La ricerca della fiducia delle modelle Puoi fidarti di una scatola nera?
La ricerca della fiducia delle modelle Puoi fidarti di una scatola nera?

I large Language Models (LLM) come GPT-4 e LLaMA2 sono entrati nel [etichettatura dei dati] chat. LLM hanno fatto molta strada e possono ora etichettare dati e assumersi compiti storicamente svolti dagli umani. Sebbene ottenere etichette dei dati con un LLM sia incredibilmente veloce e relativamente economico, c’è ancora un grande problema, questi modelli sono la quintessenza delle scatole nere. Quindi la domanda inevitabile è: quanto fiducia dobbiamo riporre nelle etichette generate da questi LLM? Nel post di oggi, affrontiamo questo dilemma per stabilire alcune linee guida fondamentali per valutare la fiducia che possiamo avere nei dati etichettati da LLM.
Contesto
- Tendenze lavorative nell’analisi dei dati NLP per l’analisi delle tendenze lavorative
- Suggerimenti per navigare con successo i colloqui di lavoro per principianti nel campo della scienza dei dati
- Automatizza l’attività di progettazione grafica con il plugin ChatGPT Canva
I risultati presentati di seguito sono frutto di un esperimento condotto da Toloka utilizzando modelli popolari e un set di dati in turco. Questo non è un rapporto scientifico, ma piuttosto una breve panoramica di possibili approcci al problema e alcune suggerimenti su come determinare quale metodo funzioni meglio per la propria applicazione.
La grande domanda
Prima di entrare nei dettagli, ecco la grande domanda: quando possiamo fidarci di un’etichetta generata da un LLM e quando dovremmo essere scettici? Conoscere questo può aiutarci nell’etichettatura automatica dei dati e può essere anche utile in altre attività pratiche come il supporto clienti, la generazione di contenuti e altro.
Lo stato attuale delle cose
Quindi, come affrontano le persone questo problema ora? Alcuni chiedono direttamente al modello di restituire un punteggio di fiducia, altri guardano la coerenza delle risposte del modello su più esecuzioni, mentre altri esaminano le log-probabilità del modello. Ma uno di questi approcci è affidabile? Scopriamolo.
La regola pratica
Cosa rende una misura di fiducia “buona”? Una semplice regola da seguire è che dovrebbe esserci una correlazione positiva tra il punteggio di fiducia e l’accuratezza dell’etichetta. In altre parole, un punteggio di fiducia più alto dovrebbe significare una maggiore probabilità di correttezza. Questa relazione può essere visualizzata utilizzando un grafico di calibrazione, in cui gli assi X e Y rappresentano rispettivamente la fiducia e l’accuratezza.
Esperimenti e i loro risultati
Approccio 1: Autostima
L’approccio dell’autostima comporta chiedere direttamente al modello della sua fiducia. E indovina un po’? I risultati non erano affatto male! Mentre i LLM che abbiamo testato hanno avuto difficoltà con il set di dati non in inglese, la correlazione tra la fiducia auto-riferita e l’accuratezza effettiva è stata piuttosto solida, il che significa che i modelli sono consapevoli dei propri limiti. Abbiamo ottenuto risultati simili per GPT-3.5 e GPT-4 qui.
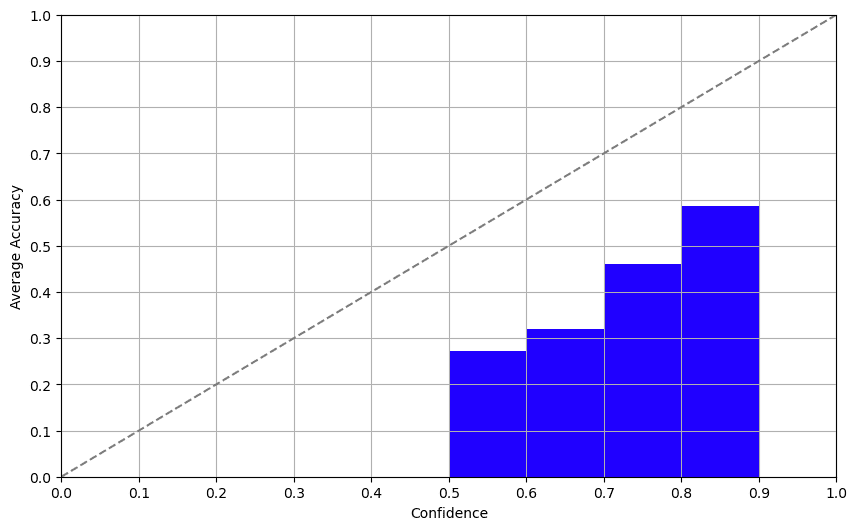
Approccio 2: Coerenza
Impostare una temperatura elevata (~0,7-1,0), etichettare lo stesso elemento più volte e analizzare la coerenza delle risposte, per maggiori dettagli, consultare questo documento. Abbiamo provato questo con GPT-3.5 ed è stato, per dirlo in modo chiaro, un completo disastro. Abbiamo sollecitato il modello a rispondere alla stessa domanda più volte e i risultati sono stati costantemente erratici. Questo approccio è affidabile quanto chiedere un consiglio di vita a una palla magica 8.
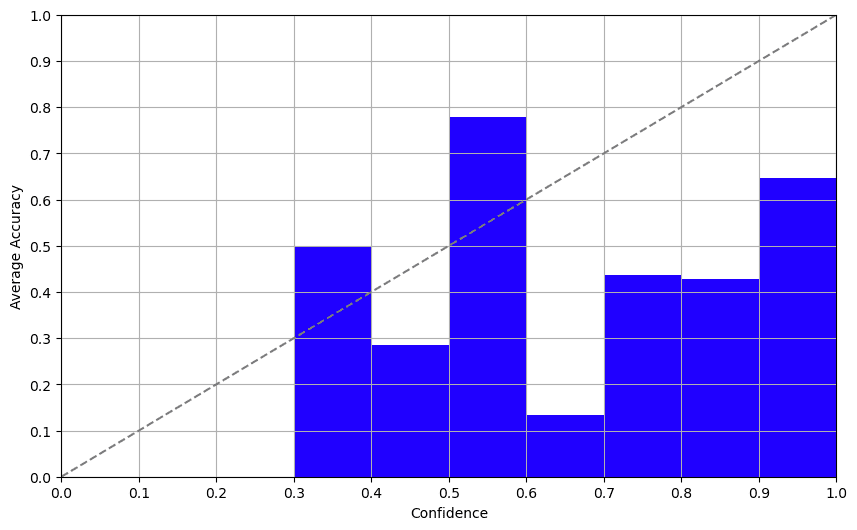
Approccio 3: Log-Probabilità
Le log-probabilità hanno riservato una piacevole sorpresa. Davinci-003 restituisce le log-probabilità dei token in modalità di completamento. Esaminando questa uscita, abbiamo ottenuto un punteggio di fiducia sorprendentemente decente che correlava bene con l’accuratezza. Questo metodo offre un approccio promettente per determinare un punteggio di fiducia affidabile.
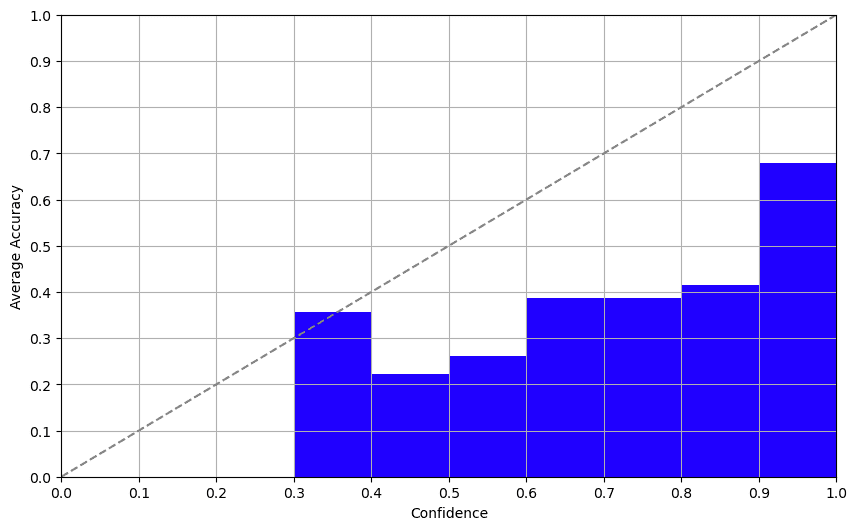
La conclusione
Allora, cosa abbiamo imparato? Ecco qui, senza troppi giri di parole:
- Autostima: Utile, ma gestiscila con cura. I pregiudizi sono ampiamente segnalati.
- Coerenza: Meglio evitarla. A meno che ti piaccia il caos.
- Probabilità Logaritmiche: Una scommessa sorprendentemente buona per ora se il modello ti consente di accedervi.
La parte eccitante? Le probabilità logaritmiche sembrano essere piuttosto robuste anche senza ottimizzare il modello, nonostante questo articolo riporti che questo metodo sia troppo sicuro di sé. C’è spazio per ulteriori esplorazioni.
Aree Future
Un passo logico successivo potrebbe essere trovare una formula magica che combini le migliori parti di ognuno di questi tre approcci o che ne esplori di nuovi. Quindi, se sei pronto per una sfida, potrebbe essere il tuo prossimo progetto da fine settimana!
Conclusioni
Ecco qua, appassionati di ML e principianti, è tutto qui. Ricordate, che siate impegnati nell’etichettatura dei dati o nella costruzione del prossimo grande agente conversazionale, capire la fiducia del modello è fondamentale. Non prenderete quei punteggi di fiducia per valore nominale e assicuratevi di fare i compiti!
Spero che abbiate trovato questo interessante. Fino alla prossima volta, continuate a elaborare quei numeri e a mettere in discussione quei modelli. Ivan Yamshchikov è professore di Elaborazione Semantica dei Dati e Calcolo Cognitivo presso il Center for AI and Robotics, Technical University of Applied Sciences Würzburg-Schweinfurt. È anche a capo del team Data Advocates presso Toloka AI. I suoi interessi di ricerca includono la creatività computazionale, l’elaborazione semantica dei dati e i modelli generativi.





