Svelare schemi nascosti Un’introduzione al clustering gerarchico
Svelando schemi nascosti Un'introduzione al clustering gerarchico
Quando ti familiarizzi con il paradigma di apprendimento supervisionato, imparerai gli algoritmi di clustering.
Spesso l’obiettivo del clustering è capire i modelli all’interno di un dataset non etichettato. Oppure può essere quello di individuare gruppi nel dataset e assegnare loro delle etichette in modo da poter eseguire l’apprendimento supervisionato sul dataset ora etichettato. Questo articolo coprirà i concetti base del clustering gerarchico.
- Quanto siamo vicini all’AGI?
- Lottare contro l’impersonificazione tramite l’IA
- La legge dell’Unione Europea prepara il terreno per uno scontro sulla disinformazione
Cos’è il Clustering Gerarchico?
L’algoritmo di clustering gerarchico si propone di trovare la similarità tra le istanze – quantificata da una metrica di distanza – per raggrupparle in segmenti chiamati cluster.
L’obiettivo dell’algoritmo è trovare cluster in modo tale che i punti di dati all’interno di un cluster siano più simili tra loro che ai punti di dati presenti in altri cluster.
Esistono due algoritmi di clustering gerarchico comuni, ognuno con il proprio approccio:
- Clustering Agglomerativo
- Clustering Divisivo
Clustering Agglomerativo
Supponiamo che ci siano n punti di dati distinti nel dataset. Il clustering agglomerativo funziona nel seguente modo:
- Inizia con n cluster; ogni punto di dati rappresenta un cluster a sé stante.
- Raggruppa i punti di dati in base alla loro similarità. Significa che i cluster simili vengono uniti in base alla distanza.
- Ripeti il passaggio 2 fino a quando rimane un solo cluster.
Clustering Divisivo
Come suggerisce il nome, il clustering divisivo cerca di attuare l’inverso del clustering agglomerativo:
- Tutti i punti di dati n si trovano in un unico cluster.
- Dividi questo unico ampio cluster in gruppi più piccoli. Si noti che il raggruppamento dei punti di dati nel clustering agglomerativo si basa sulla similarità. Ma suddividerli in cluster diversi si basa sulla dissimilarità; i punti di dati in cluster diversi sono dissimili tra loro.
- Ripeti fino a quando ogni punto di dato rappresenta un cluster a sé stante.
Metriche di Distanza
Come accennato, la similarità tra i punti di dati viene quantificata utilizzando la metrica di distanza. Le metriche di distanza comunemente utilizzate includono la distanza euclidea e la distanza di Manhattan.
Per ogni coppia di punti di dati nello spazio delle caratteristiche n-dimensionale, la distanza euclidea tra essi è data da:
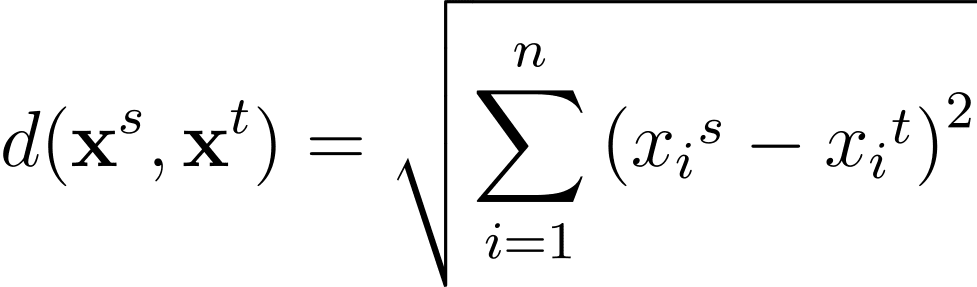
Un’altra metrica di distanza comunemente utilizzata è la distanza di Manhattan, data da:
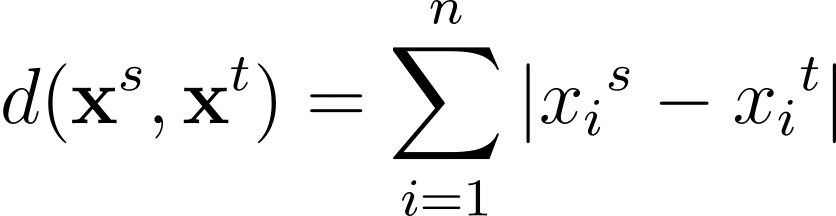
La distanza di Minkowski è una generalizzazione – per un generico p >= 1 – di queste metriche di distanza in uno spazio n-dimensionale:
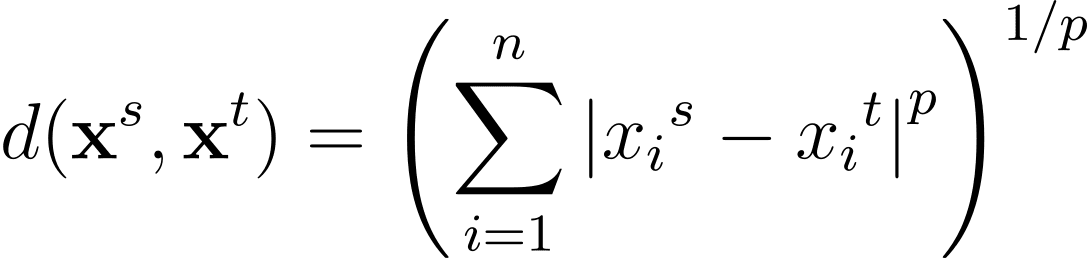
Distanza tra i Clusters: Comprendere i Criteri di Collegamento
Utilizzando le metriche di distanza, è possibile calcolare la distanza tra due punti di dati nel dataset. Tuttavia, è anche necessario definire una distanza per determinare “come” raggruppare insieme i cluster ad ogni passo.
Ricorda che ad ogni passo del clustering agglomerativo, scegliamo i due gruppi più vicini da unire. Questo è rappresentato dal criterio di collegamento. E i criteri di collegamento comunemente utilizzati includono:
- Collegamento Singolo
- Collegamento Completo
- Collegamento Medio
- Collegamento di Ward
Collegamento Singolo
Nel collegamento singolo o clustering a collegamento singolo, la distanza tra due gruppi/cluster è presa come la distanza più piccola tra tutte le coppie di punti di dati nei due cluster. 
Linkage Completa
Nella linkage completa o clustering con linkage completa, la distanza tra due cluster viene scelta come la distanza più grande tra tutte le coppie di punti nei due cluster.
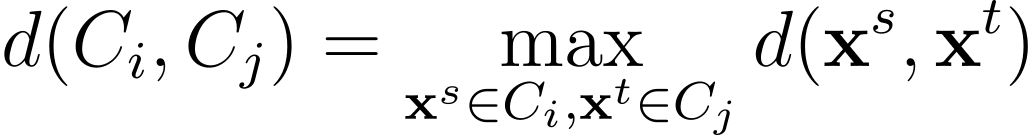
Linkage Media
A volte viene utilizzata la linkage media, che utilizza la media delle distanze tra tutte le coppie di punti nei due cluster.
Linkage di Ward
Il linkage di Ward mira a minimizzare la varianza all’interno dei cluster uniti: la fusione dei cluster dovrebbe ridurre al minimo l’aumento complessivo della varianza dopo la fusione. Ciò porta a cluster più compatti e ben separati.
La distanza tra due cluster viene calcolata considerando l’aumento nella somma totale dei quadrati delle deviazioni (varianza) dalla media del cluster unito. L’idea è misurare quanto aumenta la varianza del cluster unito rispetto alla varianza dei cluster individuali prima della fusione.
Quando codificheremo il clustering gerarchico in Python, utilizzeremo anche il linkage di Ward.
Cosa è un Dendrogramma?
Possiamo visualizzare il risultato del clustering come un dendrogramma. È una struttura ad albero gerarchica che ci aiuta a capire come i punti dati, e successivamente i cluster, sono raggruppati o uniti man mano che l’algoritmo procede.
Nella struttura ad albero gerarchica, le foglie rappresentano le istanze o i punti dati nel dataset. Le distanze corrispondenti in cui avviene la fusione o il raggruppamento possono essere inferite dall’asse y.
Poiché il tipo di linkage determina come i punti dati sono raggruppati insieme, criteri di linkage differenti producono dendrogrammi differenti.
In base alla distanza, possiamo utilizzare il dendrogramma – tagliarlo o sezionarlo in un punto specifico – per ottenere il numero richiesto di cluster.
A differenza di alcuni algoritmi di clustering come il clustering K-Means, il clustering gerarchico non richiede di specificare il numero di cluster in anticipo. Tuttavia, il clustering agglomerativo può richiedere molto tempo di calcolo quando si lavora con dataset di grandi dimensioni.
Clustering Gerarchico in Python con SciPy
Successivamente, effettueremo il clustering gerarchico sul dataset del vino incorporato – passo dopo passo. Per farlo, sfrutteremo il pacchetto di clustering – scipy.cluster – da SciPy.
Step 1 – Importare le librerie necessarie
Prima di tutto, importiamo le librerie e i moduli necessari dalle librerie scikit-learn e SciPy:
# importsimport pandas as pdimport matplotlib.pyplot as pltfrom sklearn.datasets import load_winefrom sklearn.preprocessing import MinMaxScalerfrom scipy.cluster.hierarchy import dendrogram, linkageStep 2 – Caricare e preelaborare il dataset
In seguito, carichiamo il dataset del vino in un dataframe pandas. Si tratta di un dataset semplice che fa parte del modulo datasets di scikit-learn ed è utile per l’esplorazione del clustering gerarchico.
# Caricare il datasetdata = load_wine()X = data.data# Convertire in un DataFrame wine_df = pd.DataFrame(X, columns=data.feature_names)Verifichiamo le prime righe del dataframe:
wine_df.head()
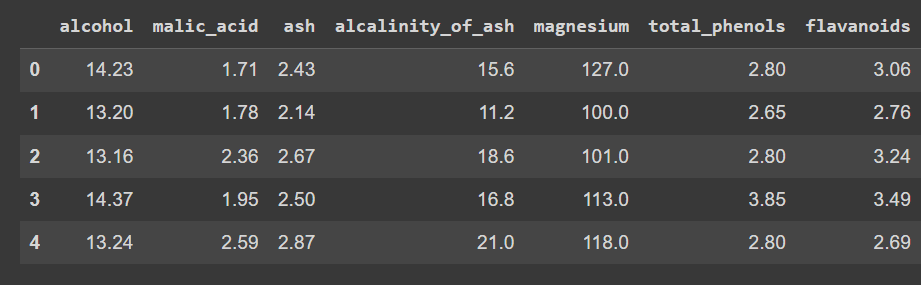 Output troncato di wine_df.head()
Output troncato di wine_df.head()
Notare che abbiamo caricato solo le caratteristiche e non l’etichetta di output, in modo da poter eseguire il clustering per scoprire gruppi nel dataset.
Verifichiamo la forma del dataframe:
print(wine_df.shape)
Ci sono 178 record e 14 caratteristiche:
Output >>> (178, 14)
Poiché il dataset contiene valori numerici che si estendono su diverse gamme, preprocessiamo il dataset. Utilizzeremo MinMaxScaler per trasformare ciascuna delle caratteristiche in valori compresi nell’intervallo [0, 1].
# Ridimensiona le caratteristiche utilizzando MinMaxScalerscaler = MinMaxScaler()X_scaled = scaler.fit_transform(X)
Passaggio 3 – Esegui il clustering gerarchico e traccia il dendrogramma
Calcoliamo la matrice di collegamento, effettuiamo il clustering e tracciamo il dendrogramma. Possiamo utilizzare linkage dal modulo hierarchy per calcolare la matrice di collegamento basata sul collegamento di Ward (imposta method su ‘ward’).
Come discusso, il collegamento di Ward minimizza la varianza all’interno di ogni cluster. Quindi tracciamo il dendrogramma per visualizzare il processo di clustering gerarchico.
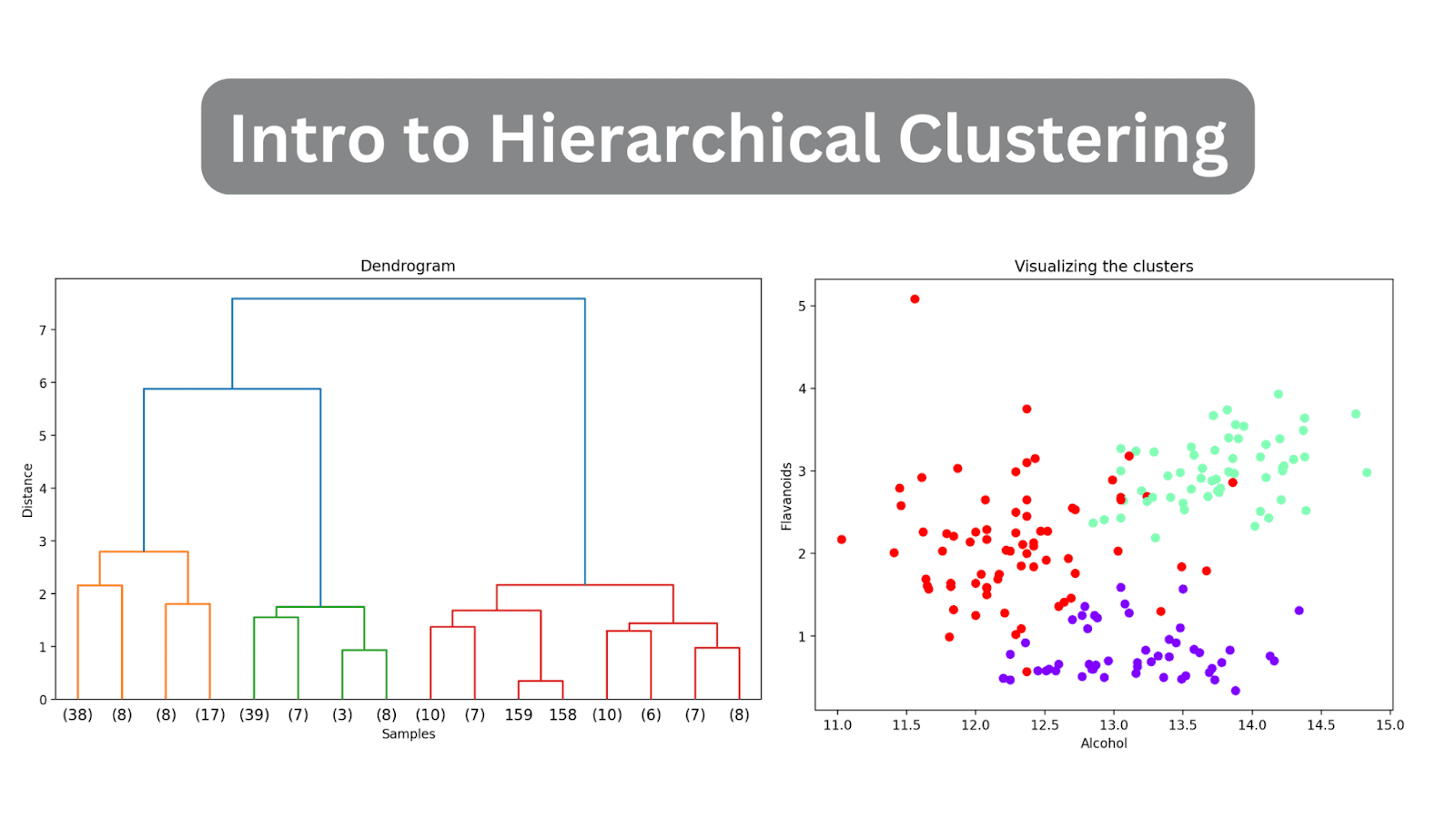
# Calcola la matrice di collegamentolinked = linkage(X_scaled, method='ward')# Traccia il dendrogrammaplt.figure(figsize=(10, 6),dpi=200)dendrogram(linked, orientation='top', distance_sort='descending', show_leaf_counts=True)plt.title('Dendrogramma')plt.xlabel('Campioni')plt.ylabel('Distanza')plt.show()
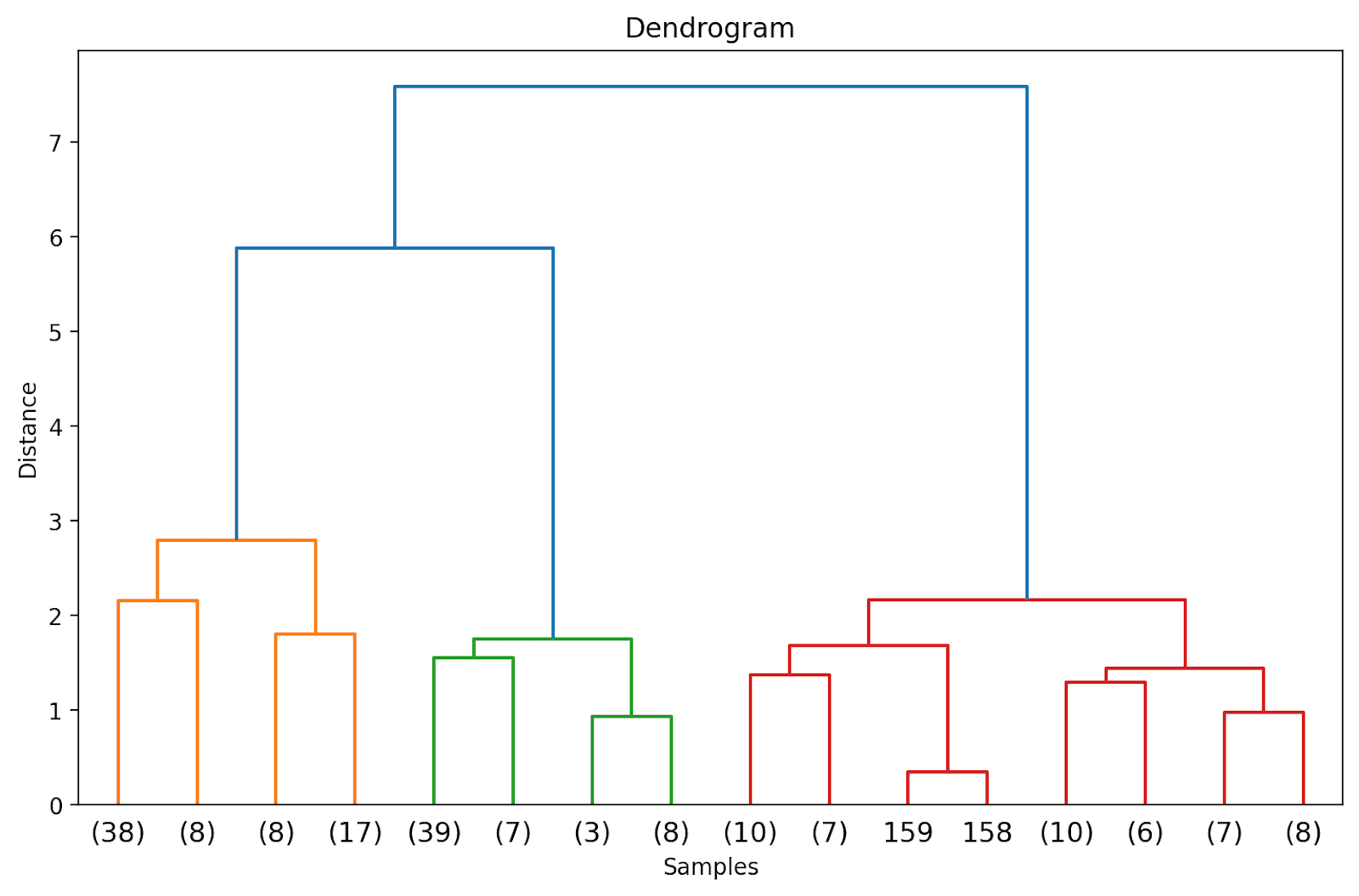
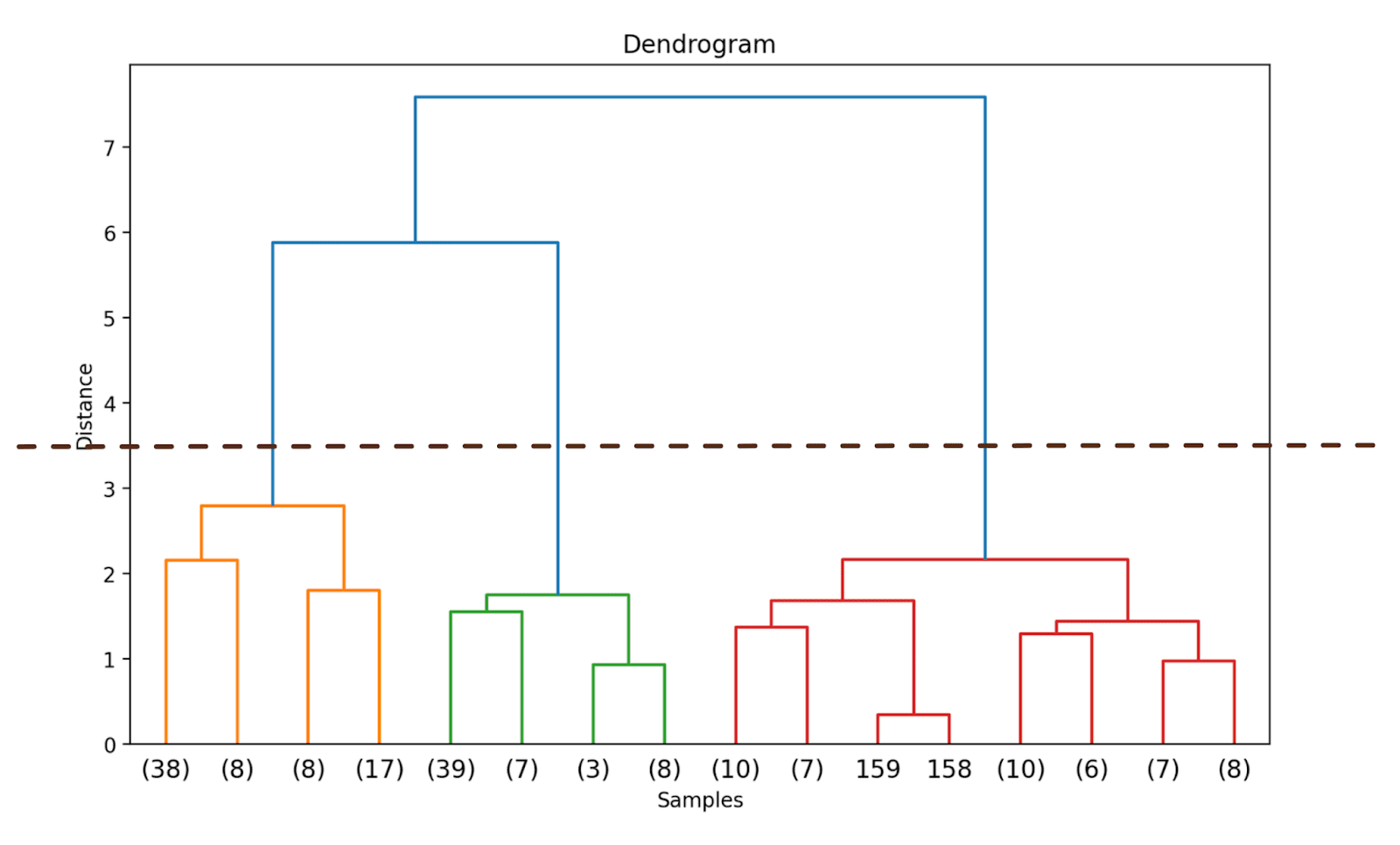
Poiché non abbiamo (ancora) troncato il dendrogramma, possiamo visualizzare come i 178 punti dati sono raggruppati in un unico cluster. Anche se questo sembra difficile da interpretare, possiamo comunque vedere che ci sono tre cluster diversi.
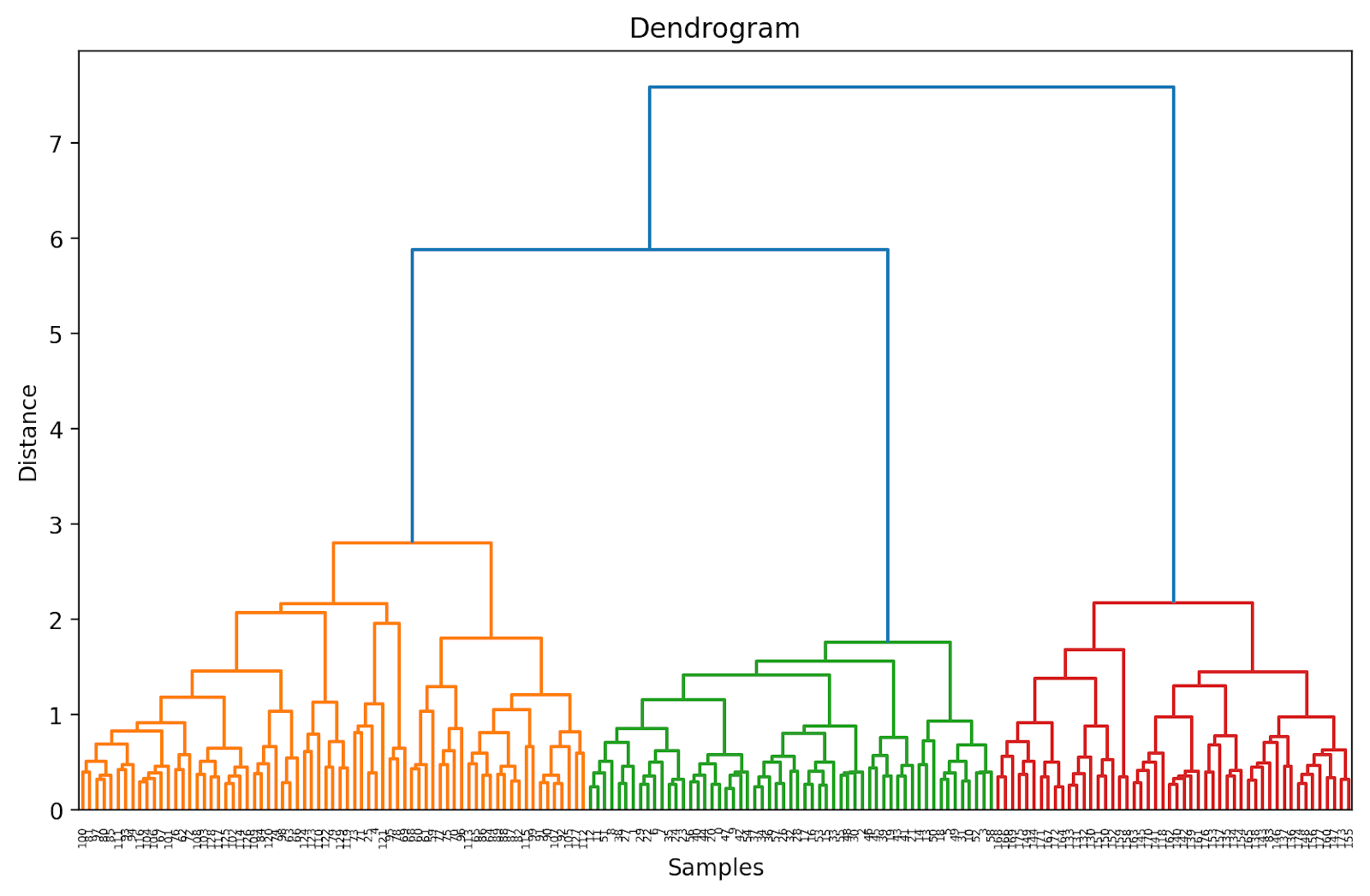
Troncamento del dendrogramma per una visualizzazione più semplice
Nella pratica, anziché l’intero dendrogramma, possiamo visualizzare una versione troncata più facile da interpretare e comprendere.
Per troncare il dendrogramma, possiamo impostare truncate_mode su ‘level’ e p = 3.
# Calcola la matrice di collegamentolinked = linkage(X_scaled, method='ward')# Traccia il dendrogrammaplt.figure(figsize=(10, 6),dpi=200)dendrogram(linked, orientation='top', distance_sort='descending', truncate_mode='level', p=3, show_leaf_counts=True)plt.title('Dendrogramma')plt.xlabel('Campioni')plt.ylabel('Distanza')plt.show()
In questo modo, il dendrogramma viene troncato includendo solo quei cluster che si trovano entro 3 livelli dalla fusione finale.
Nel dendrogramma sopra, è possibile vedere che alcuni punti dati come 158 e 159 sono rappresentati individualmente. Altri sono indicati tra parentesi; questi non sono singoli punti dati ma il numero di punti dati in un cluster. (k) indica un cluster con k campioni.
Passaggio 4 – Identificare il numero ottimale di cluster
Il dendrogramma ci aiuta a scegliere il numero ottimale di cluster.
Possiamo osservare dove la distanza lungo l’asse y aumenta drasticamente, scegliere di troncare il dendrogramma a quel punto – e utilizzare la distanza come soglia per formare i cluster.
Per questo esempio, il numero ottimale di cluster è 3.
Passo 5 – Formare i cluster
Una volta deciso il numero ottimale di cluster, possiamo utilizzare la distanza corrispondente lungo l’asse y – una distanza soglia. Questo garantisce che sopra la distanza soglia, i cluster non vengano più uniti. Scegliamo una threshold_distance di 3.5 (come inferito dal dendrogramma).
Quindi utilizziamo fcluster con il criterion impostato su ‘distance’ per ottenere l’assegnazione del cluster per tutti i punti dati:
from scipy.cluster.hierarchy import fcluster # Scegli una distanza soglia basata sul dendrogramma threshold_distance = 3.5 # Taglia il dendrogramma per ottenere le etichette di cluster cluster_labels = fcluster (collegato, threshold_distance, criterion = 'distanza') # Assegna le etichette del cluster al DataFrame wine_df['cluster'] = cluster_labels
Ora dovresti essere in grado di vedere le etichette dei cluster (uno tra {1, 2, 3}) per tutti i punti dati:
print(wine_df['cluster'])
Output >>>0 21 22 23 24 3 ..173 1174 1175 1176 1177 1Name: cluster, Length: 178, dtype: int32
Passo 6 – Visualizza i cluster
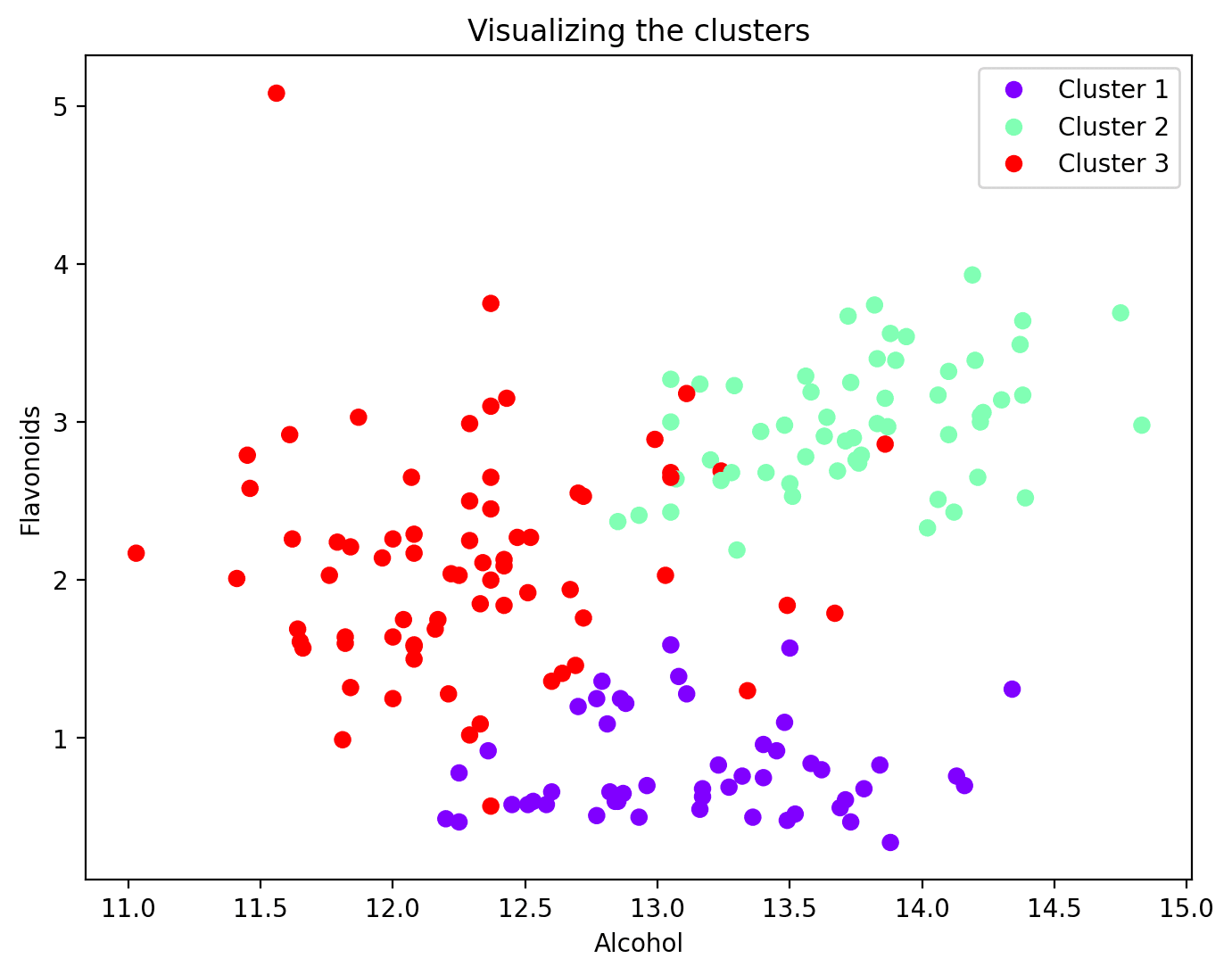
Ora che ogni punto dati è stato assegnato a un cluster, puoi visualizzare un sottoinsieme di caratteristiche e le loro assegnazioni di cluster. Ecco il diagramma a dispersione di due caratteristiche insieme alla mappatura del cluster:
plt.figure(figsize = (8, 6)) scatter = plt.scatter (wine_df['alcohol'], wine_df['flavanoids'], c = wine_df['cluster'], cmap = 'rainbow') plt.xlabel ('Alcool') plt.ylabel ('Flavonoidi') plt.title ('Visualizzazione dei cluster') # Aggiungi legenda legend_labels = [f'Cluster {i + 1}' per i in range (n_clusters)] plt.legend (handles = scatter.legend_elements () [0], labels = legend_labels) plt.show ()
Riassumendo
E questo è tutto! In questo tutorial, abbiamo utilizzato SciPy per eseguire clustering gerarchico solo per poter coprire in modo più dettagliato i passaggi coinvolti. In alternativa, è possibile utilizzare anche la classe AgglomerativeClustering dal modulo cluster di scikit-learn. Buona codifica dei cluster!
Riferimenti
[1] Introduzione all’apprendimento automatico
[2] Un’introduzione all’apprendimento statistico (ISLR) Bala Priya C è una sviluppatrice e scrittrice tecnica proveniente dall’India. Le piace lavorare all’intersezione di matematica, programmazione, data science e creazione di contenuti. Le sue aree di interesse e competenza includono DevOps, data science e elaborazione del linguaggio naturale. Ama leggere, scrivere, codificare e il caffè! Attualmente sta lavorando per imparare e condividere le sue conoscenze con la comunità degli sviluppatori scrivendo tutorial, guide pratiche, articoli di opinione e altro ancora.






