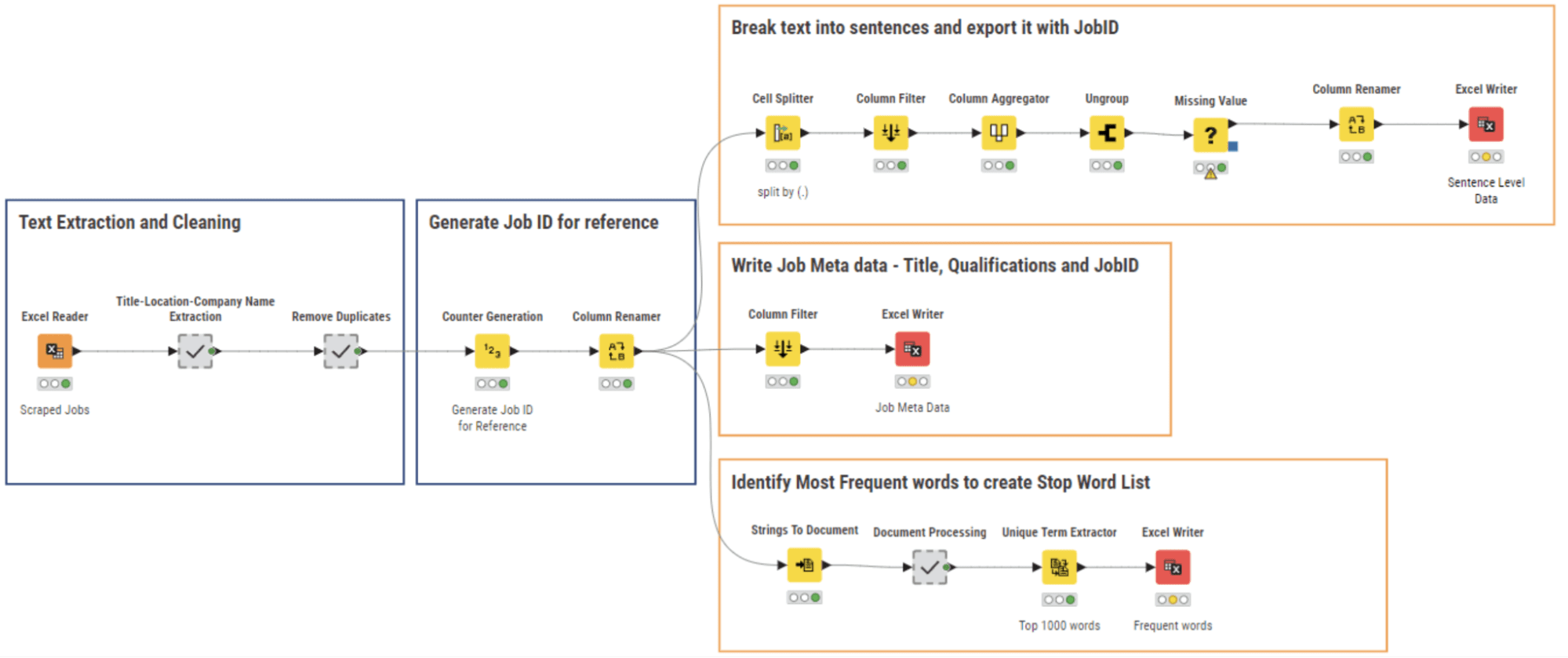
Come tutti i dati appena raccolti, i risultati del web scraping avevano bisogno di una pulizia. Eseguiamo l’analisi del linguaggio naturale insieme alla pulizia dei dati e scriviamo i rispettivi file di dati utilizzando il flusso di lavoro 02_NLP Parsing e cleaning mostrato nella Figura 5.
Diversi campi dai dati estratti sono stati salvati sotto forma di concatenazione di valori di stringa. Qui, abbiamo estratto le sezioni individuali utilizzando una serie di nodi di String Manipulation all’interno del meta nodo “Estrazione del Titolo-Località-Nome dell’Azienda” e quindi abbiamo rimosso le colonne non necessarie e ci siamo sbarazzati delle righe duplicate.
Abbiamo quindi assegnato un ID univoco a ciascun testo dell’annuncio di lavoro e frammentato l’intero documento in frasi tramite il nodo Cell Splitter. Le informazioni meta per ogni lavoro – titolo, località e azienda – sono state anche estratte e salvate insieme all’ID del lavoro.
È stato estratto l’elenco delle 1000 parole più frequenti da tutti i documenti, per generare una lista di stopwords, includendo parole come “richiedente”, “collaborazione”, “occupazione”, ecc… Queste parole sono presenti in ogni annuncio di lavoro e quindi non aggiungono informazioni per le successive attività di NLP.
Il risultato di questa fase di pulizia è un insieme di tre file:
– Una tabella contenente le frasi dei documenti;
– Una tabella contenente i metadati della descrizione del lavoro;
– Una tabella contenente l’elenco delle stopwords.
Modellazione dei topic ed esplorazione dei risultati
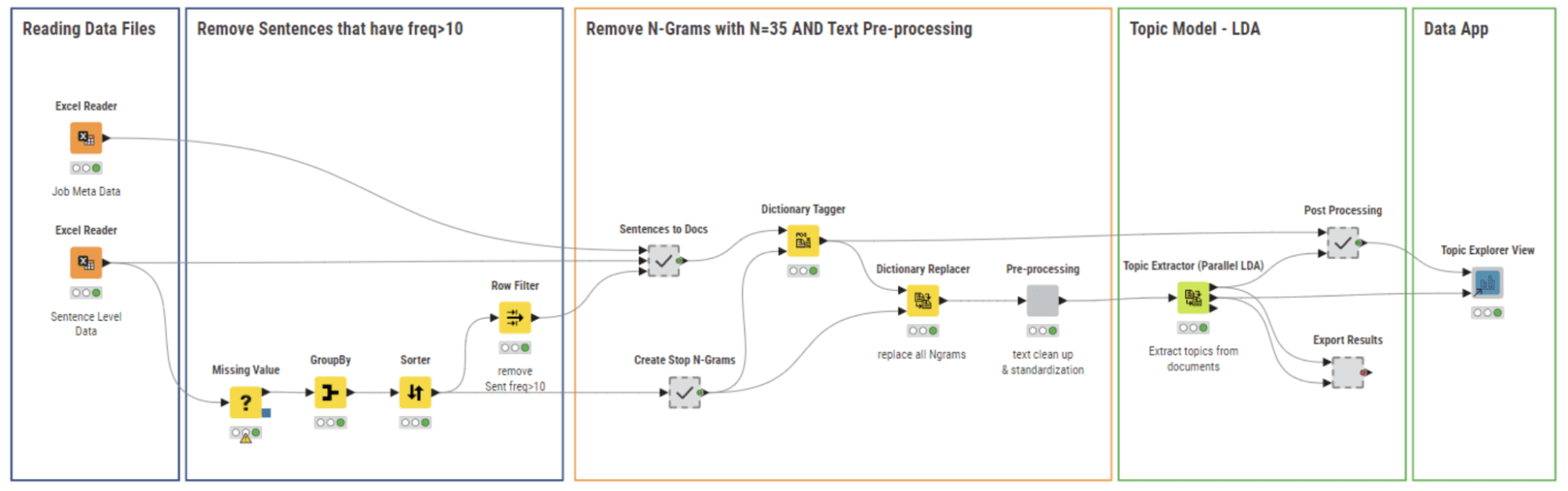
Il flusso di lavoro 03_Topic Modeling and Exploration Data App (Figura 6) utilizza i file di dati puliti dal flusso di lavoro precedente. In questa fase, miriamo a:
- Rilevare e rimuovere le frasi comuni (Stop Phrases) che compaiono in molti annunci di lavoro
- Eseguire le normali operazioni di elaborazione del testo per preparare i dati per la modellazione dei topic
- Costruire il modello dei topic e visualizzare i risultati.
Discutiamo in dettaglio i compiti sopra citati nelle seguenti sottosezioni.
3.1 Rimuovi frasi di stop con N-grammi
Molte offerte di lavoro includono frasi che si trovano comunemente nelle politiche aziendali o negli accordi generali, come ad esempio “Non-Discrimination policy” o “Non-Disclosure Agreements”. La Figura 7 fornisce un esempio in cui le offerte di lavoro 1 e 2 menzionano la politica di “Non-Discrimination”. Queste frasi non sono rilevanti per la nostra analisi e quindi devono essere rimosse dal nostro corpus di testo. Le chiamiamo “Frase di Stop” e utilizziamo due metodi per identificarle e filtrarle.
Il primo metodo è semplice: calcoliamo la frequenza di ogni frase nel nostro corpus e eliminiamo le frasi con una frequenza maggiore di 10.
Il secondo metodo prevede un approccio con gli N-grammi, dove N può variare tra 20 e 40. Selezioniamo un valore per N e valutiamo la rilevanza degli N-grammi derivati dal corpus contando il numero di N-grammi che rientrano nella categoria di frase di stop. Ripetiamo questo processo per ogni valore di N all’interno del range. Abbiamo scelto N=35 come il miglior valore per identificare il numero più elevato di Frasi di Stop.

Abbiamo utilizzato entrambi i metodi per rimuovere le “Frase di Stop” come mostrato dal flusso di lavoro rappresentato nella Figura 7. Inizialmente abbiamo rimosso le frasi più frequenti, quindi abbiamo creato N-grammi con N=35 e li abbiamo etichettati in ogni documento con il nodo Dictionary Tagger, e infine abbiamo rimosso questi N-grammi utilizzando il nodo Dictionary Replacer.
3.2 Prepara i dati per la modellazione del topic con tecniche di pre-elaborazione del testo
Dopo aver rimosso le Frasi di Stop, eseguiamo la pre-elaborazione del testo standard per preparare i dati per la modellazione del topic.
Innanzitutto, eliminiamo i valori numerici e alfanumerici dal corpus. Quindi, rimuoviamo i segni di punteggiatura e le comuni stop words inglesi. Inoltre, utilizziamo la lista personalizzata delle stop words specifiche del dominio di lavoro che abbiamo creato in precedenza per filtrare le stop words specifiche del dominio lavorativo. Infine, convertiamo tutti i caratteri in minuscolo.
Abbiamo deciso di concentrarci sulle parole che hanno significato, motivo per cui abbiamo filtrato i documenti per includere solo sostantivi e verbi. Ciò può essere fatto assegnando un tag di Parti del Discorso (POS) a ogni parola nel documento. Utilizziamo il nodo POS Tagger per assegnare questi tag e filtrarli in base al loro valore, mantenendo specificamente le parole con POS = Sostantivo e POS = Verbo.
Infine, applichiamo la lemmatizzazione di Stanford per assicurare che il corpus sia pronto per la modellazione del topic. Tutti questi passaggi di pre-elaborazione vengono eseguiti dal componente “Pre-elaborazione” mostrato nella Figura 6.
3.3 Costruisci il modello del topic e visualizzalo
Nella fase finale della nostra implementazione, abbiamo applicato l’algoritmo Latent Dirichlet Allocation (LDA) per costruire un modello del topic utilizzando il nodo Topic Extractor (Parallel LDA) mostrato nella Figura 6. L’algoritmo LDA produce un certo numero di topic (k), ognuno dei quali è descritto da un certo numero di parole chiave (m). I parametri (k, m) devono essere definiti.
Come nota aggiuntiva, k e m non possono essere troppo grandi, poiché vogliamo visualizzare e interpretare i topic (set di competenze) esaminando le parole chiave (competenze) e i loro pesi rispettivi. Abbiamo esplorato un intervallo [1, 10] per k e fissato il valore di m=15. Dopo un’attenta analisi, abbiamo scoperto che k=7 porta ai topic più diversi e distinti con una sovrapposizione minima nelle parole chiave. Pertanto, abbiamo determinato che k=7 è il valore ottimale per la nostra analisi.
Esplora i risultati della modellazione del topic con un’applicazione dati interattiva
Per consentire a tutti di accedere ai risultati della modellazione dei topic e di provarci da soli, abbiamo implementato il workflow (nella Figura 6) come una Applicazione dati su KNIME Business Hub e l’abbiamo resa pubblica, così che tutti possano accedervi. Puoi controllarlo su: Tendenze di lavoro nell’analisi dei dati.
La parte visiva di questa app dati proviene dal componente Topic Explorer View di Francesco Tuscolano e Paolo Tamagnini, disponibile per il download gratuito dal KNIME Community Hub, e offre una serie di visualizzazioni interattive di argomenti per argomento e documento.
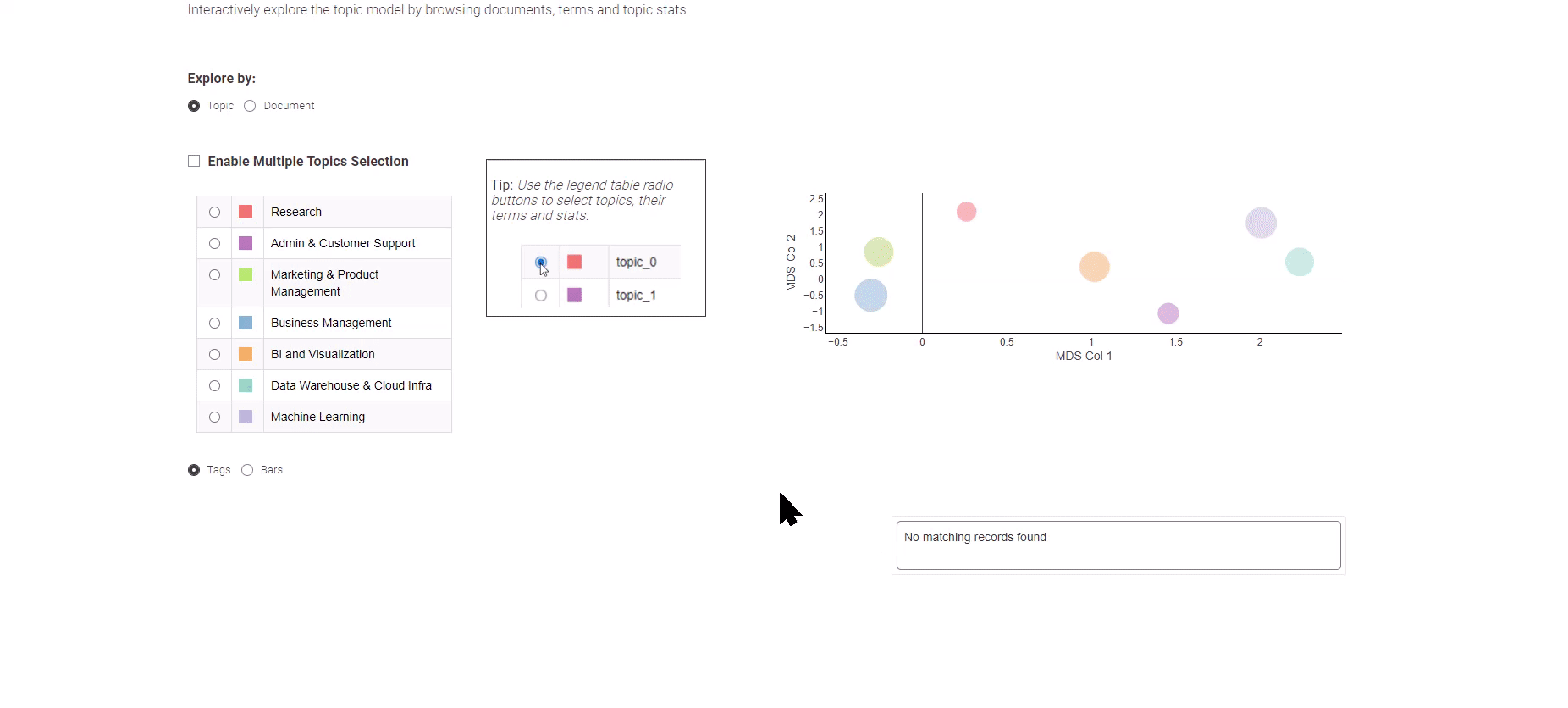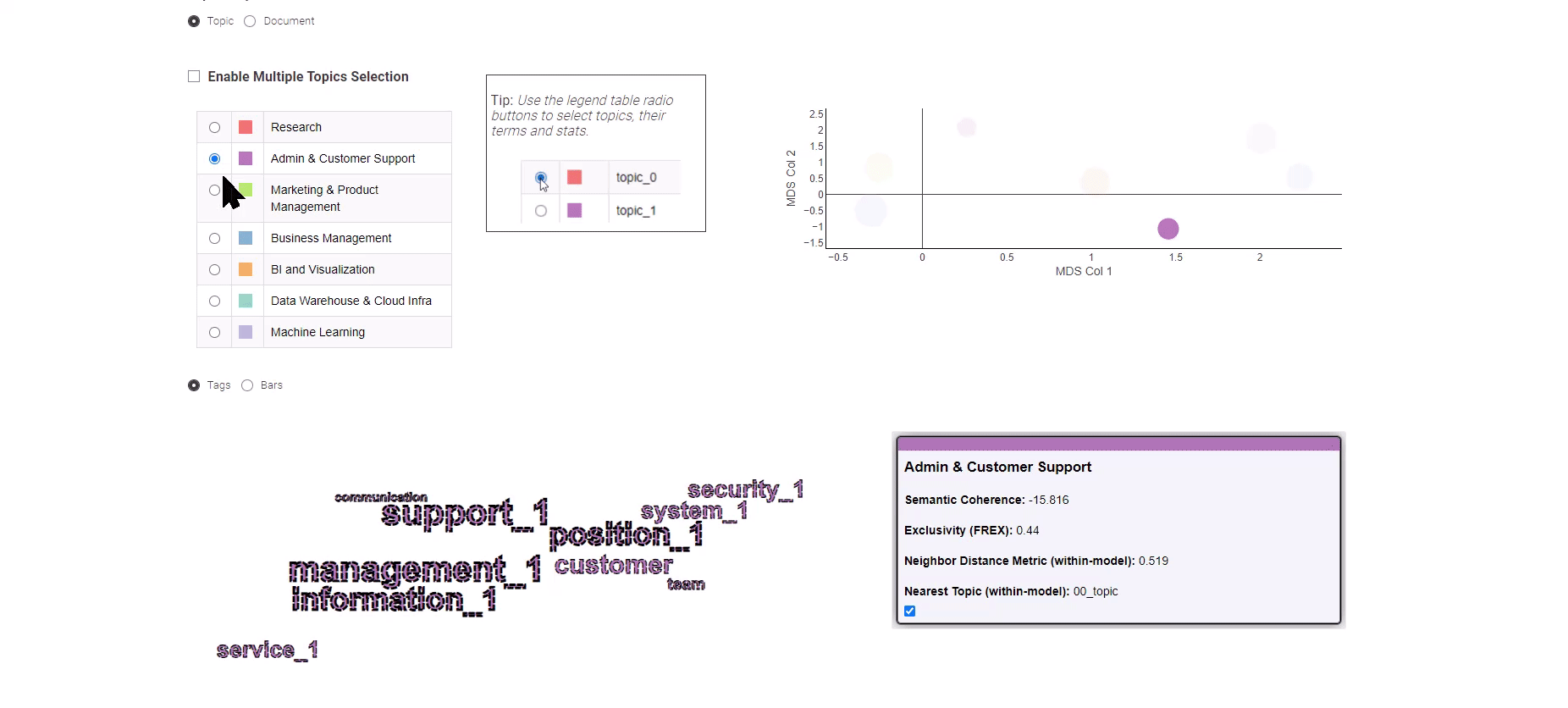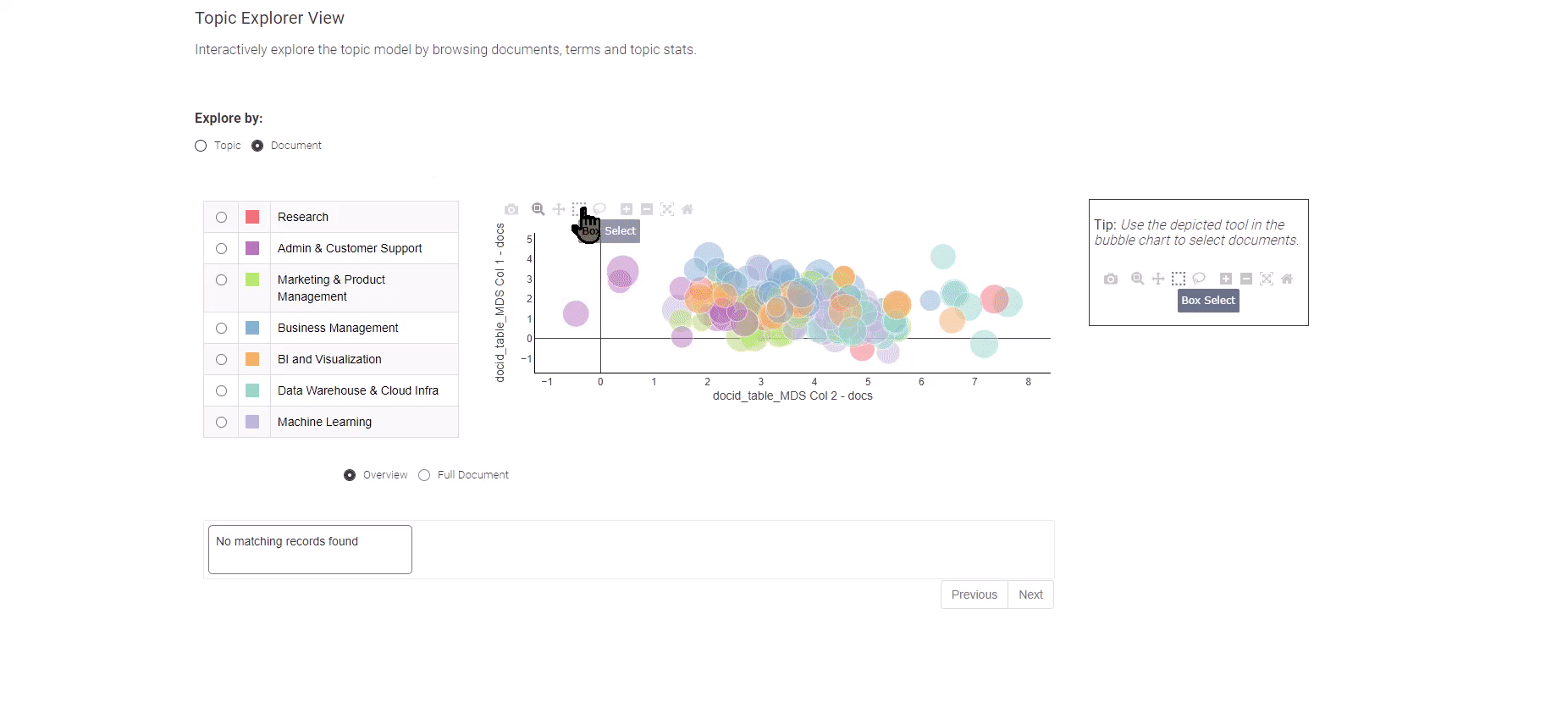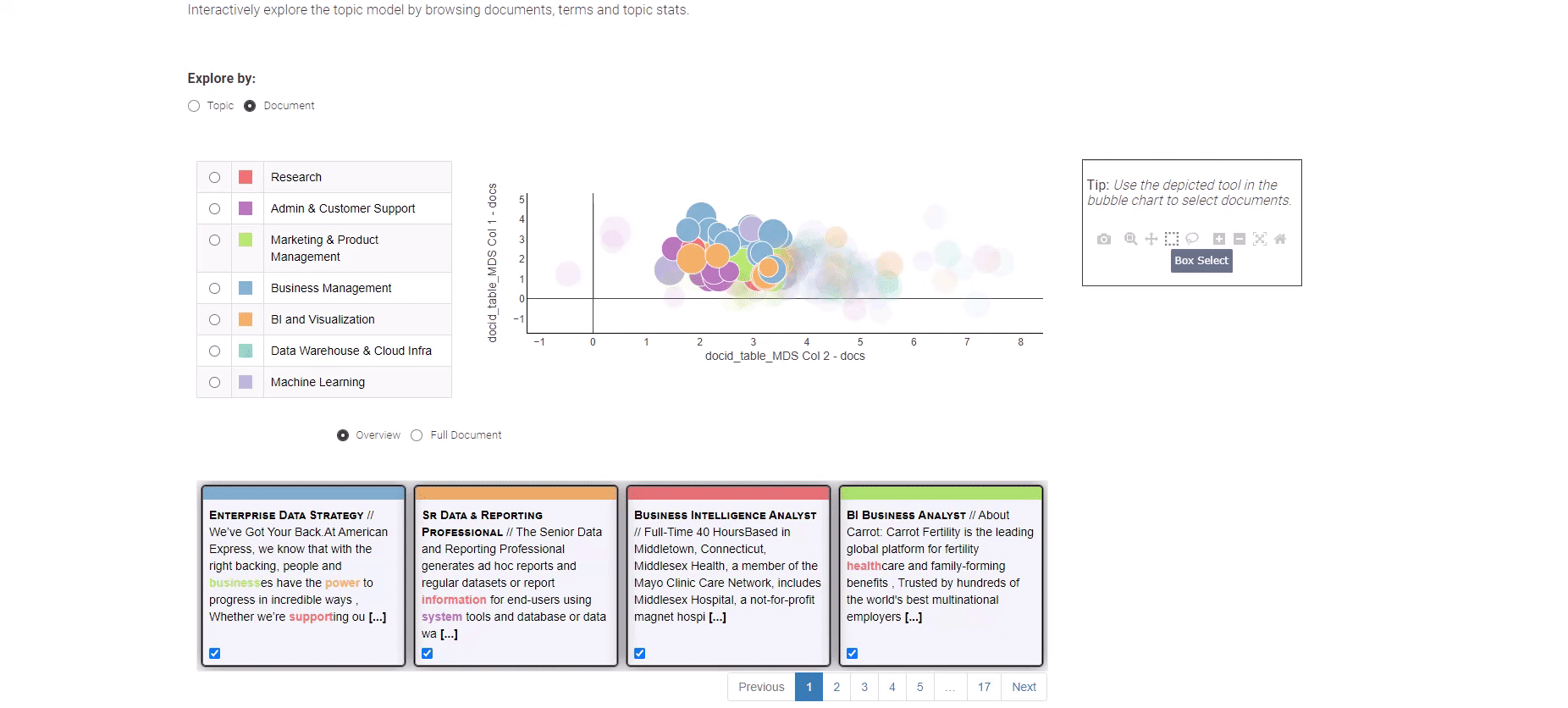 Figura 8: Tendenze nel lavoro dell’analisi dei dati per l’esplorazione dei risultati della modellazione dei topic
Figura 8: Tendenze nel lavoro dell’analisi dei dati per l’esplorazione dei risultati della modellazione dei topic
Come mostrato nella Figura 8, questa App dati offre la scelta tra due visualizzazioni distinte: la visualizzazione “Argomento” e la visualizzazione “Documento”.
La visualizzazione “Argomento” utilizza un algoritmo di scalatura multidimensionale per rappresentare gli argomenti su un grafico bidimensionale, illustrando efficacemente le relazioni semantiche tra di essi. Nel pannello di sinistra, puoi selezionare comodamente un argomento di interesse, che mostrerà le sue principali parole chiave corrispondenti.
Per esplorare le singole offerte di lavoro, opta semplicemente per la visualizzazione “Documento”. La visualizzazione “Documento” presenta una rappresentazione condensata di tutti i documenti lungo due dimensioni. Utilizza il metodo di selezione a casella per individuare i documenti significativi e in fondo, una panoramica dei documenti selezionati ti aspetta.
Esplorazione del mercato del lavoro nell’analisi dei dati utilizzando NLP
Ecco un riassunto dell’applicazione “Tendenze di lavoro nell’analisi dei dati”, che è stata implementata e utilizzata per esplorare le richieste di competenze più recenti e i ruoli professionali nel mercato del lavoro della scienza dei dati. Per questo blog, abbiamo limitato la nostra area di azione alle descrizioni di lavoro per gli Stati Uniti, scritte in inglese, da febbraio ad aprile 2023.
Per comprendere le tendenze nel lavoro e fornire una revisione, il “Tendenze di lavoro nell’analisi dei dati” recupera dati dai siti delle agenzie di lavoro, estrae il testo dalle offerte di lavoro online, estrae argomenti e parole chiave dopo aver eseguito una serie di attività di NLP e visualizza infine i risultati per argomento e per documento per individuare i modelli nei dati.
L’applicazione è composta da una serie di quattro workflow KNIME da eseguire in sequenza per lo scraping web, l’elaborazione dei dati, la modellazione dei topic e quindi le visualizzazioni interattive per consentire all’utente di individuare le tendenze nel lavoro.
Abbiamo implementato il workflow su KNIME Business Hub e lo abbiamo reso pubblico, in modo che tutti possano accedervi. Puoi controllarlo su: Tendenze di lavoro nell’analisi dei dati.
L’intero set di workflow è disponibile gratuitamente per il download dal KNIME Community Hub presso Tendenze di lavoro nell’analisi dei dati. I workflow possono essere facilmente modificati e adattati per scoprire le tendenze in altri settori del mercato del lavoro. Basta modificare l’elenco delle parole chiave di ricerca nel file Excel, il sito web e il periodo temporale per la ricerca.
Cosa dicono i risultati? Quali competenze e ruoli professionali sono più ricercati nel mercato del lavoro della scienza dei dati di oggi? Nel nostro prossimo post sul blog, ti guideremo nell’esplorazione dei risultati di questa modellazione dei topic. Insieme, esamineremo da vicino l’interessante interazione tra ruoli professionali e competenze, ottenendo preziose informazioni sul mercato del lavoro della scienza dei dati lungo il percorso. Resta sintonizzato per un’esplorazione illuminante!
Risorse
- Una revisione sistematica dei requisiti di lavoro e dei corsi online di analisi dei dati di A. Mauro et al.
Mahantesh Pattadkal ha oltre 6 anni di esperienza nella consulenza su progetti e prodotti di scienza dei dati. Con una Laurea Magistrale in Scienze dei Dati, la sua competenza risplende nell’Apprendimento Profondo, nel Processamento del Linguaggio Naturale e nell’Apprendimento Automatico Esplicabile. Inoltre, si impegna attivamente con la Community KNIME per la collaborazione su progetti basati sulla scienza dei dati.
Andrea De Mauro ha oltre 15 anni di esperienza nella creazione di team di analisi aziendale e di scienza dei dati presso aziende multinazionali come P&G e Vodafone. Oltre al suo ruolo aziendale, ama insegnare Marketing Analytics e Applied Machine Learning presso diverse università in Italia e in Svizzera. Attraverso le sue ricerche e scritture, ha esplorato l’impatto commerciale e sociale dei Dati e dell’Intelligenza Artificiale, convinto che una maggiore alfabetizzazione nell’analisi dei dati renderà il mondo migliore. Il suo ultimo libro è ‘Data Analytics Made Easy’, pubblicato da Packt. È apparso nella lista globale ‘Forty Under 40’ del 2022 della rivista CDO.






