Massimizza le prestazioni nelle applicazioni di Edge AI
Migliora al massimo le prestazioni nelle applicazioni di Edge AI
Mentre l’IA migra dal cloud al Edge, vediamo la tecnologia utilizzata in una varietà sempre più ampia di casi d’uso, che vanno dal rilevamento di anomalie all’applicazioni che includono lo shopping intelligente, la sorveglianza, la robotica e l’automazione delle fabbriche. Pertanto, non esiste una soluzione universale. Ma con la rapida crescita dei dispositivi dotati di telecamera, l’IA è stata ampiamente adottata per analizzare dati video in tempo reale al fine di automatizzare il monitoraggio video per migliorare la sicurezza, migliorare l’efficienza operativa e garantire migliori esperienze ai clienti, ottenendo così un vantaggio competitivo nelle rispettive industrie. Per supportare al meglio l’analisi video, è necessario comprendere le strategie per ottimizzare le prestazioni del sistema nelle implementazioni di IA Edge.
Le strategie per ottimizzare le prestazioni del sistema di IA includono:
- Selezionare le unità di calcolo delle dimensioni corrette per soddisfare o superare i livelli di prestazioni richiesti. Per un’applicazione di IA, queste unità di calcolo devono svolgere le funzioni dell’intero pipeline della visione (cioè il pre e il post processing video, l’inferenza della rete neurale).
Potrebbe essere necessario un acceleratore di IA dedicato, sia esso discreto o integrato in un SoC (al posto dell’esecuzione dell’inferenza dell’IA su una CPU o GPU).
- Svelare schemi nascosti Un’introduzione al clustering gerarchico
- Quanto siamo vicini all’AGI?
- Lottare contro l’impersonificazione tramite l’IA
- Comprendere la differenza tra throughput e latenza; dove il throughput è il tasso con cui i dati possono essere elaborati in un sistema e la latenza misura il ritardo di elaborazione dei dati attraverso il sistema ed è spesso associata alla reattività in tempo reale. Ad esempio, un sistema può generare dati di immagini a 100 frame al secondo (throughput) ma ci vogliono 100 ms (latenza) affinché un’immagine passi attraverso il sistema.
- Considerare la capacità di scalare facilmente le prestazioni di IA in futuro per soddisfare le crescenti esigenze, i requisiti in continua evoluzione e le tecnologie emergenti (ad esempio, modelli di IA più avanzati per una maggiore funzionalità e precisione). È possibile ottenere la scalabilità delle prestazioni utilizzando acceleratori di IA nel formato modulo o con chip aggiuntivi di acceleratori di IA.
Comprensione dei requisiti di prestazioni variabili dell’IA
I requisiti effettivi delle prestazioni dipendono dall’applicazione. Tipicamente, ci si aspetta che per l’analisi video, il sistema debba elaborare flussi di dati provenienti dalle telecamere a una frequenza di 30-60 frame al secondo e con una risoluzione di 1080p o 4k. Una telecamera con IA abilitata elaborerebbe un singolo flusso; un’apparecchiatura Edge elaborerebbe più flussi in parallelo. In entrambi i casi, il sistema di IA per Edge deve supportare le funzioni di pre-elaborazione per trasformare i dati dei sensori della telecamera in un formato che corrisponda ai requisiti di input della sezione di inferenza dell’IA (Figura 1).
Le funzioni di pre-elaborazione prendono i dati grezzi e svolgono attività come ridimensionamento, normalizzazione e conversione dello spazio colore, prima di alimentare l’input nel modello in esecuzione sull’acceleratore di IA. La pre-elaborazione può utilizzare efficienti librerie di elaborazione delle immagini come OpenCV per ridurre i tempi di pre-elaborazione. La post-elaborazione comporta l’analisi dell’output dell’inferenza. Utilizza attività come la soppressione dei massimi non locali (NMS interpreta l’output dei modelli di rilevamento degli oggetti) e la visualizzazione delle immagini per generare informazioni concrete, ad esempio bounding box, etichette di classe o punteggi di confidenza.

L’inferenza del modello di IA può presentare la sfida aggiuntiva di elaborare più modelli di reti neurali per ogni fotogramma, a seconda delle capacità dell’applicazione. Le applicazioni di computer vision di solito coinvolgono più compiti di IA che richiedono una pipeline di modelli multipli. Inoltre, l’output di un modello è spesso l’input del modello successivo. In altre parole, i modelli in un’applicazione dipendono spesso l’uno dall’altro e devono essere eseguiti in sequenza. L’insieme esatto di modelli da eseguire potrebbe non essere statico e potrebbe variare in modo dinamico, anche su base frame-by-frame.
La sfida di eseguire modelli multipli in modo dinamico richiede un acceleratore di IA esterno con una memoria dedicata e sufficientemente grande per memorizzare i modelli. Spesso l’acceleratore di IA integrato all’interno di un SoC non è in grado di gestire il carico di lavoro multi-modello a causa dei vincoli imposti dal sottosistema di memoria condivisa e da altre risorse nel SoC.
Ad esempio, il tracciamento degli oggetti basato sulla previsione del movimento si basa su rilevazioni continue per determinare un vettore che viene utilizzato per identificare l’oggetto tracciato in una posizione futura. L’efficacia di questo approccio è limitata perché manca di una vera capacità di ricontestualizzazione. Con la previsione del movimento, il tracciato di un oggetto può essere perso a causa di rilevazioni mancate, occlusioni o dell’oggetto che esce dal campo visivo, anche momentaneamente. Una volta perso, non c’è modo di riassegnare il tracciato dell’oggetto. Aggiungendo la riconoscibilità si risolve questa limitazione, ma richiede un embedding dell’aspetto visivo (ovvero una impronta digitale dell’immagine). Gli embedding dell’aspetto richiedono una seconda rete per generare un vettore di caratteristiche elaborando l’immagine contenuta all’interno del bounding box dell’oggetto rilevato dalla prima rete. Questo embedding può essere utilizzato per riconoscere nuovamente l’oggetto, indipendentemente dal tempo o dallo spazio. Poiché gli embedding devono essere generati per ogni oggetto rilevato nel campo visivo, i requisiti di elaborazione aumentano man mano che la scena diventa più intensa. Il tracciamento degli oggetti con riconoscibilità richiede una riflessione accurata tra l’esecuzione di rilevazioni ad alta precisione/alta risoluzione/alta frequenza dei fotogrammi e la riserva di spazio sufficiente per la scalabilità degli embedding. Un modo per soddisfare il requisito di elaborazione è utilizzare un acceleratore di IA dedicato. Come accennato in precedenza, il motore di IA del SoC può risentire della mancanza di risorse di memoria condivisa. L’ottimizzazione del modello può anche essere utilizzata per ridurre il requisito di elaborazione, ma potrebbe influire sulle prestazioni e/o sull’accuratezza.
Non limitare le prestazioni dell’IA con sovraccarico a livello di sistema
In una telecamera intelligente o in un dispositivo periferico, il SoC integrato (ovvero il processore di sistema) acquisisce i frame video e esegue le fasi di pre-elaborazione descritte precedentemente. Queste funzioni possono essere eseguite utilizzando i core CPU o la GPU del SoC (se disponibile), ma possono anche essere eseguite da acceleratori hardware dedicati nel SoC (ad esempio, il processore di segnale dell’immagine). Dopo che queste fasi di pre-elaborazione sono completate, l’acceleratore IA integrato nel SoC può accedere direttamente a questo input quantizzato dalla memoria di sistema, o nel caso di un acceleratore IA discreto, l’input viene quindi inviato per l’inferenza, tipicamente tramite l’interfaccia USB o PCIe.
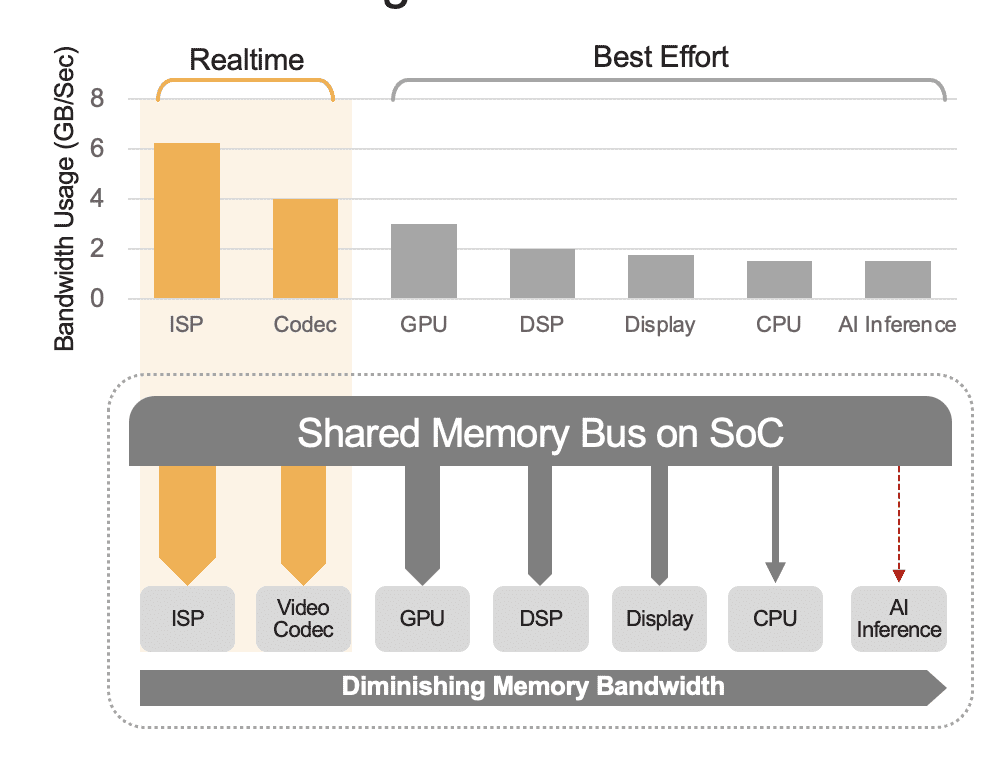
Un SoC integrato può contenere una serie di unità di calcolo, tra cui CPU, GPU, acceleratore IA, processore di visione, codec video, processore di segnale dell’immagine (ISP) e altro ancora. Queste unità di calcolo condividono tutte la stessa linea di memoria e quindi l’accesso alla stessa memoria. Inoltre, la CPU e la GPU potrebbero anche dover svolgere un ruolo nell’inferenza e queste unità saranno impegnate nell’esecuzione di altre attività in un sistema in uso. Questo è quello che intendiamo per sovraccarico a livello di sistema (figura 2).
Molti sviluppatori valutano erroneamente le prestazioni dell’acceleratore IA integrato nel SoC senza considerare l’effetto del sovraccarico a livello di sistema sulle prestazioni complessive. Ad esempio, considera l’esecuzione di un benchmark YOLO su un acceleratore IA da 50 TOPS integrato in un SoC, che potrebbe ottenere un risultato di benchmark di 100 inferenze al secondo (IPS). Ma in un sistema in uso con tutte le altre unità di calcolo attive, quei 50 TOPS potrebbero ridursi a circa 12 TOPS e le prestazioni complessive fornirebbero solo 25 IPS, assumendo un fattore di utilizzo del 25%. Il sovraccarico di sistema è sempre un fattore se la piattaforma sta elaborando continuamente flussi video. In alternativa, con un acceleratore IA discreto (ad esempio, Kinara Ara-1, Hailo-8, Intel Myriad X), l’utilizzo a livello di sistema potrebbe essere superiore al 90% perché una volta che il SoC host avvia la funzione di inferenza e trasferisce i dati di input del modello IA, l’acceleratore funziona in modo autonomo utilizzando la sua memoria dedicata per accedere ai pesi del modello e ai parametri.
L’analisi video al margine richiede una bassa latenza
Fino a questo punto, abbiamo discusso delle prestazioni dell’IA in termini di frame al secondo e TOPS. Ma una bassa latenza è un altro requisito importante per garantire una reattività in tempo reale del sistema. Ad esempio, nei videogiochi, una bassa latenza è fondamentale per un’esperienza di gioco fluida e reattiva, in particolare nei giochi a controllo di movimento e nei sistemi di realtà virtuale (VR). Nei sistemi di guida autonoma, una bassa latenza è essenziale per la rilevazione in tempo reale degli oggetti, il riconoscimento dei pedoni, il rilevamento delle corsie e il riconoscimento dei segnali stradali al fine di evitare compromettere la sicurezza. I sistemi di guida autonoma richiedono tipicamente una latenza end-to-end inferiore a 150 ms dalla rilevazione all’azione effettiva. Allo stesso modo, nella produzione, una bassa latenza è essenziale per la rilevazione in tempo reale dei difetti, il riconoscimento delle anomalie e l’orientamento robotico dipendono dall’analisi video a bassa latenza per garantire un funzionamento efficiente e ridurre al minimo i tempi di fermo produzione.
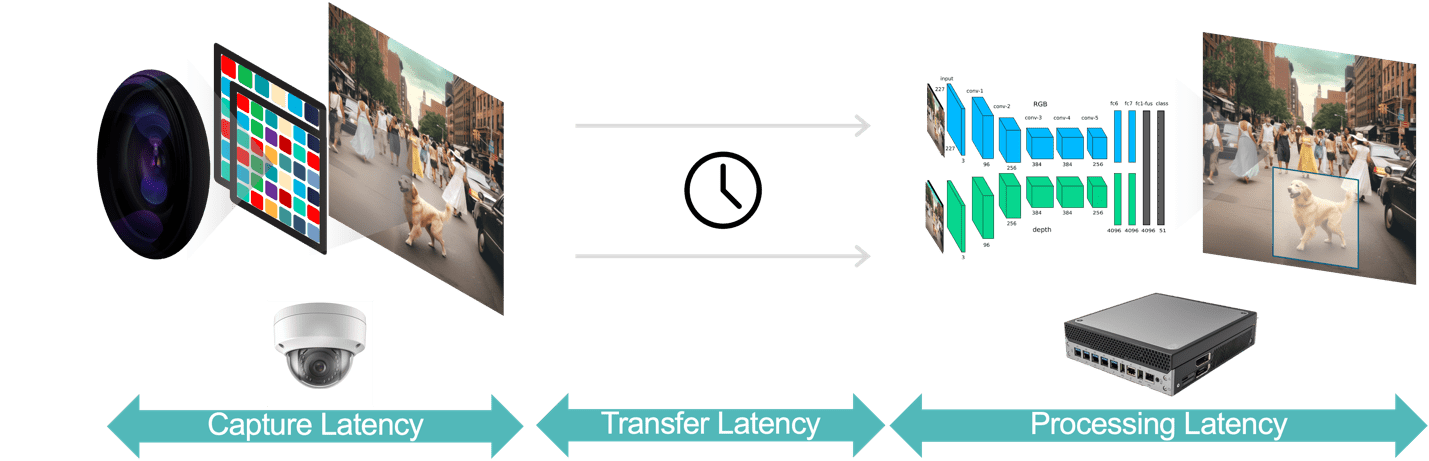
In generale, ci sono tre componenti di latenza in un’applicazione di analisi video (figura 3):
- La latenza di acquisizione dei dati è il tempo dalla cattura di un frame video da parte del sensore della telecamera alla disponibilità del frame per il sistema di analisi per il processo. Puoi ottimizzare questa latenza scegliendo una telecamera con un sensore rapido e un processore a bassa latenza, selezionando frame rate ottimali e utilizzando formati di compressione video efficienti.
- La latenza di trasferimento dei dati è il tempo necessario perché i dati video acquisiti e compressi viaggino dalla telecamera ai dispositivi periferici o ai server locali. Ciò include i ritardi di elaborazione di rete che si verificano in ciascun punto finale.
- La latenza di elaborazione dei dati si riferisce al tempo necessario per i dispositivi periferici per eseguire compiti di elaborazione video come la decompressione dei frame e gli algoritmi di analisi (ad esempio, il tracking degli oggetti basato sulla previsione dei movimenti, il riconoscimento facciale). Come evidenziato in precedenza, la latenza di elaborazione è ancora più importante per le applicazioni che devono eseguire più modelli IA per ciascun frame video.
La latenza di elaborazione dei dati può essere ottimizzata utilizzando un acceleratore IA con un’architettura progettata per ridurre al minimo lo spostamento dei dati all’interno del chip e tra il calcolo e i vari livelli della gerarchia di memoria. Inoltre, per migliorare la latenza ed efficienza a livello di sistema, l’architettura deve supportare un tempo di commutazione tra i modelli pari a zero (o quasi zero), per supportare meglio le applicazioni multi-modello di cui abbiamo discusso in precedenza. Un altro fattore per un miglioramento delle prestazioni e della latenza riguarda la flessibilità algoritmica. In altre parole, alcune architetture sono progettate per un comportamento ottimale solo su modelli IA specifici, ma con l’ambiente AI che cambia rapidamente, nuovi modelli per prestazioni superiori e migliore accuratezza stanno emergendo praticamente ogni giorno. Pertanto, seleziona un processore IA periferico senza restrizioni pratiche sulla topologia del modello, gli operatori e le dimensioni.
Ci sono molti fattori da considerare per massimizzare le prestazioni in un dispositivo di intelligenza artificiale di bordo, tra cui requisiti di prestazioni e latenza e sovraccarico di sistema. Una strategia di successo dovrebbe prendere in considerazione un acceleratore di intelligenza artificiale esterno per superare le limitazioni di memoria e prestazioni del motore di intelligenza artificiale SoC. C.H. Chee è un esperto dirigente di marketing e gestione di prodotti. Chee ha ampia esperienza nella promozione di prodotti e soluzioni nel settore dei semiconduttori, con particolare attenzione all’intelligenza artificiale basata sulla visione, alla connettività e alle interfacce video per numerosi mercati, tra cui il settore aziendale e il settore dei consumatori. Come imprenditore, Chee ha co-fondato due start-up di semiconduttori video acquisite da una società di semiconduttori pubblica. Chee ha guidato team di marketing di prodotto e ama lavorare con un piccolo gruppo che si concentra sulla realizzazione di risultati straordinari.






